| 【摘要】为了实现更高效的图像去噪,提出一种新的自编码卷积神经网络图像去噪算法。新算法改变了卷积层的激活函数和整个网络跳跃连接的方式,并在学习率的选取上有了一定改进。新模型结构设计简单,卷积网络层数更少。数值实验表明,新模型比原模型运行时间更少、视觉效果更好、峰值信噪比更大。 关键词:图像去噪、卷积神经网络、人工智能、机器学习 中图分类号:TP391.4 文献标志码:A 文章编号:1674-232X(2021) 01-0095-07 |
作者:杜渺勇1,于祥雨2,周浩1,韩丹夫1
近年来,深度学习在实际问题处理中发挥了巨大作用。从医学、视觉心理学,再到安全检查、数字通信技术等,图像能够帮助人类观察对象,并为之采取正确的行动【1】。传统上,已经有许多经典的图像处理方法,例如滤波方法、偏微分方程方法和小波分析方法等【2】。随着大数据和人工智能领域的发展,图像数据规模呈指数型增长,如何将图像处理与深度学习相结合是研究者们的关注热点【3-5】。
图像复原是计算机视觉处理的一个经典问题【6-7】。简而言之,图像复原就是将一张损坏的图像恢复成它的原始状态。目前,深度神经网络展现了它在图像处理方面优良的性能,包括图像复原、图像分类和语义分割等。
Jain和Seung在2007年首先提出了深度神经网络的图像去噪方法【8】。他们在训练神经网络时采取了逐层训练的方法,使网络更加快速地收敛。文献【9】提出堆叠稀疏去噪自编码去噪器,并将其用于图像的去噪和复原工作,但是其网络层数较浅。文献【10】提出了一种新的自编码卷积神经网络的框架,但是由于有维度收缩和维度放大等操作,图像的细节信息容易被破坏。文献【11】根据细胞神经网络(cellular neural networks, CNN)处理图像的优良性能,提出了更深层次的卷积神经网络框架。这个框架不需要使用图像的先验信息,而是直接以端到端的方式学习,并且使用了卷积与反卷积映射。由于深层网络难以训练,这个框架也引入了多层跳跃连接,进而获得较好的去噪效果。
1. 卷积自动编码器的模型介绍
堆叠自编码神经网络是最初的用于图像去噪的深度神经网络【7】,它通过一次只对一层进行无监督的预训练,来最小化相对于输入的重构误差。一旦所有层都经过了预训练之后,网络就会进入微调阶段。Xie等结合稀疏编码和自编码深度神经网络【9】,提出了新的网络用于图像去噪和图像复原等任务。其主要思想是提出了正则化的稀疏诱导项,以提高网络的性能。深度级联网络(deep cascade network, DNC)是一种用于图像超分辨率的多层协同局部自动编码网络【12】。它将纹理高频增强后的图像块输入到网络中,来抑制噪声,并协调重叠部分的相容性。Dong等提出了对称的自编码网络,并且增加跳跃连接【11】。
本文通过改进文献【11】的激活函数、跳跃连接和学习率,只需要更少的隐藏层就能达到文献【11】的去噪效果,并且训练时间和测试时间均有所减少。与文献【11】相比,本文在原有神经网络结构上还引入加权系数的思想,即跳跃连接不是直接将卷积层与反卷积层相加,而是在卷积层和反卷积层之前添加权重系数,实验结果显示峰值信噪比也有所增高。
2. 新的方法
2.1 模型综述
图像去噪是对含有噪声的图像进行处理,并估计原始图像的过程.这个问题可以被描述为
Y(i , j)= X(i , j)+η(i , j) , (1)
其中,Y(i , j)表示噪声图像,X(i , j)表示原始图像,η(i , j)表示加性噪声。原始图像在加性噪声的干扰下,退化为噪声图像。由此,图像去噪的过程也可以表述为获得原始图像估计值F(i , j)的过程。X(i , j)和F(i , j)的偏差越小,图像去噪效果越好。
本文将均方误差作为损失函数,其定义如下:

其中,Fk(i , j)表示去噪后的图像,Xk(i , j)表示原始图像,n是每个训练批次的样本数量,w和h分别表示每个样本的宽度和高度。虽然本文是对彩色图像进行去噪,但也是对RGB通道分别依次进行,一次处理的图像也是单通道的。
为了计算函数L的最小值,新模型采用Adam算法迭代优化和更新参数。本文提出的卷积自动编码器的基本结构是由一系列卷积层和反卷积层组成,编码器部分是一些卷积层,解码器部分是一些反卷积层,并且添加跳跃连接将卷积层对反卷层连接起来。如图1和图2所示。
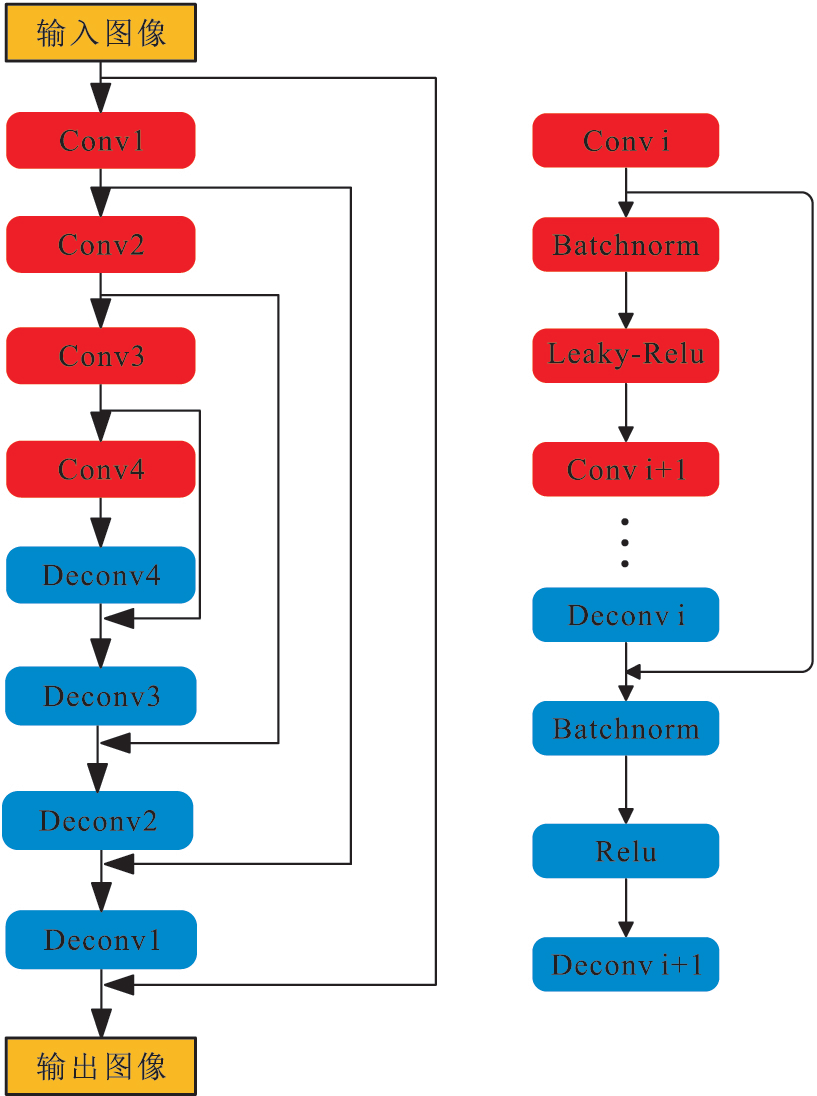
图1 原算法 CNN网络结构
Fig.1 Original CNN networks structure
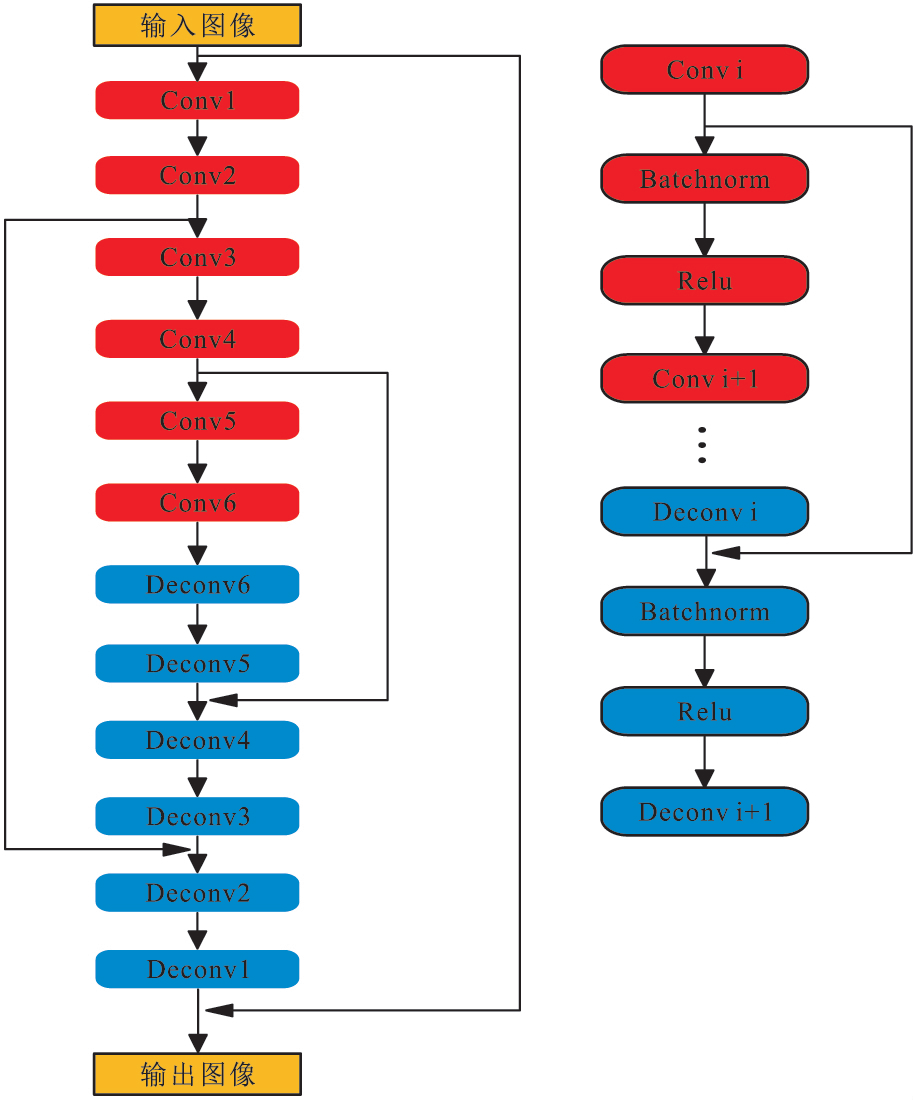
图2 新的 CNN网络结构
Fig.2 New CNN networks structure
与文献【11】相比较,笔者改变了卷积层的激活函数和整个网络跳跃连接的方式,并在学习率的选取上有了一定改进。本文卷积神经网络模型的输入是含噪声的彩色图像,包含RGB3个通道,输出是去噪后的彩色图像。网络的隐含层由4个卷积层和4个反卷积层构成,为了使网络能够更好地收敛,加速训练并且提升性能,在前4个卷积层都使用了Batch normalization和Leaky-Relu激活函数。在后4个反卷积层都使用了Batch normalization和Relu激活函数。并增加跳跃连接操作,将卷积层的映射信息直接添加到反卷积层。卷积核的大小为3x3,填充方式为Same卷积,步长设置为1,这样卷积前和卷积之后的图像大小是一致的。对于RGB图像,分别对3个通道进行卷积,然后再将其生成的图片进行合并。
2.2 网络设置
2.2.1 输入和输出层
卷积网络使用的是端对端的设置,输入与输出均是彩色图像,且输入图像与输出图像的尺寸大小一致。其中输入是含有噪声的图像,在经过输入层之后,含有噪声的图像就会转变成一个数值矩阵。在隐含层对噪声图像进行学习,而输出层则采用残差学习方法,得到噪声图像矩阵的估计值,并把它转变成去噪图像的输出。在模型训练过程当中,输出层得到噪声图像矩阵的估计值之后,将进行损失函数的计算、改进权值并将其返回到网络中,进行相关参数的优化。
2.2.2 卷积层和反卷积层
虽然CNN可以通过增大感受野或者增加层数来提高性能,但是复杂的CNN需要的训练参数更多,并且模型复杂。相对于层数更少的CNN,不仅训练时间会增加,图像去噪所消耗的时间也会增加,还易于产生过拟合现象。本文在文献【11】的基础上减少了4个隐含层,本文设计的网络由4层卷积层和4层反卷积层组成,并且在卷积层使用了Batch normalization和Leaky-Relu激活函数。在Relu函数的基础上,有学者提出了Leaky Relu函数,它不仅具有Relu函数的优点,而且可以修正数据分布。在网络的训练过程中,阈值为负的神经元也得到了训练和更新。这样保留了阈值为负的神经元信息,同时也提升了网络的拟合能力。在反卷积层则使用了Batch normalization和Relu激活函数。这样的设计结构在简化模型、减少参数的基础上,保证了图像去噪的性能。
2.2.3 批量正则化层
池化的方法在图像识别和分类应用中有着广泛应用,能够对特征提供平移不变性,也可以减少训练参数。但对于图像去噪,池化层的操作可能会使图像丢失部分有效的信息。因此,本文没有使用池化的操作,而是选择了用批量正则化层对卷积层和反卷积层获得的特征进行归一化处理,使网络能够进行更好的收敛。
2.2.4 跳跃连接
对于浅层网络来说,噪声图像经过卷积和反卷积的过程便能得到复原图像,随着网络层数的增加,即使有反卷积层,依旧会丢失部分图像细节.在优化过程中,深度网络经常会遇到梯度消失的问题,变得更加难以训练。为了解决这个问题,我们添加了跳跃连接结构,通过跳跃连接把大量的特征图传输到反卷积层,这样有助于反卷积层恢复更清晰的图像,同时也有利于将梯度反向传播到底层,这使得训练更深层次的网络变得更加容易。
2.3 网络参数设置
本文所设计CNN结构参数如表1所示,简记卷积、批次归一化和Leaky-Relu激活函数为CBLR,反卷积、批次归一化和Relu激活函数为DCBR。
噪声图像经过输入层之后转化为矩阵送往卷积层。噪声图像是RGB彩色图像,传输到卷积层时,将3个通道分别进行传输。等一个颜色通道完成之后,再输入下一个颜色通道,最后再将处理好之后的3个通道的图片进行重构。在设置卷积核时,大尺寸的卷积核能够拥有更大的感受野,可以捕获到更多信息。但这样也意味着网络会有更多的参数,由此导致计算量增加。参考 VGG网络(Visual Geometry Group)的性能,本文CNN所用卷积核尺寸为3x3,步长设置为1。本文网络训练的迭代次数设置为2000。在选择学习率时,原文献的学习率为10-4,通过数值10-5级别时,图像去噪效果更好,因而本文学习率设置为2x10-5。
本文梯度下降优化方法使用 Adam方法,Adam方法能基于训练数据迭代地更新神经网络权重。它同时具备AdaGrad和RMSProp算法的优点,即高效的计算,所需内存少,可以很好地处理稀疏梯度和非稳态问题等。

表1 CNN网络参数
Tab.1 CNN network parameters
3. 实验结果与分析
3.1 实验设置
本次实验环境包括硬件设备和软件配置两部分,其中硬件配置GPU是NVIDIA Persistence-M,运行内存为6G。操作系统为CentOS7.3, CUDA10。编程语言为python3.6.5,其深度框架是pytorch1.2。
本次实验使用的数据集是ImageNet数据库和一些自然图片,本文随机选取了其中10张图片作为测试数据集,选取50张图片作为训练数据集。对图像的去噪效果使用主观观察和客观分析相结合的方法,用峰值信噪比(peak signal-to-noise ratio,PSNR)作为评判去噪效果的定量指标。
3.2 实验结果分析
本文以文献【11】的算法为对比,评价指标由主观观察、峰值信噪比和运行时间组成。我们对测试图像分别添加标准差为10、20、30的噪声,并进行去噪。实验结果如图3-图6和表2所示。
如图3和图4所示,当添加的高斯噪声标准差为10和30时,随着迭代批次的增加,本文算法的均方误差与原算法的均方误差都有所降低,但是在批次量小于250时,本文算法的均方误差下降得更快一些,并且原算法与本文算法的均方误差总体上保持着波动下降的趋势。
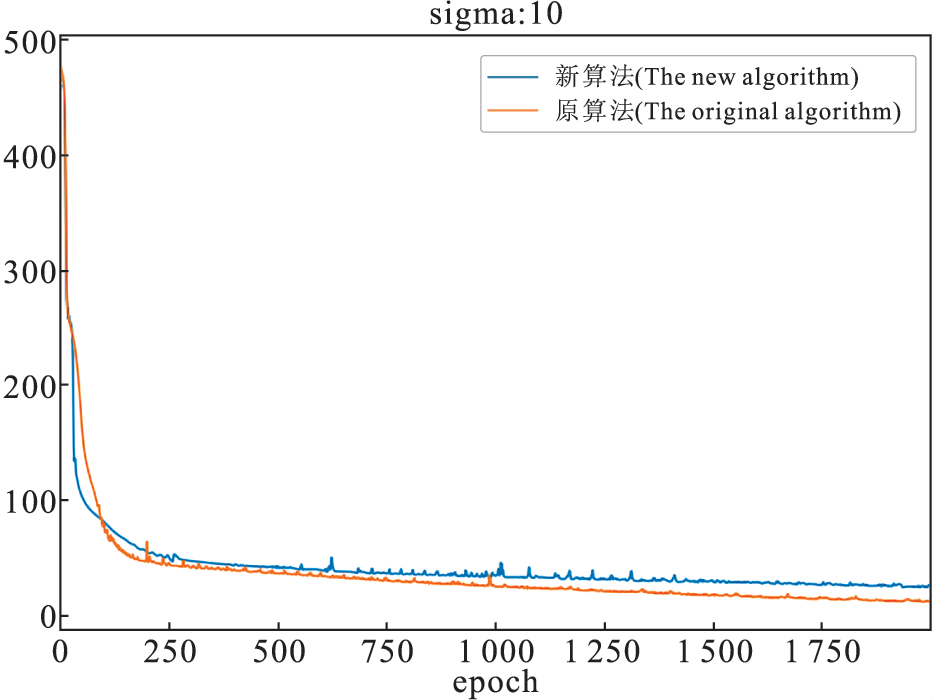
图3 对图像添加标准差为10的训练损失误差图
Fig.3 Image training loss error with standard deviation of 10
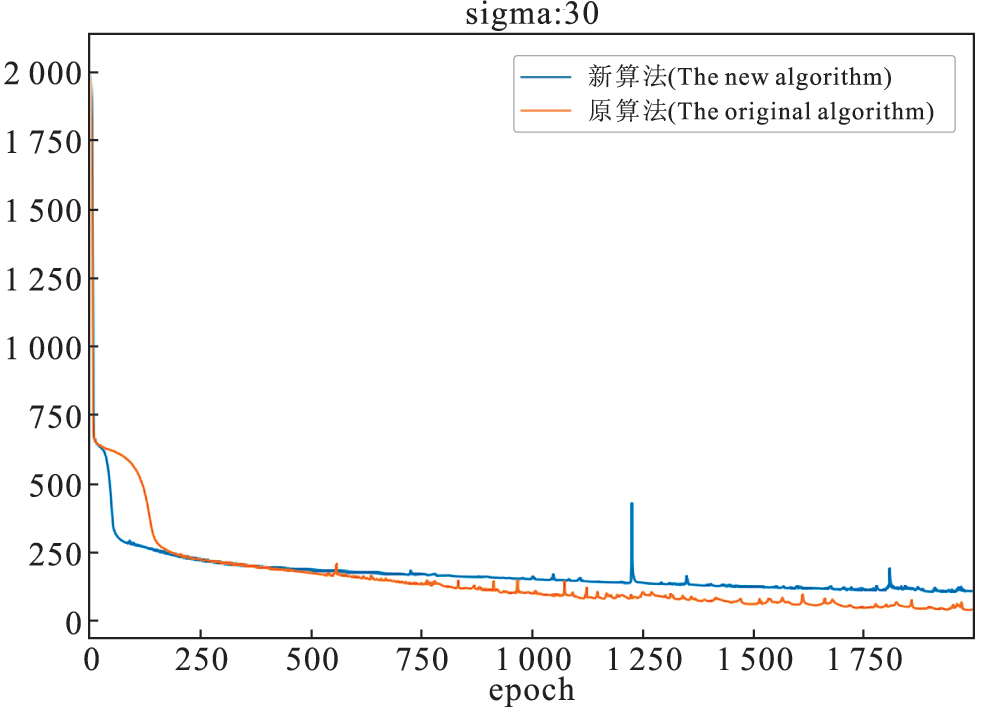
图4 对图像添加标准差为30的训练损失误差图
Fig.4 Image training loss error with standard deviation of 30
由图5和图6可见,随着高斯噪声标准差的增大,两种方法的去噪效果均有所减弱。从图5可以看出,处理标准差为10的图像时,本文算法与文献【11】算法都很好地保护了图像的细节信息,并且图像平滑自然。图5黑色鸭子白色脖颈上的噪声,原算法比本文去除得更加彻底,本文算法处理之后还是有零星的噪声点。但是在处理黄色小树懒身上的噪声时,本文算法去噪之后的视觉效果更好,处理后噪声点更少。从图6可以看出,当添加标准差为30的高斯噪声时,新算法的视觉效果明显好于原算法,不论是黑色鸭子、还是小松鼠,新算法去噪之后图像更加平滑,零星的噪声点少,并且很好地保护了图像边缘。
从表2可见,随着噪声的增大,本文算法和文献【11】方法的去噪效果均有所减弱,本文算法在处理噪声标准差为10和噪声标准差为20的图像时,峰值信噪比有了明显降低。但噪声标准差为30的图像与噪声标准差为20的图像之间的峰值信噪比下降幅度不大。不论是在噪声标准差为10、20、30时,本文的峰值信噪都远高于原算法,并且本文神经网络的深度也比原算法少4层,运行时间上更快一些。

图5 对图像添加标准差为10的去噪效果图
Fig.5 Image denoising effect map with standard deviation of 10

图6 对图像添加标准差为30的去噪效果图
Fig.6 Image denoising effect map with standard deviation of 30
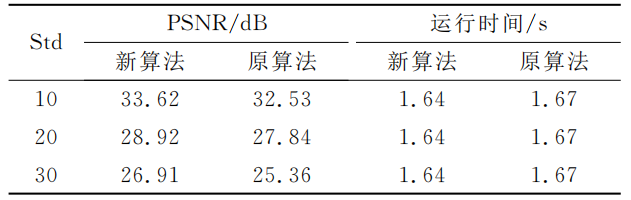
表2 10张测试图像平均峰值信噪比(PSNR)和程序运行时间
Tab.2 Average peak signal-to-noise ratio of 10 natural images and running time of programs

表3 10张测试图像平均峰值信噪比(PSNR)和程序运行时间(调整参数后)
Tab.3 Average peak signal-to-noise ratio of 10 natural images
and running time of programs(after parameters adjustment)
3.3 调参结果
对于原先的12层模型,本文还有一种调整参数后的模型,即跳跃连接不是直接将卷积层与反卷积层相加,而是在卷积层和反卷积层之前添加权重系数。如图1所示,原算法Deconv5层后的激活函数为f(Deconv5+Conv4),可以将其修改为f(Deconv5+0.5xConv4+0.5xConv3)。经过数值实验,本文发现去噪效果略有提升,结果如表3所示。
4. 结论
提出了一种新的自编码卷积神经网络图像去噪的方法,它能够有效进行图像去噪。在原算法的基础上,改变了卷积层的激活函数和整个网络跳跃连接的方式,并在学习率的选取上有了一定改进。这样的结构设计简单,程序处理时间更少,并且峰值信噪比较原模型高。本文仅将该模型用于自然图像的去噪,后期还可能用于医学图像和卫星图像的去噪,以及其他图像的复原工作。
参考文献
[1] HIGAKI T, NAKAMURA Y, ZHOUJ, et al. Deep learning reconstruction at CT, phantom study of the Image characteristics[J]. Academic Radiology, 2020, 27(1):82-87.
[2] SALIM B, PATRICK L , AMINEBS. PDE-based efficient method for colour image restoration[J]. Computers and Mathematics with Applications, 2017, 4(3): 577-590.
[3] BRISK R, BONDR, BANKSE, et al. Deep learning to automatically interpret images of the electrocardiogram: Do we need the raw samples[J]. Journal of Electrocardiology, 2019, 57:S65-S69.
[4] DIMITRIOU N, ARANDJELOVICO, CAIEP D. Deep learning for whole slide image analysis: an overview[J/OL]. [2020-03-25]. https://doi.org/10.3389/fmed.2019.00264.
[5] 张泽浩, 周卫星. 基于深度学习的图像去雾算法[J]. 华南师范大学学报(自然科学版), 2019, 51(3) :123-128.
[6] 杨海清, 徐勇军, 王明雪. 基于深度强化学习和循环卷积神经网络的图像恢复算法[J] . 高技术通讯, 2019, 29(5): 432-437.
[7] BENGIO Y. Learning deep architectures for AI[J]. Foundations and Trendsin Machine Learning, 2009, 2(1): 121-127.
[8] JAIN V, SEUNG HS. Natural image denoising with convolutional networks[C]// Advances in Neural Information Processing Systems. New York: Curran Associates Inc, 2009: 769-776.
[9] XIE J, XU L,CHEN E. Image denoising and inpainting with deep neural networks [C]// International Conference on Neural Information Processing Systems. New York:Curran Associates Inc, 2012: 341-349.
[10] 陈琦, 潘伟民. 基于自编码器的图像去噪设计与实现[J]. 新疆师范大学学报(自然科学版), 2018, 37(2): 80-85.
[11] DONGJ F, MAO XJ, SHEN C H, et al. Learning deep representations using convolutional auto-encoders with symmetric skip connections[C]// 2018 IEEE International Conferenceon Acoustics, Speechand Signal Processing(ICASSP). WashingtonDC: IEEE, 2018: 3006-3010.
[12] CUIZ, CHANG H, SHANS, et al. Deep network cascade for image super-resolution[C]// European Conferenceon Computer Vision. Switzerland: Springer, Cham, 2014: 49-64.
1. 杭州师范大学理学院,浙江杭州,311121
2. 华院计算技术(上海)股份有限公司【原华院数据技术(上海)有限公司】,上海,200436