小朋友们好,大朋友们好!
我是猫妹,一名爱上Python编程的小学生。
欢迎和猫妹一起,趣味学Python。
今日主题
如何用Python,抓取并分析2023中国大学排名数据。
用到的Python库有requests、bs4。
requests库
requests库是Python基于urllib,采用Apache2 Licensed开源协议的HTTP库。
它比urllib更加方便,完全满足HTTP测试需求。
Requests的哲学是以PEP20的习语为中心开发的,它比urllib更加Pythoner。
可以通过pip install requests 安装 requests库。
举个简单的例子:
我们日常看到的网页是这样的
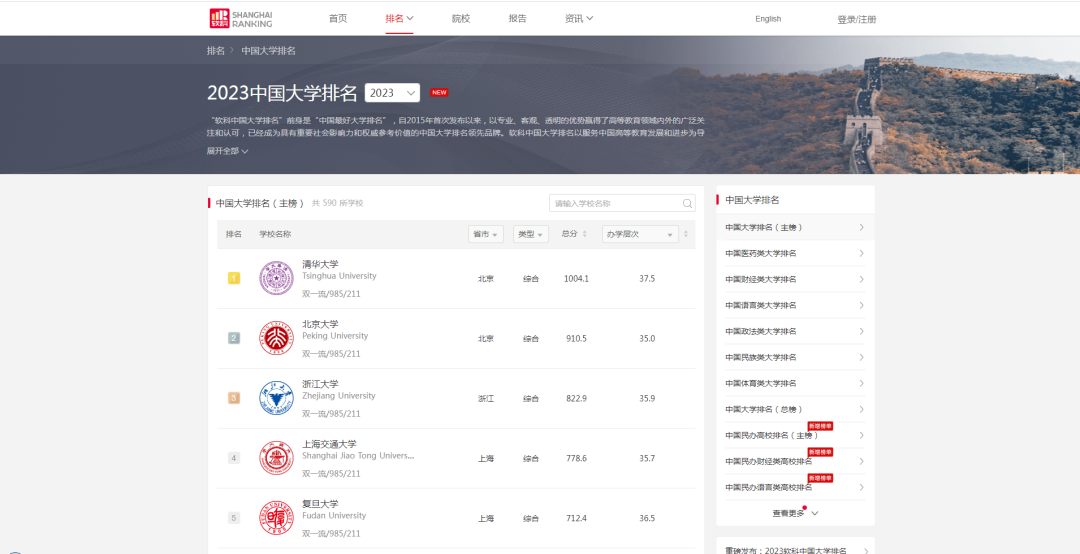
我们看到的是部分信息,还有许多信息看不到的,比如排版、交互等。
如果要看更多信息,要在哪里看呢?
当然是网页源代码啦!
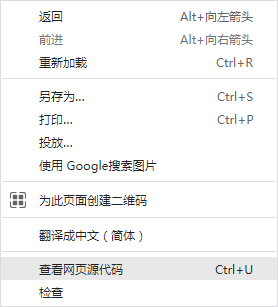
网页源代码长这样,这里面是前端信息,主要是html标签等。

看到网页源代码后,第一印象是啥?
很多,很复杂,很难手写。
有很多设计工具可以辅助生成网页源代码的。
要解析网页源代码,可以用Python,比如借助于bs4库。
bs4库
bs4 全名 BeautifulSoup,是编写 python 爬虫常用库之一,主要用来解析 html 标签。
可以通过pip install beautifulsoup4安装bs4 库。
说得简单点,bs库就是分析上述字符串,把自己感兴趣的信息提取出来。
将网页源代码解析后的信息是这样的:
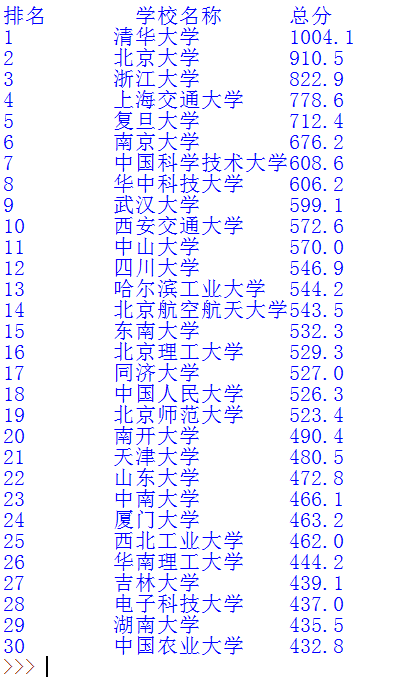
测试代码
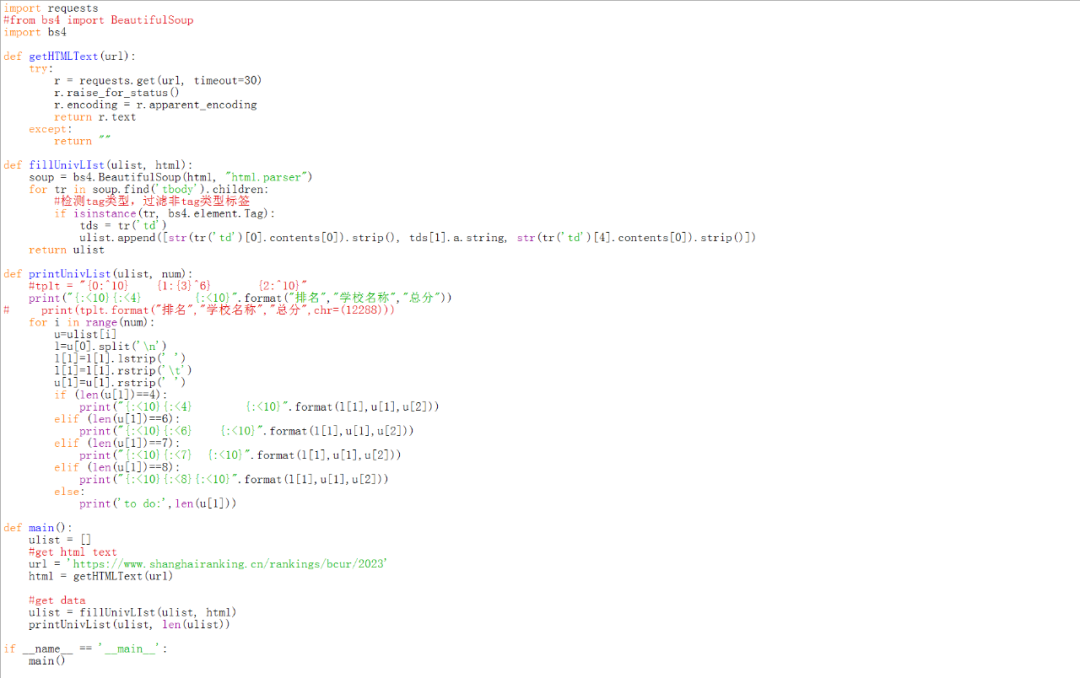
对中国大学排名,感兴趣的小伙伴,可以直接网站上浏览哈


好了,我们今天就学到这里吧!
如果遇到什么问题,咱们多多交流,共同解决。
我是猫妹,咱们下次见!