问题:抓取最好大学网上中国大学排名榜。网址:最好大学网
实现输出: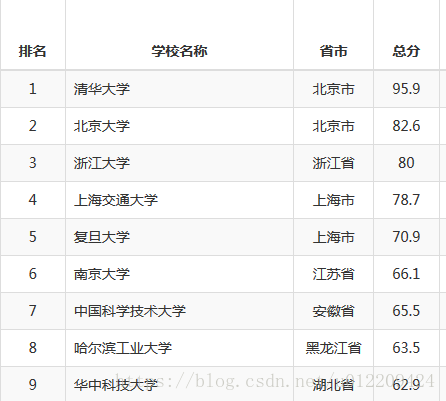
要求:使用requests库和BeautifulSoup库实现。
# scrapy the rank of China university
import requests
from bs4 import BeautifulSoup
import bs4
# 获取内容
def getText(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}
try:
r = requests.get(url, headers=headers, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
# 解析内容
def parserText(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr.find_all('td')
ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string])
return ulist
# 打印内容
def printText(ulist, num=20):
# 默认打印前20名高校
tplt = '{0:^4}{1:{4}^20}{2:^8}{3:^4}'
print(tplt.format('排名', '学校名称', '地区', '总分', chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
# 主函数
def main():
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getText(url)
uinfo = []
parserText(uinfo, html)
printText(uinfo, num=100)
main()学习点:
1.在发送request请求时,使用try···except···语句块,捕获请求异常,并使用r.raise_for_status()获取HTTP状态码异常。
2.使用for tr in soup.find(‘tbody’).children 获取html中tbody子标签中tr标签内容,并使用isinstance判断tr是否是一个标签。
3.find_all和find的不同使用,前者返回结果列表集,后者返回一个字符串对象。同时tds = tr.find_all(‘td’) 等价于tds = tr.(‘td’)
4.append在列表中新增一个元素,该元素可以是字符串、列表、集合、字典等。如ulist.append()新增一个列表元素
5.format格式化输出中文时,字符长度不足时会使用英文状态下空格填充,导致出现输出格式错乱,修改为使用中文状态下空格填充,中文状态空格unicode编码为chr(12288)
6.使用中文空格填充方法,{1:{4}^20},4代表序号为4的第五个元素,因此将chr(12288)放在最后。
扩展:既然可以抓取2016年大学排名,自然也可以抓取2017年大学排名,是否如此呢?将url变量修改为:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2017.html
再次运行脚本,发现脚本报错,提示NoneType。对脚本内容进行仔细走查,发现代码没有问题,再次运行还是报错。打印soup内容发现,在抓取2017年的大学排名时,soup.find(‘tbody’)结果如下:
<tr class="alt"><td>1<td><div align="left">清华大学</div></td><td>北京</td><td>94.0 </td><td class="hidden-xs need-hidden indicator5">100.0 </td><td class="hidden-xs need-hidden indicator6" style="display:none;">97.70%</td><td class="hidden-xs need-hidden indicator7" style="display:none;">40938</td><td class="hidden-xs need-hidden indicator8" style="display:none;">1.381</td><td class="hidden-xs need-hidden indicator9" style="display:none;">1373</td><td class="hidden-xs need-hidden indicator10" style="display:none;">111</td><td class="hidden-xs need-hidden indicator11" style="display:none;">1263428</td><td class="hidden-xs need-hidden indicator12" style="display:none;">613524</td><td class="hidden-xs need-hidden indicator13" style="display:none;">7.04%</td></td></tr>抓取2016年的大学排名时,soup.find(‘tbody’)结果如下:
<tr class="alt"><td>1</td>
<td><div align="left">清华大学</div></td>
<td>北京市</td><td>95.9</td><td class="hidden-xs need-hidden indicator5">100.0</td><td class="hidden-xs need-hidden indicator6" style="display:none;">97.90%</td><td class="hidden-xs need-hidden indicator7" style="display:none;">37342</td><td class="hidden-xs need-hidden indicator8" style="display:none;">1.298</td><td class="hidden-xs need-hidden indicator9" style="display:none;">1177</td><td class="hidden-xs need-hidden indicator10" style="display:none;">109</td><td class="hidden-xs need-hidden indicator11" style="display:none;">1137711</td><td class="hidden-xs need-hidden indicator12" style="display:none;">1187</td><td class="hidden-xs need-hidden indicator13" style="display:none;">593522</td></tr>可以对比出两者的不同,在2017年的html中,排名td标签缺少了闭合标签,导致在ulist.append([tds[0].string])时获取到的是None,所以在使用ulist打印时,会出现NoneType错误。修改代码如下:
# 解析内容
def parserText(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
#print(soup.find('tbody'))
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr.find_all('td')
ulist.append([tds[1].string, tds[2].string, tds[3].string])
return ulist
# 打印内容
def printText(ulist, num=20):
# 默认打印前20名高校
tplt = '{0:^4}{1:{4}^20}{2:^8}{3:^4}'
print(tplt.format('排名', '学校名称', '地区', '总分', chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(i, u[0], u[1], u[2], chr(12288)))最终能够正确打印。
从该例中可以看出,使用标签方法获取标签内容,对HTML的格式有严格要求,一旦出现html格式错误,就会导致脚本运行错误。