随着云计算和容器技术的发展,以docker为核心的容器技术迅速在开发者和科技公司中应用,Kubernetes凭借丰富的企业级、生产级功能成为事实上的容器集群管理系统。可是k8s的通用性削弱了调度算法的定制性,本文将调研定制化调度算法的方法,并且给出一个开源实现。
k8s与调度器架构
图1-1是Kubernetes的整体架构图,集群节点分为两种角色:Master节点和Node节点。Master节点是整个集群的管理中心,负责集群管理、容器调度、状态存储等组件都运行在Master节点上;Node节点是实际上的工作节点,负责运行具体的容器。
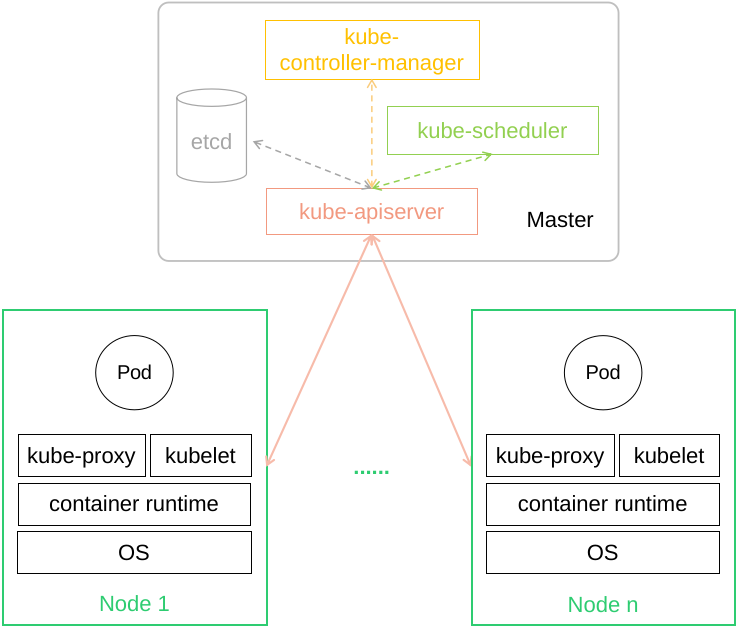
图 1-1 Kubernetes整体架构
Kubernetes调度器是独立运行的进程,内部运行过程从逻辑上可以分为多个模块。图1-2展示了默认调度器内部包含的具体模块,配置模块负责读取调度器相关配置信息,并且根据配置内容初始化调度器。
优先队列模块是一个优先堆数据结构,负责将待调度Pod根据优先级排序,优先级高的Pod排在前面,调度器会轮询优先队列,当队列中存在待调度Pod时就会执行调度过程[1]。
调度模块由
算法模块、Node缓存和调度扩展点三部分组成,算法模块提供对Node进行评分的一系列基础算法,比如均衡节点CPU和内存使用率的NodeResourcesBalancedAllocation算法,算法模块是可扩展的,用户可以修改和添加自己的调度算法;Node缓存模块负责缓存集群节点的最新状态数据,为调度算法提供数据支撑;调度扩展点由一系列扩展点构成,每个扩展点负责不同的功能,最重要的扩展点是Filter、Score和Bind这三个扩展点。最后是绑定模块,负责将调度器选择的Node和Pod绑定在一起。
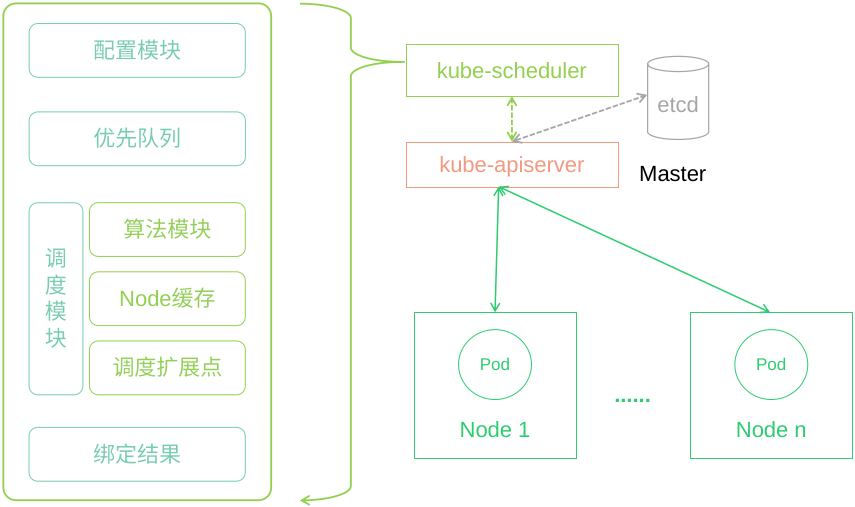
图 1-2 Kubernetes调度器架构
Kubernetes调度器代码采用可插拔的插件化设计思路,包括核心部分和可插拔部分。图1-2中的配置模块、优先队列和Node缓存是核心部分,算法模块、调度扩展点属于可插拔部分。这种插件化设计允许调度器一些功能通过插件的方式实现,方便代码修改和功能扩展,同时保持调度器核心代码简单可维护[2]。
图1-3列出了调度器扩展点模块中包含的具体扩展点。Pod的调度过程分为调度周期和绑定周期,调度和绑定周期共同构成Pod的调度上下文。调度上下文由一系列扩展点构成,每个扩展点负责一部分功能,最重要的扩展点是调度周期中的预选(Filter)和优选(Score)扩展点和绑定周期中的绑定(Bind)扩展点。
预选扩展点负责判断每个节点是否能够满足Pod的资源需求,不满足就过滤掉该节点。优选扩展点部分会对每个Pod运行默认的评分算法,并且将最终评分加权汇总,得到最后所有节点的综合评分;调度器会选择综合评分最高的节点,如果有多个节点评分相同且最高,调度器会通过水塘采样算法在多个节点中随机选择一个作为调度结果,然后将该节点上Pod申请的资源用量进行保留操作,防止被其它Pod使用。在绑定周期中,调度器将Pod绑定到评分最高的节点上,这一步本质是修改Pod对象中节点相关的信息,并且更新到存储组件etcd中。
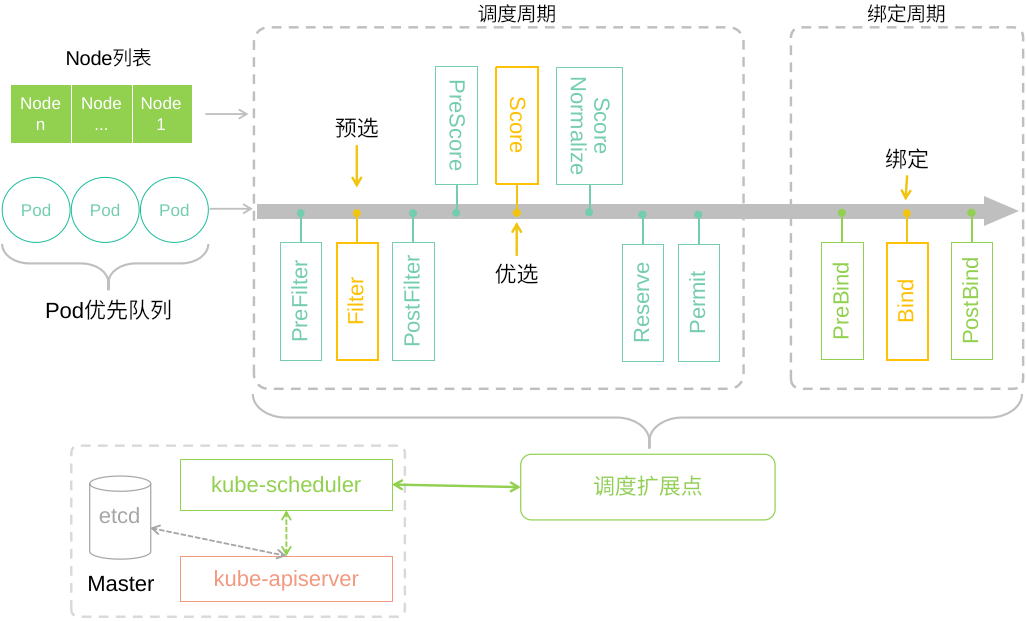
图 1-3 Kubernetes调度器扩展点架构
定制化算法方案
如果要实现自定义调度算法,主要有三种方案:
修改默认调度器的源代码,加入自己的调度算法,然后重新编译和部署调度器,论文kcss[3]和kubecg[4]中的调度器研究基于此方案实现;
开发自己的调度器,和默认调度器同时运行在集群中;
基于Kubernetes Scheduler Extender机制[5],在扩展调度器中实现自定义算法,论文dynamic IO[6]中的算法实现基于这种方案。
上述三种自定义调度算法实现方案的优缺点见表2-1。综合来讲,
方案1改动最小,但是这样做会破坏开源软件的可维护性,当Kubernetes主干代码更新时,改动后的调度器要和上游代码保持一致,这会带来大量的维护和测试工作。
方案2是实现自己的调度器,并且在集群中运行多个调度器,多个调度器之间没有集群资源数据同步,存在并发调度数据竞争和数据不一致的问题。
方案3需要默认调度器通过API和Extender交互,新增的网络请求会增加整个调度过程的耗时。
表2-1 自研调度算法方案对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| 方案1:修改调度器源代码 | 改动小 | 破坏源代码、不好维护 |
| 方案2:运行多个调度器 | 不改动源代码 | 存在数据竞争、不一致 |
| 方案3:开发扩展调度器 | 不改动源代码 | 存在网络耗时 |
本文的调度器实现采用方案3,设计并开发符合Scheduler Extender机制和API规范的扩展调度器,将其命名为Liang。代码2-1是扩展调度器JOSN格式的策略配置文件,通过配置文件参数将该策略文件传递给Kubernetes默认调度器,其中urlPrefix表示扩展调度器Liang运行后监听的API地址,prioritizeVerb表示优选扩展点在扩展调度器中的路由。当默认调度器在优选扩展点运行完评分插件后会发送HTTP POST网络请求到Liang的API地址,并将Pod和候选节点信息放在HTTP Body中一起传递过去。接收到POST请求后,扩展调度器Liang会根据评分算法对节点进行评分并将结果返回给默认调度器。
{
"kind": "Policy",
"apiVersion": "v1",
"extenders": [
{
"urlPrefix": "http://localhost:8000/v1",
"prioritizeVerb": "prioritizeVerb",
"weight": 1,
"enableHttps": false,
"httpTimeout": 1000000000,
"nodeCacheCapable": true,
"ignorable": false
}
]
}代码 2-1
图2-1是带扩展的默认调度器(kube-scheduler)启动过程,通过kube-policy.json配置文件将扩展调度器Liang的配置信息告诉默认调度器。
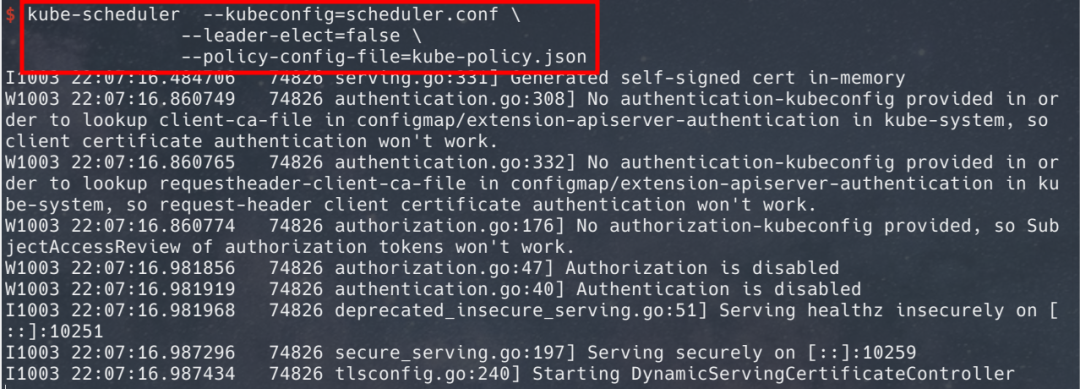
图 2-1 扩展调度器通过配置文件传递给默认调度器启动
扩展调度器Liang
扩展调度器Liang独立于Kubernetes默认调度器,Liang的模块设计和组织架构如图3-1所示,包括多维资源采集存储和API服务两大部分。多维资源数据采集通过在集群中运行Prometheus和node-exporter实现,扩展调度器Liang负责从Prometheus获取多维指标然后运用调度算法,将结果返回给默认调度器。
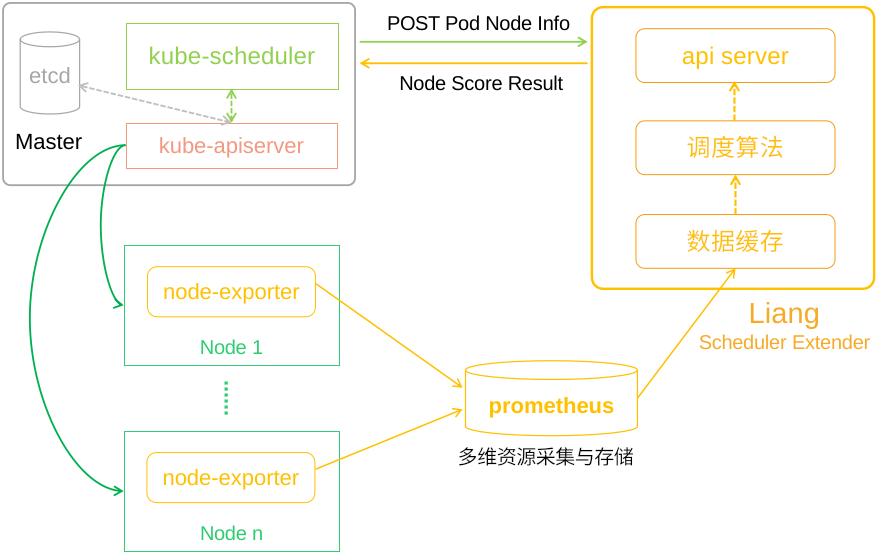
图 3-1 扩展调度器Liang整体架构
api server模块,负责实现符合扩展调度器数据格式和传输规范的API接口,Liang接收到Kubernetes的评分请求后,解析得到请求中的Pod和候选节点信息,作为参数传递给内部的调度算法,得到候选节点的评分结果并返回给默认调度器。
调度算法模块,扩展调度器Liang的核心模块,负责实现自定义的调度算法。得益于扩展调度器机制,Liang中可以实现多个自定义调度算法。本文主要设计并实现了BNP和CMDN两个调度算法。
数据缓存模块,主要功能有两个:
通过请求Prometheus的API得到整个Kubernetes集群中所有节点的状态数据。
实现基于内存的指标数据缓存机制,提供指标数据的写入和读取接口,提高算法运行时获取多维指标数据的速度。
Liang使用Go语言开发,代码量约3400行,开源网址为Liang开源地址[7]。
表3-1是扩展调度器是否使用缓存机制和默认调度器做出调度决策的耗时对比,调度耗时通过在Kubernetes调度器源代码中打印时间戳的方式获取,分别运行9次然后计算平均值。从表3-1中可以看到,默认调度器做出调度决策的耗时非常小,不到1ms。加上扩展调度器和缓存机制的情况下,平均调度决策耗时为4.439ms,比默认调度器增加了约3ms,增加的时间主要是默认调度器与扩展调度器Liang之间网络请求耗时以及Liang运行调度算法所需的时间。
当扩展调度器不加缓存机制时,每次做出调度决策的平均耗时为1110.439ms,调度耗时迅速增加超过100倍,主要是每次做出调度决策都要请求Prometheus计算和获取集群中的指标数据。因此,扩展调度器加上缓存机制可以避免请求Prometheus带来的网络请求时间,降低扩展调度器的决策时间,提升了扩展调度器的性能。
表 3-1 不同调度器架构决策耗时
| 调度类型 | 平均决策耗时 |
|---|---|
| 默认调度器 | 0.945ms |
| 扩展调度器-使用缓存 | 4.439ms |
| 扩展调度器-不使用缓存 | 1110.439ms |
BNP算法
BNP算法在Liang中实现,它将网络IO使用情况纳入k8s调度算法的考量,能够均衡集群中的网络IO用量。
图3-2是实验中默认调度算法和BNP算法中,整个集群中网络IO资源的变化情况,每部署一个Pod统计一次数据,共部署九个Pod。可以明显看到,BNP实验中网络IO资源要比默认调度算法分配更均衡。
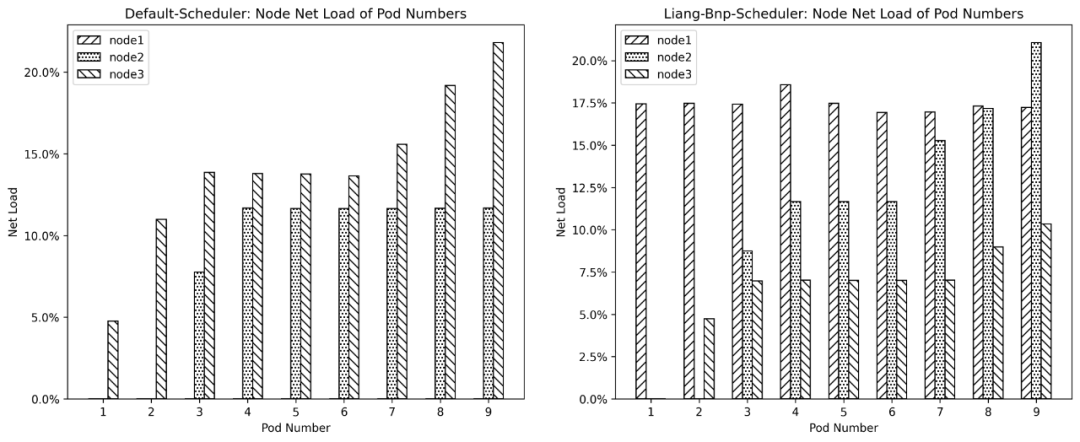
图 3-2 bnp算法网络IO使用率变化情况
CMDN算法
CMDN算法在Liang中实现,它的目标是让集群中的多维资源分配更加均衡或者更加紧凑,核心步骤是针对CPU、内存、磁盘IO和网络IO以及网卡带宽这五个指标进行综合排序,选择最佳Node部署Pod。图3-3是实验中CPU使用率变化对比情况,可以明显看到,CMDN均衡策略下CPU使用率均衡程度要比默认调度算法分配更均衡。
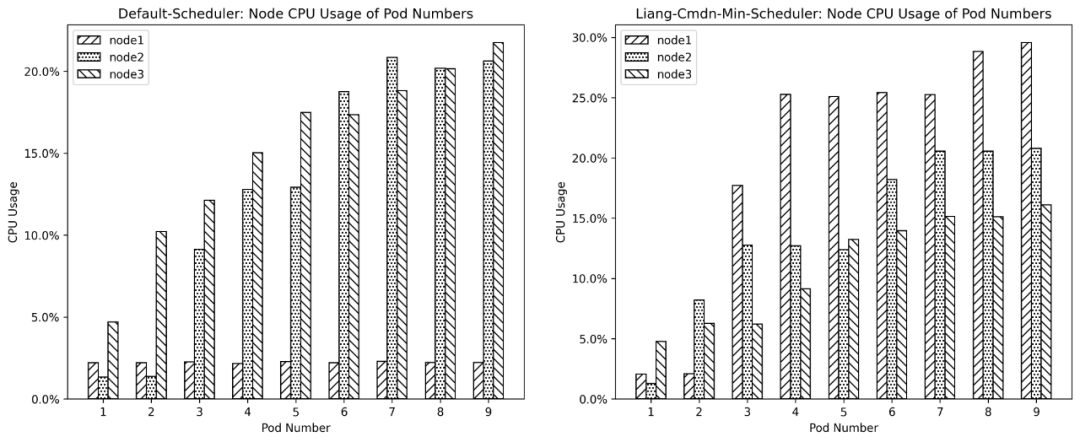
图 3-3 cmdn算法均衡策略下CPU使用率变化情况
总结
Kubernetes调度算法的通用性削弱了算法的定制性。本文研究了k8s调度器架构和扩展机制,对比了三种定制化调度算法方案,选择扩展方案实现扩展调度器Liang,并在Liang中实现了两个调度算法BNP和CMDN用于展示定制化算法能力。
扩展方案极大丰富了定制化调度算法的能力,可以满足非常多定制化场景的需求。同时也需要注意,定制调度算法往往需要更多的数据,这就需要在k8s集群中额外部署数据采集模块,增加了运维成本,降低了定制化调度算法的通用性。
参考资料
[1]
当队列中存在待调度Pod时就会执行调度过程: http://dx.doi.org/10.24138/jcomss.v16i1.1027
[2]同时保持调度器核心代码简单可维护: https://v1-20.docs.kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/
[3]kcss: https://doi.org/10.1007/s11227-020-03427-3
[4]kubecg: https://doi.org/10.1002/spe.2898
[5]Kubernetes Scheduler Extender机制: https://github.com/kubernetes/community/blob/master/contributors/design-proposals/scheduling/scheduler_extender.md
[6]dynamic IO: https://doi.org/10.1145/3407947.3407950
[7]Liang开源地址: https://github.com/adolphlwq/liang