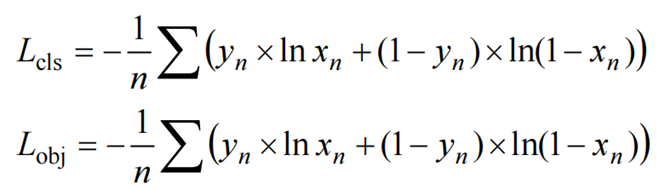1. YOLOV5的前处理Anchor的改进
1.1 Anchor生成的改进
-
首先YOLOV3/V4/V5都是根据训练的数据集来生成anchor, 就是在训练之前用一个独立的程序去计算Anchor, 但是还不够好
-
因为自动生成的anchor是拿来整个数据集去做的,但是我们知道目标检测训练的时候是分batch训练的, YOLOV5这边把这个功能嵌入到训练的流程中, 也就是说YOLOV5每一个batch会生成一次anchor更加贴近我们的数据集。
1.2 Anchor生成的流程
-
载如当前batch的全部Width, Height
-
将每张图片中的w, h的最大值等比例缩放到指定大小, 较小的边也相应的缩放
- 这里的指定大小是一个超参数,可以通过更改训练配置文件中的 img_size 参数来指定输入图像大小,例如 img_size=640 表示输入图像的大小为 640x640 像素。
-
将训练集中标注的ground truth bbox(GT),经过缩放和坐标变换后得到的绝对坐标形式。
-
筛选 bboxes,保留 w、h 都大于等于 2 像素的 bboxes
- 在训练过程中,过小的目标物体(如像素数少于2个)不太可能被检测到,因为其大小非常小,难以在图像中区分出来。此外,过小的目标也会增加训练难度,可能会对模型的训练效果产生负面影响。因此,通常会将较小的目标过滤掉,只保留尺寸较大的目标进行训练。在 YOLOv5 中,将 w、h 都大于等于 2 像素的 bboxes 作为训练数据,以提高训练的效率和准确率。
-
使用 k-means 聚类得到 n 个 Anchors;
-
使用遗传算法随机对 Anchors 的 w、h 进行变异,如果变异后效果变得更好就将变异后的结果赋值给 Anchors,如果变异后效果变差就跳过。
2. YOLOV5前处理的改进 Letterbox
-
前期 YOLO算法中常用 416×416、608×608 等尺寸,比如对 800×600 的图像进行缩放和填充。如图所示,YOLOv5 作者认为,在项目实际应用时,很多图像的长宽比不同,因此均直接进行缩放填充后,两端的灰边大小会不同,而如果填充的比较多,则存在信息的冗余,也可能会影响推理速度。
-
YOLOv5的Letterbox函数对原始图像进行自适应的缩放和填充,使其能够被最小的32倍数整除,同时添加最少的灰边,以减少信息冗余和推理速度的影响。这样可以有效地处理不同大小和长宽比的图像,并保证网络的稳定和高效。
3. 一个案例看计算流程 超参数image_size设置416
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lY0nFxQV-1679577573911)(null)]
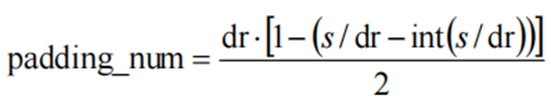
-
首先计算比例: min(416/800, 416/600) = 0.52
-
计算收缩后的图像长宽: w, h = 800 x 0.52, 600 x 0.52 = 312, 480
-
计算要填充的像素: padding_num = 0.2 x (32 x (1 - 312 / 32 - int(312 / 32))) = 4
-
最后知道上下填充的像素是4, 这个图最后的大小就是416 x (316 + 4 + 4) = 416 x 320
-
总结: 通过超参数来计算宽和宽边需要填充的像素
4. YOLOV5的激活函数的SiLU
-
Mish和SiLU是两种不同的激活函数,虽然它们的形状相似,但是它们的导数和函数值的计算方法是不同的。
-
Mish激活函数是由Misra在2019年提出的一种激活函数,它的公式为:
f(x) = x * tanh(softplus(x))
其中,softplus函数定义为:softplus(x) = ln(1 + exp(x))。 -
SiLU激活函数是由Elsken在2018年提出的一种激活函数,它的公式为:
f(x) = x * sigmoid(x)
其中,sigmoid函数定义为:sigmoid(x) = 1 / (1 + exp(-x))。
虽然它们的形状相似,但是Mish的导数计算比较复杂,而SiLU的导数计算比较简单,因此在YOLOv5中使用SiLU作为激活函数,可以提高网络训练的效率。此外,SiLU的计算速度也比Mish快,可以进一步提高网络的推理速度。
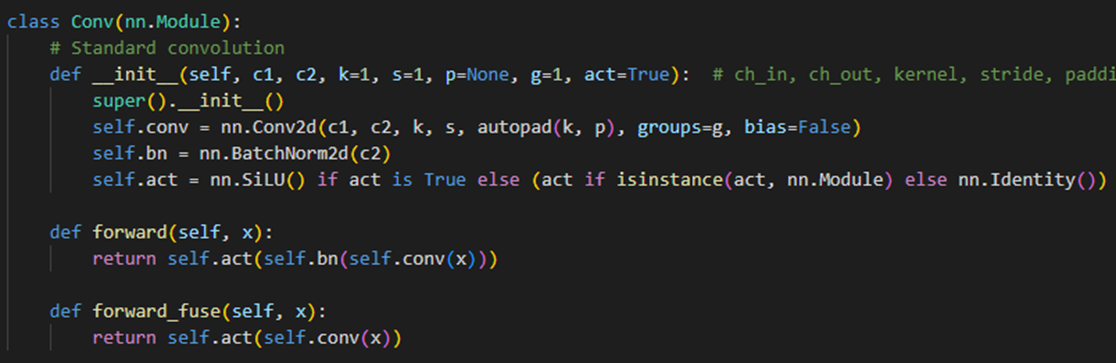
5. YOLOV5中的CSPBlock
5.1 CBA模块
- Conv + BN + SiLU
5.2 C3模块
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x4lROUli-1679577573867)(null)]
这个是V5的,看起来就比较简易
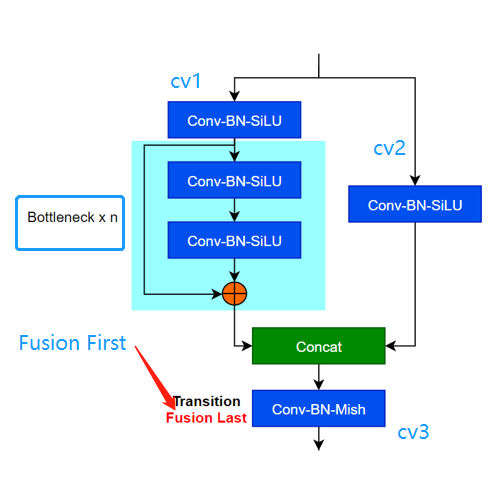
这个是V4的,看起来就复杂了很多
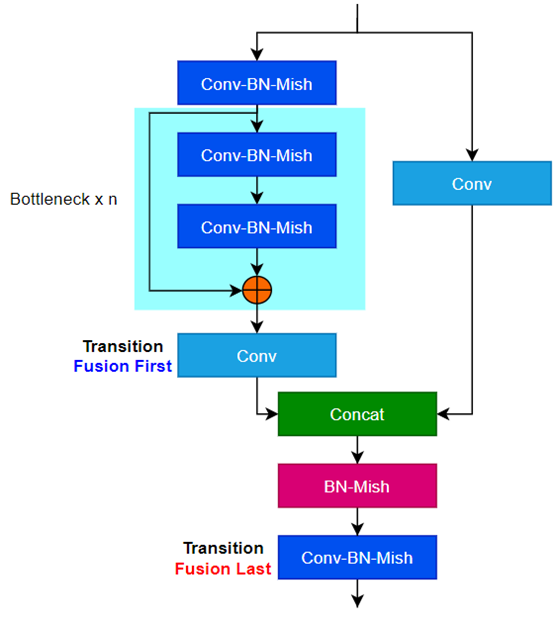
删除了BN-MISH 也仅仅只是使用fusion first
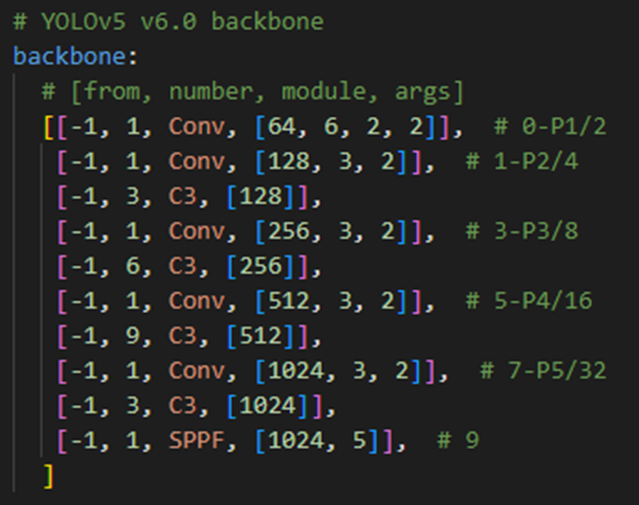
6. 完整的BackBone
- stage就是执行了多少次上面的那个CSPBlock,可以从配置文件中看出来, 跟YOLOV4的CSPDarkNet53一样, 采用了stage = [3, 6, 9, 3] 分别对应下采样背书为: 4, 8, 16, 32
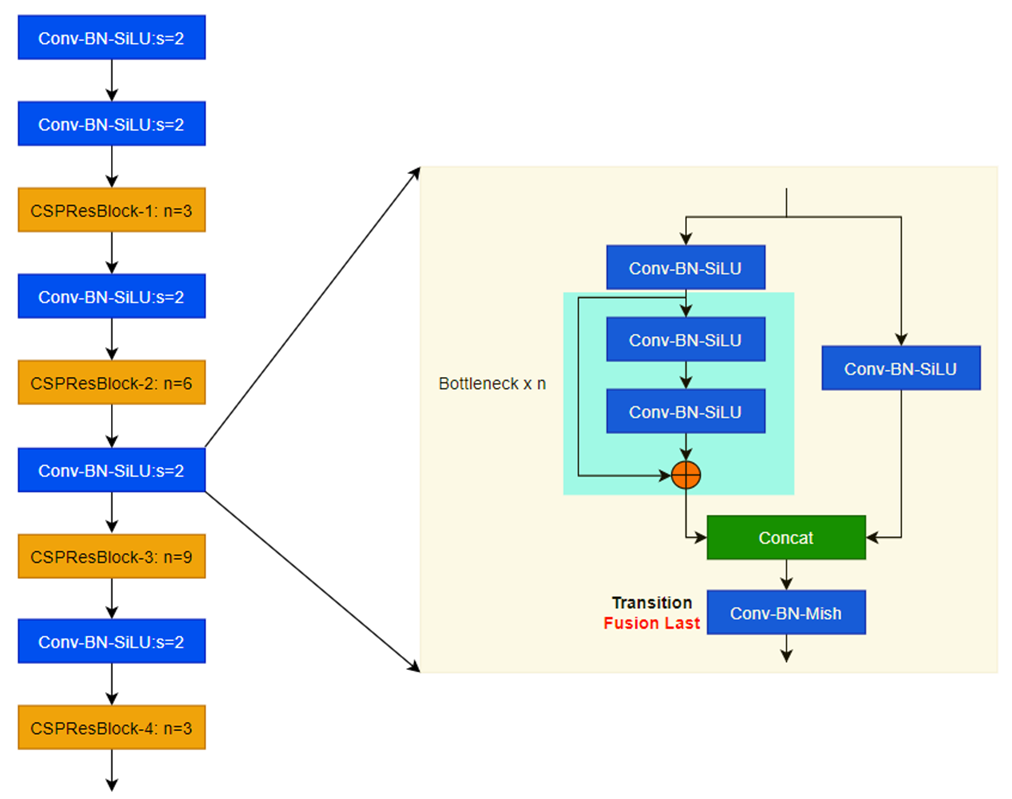
6. YOLOV5中的SPP改进: SPPF
-
SPPF/SPP也是加载在backbone后面的, 用于进一步提取特征。
-
无论是SPPF还是SPP,都不会改变特征图的大小和通道, 把他们拿掉也不会影响整体网络的输出输入,但是他们的作用是对高层特征进行提取并融合。
-
这一模块的主要作用是对高层特征进行提取并融合,在融合的过程中多次运用最大池化,尽可能多的去提取高层次的语义特征。
7. 坐标表示的对比(V3/V4 vs V5)
7.1 v3/v4 使用的坐标表示
坐标图解
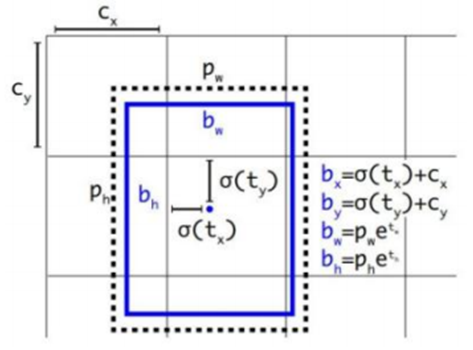
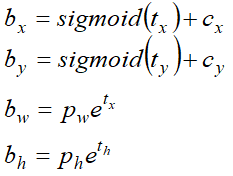
b_w = p_w * e^(t_w) 这里是写错了,公式以下面为准
x = sigmoid(tx) + cx
y = sigmoid(ty) + cy
w = pw * exp(tw)
h = ph * exp(th)
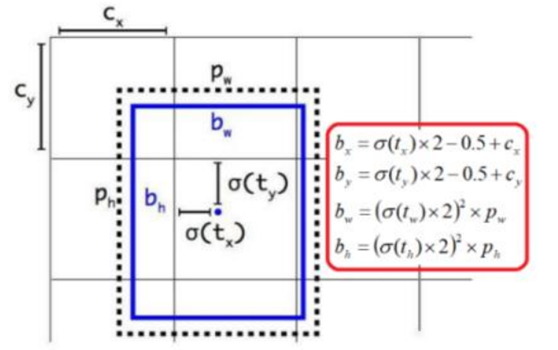
首先理解外面那个黑色的框框是Anchor, 也就是我们训练之前通过聚类生成的。蓝色的是我们的bboxes。
YOLO系列算法回归出来的东西是图上的tx, ty, tw, th 这些相对坐标, 让母后通过图上的计算公式计算成为bounding box的坐标以及宽高。
Cx, Cy, 是grid的值,告诉我们当前的grid实在第几个
这样就是理解之前说bounding box是Anchor变化过来的
7.2 v5的坐标系表示
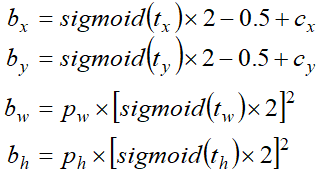
其实就是换了一种方式把anchor改成bounding box。YOLOV5没有论文, 但是YOLOV3/V4 U版都是使用的这种坐标的转换
8. YOLOV5中的正负样本匹配对比V3 V4的正负样本的匹配
8.1 先验知识
V3/V4/V5的预测都是分成三个尺度做预测, 每个预测层都有三个Anchor Box
增加正样本可以提高模型的准确性和召回率,但不一定能够直接提高模型的收敛速度。在训练过程中,增加正样本可能会增加模型的复杂度,导致训练时间变长,同时也会增加模型过拟合的风险。因此,在增加正样本的同时,需要综合考虑模型的准确性和复杂度,并进行适当的调整和优化。
8.2 V3中的正负样本匹配
-
V3是每一个尺度也就是每一个检测层分配一个跟GT最大IOU的Anchor box做正样本, 没错,正样本就是就是满足条件的Anchor box,然后他会通过训练得到参数,在推理的时候生成上面bounding box所需要的参数生成bboxes
-
这样子就会有一种正样本不够的问题,因为每一个数据V3最多只能生成3个正样本, 即每一层都的最大那个, 如果一个样本不是正样本,那么它既没有定位损失,也没有类别损失,只有置信度损失
-
V4增加了正样本的数量
8.3 V4的正负样本匹配
-
V4的选择是只要大于设置的IOU阈值全部设置成正样本, 那么就意味着三个尺度/三个预测层最多可以拥有9个正样本
-
原本被V3忽略掉的他这边也被视为正样本
8.4 V5的正负样本匹配
-
其实也就是在V4做完之后再加了一个操作, 就是把每个grid分成了四个象限, 然后可以再拉两个grid进来,再拉两个grid也就意味着可以多6个Anchor去计算IOU看看是否有机会成为正样本
-
V3每层只有1个正样本, V4通过计算可以有1-3个, V5多拉了两个grid进来可以有3-9个
-
YOLOv5的这种匹配方式能够分配更多的正样本,有助于训练加速收敛,以及正负样本的平衡。而且由于每个特征图都会将所有的 GT与当前特征图的 Anchor 计算能否分配正样本,也就说明一个GT可能会在多个特征图中都分配到正样本。
9. 损失函数
YOLOv5 和 YOLOv4 一样都采用 CIoU Loss 做 Bounding Box 的回归损失函数,而分类损失和目标损失都使用的是交叉熵损失。
对于回归损失,其数学表达式如下:
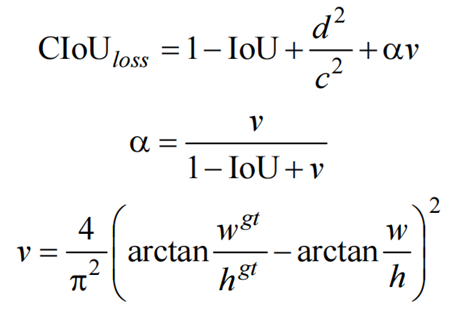
式中,d,c 分别表示预测结果与标注结果中心点的欧氏距离和框的对角线距离。这样CIOU Loss 将目标框回归函数应该考虑的 3 个重要几何因素都考虑进去了:重叠面积、中心点距离、长宽比。
对于分类损失和目标损失,其数学表达式如下: