Towards Continual Knowledge Learning of Language Models
文章目录
1 发展背景和要解决的问题是什么?
-
Language Models are known to encode world knowledge in model parameters.
语言模型被我们熟知,用于在大规模语料库上预训练时编码现实知识到模型参数中。
-
In the real world, the world knowledge stored in the LMs can quickly become outdated as the world changes.
在现实世界中,存储在语言模型中的现实知识会很快过时,由于世界在不断变化。
-
It is important to avoid catastrophic forgetting and reliably acquire new knowledge while preserving invariant knowledge.
避免灾难性遗忘和可靠地获取新知识,同时保存不变知识是非常重要的。
-
Purpose of this paper: To push the community towards better maintenance of ever-changing LMs, this paper formulates a new continual learning (CL) problem called Continual Knowledge Learning (CKL).
这篇论文的目的是推动社区去更好地维护一直在改变的语言模型,本文提出新的CL问题,成为CKL。
2 为什么重要?
-
How to avoid catastrophic forgetting and reliably acquire new knowledge is a vital problem.
在现实世界中,如何去避免灾难性遗忘和可靠获取新知识是一个至关重要的问题。
-
Some information should be updated, while some should not be altered (called time-invariant information).
一些信息应该被更新,而另一些信息应该被保留下来(这部分信息为“时不变”信息)

3 为什么有挑战性?
-
Renew the internal knowledge is nontrivial and has only been explored in rather specific settings.
更新语言模型参数中包含的内在知识并不平常,并且只在具体的设定下进行过探索。
-
Example 1: Modify specific target knowledge such as individual facts.
比如最近的工作提出修改特定的目标知识比如单个事实。
-
Example 2: Addressed LMs as temporal knowledge bases by jointly modeling text with its timestamp.
通过联合建模文本及其时间戳,将语言模型作为时间知识库来处理。
-
-
But the problem of renewing the world knowledge of LMs in a more general and scalable way, such as through continual pretraining on a corpus with new knowledge, has not been formally formulated or explored by previous works.
但是!以前还没有工作以一种更普遍和可扩展的方式更新语言模型的知识问题,例如通过对具有新知识的语料库进行持续训练。
-
The community lacks a benchmark that can be used to systematically study how the internal knowledge of LMs changes through the training on new information.
另外,现在社区还缺乏一种benchmark,用来系统地研究语言模型内部知识如何通过持续训练新知识而变化。
-
Methodologies to effectively renew the knowledge of LMs at scale have yet to be thoroughly explored.
有效地大规模更新语言模型知识仍有待探索。
-
There are nontrivial differences between traditional CL and the proposed Continual Knowledge Learning (CKL) formulation which make applying traditional CL methods inadequate.
传统CL和提出的CKL之间存在显著的差别,使得传统的CL方法并不充分。
Traditional CL: regularization, rehearsal, and parameter expansion methods.
Regularization: 正则化方法需识别用于以前任务的重要参数,但知识在LM中如何存储以及存储在哪里目前极其难以识别和定位。
Rehearsal: 将一次性学习所有任务流(多任务学习)视为性能上界,并使用情景记忆中存储的样本复制这样的设置,来自训练前语料库中的少数样本不能代表语料库中的整体世界知识。此外,如果LM在语料库流的打乱连接上进行预先训练,就不能保证LM将从最近的语料库中获得正确的、最近的信息,特别是在前一个语料库比后者的语料库大得多的情况下。
Parameter-expansion: 专注于通过强监督学习不同的任务,而在CKL中,重点是通过自监督从语料库中不断更新世界知识。
Explore methodologies from the literature that are suitable for CKL, modifying and adapting each method according to our
needs as CKL methods.
从以前的工作中探索适合CKL的方法,根据我们的需要对每种方法进行修改和调整,作为合适的CKL方法
4 方法的核心insight是什么?
-
CKL is much closer to the initial motivation behind CL, which is that the “fundamental characteristic of natural intelligence is its ability to continually learn new knowledge while updating information about the old ones”
自然智力的基本特征是它不断学习新知识,同时更新旧知识的能力。
5 方法主体是什么?
-
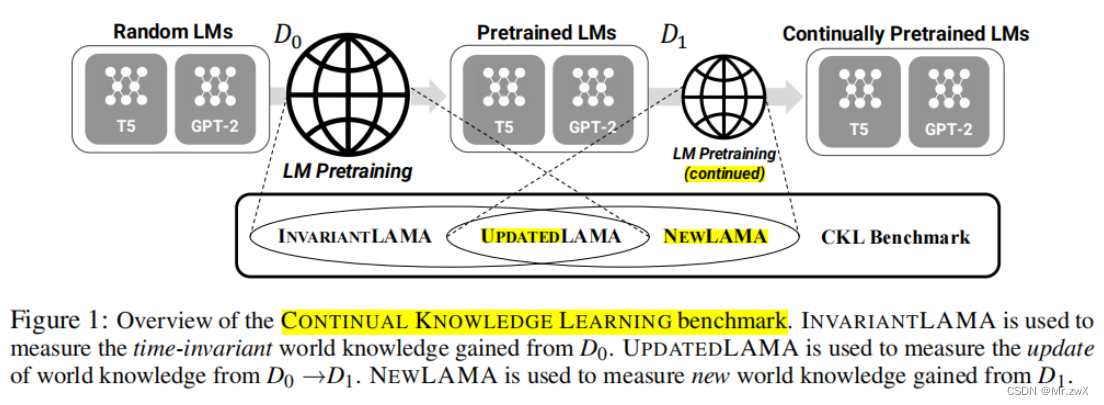
Propose a novel continual learning (CL) formulation named Continual Knowledge Learning (CKL). The goal is to renew the internal world knowledge of LMs through continual pretraining on new corpora.
提出一种全新的持续学习表示,称作持续知识学习。目的是通过持续地在新语料库上进行预训练,从而更新语言模型的内部知识。
-
Systematically categorize world knowledge into three main categories and make benchmark datasets to measure each of them during CKL.
系统地将知识分为三个类别,并且制作了benchmark数据集去衡量每个类别。
- INVARIANTLAMA:语言模型中的时不变(time-invariant)知识,这些知识不应该被遗忘或替代。
- UPDATEDLAMA:语言模型中过时(outdated)知识,需要被更新到模型中。
- NEWLAMA:语言模型中的新(new)知识,需要被注入到模型中。
-
Propose a novel metric named FUAR that can measure the trade-off between forgetting, updating, and acquiring knowledge.
FUAR: FORGOTTEN / (UPDATED + ACQUIRED) RATIO
提出一种群全新的指标,称作FUAR,用于衡量遗忘、更新和获取新知识之间的权衡。
6 关键技术点和解决方法?
-
Task Formulation
-
View the task of renewing the internal knowledge as CL. Pretraining on the original corpus can be considered as a previous task, and continued pretraining on new corpus can be considered as the current task.
将更新模型内部知识这个任务看作是持续学习的一种,在原始语料库预训练看作是之前的任务,将新语料库上的持续预训练看作是当前任务。
-
The Goal is to retaining the time-invariant world knowledge gained through initial pretraining while efficiently learning new and updated world knowledge through continued pretraining.
最终的目的是保留通过初始预训练获得的时不变世界知识,同时通过持续的预训练有效地学习新的、更新的世界知识。
-
Measuring Retention of Time-invariant World Knowledge -> INVARIANTLAMA

-
Measuring Update of Outdated World Knowledge -> UPDATEDLAMA

-
Measuring Acquisition of New World Knowledge -> NEWLAMA
-
-
Combined Metric for CKL
It can compare the efficiency of each CKL method using the trade-off between forgotten time-invariant knowledge and updated or newly acquired knowledge
FUAR: FORGOTTEN / (UPDATED + ACQUIRED) RATIO
提出新的指标,可与使用遗忘的时不变知识和更新或新获得的知识之间的权衡,来比较每种CKL之间的效率。其实FUAR表示:相对来说,为了学习新知识而遗忘时不变实例的数量多少。
T是任意一个task,Dn是用于语言模型预训练的一系列语料库,D0是最初的预训练语料库。
定义了一个Gap表示持续训练过程中两次语言模型之间的差距:

拆解任务为:TF是衡量遗忘”时不变“知识的任务;TU是衡量更新知识的任务;T^A是衡量获取新知识的任务。
FUAR定义为一个更普适的情况,因为可能在多个语料库上进行持续预训练:
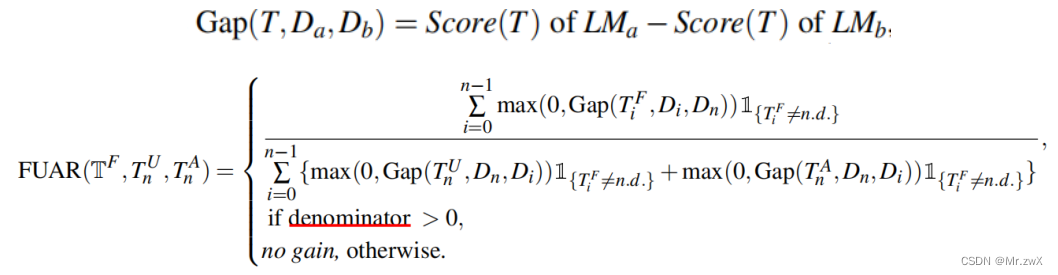
- FAUR=1时,表示equal trade-off,平均忘记一个”时不变“知识实例,就会获得一个新的或更新一个知识实例。
- FAUR<1时,表示获取新知识或更新知识多于忘记知识的数量,所以表明了更低的FAUR值能将该CKL考虑为更合适。
- FAUR=0时,表示没有遗忘的知识,所以这是性能的上界(upper bound)。
- 分母采用获取知识和更新知识进行sum,是因为我们定义两者是互斥的。
- 如果分母为0,表示这个例子无收益,并认为这个是最坏的情况。
-
Data Construction
Data for continual pretraining: CC-RECENTNEWS
INVARIANTLAMA: manually select 28 time-invariant relations from T-Rex
UPDATEDLAMA、NEWLAMA: use Amazon Mechanical Turk for crowd-sourcing Human Intelligent Tasks.
这个过程需要从模型生成的一系列问题列表中选择可回答的问题,将它们转换为完型句式。还分别请了11名专家来验证其正确性,并搜索C4数据库,将每个实例分类为updated和new。
7 关键发现是什么?
- 发现参数扩展方法在所有的实验设置中都表现出最稳健的性能。然而却是严重的记忆效率低下、看到相同的数据往往是遗忘的一个关键原因。
8 主要实验结论是什么
-
实验设定
- 模型:encoder-decoer model——T5
- Dataset D0: C4 and Wikipedia Dataset D1: CC-RencentNews
- Initial: 在任何持续预训练之前进行的评估。认为其性能是INVARIANTLAMA的上界,UPDATEDLAMA和NEWLAMA的下界。
- Vanilla: 一种特殊的继续预训练,领域为新知识,不借助任何训练策略去继续训练。
- RecAdam: 类别为regularization方法。与传统的正则化方法相比,模型参数之间存在一个更强的独立假设。在持续的预训练过程中,不访问初始的训练前的语料库来规范模型的权重。优化器被退火,以便更少的正则化。
- Mix-Review: 类别为rehearsal方法。假设可以访问初始训练前的语料库,并在继续预训练期间在初始预训练数据的随机子集中进行混合,这取决于当前时间步的混合比例。随着训练的进行,混合比衰减到0,减少了每次迭代中混合原始数据的量。
- LoRA: 类别为parameter-expansion方法。它冻结了LM的原始参数,并将可训练的秩分解矩阵添加到每一层中,并在持续的预训练中进行更新。
- K-Adapter: 另一种parameter-expansion方法。冻结LM的原始参数,同时添加k个新层数,即adapter,并在继续的预训练期间进行更新。
- Modular: 新提出的parameter-expansion方法。特别用于encoder-decoder模型,它冻结原始的、预训练的encoder,同时添加一个新的、随机初始化的encoder,在继续的预训练期间进行更新。
-
主要实验结果
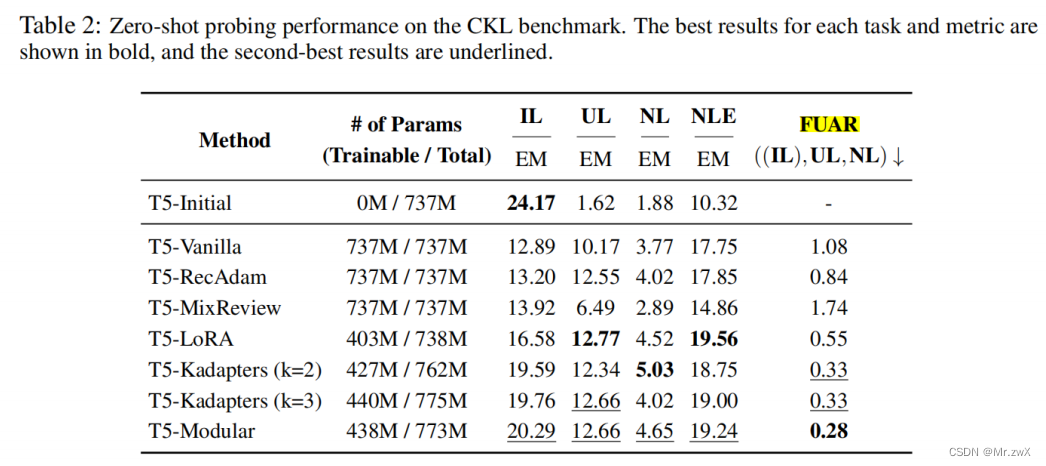
- CKL方法中,除了Mix-Review,在更新或获取新知识时,都只会遗忘更少的知识,相比于Vanilla。
- 表现出严重的CL与CKL之间的差别,rehearsal方法在传统的CL设定中表现出很强的性能,但在CKL中的性能最差。
- 得到一致的发现,parameter-expansion的方法都能取得更好的效果。
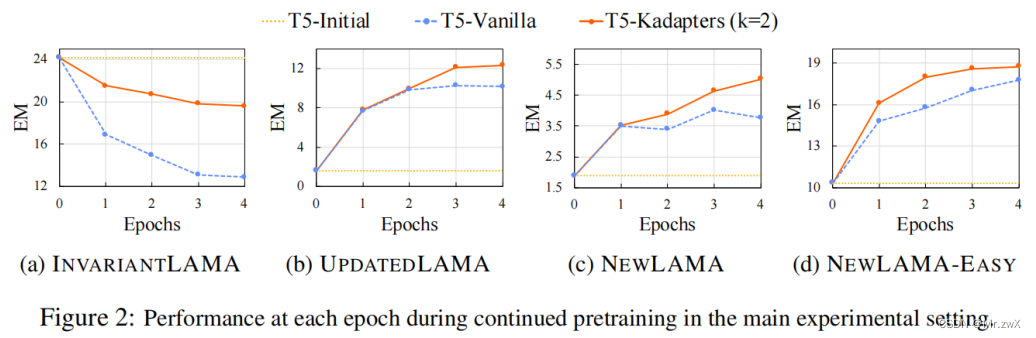
- Initial性能被认为是INVARIANTLAMA的上界,UPDATEDLAMA和NEWLAMA的下界。
- 与T5-Vanilla相比,CKL允许大量保留“时不变”的知识,同时改进更新和获得新知识,减轻了整体的权衡。
-
探索CKL的多阶段
- 构造了CC-RECENTNEWS-SMALL,是CC-RECENTNEWS的变体(包含随机采样的10%数据)。然后,根据每篇文章的发布日期将数据分割为两个不同的部分,成为SMALL-P1和SMALL-P2。
- parameter-expansion的方法存在明显的缺点,它们需要在每个阶段加入新参数来更新知识,比如在每个持续预训练的阶段中,T5-Modular的总参数量增加了36M。
-
学习率的影响
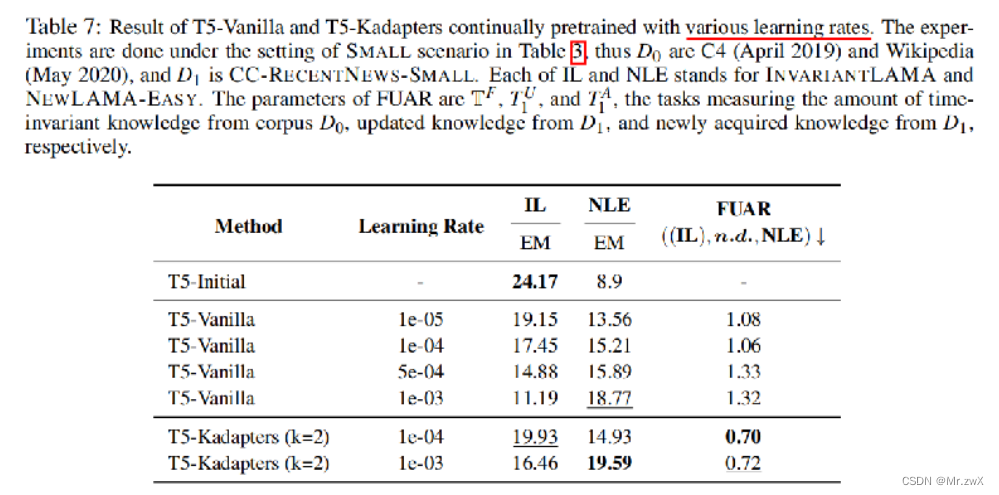
降低持续预训练的学习率可以减少对原始知识的遗忘,也可以减少对新知识的学习。
9 总结和核心takeaway(如何帮助自己的工作?)
-
Use the new benchmark and metric to quantify the retention of time-invariant world knowledge, the update of outdated knowledge, and the acquisition of new knowledge.
采用本文提出的新benchmark和metric去量化更新或获取新知识时的“时不变”知识的保留量。
-
It is important to do more research on continuous learning, as this paper only presents a problem framwork and experiments based on existing models.
本文只是提出一种问题框架和基于现有模型的实验,所以进一步去研究如何实现持续的语言模型学习是非常重要的、有前景的。
-
How to update the knowledge in LMs in a computation-effective manner.