1. 模型介绍
1.1 退化模型
首先训练数据使用了2个first-order:
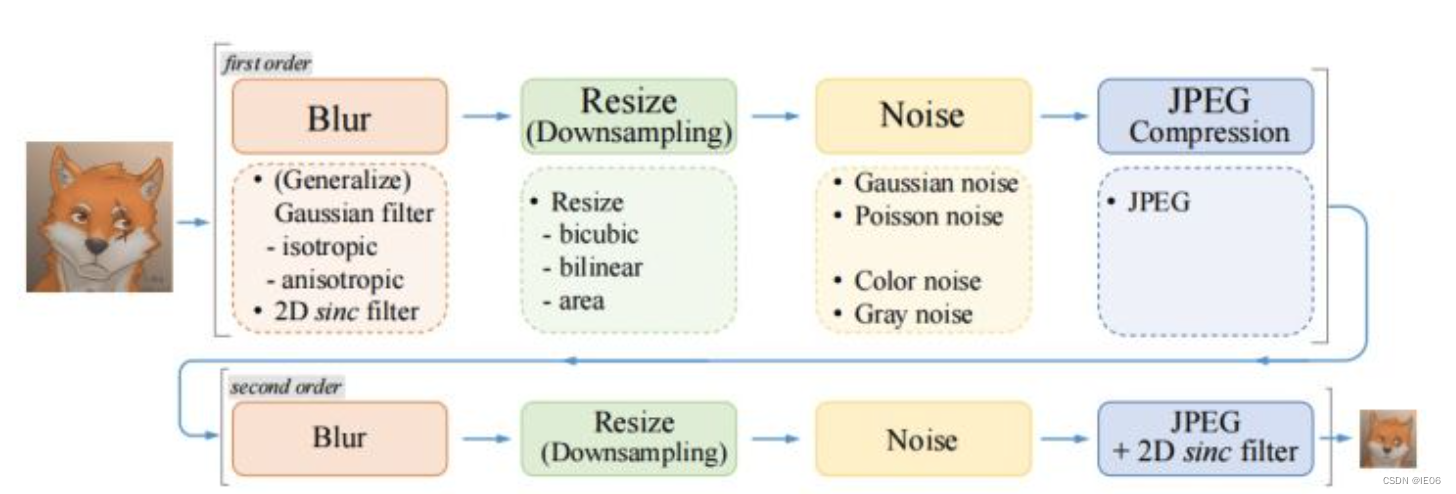
最后一步加入了振铃和过冲现象:

1.2 SRCNN
将CNN用到超分领域的第一篇文章:
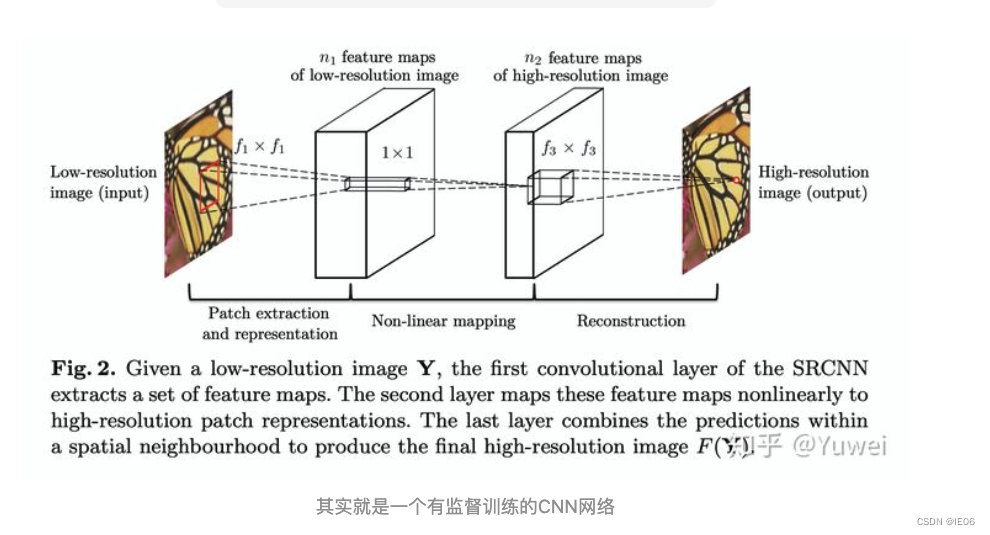
论文中卷积核和通道数的实验设置为:
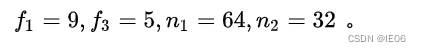
1.3 SRGAN
SRGAN将GAN引入超分领域,用于解决如下问题:
1)高频细节(high-frequency details) 的丢失,整体图像过于平滑/模糊;
2)与人的视觉感知不一致,超分图像的精确性与人的期望不匹配(人可能更关注前景,而对背景清晰度要求不高)。
提出如下改进:
- 新的backbone:SRResNet;
- GAN-based network 及 新的损失函数:
- adversarial loss:提升真实感(photo-realistic natural images);
- content loss:获取HR image和生成图像的感知相似性(perceptual similarity),而不只是像素级相似性(pixel similarity);或者说特征空间的相似性而不是像素空间的相似性。
- 使用主观评估手段,更加强调人的感知。
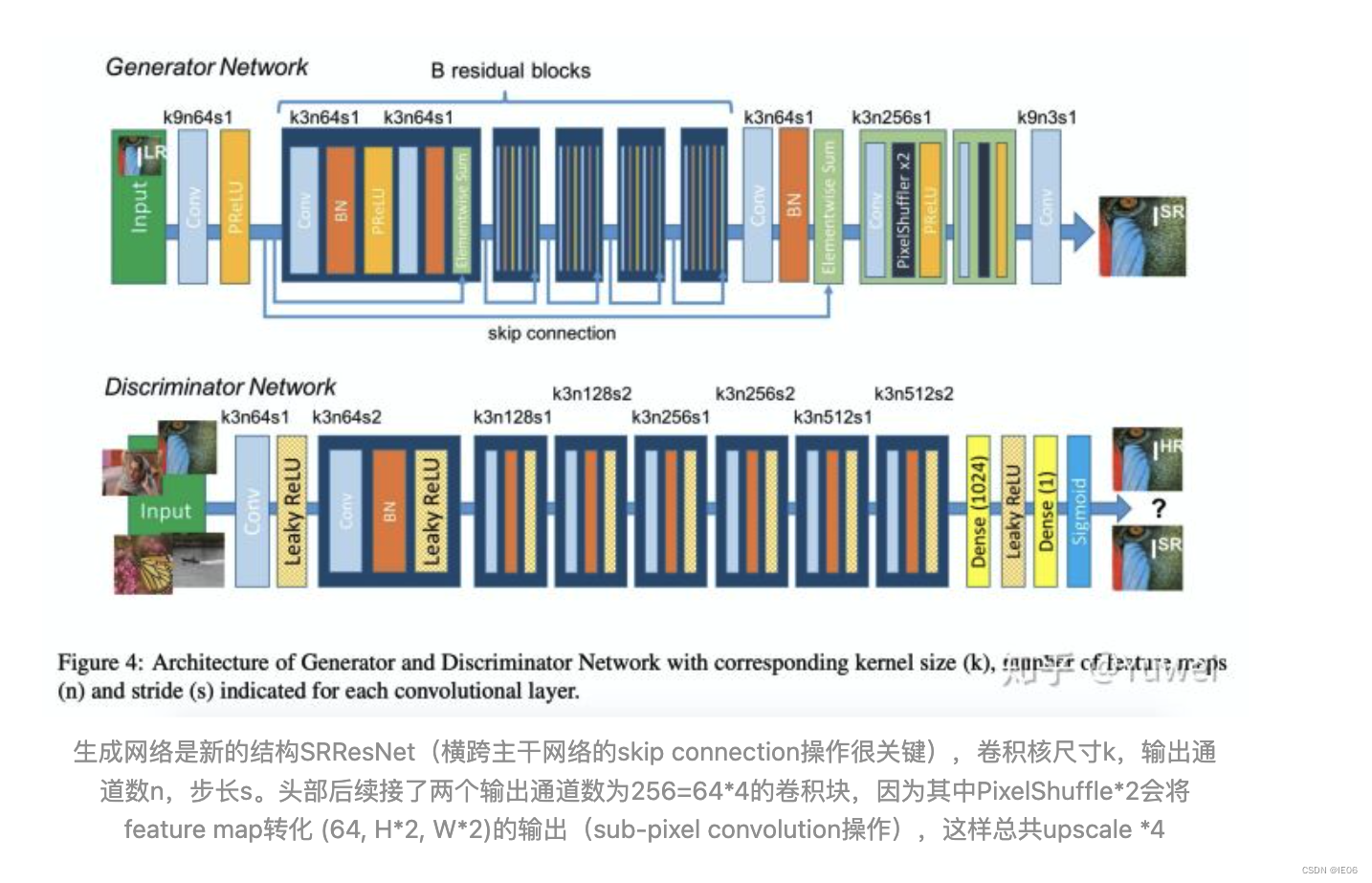
模型结构如下,Generator网络是SRResNet,论文使用了16个residual blocks;Discriminator网络为8次卷积操作(4次步长为2)+2次全连接层的VGG网络。
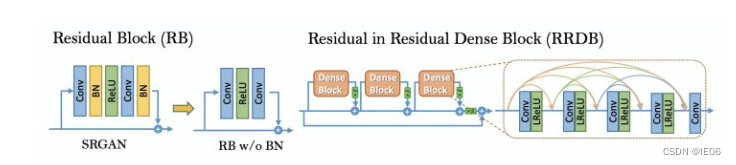
1.4 ESRGAN
enhanced SRGAN,主要解决细节模糊和伪影问题。
- SRResNet网络结构的改进:
1)移除BN,有利于去除伪影,提升泛化能力;
2)使用Residual-in-Residual Dense Block (RRDB)作为基本构建模块,更强更易训练; - GAN-based Network的损失函数的改进:使用RaGAN (Relativistic average GAN)中的相对损失函数,提升图像的相对真实性从而恢复更多的纹理细节;
- 感知损失函数的改进:使用VGG激活层前的特征值计算重构损失,提升了亮度的一致性和纹理恢复程度。
2. 快速上手
2.1 各种资源
绿色版的exe文件参见github,支持windows,linux,mac和NCNN
在线版本:https://huggingface.co/spaces/akhaliq/Real-ESRGAN
使用方法:./realesrgan-ncnn-vulkan.exe -i 二次元图片.jpg -o 二刺螈图片.png -n realesrgan-x4plus-anime
参数如下:
Usage: realesrgan-ncnn-vulkan.exe -i infile -o outfile [options]...
-h show this help
-i input-path input image path (jpg/png/webp) or directory
-o output-path output image path (jpg/png/webp) or directory
-s scale upscale ratio (can be 2, 3, 4. default=4)
-t tile-size tile size (>=32/0=auto, default=0) can be 0,0,0 for multi-gpu
-m model-path folder path to the pre-trained models. default=models
-n model-name model name (default=realesr-animevideov3, can be realesr-animevideov3 | realesrgan-x4plus | realesrgan-x4plus-anime | realesrnet-x4plus)
-g gpu-id gpu device to use (default=auto) can be 0,1,2 for multi-gpu
-j load:proc:save thread count for load/proc/save (default=1:2:2) can be 1:2,2,2:2 for multi-gpu
-x enable tta mode"
-f format output image format (jpg/png/webp, default=ext/png)
-v verbose output
目前已有的模型:
realesrgan-x4plus(默认)效果清晰,偏向于脑补;
reaesrnet-x4plus(效果模糊,偏向于涂抹)
realesrgan-x4plus-anime(针对动漫插画图像优化,有更小的体积)
realesr-animevideov3 (针对动漫视频)
这个是未来的计划:

2.2 github上原代码
git clone https://github.com/xinntao/Real-ESRGAN.git
cd Real-ESRGAN
# 安装 basicsr - https://github.com/xinntao/BasicSR
# 我们使用BasicSR来训练以及推断
pip install basicsr
# facexlib和gfpgan是用来增强人脸的
pip install facexlib
pip install gfpgan
pip install -r requirements.txt
python setup.py develop
wget https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth -P experiments/pretrained_models
然后执行:
python inference_realesrgan.py -n RealESRGAN_x4plus -i inputs --face_enhance
2.3 训练和微调
参考https://github.com/xinntao/Real-ESRGAN/blob/master/docs/Training_CN.md
微调时,可以使用程序自带的降级模型,也可以自备数据对。