1.误差分析(Bias and Variance)
当我们以非常复杂的模型去进行测试的时候,可能得到的结果并不理想

影响结果的主要有两个因素:Bias 偏差、Variance 方差
Bias 偏差
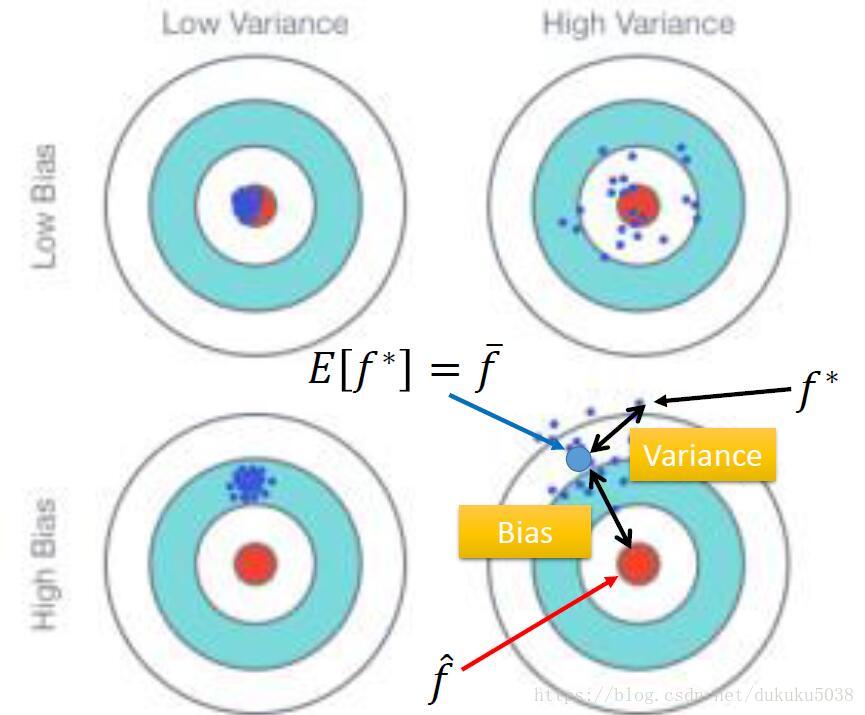
在这里,我们定义偏差是指与目标结果的偏移量,这个偏移量是我们选出来的函数的期望 。如图所示:与目标距离远的是大偏差,与目标距离近的是小偏差
Variance 方差
而方差描述的的是我们选出来的函数,他的稳定性,是否集中在目标区域
与相对分散的是高方差,相对集中的是低方差


小总结:偏差描述的是与目标的距离,而方差描述的是分散程度,我们的目的是在机器学习三板斧过后,找到一个低偏差,低方差的函数。如图左一
但是说起来容易,做起来难,我们一起看看吴恩达博士在cs229中的建议
2. 模型调优
问题举例:以朴素贝叶斯(我们后面会具体讲这个模型)为模型的邮件分类系统,错误率达到了20%,这是不能接受
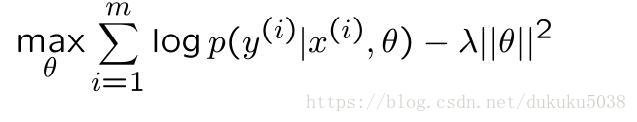
吴恩达的建议是:
1.获得跟多的的训练数据
2.尝试更少的更多的特征维度
3.尝试更多以的更少的特征维度
4.尝试更换邮件头或者邮件体的特征
5.把梯度下降的方法运行更多次
6.尝试使用牛顿方法
7.使用不同的参数
8 抛弃朴素贝叶斯模型尝试SVM

这么多方法,我们怎么选?
误差分析这个工具就可以派上用场了。一般情况下:高方差表示的就是训练误差小于测试误差,高误差表示 训练误差本来就很高

在这里我们给出典型的学习曲线:
- 高方差: 测试误差明显大于训练误差,而且两者的距离远(与训练误差距离远)
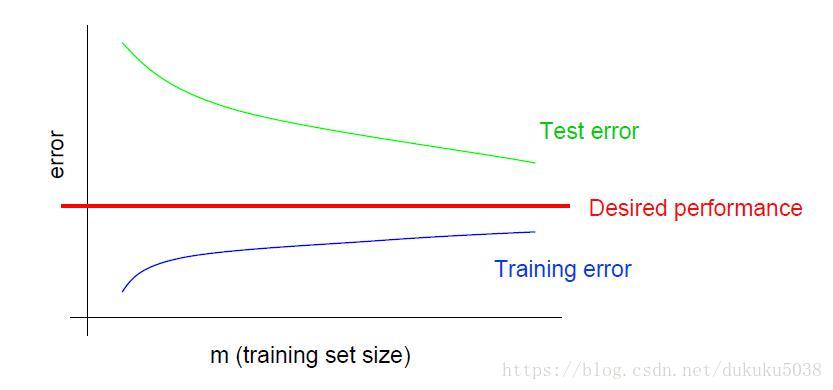
- 高误差: 训练误差大于我们期望的表现,但是与测试误差接近
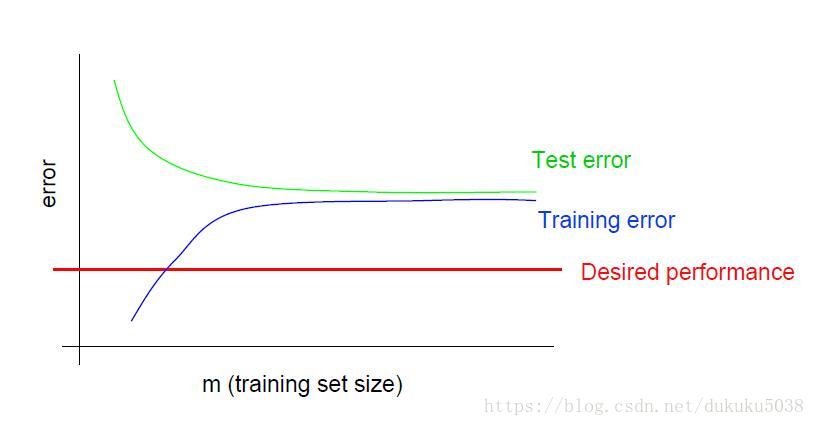
所以刚才我们提到的8个方法中的前4个要解决的问题是:
1.获得跟多的的训练数据 (高方差)
2.尝试更少的更多的特征维度(高方差)
3.尝试更多以的更少的特征维度(高误差)
4.尝试更换邮件头或者邮件体的特征(高误差)
接下来我们假设:
(1) 贝叶斯回归正常邮件的错误率是2%,垃圾邮件的错误率是2%。(如果把2%的正确邮件当成垃圾的,就是不可接受的)
(2) SVM 方法在垃圾邮件的识别错误率是10%,而正常邮件的识别错误率是0.01%。(这个表现是可以接受的)
(3) 但是,你又想用逻辑回归,应为计算量相对比较小
这个问题怎么破?

我们拿贝叶斯和SVM两个模型做对比

我们比较最后结果的的正确性
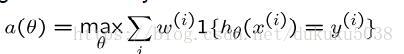
当
举例来说:上面的方程表示svm的表现好于beyesian
接下来我们就分析beyesian的损失函数 这里的=
想到于负的Loss,
越大,相当于Loss越小。
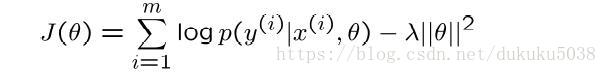
然后我们比较svm和beyesian的损失函数
case1:SVM的正确性大于BLR ,评价函数的结果也大于BLR(Loss小)
这里说明BLR模型的整体效果不如SVM,原因是 没有找到最大值,还有优化空间,需要用不同的方法优化case2: SVM的正确性大于BLR,但是评价函数的结果小于BLR
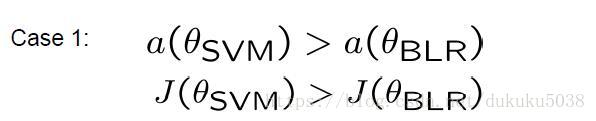
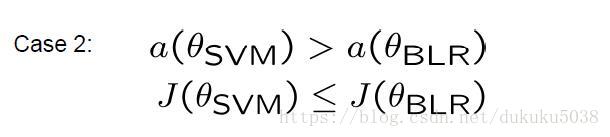
这里说明BLR已经找到了评价函数
的最大值,但是结果不理想,需要调整评价函数或者换不同的模型。
所以刚才我们提到的8个方法中的后4个要解决的问题是:
5.把梯度下降的方法运行更多次(优化求极值的方法)
6.尝试使用牛顿方法(优化求极值的方法)
7.使用不同的参数
(改变评价函数)
8 抛弃朴素贝叶斯模型尝试SVM(改变评价函数)
着这里我们把吴恩达博士给的八个方法具体用到哪些场景已经了“心中有数”了。
我们再举一个例子,斯坦福自动驾驶直升机

- 首先我们建立一个模拟器
- 建立Loss 函数
- 运行强化学习算法(以后单独会讲解)与最小化Loss 然后找到最好的
当你执行完这些步骤后,得到的结果很不理想,没有找到合适的 (实际环境中飞机总是坠毁),那我们该怎么办。有三种选择:
(1) 调整我们建立的飞行模拟器
(2) 调整Loss 函数
(3) 调整强化学习算法
如果模拟环境飞机是正常飞行的,而正常环境飞机总是坠毁,那我们就选择(1)调整我们的模拟器;
如果让有经验的飞行员去控制飞机,我们采集他的行为数据参数
,
当
, 说明飞行员的表现更好,而我们的强化学习算法没有能够有效的降低Loss,那我们就进行(3)调整强化学习算法**
让我们再举一个人脸识别系统误差分析的例子(这个例子比较旧,但是思路可以借鉴,人脸识别算法已经很成熟了)
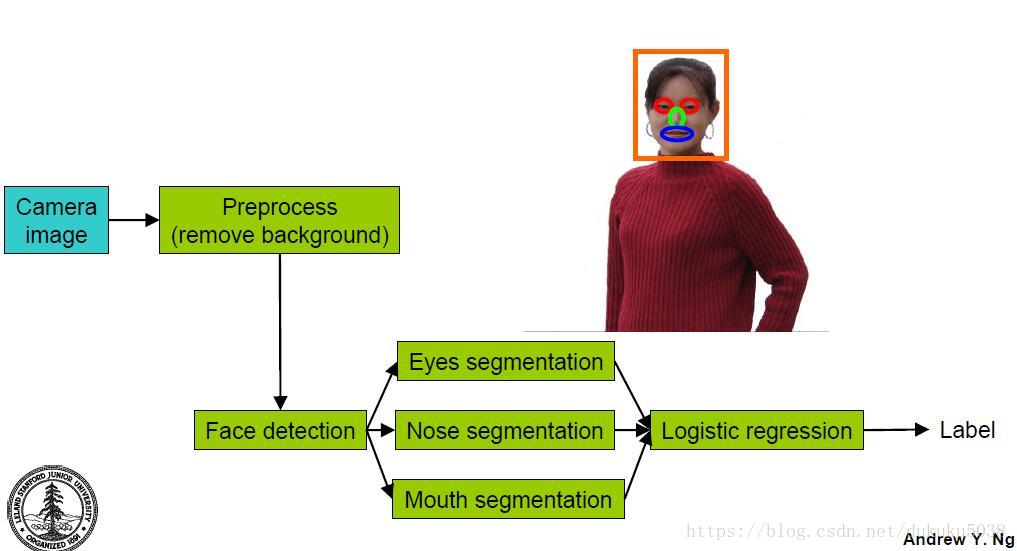
许多系统都是由不同的模块构建起来的。
当相机采集照片后,通过预处理去掉背景(preprocess),进入人脸识别模块(Face detection),人脸识别模块又包含三个子模块,眼睛识别、鼻子识别、嘴巴识别,然后用三个子模块的结果进行逻辑回归,最后输出结果。
每个模块对于整体系统正确率贡献是不同的
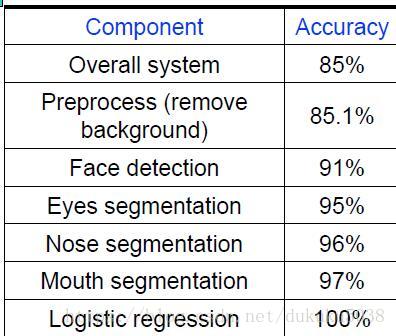
分析每个模块对误差的贡献对整体系统设计是非常有意义的
最后吴恩达给出了运行机器学习算法的三个建议和两个系统实现方法
(1) 花在错误分析上的时间是值得的
(2) 你的独创性和灵感往往赖在正确的错误诊断中
(3) 错误分析可以让你对问题的理解更加深刻
方法一、仔细设计,但是花费时间多,可能会过多考虑不重要问题
方法二、快速先干出一个可以运行的系统,但是分析、调优

最后,如果不是要做算法提升的工作,那就拿起键盘就是干。(因为开始的时候,我们并不知道那个模块有用与否,所以先运行起来,再调整)