
在真实的场景中,当标记数据稀缺时,文本分类任务通常存在冷启动的现象(也就是标记文本数量太少时很容易过拟合)。本文提出了一种方法来提高这类模型的性能,即在预处理阶段和微调阶段之间增加一个中间的无监督分类任务。作为中间任务,进行聚类,并训练预训练模型预测聚类标签。本文在各种数据集上测试了这个假设,结果表明,当可用于微调的标记实例数量只有几十到几百个时,这个额外的分类阶段可以显著提高性能,主要是针对主题分类任务。
之所以可以这样做,因为合理的中间任务有望为最后的微调阶段提供一个更好的起点,在目标任务可用的稀缺标记数据上执行,旨在最终提高性能。尽管这两个任务并不是相关联的,但是在对域内数据底层语义的学习上还是大有裨益的。
而本文采纳的无监督方法也是最为简单的一种:以BOW学习的文本表示,将未标记的训练数据划分为与文本实例的相对同构簇。接下来,将这些聚类作为中间文本分类任务的标记数据,并在最终对实际目标任务标签进行微调之前,针对这个多类问题,对预训练模型进行带有或不带有额外的MLM预训练。鉴于MLM任务以及聚类、微调三种任务可以任意组合,本文所提出的总体结构图如下:
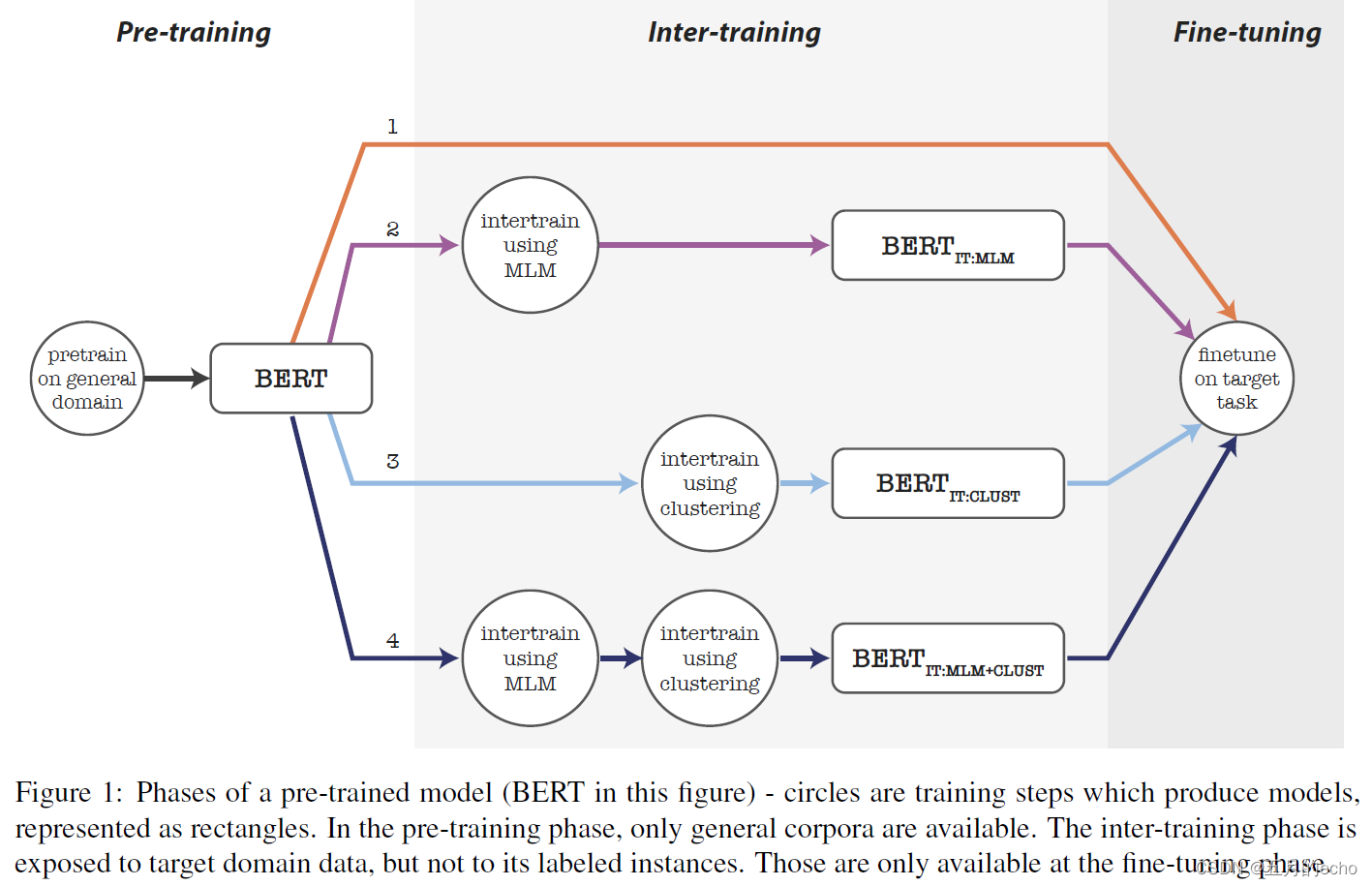
step1-4分别对应了四种不同的处理流程:
- 直接对下游任务进行微调。
- 先对领域做MLM的自监督学习,再对下游进行微调。
- 聚类之后再做微调。
- MLM自监督之后