YOLOv3官网:https://pjreddie.com/darknet/yolo/
YOLOv2官网:https://pjreddie.com/darknet/yolov2/
darkflow官网:https://github.com/thtrieu/darkflow
darkflow翻译:https://blog.csdn.net/wc781708249/article/details/79710448
1.获取数据与标签
将图片转换为xml格式,随后再转换为txt.
(1)获取图片并使用labelimg标注图片生成xml数据
从FDDB数据库中提取300张图片并放入Image文件夹.
FDDB是全世界最具权威的人脸检测评测平台之一,包含2845张图片,共有5171个人脸作为测试集。测试集范围包括:不同姿势、不同分辨率、旋转和遮挡等图片,同时包括灰度图和彩色图,标准的人脸标注区域为椭圆形。
图片来源:美联社和路透社新闻报道图片,并删除了重复图片
使用标注工具labelimg手动给每一张图片加标签生成xml文件格式放入xml文件夹中.
(2)将xml转换成为darknet能读入的txt格式文件
首先需要生成一个包含所有图片名字的eyes_train.txt,这里命名为picaddress.py
#coding=utf-8
import os
import os.path
"""
将所有的图片文件名写进txt文件里
"""
pathh = "/home/hx-104b/darknet/Image/"
for filenames in os.walk(pathh):
filenames = list(filenames)
filenames = filenames[2]
for filename in filenames:
print(filename)
with open ("eyes_train.txt",'a') as f:
f.write(pathh+filename+'\n')画风如下:
保存有所有图片的路径.
接着,使用修改过的voc_label.py将所有的xml文件转换成yolo能够读到的txt文件,其中txt格式的文件如下:
<object-class> <x> <y> <width> <height>voc_label代码更改如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[]
classes = ["eyes"]
#原样保留。size为图片大小
# 将ROI的坐标转换为yolo需要的坐标
# size是图片的w和h
# box里保存的是ROI的坐标(x,y的最大值和最小值)
# 返回值为ROI中心点相对于图片大小的比例坐标,和ROI的w、h相对于图片大小的比例
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
#对于单个xml的处理
def convert_annotation(image_id):
image_add = os.path.split(image_id)[1] #截取文件名带后缀
image_add = image_add[0:image_add.find('.', 1)]#删除后缀,现在只有文件名没有后缀
in_file = open('/home/hx-104b/darknet/xml/%s.xml'%(image_add))
print('now write to:/home/hx-104b/darknet/eye_labels/%s.txt' % (image_add))
out_file = open('/home/hx-104b/darknet/eye_labels/%s.txt'%(image_add), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.findall("object"):
# obj.append("number") = obj.find('name').text
obj.find('name').text = "eyes"
print(obj.find('name').text)
tree.write('/home/hx-104b/darknet/xml/' + image_add + '.xml')
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
# 如果训练标签中的品种不在程序预定品种,或者difficult = 1,跳过此object
for obj in root.iter('object'):
#difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes:# or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
# b是每个Object中,一个bndbox上下左右像素的元组
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if not os.path.exists('/home/hx-104b/darknet/eye_labels/'):
os.makedirs('/home/hx-104b/darknet/eye_labels/')
image_adds = open("eyes_train.txt")
for image_add in image_adds:
image_add = image_add.strip()
print (image_add)
convert_annotation(image_add)这样就可以将所有的xml文件转换成txt格式并保存到eye_labels文件夹.
随后便可以将eyes_train.txt分出来一部分文件名生成eyes_test.txt作为验证集.(我这里训练集270张图片,验证集30张图片)
如果只到这里会报错,会说找不到Image文件夹下的同名txt文件,因此将eyes_label文件夹下的txt文件全部复制到Image文件夹下.
随后Image文件夹的画风如下:
图片与他们的txt标签文件一一对应.
2.修改配置文件
(1)修改.cfg文件
复制不会报错的的的yolo.cfg复制为yolo-eyes.cfg,随后对yolo-eyes.cfg进行修改.
类别为1,即classes=1.
需要训练时将前四行中的testing注释掉,使用training参数.
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=1
subdivisions=1注:因为内存限制最后将batch和subdivision修改为1.
batch: 每一次迭代送到网络的图片数量,也叫批数量。增大这个可以让网络在较少的迭代次数内完成一个epoch。在固定最大迭代次数的前提下,增加batch会延长训练时间,但会更好的寻找到梯度下降的方向。如果你显存够大,可以适当增大这个值来提高内存利用率。这个值是需要大家不断尝试选取的,过小的话会让训练不够收敛,过大会陷入局部最优。
subdivision:这个参数很有意思的,它会让你的每一个batch不是一下子都丢到网络里。而是分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半。
如果后续训练过程中会发散,则可以调整学习率,将学习率从0.001变得再小一点.
learning_rate=0.00001#学习率可以变得再小一点,避免训练过程中发散
burn_in=1000
max_batches = 500200#训练步长可以在这一步调整,原来是500200次
policy=steps
steps=400000
scales=.1,.1learning_rate:学习率,训练发散的话可以降低学习率。学习遇到瓶颈,loss不变的话也减低学习率。
policy:学习策略,一般都是step这种步进式。
step,scales:这两个是组合一起的,举个例子:learn_rate: 0.001, step:100,25000,35000 scales: 10, .1, .1 这组数据的意思就是在0-100次iteration期间learning rate为原始0.001,在100-25000次iteration期间learning rate为原始的10倍0.01,在25000-35000次iteration期间learning rate为当前值的0.1倍,就是0.001, 在35000到最大iteration期间使用learning rate为当前值的0.1倍,就是0.0001。随着iteration增加,降低学习率可以是模型更有效的学习,也就是更好的降低train loss。
更改[region]中的classes为1,根据 的公式,修改最后一个[convolutional]的filter改为30.
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=30 #修改这里的filter为30
activation=linear
[region]
anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828
bias_match=1
classes=1#修改种类为1
coords=4
num=5
softmax=1
jitter=.3
rescore=1
object_scale=5
noobject_scale=1
class_scale=1
coord_scale=1
absolute=1
thresh = .1
random=0#默认random为1,但是因为因为内存限制,将random改为0.random,是一个开关。如果设置为1的话,就是在训练的时候每一batch图片会随便改成320-640(32整倍数)大小的图片。目的和上面的色度,曝光度等一样。如果设置为0的话,所有图片就只修改成默认的大小 416*416。(2018.04.08更新,评论给里有朋友说这里如果设置为1的话,训练的时候obj和noobj会出现全为0的情况,设置为0后一切正常。)
(2)新建cfg/eyes.data文件
vim cfg/eyes.data在eyes.data文件中写下以下参数:
classes=1
train=/home/hx-104b/darknet/eyes_train.txt
valid=/home/hx-104b/darknet/eyes_test.txt
names=data/eyes.names
backup=backupnames是训练的名字,backup是在训练过程中相应步数的权重文件文件夹.
vim data/eyes.names生成data/eyes.names文件并写入eyes类别.
生成backup文件夹.
mkdir backup3.开始训练
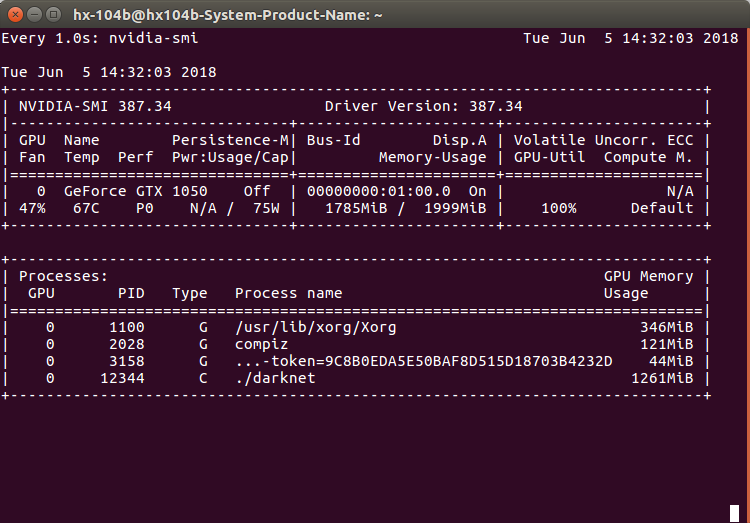
./darknet detector train cfg/eyes.data cfg/yolo-eyes.cfg 可以使用GPU监视命令,来查看GPU使用情况.
watch -n 1 nvidia-smiwatch的作用是周期性执行某一命令,”-n”后面指每多少秒执行一次命令,这里每隔1s更新一次GPU使用情况.
训练中的log如下:
...
Loaded: 0.000032 seconds
Region Avg IOU: 0.575282, Class: 1.000000, Obj: 0.320522, No Obj: 0.003656, Avg Recall: 1.000000, count: 1
7176: 2.402723, 4.019706 avg, 0.001000 rate, 0.285689 seconds, 7176 images
Loaded: 0.000029 seconds
Region Avg IOU: 0.494161, Class: 1.000000, Obj: 0.676317, No Obj: 0.002139, Avg Recall: 0.000000, count: 1
7177: 2.484811, 3.866217 avg, 0.001000 rate, 0.281483 seconds, 7177 images
...
训练log中各参数的意义:
Region Avg IOU:平均的IOU,代表预测的bounding box和ground truth的交集与并集之比,期望该值趋近于1。
Avg Recall: 这个表示平均召回率, 意思是 检测出物体的个数 除以 标注的所有物体个数。期望该值趋近1
Class:是标注物体的概率,期望该值趋近于1.
Obj:期望该值趋近于1.
No Obj:期望该值越来越小但不为零.
avg:平均损失,期望该值趋近于0
count: 标注的所有物体的个数。 如果 count = 6, recall = 0.66667, 就是表示一共有6个物体(可能包含不同类别,这个不管类别),然后我预测出来了4个,所以Recall 就是 4 除以 6 = 0.66667 。
rate:当前学习率
4.训练过程中的可视化
命令:
tee person_train_log.txt使用:
./darknet detector train cfg/tiny-yolo.cfg tiny-yolo_8000.conv.9 2>1 | tee person_train_log.txt保存log时会生成两个文件,文件1里保存的是网络加载信息和checkout点保存信息,person_train_log.txt中保存的是训练信息。
在使用脚本绘制变化曲线之前,需要先使用extract_log.py脚本,格式化log,用生成的新的log文件供可视化工具绘图,格式化log的extract_log.py脚本如下:
# coding=utf-8
# 该文件用来提取训练log,去除不可解析的log后使log文件格式化,生成新的log文件供可视化工具绘图
def extract_log(log_file,new_log_file,key_word):
f = open(log_file)
train_log = open(new_log_file, 'w')
for line in f:
# 去除多gpu的同步log
if 'Syncing' in line:
continue
# 去除除零错误的log
if 'nan' in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
extract_log('person_train_log.txt','person_train_log_loss.txt','images') #voc_train_log.txt 用于绘制loss曲线
extract_log('person_train_log.txt','person_train_log_iou.txt','IOU')使用train_loss_visualization.py脚本可以绘制loss变化曲线
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines =9873
result = pd.read_csv('person_train_log_loss.txt', skiprows=[x for x in range(lines) if ((x%10!=9) |(x<1000))] ,error_bad_lines=False, names=['loss', 'avg', 'rate', 'seconds', 'images'])
result.head()
result['loss']=result['loss'].str.split(' ').str.get(1)
result['avg']=result['avg'].str.split(' ').str.get(1)
result['rate']=result['rate'].str.split(' ').str.get(1)
result['seconds']=result['seconds'].str.split(' ').str.get(1)
result['images']=result['images'].str.split(' ').str.get(1)
result.head()
result.tail()
#print(result.head())
# print(result.tail())
# print(result.dtypes)
print(result['loss'])
print(result['avg'])
print(result['rate'])
print(result['seconds'])
print(result['images'])
result['loss']=pd.to_numeric(result['loss'])
result['avg']=pd.to_numeric(result['avg'])
result['rate']=pd.to_numeric(result['rate'])
result['seconds']=pd.to_numeric(result['seconds'])
result['images']=pd.to_numeric(result['images'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['avg'].values,label='avg_loss')
#ax.plot(result['loss'].values,label='loss')
ax.legend(loc='best')
ax.set_title('The loss curves')
ax.set_xlabel('batches')
fig.savefig('avg_loss')
#fig.savefig('loss')可以通过分析损失变化曲线,修改cfg中的学习率变化策略,比如上图:模型在100000万次迭代后损失下降速度非常慢,几乎没有下降。结合log和cfg文件发现,自定义的学习率变化策略在十万次迭代时会减小十倍,十万次迭代后学习率下降到非常小的程度,导致损失下降速度降低。修改cfg中的学习率变化策略,10万次迭代时不改变学习率,30万次时再降低。
除了可视化loss,还可以可视化Avg IOU,Avg Recall等参数
可视化’Region Avg IOU’, ‘Class’, ‘Obj’, ‘No Obj’, ‘Avg Recall’,’count’这些参数可以使用脚本train_iou_visualization.py,使用方式和train_loss_visualization.py相同,train_iou_visualization.py脚本如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
lines =9873
result = pd.read_csv('voc_train_log_iou.txt', skiprows=[x for x in range(lines) if (x%10==0 or x%10==9) ] ,error_bad_lines=False, names=['Region Avg IOU', 'Class', 'Obj', 'No Obj', 'Avg Recall','count'])
result.head()
result['Region Avg IOU']=result['Region Avg IOU'].str.split(': ').str.get(1)
result['Class']=result['Class'].str.split(': ').str.get(1)
result['Obj']=result['Obj'].str.split(': ').str.get(1)
result['No Obj']=result['No Obj'].str.split(': ').str.get(1)
result['Avg Recall']=result['Avg Recall'].str.split(': ').str.get(1)
result['count']=result['count'].str.split(': ').str.get(1)
result.head()
result.tail()
#print(result.head())
# print(result.tail())
# print(result.dtypes)
print(result['Region Avg IOU'])
result['Region Avg IOU']=pd.to_numeric(result['Region Avg IOU'])
result['Class']=pd.to_numeric(result['Class'])
result['Obj']=pd.to_numeric(result['Obj'])
result['No Obj']=pd.to_numeric(result['No Obj'])
result['Avg Recall']=pd.to_numeric(result['Avg Recall'])
result['count']=pd.to_numeric(result['count'])
result.dtypes
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.plot(result['Region Avg IOU'].values,label='Region Avg IOU')
#ax.plot(result['Class'].values,label='Class')
#ax.plot(result['Obj'].values,label='Obj')
#ax.plot(result['No Obj'].values,label='No Obj')
#ax.plot(result['Avg Recall'].values,label='Avg Recall')
#ax.plot(result['count'].values,label='count')
ax.legend(loc='best')
#ax.set_title('The Region Avg IOU curves')
ax.set_title('The Region Avg IOU curves')
ax.set_xlabel('batches')
#fig.savefig('Avg IOU')
fig.savefig('Region Avg IOU')xiankaAssertionError: Over-read bin/tiny-yolo.weights
this error is caused by the mismatch between the cfg and binary weight file. Here is the related code which causes it.
At the beginning of flow, it will first try to initialize the TFNet from the given cfg and bin specified by the user in the command line.
# in darkflow/utils/loader.py
class weights_walker(object):
...
self.size = os.path.getsize(path)This walk will read weights from the bin file for each layer with the exact amount of bytes according to the cfg. Before actually reading it, it does a check on if the bytes to read is less than the remaining bytes in the file. Here is the code for that
出现这个错误是由于cfg与weights文件不兼容不匹配,可以下载对应的cfg以及weight文件.
flow --model cfg/yolo-tiny.cfg --load bin/yolo-tiny.weights显示:
Parsing ./cfg/yolo-tiny.cfg
Parsing cfg/yolo-tiny.cfg
Loading bin/yolo-tiny.weights ...
Successfully identified 180357512 bytes
Finished in 0.003332376480102539s
Model has a VOC model name, loading VOC labels.
Building net ...
Source | Train? | Layer description | Output size
-------+--------+----------------------------------+---------------
| | input | (?, 448, 448, 3)
Load | Yep! | scale to (-1, 1) | (?, 448, 448, 3)
Load | Yep! | conv 3x3p1_1 leaky | (?, 448, 448, 16)
Load | Yep! | maxp 2x2p0_2 | (?, 224, 224, 16)
Load | Yep! | conv 3x3p1_1 leaky | (?, 224, 224, 32)
Load | Yep! | maxp 2x2p0_2 | (?, 112, 112, 32)
Load | Yep! | conv 3x3p1_1 leaky | (?, 112, 112, 64)
Load | Yep! | maxp 2x2p0_2 | (?, 56, 56, 64)
Load | Yep! | conv 3x3p1_1 leaky | (?, 56, 56, 128)
Load | Yep! | maxp 2x2p0_2 | (?, 28, 28, 128)
Load | Yep! | conv 3x3p1_1 leaky | (?, 28, 28, 256)
Load | Yep! | maxp 2x2p0_2 | (?, 14, 14, 256)
Load | Yep! | conv 3x3p1_1 leaky | (?, 14, 14, 512)
Load | Yep! | maxp 2x2p0_2 | (?, 7, 7, 512)
Load | Yep! | conv 3x3p1_1 leaky | (?, 7, 7, 1024)
Load | Yep! | conv 3x3p1_1 leaky | (?, 7, 7, 1024)
Load | Yep! | conv 3x3p1_1 leaky | (?, 7, 7, 1024)
Load | Yep! | flat | (?, 50176)
Load | Yep! | full 50176 x 256 linear | (?, 256)
Load | Yep! | full 256 x 4096 leaky | (?, 4096)
Load | Yep! | drop | (?, 4096)
Load | Yep! | full 4096 x 1470 linear | (?, 1470)
-------+--------+----------------------------------+---------------
Running entirely on CPU
2018-06-04 15:45:42.832684: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
2018-06-04 15:45:42.925780: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:892] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2018-06-04 15:45:42.925998: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: GeForce GTX 1050 major: 6 minor: 1 memoryClockRate(GHz): 1.455
pciBusID: 0000:01:00.0
totalMemory: 1.95GiB freeMemory: 1.24GiB
2018-06-04 15:45:42.926014: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: GeForce GTX 1050, pci bus id: 0000:01:00.0, compute capability: 6.1)
Finished in 1.2492377758026123s
Forwarding 8 inputs ...
Total time = 0.750807523727417s / 8 inps = 10.655194237111061 ips
Post processing 8 inputs ...
Total time = 0.20556306838989258s / 8 inps = 38.91749652630382 ips
AssertionError: labels.txt and cfg/yolo-tiny-eye.cfg indicate inconsistent class numbers
flow --model cfg/yolo-new.cfg如种类不同,原来的labels.txt有20个种类,现在只有一个种类.
将classes转换为1.
主要参考:
Darknet】【yolo v2】训练自己数据集的一些心得—-VOC格式
世上最详细,使用Darknet:Yolov3训练数据【看这里】
【YOLO学习】召回率(Recall),精确率(Precision),平均正确率(Average_precision(AP) ),交除并(Intersection-over-Union(IoU))