1. GhostNet
Han, Kai, et al. “Ghostnet: More features from cheap operations.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
本文的题目起得很fancy,有一种神秘的色彩,其实读完文章之后,就会觉得ghost这个比喻非常的有趣也很贴切。阅读本文的前提必须对SENet以及深度可分离卷积这些工作有一定的了解。
我认为这个工作和之前的SqueezeNet的思想也是非常类似,都是采用了两种卷积对特征图进行处理从而达到减少计算量的效果。
在文章的开头,作者就表明了自己工作的motivation,在卷积提取特征图的过程中,作者发现很多特征图其实非常类似,一些特征图可以由其他特征图做一些简单的变换得来。
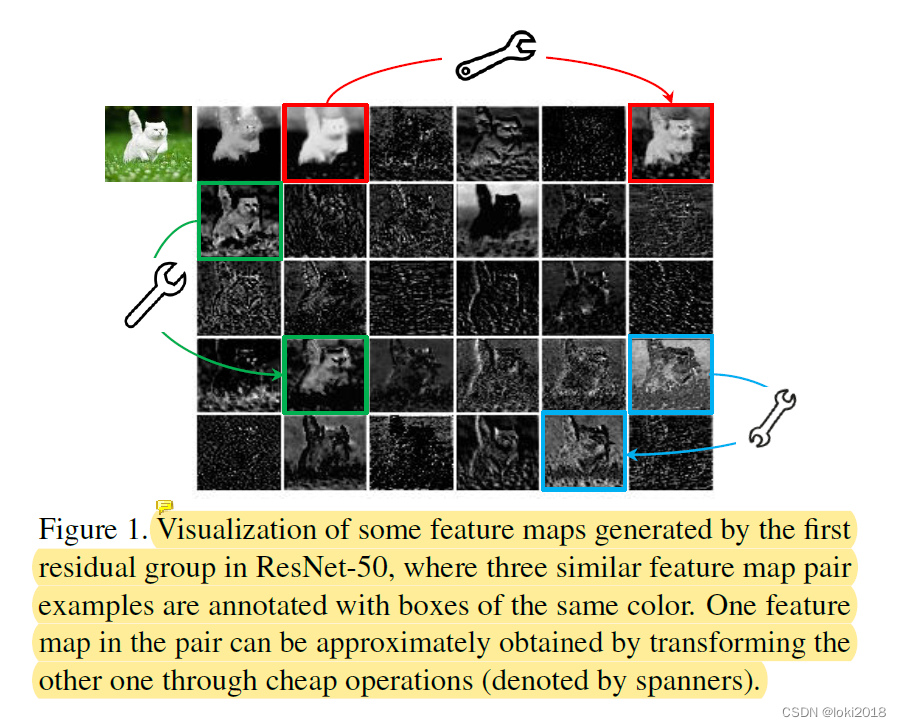
如上图所示,可以很明显地看到很多特征图存在着非常类似的特征,只不过是颜色的深浅的区别,为了减少计算的复杂度,很自然地就会去想是不是可以去除这些过于类似的冗余特征图。然而,作者在文中指出冗余的特征图对于模型的精度还是起着很重要的作用的,因此不能简单地减少特征图的生成数量来实现高效计算。
作者认为冗余特征图就像是其他主要特征图的影子(幻象)一般(这也是文章题目的由来),可以由某些特征图做简单的变换得来,因此,不同于主要的特征图是由复杂的卷积得到,幻象特征图可以通过对主要特征图进行一些简单的卷积操作来得到。
所以,作者提出了一种新的卷积模块,称为GhostModule,将普通的卷积分为了两步,先生成主要的特征图,再由主要的特征图做简单的卷积变换生成幻象特征图,这样可以大大减少计算的开销。
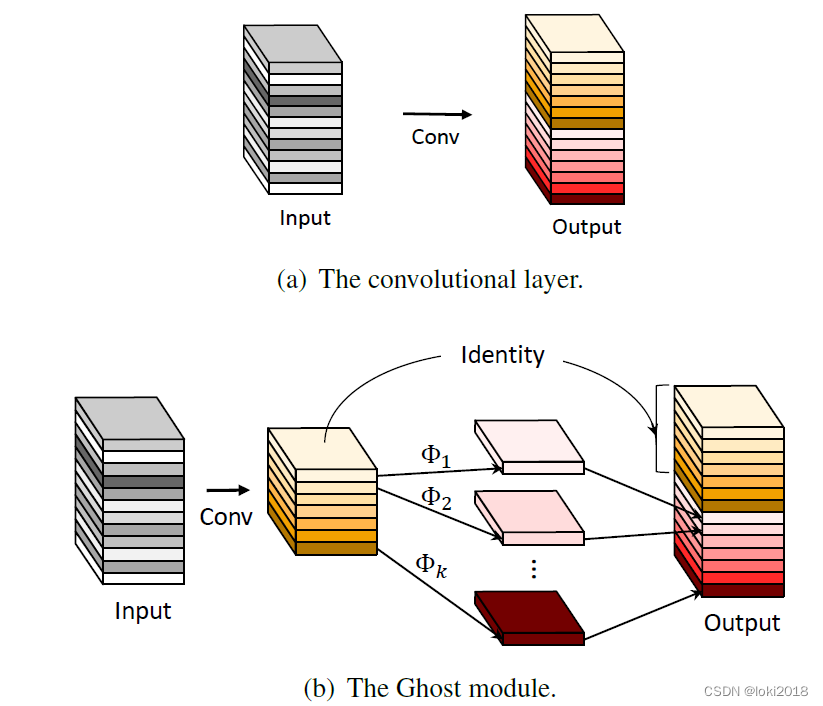
在代码实现中,为了追求效率,生成主要特征图的卷积采用的是1x1的pointwise convolution,而生成幻象特征图采用了3x3或者5x5的depthwise convolution,事实上其实生成幻象特征图的卷积操作并不比生成主要特征图的操作简单多少,但是相对于所有通道做普通的卷积或者深度可分离卷积还是节省不少计算开销的。
2. 代码
import torch
import torch.nn as nn
import torchvision
from torch.utils import data
import matplotlib.pyplot as plt
import copy
import math
def conv1x1(in_channels, out_channels, stride=1, groups=1, bias=False):
# 1x1卷积操作
return nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=1, stride=stride, groups=groups, bias=bias)
def conv3x3(in_channels, out_channels, stride=1, padding=1, dilation=1, groups=1, bias=False):
# 3x3卷积操作
# 默认不是下采样
return nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=3, stride=stride, padding=padding, dilation=dilation,
groups=groups,bias=bias)
class SEBlock(nn.Module):
def __init__(self, channels, reduction=16):
# 提取通道维度上的关系,并不改变最终输出的通道数和特征图形状
super(SEBlock, self).__init__()
mid_channels = channels // reduction # 中间通道数,先进行通道维度的缩放,最后再扩展至和输入通道数相同
self.pool = nn.AdaptiveAvgPool2d(output_size=1) # 相当于每个通道的宽高变为了1x1
self.conv1 = conv1x1(in_channels=channels, out_channels=mid_channels) # squeeze,减少通道数
self.activ = nn.ReLU(inplace=True)
self.conv2 = conv1x1(in_channels=mid_channels, out_channels=channels) # excitation,扩展通道数
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x [batch_size, c, h, w]
# w [batch_size, c, 1, 1]
w = self.pool(x)
w = self.conv1(w)
w = self.activ(w)
w = self.conv2(w)
w = self.sigmoid(w)
x = x * w
return x
def dwconv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=stride,
padding=1,
groups=in_channels,
bias=False)
class GhostModule(nn.Module):
def __init__(self, in_channels, out_channels, ratio=2, stride=1):
# ratio是分割main和cheap的比例
super(GhostModule, self).__init__()
main_out_channels = math.ceil(out_channels / ratio)
cheap_out_channels = out_channels - main_out_channels
self.main_conv = nn.Sequential(
conv1x1(in_channels=in_channels,
out_channels=main_out_channels,
stride=stride),
nn.BatchNorm2d(num_features=main_out_channels),
nn.ReLU(inplace=True)
)
self.cheap_conv = nn.Sequential(
dwconv3x3(in_channels=main_out_channels,
out_channels=cheap_out_channels),
nn.BatchNorm2d(num_features=cheap_out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x1 = self.main_conv(x)
x2 = self.cheap_conv(x1)
out = torch.cat([x1, x2], dim=1)
return out
class GhostBottleNeck(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels, stride, use_se):
super(GhostBottleNeck, self).__init__()
assert stride in [1, 2]
self.conv = nn.Sequential(
GhostModule(in_channels=in_channels,
out_channels=mid_channels,
stride=stride),
SEBlock(channels=mid_channels) if use_se else nn.Sequential(),
GhostModule(in_channels=mid_channels,
out_channels=out_channels)
)
if stride == 1 and in_channels == out_channels:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
dwconv3x3(in_channels=in_channels,
out_channels=in_channels,
stride=stride),
conv1x1(in_channels=in_channels,
out_channels=out_channels),
nn.BatchNorm2d(num_features=out_channels)
)
def forward(self, x):
return self.conv(x) + self.shortcut(x)
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class GhostNet(nn.Module):
def __init__(self, in_channels=1, num_classes=10, input_size=(224, 224), width_mult=1.):
super(GhostNet, self).__init__()
channels = [
# t, c, SE, s
[16, 16, 0, 1],
[48, 24, 0, 2],
[72, 24, 0, 1],
[72, 40, 1, 2],
[120, 40, 1, 1],
[240, 80, 0, 2],
[200, 80, 0, 1],
[184, 80, 0, 1],
[184, 80, 0, 1],
[480, 112, 1, 1],
[672, 112, 1, 1],
[672, 160, 1, 2],
[960, 160, 0, 1],
[960, 160, 1, 1],
[960, 160, 0, 1],
[960, 160, 1, 1]
]
self.features = nn.Sequential()
out_channels = _make_divisible(16 * width_mult, 4)
self.features.add_module("init_block", nn.Sequential(nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=2,
padding=1,
bias=False),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU(inplace=True)))
in_channels = out_channels
for i, (exp_size, c, use_se, stride) in enumerate(channels):
out_channels = _make_divisible(c * width_mult, 4)
mid_channels = _make_divisible(exp_size * width_mult, 4)
self.features.add_module("GhostBlock{}".format(i+1), GhostBottleNeck(
in_channels=in_channels,
mid_channels=mid_channels,
out_channels=out_channels,
stride=stride,
use_se=use_se
))
in_channels = out_channels
out_channels = _make_divisible(exp_size * width_mult, 4)
self.squeeze = nn.Sequential(
conv1x1(in_channels=in_channels, out_channels=out_channels),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d(1)
)
in_channels = out_channels
out_channels = 1280
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=in_channels, out_features=out_channels, bias=False),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(in_features=out_channels, out_features=num_classes),
)
self._init_weights()
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.squeeze(x)
x = self.classifier(x)
return x