分类器:
输入数据,识别是什么类,可以拓展为更广泛的用途。
将特征数据化,作为判断的依据。
和regression有相似的地方,但也有很大区别,把最好不把classification当作regression做


对于有多个分组的如class 1,2,3,直接用1,2.,3代表分组会产生不存在的其他关系,如3和2比3和1要接近,这不是我们想要看到的结果,可以用矩阵向量来表示,后文。
分类器的模型:
因为loss函数不可微分,那么gradient decent的方法就不可用,采用其他方法。

可以用概率来估计以找到最好的function,利用贝叶斯公式求出概率(generative model)

其中C1,C2是先验概率,就是每个整个class的比例,然后根据条件概率求出每个类中找到目标的概率。
其中P(x|C1),可以将data的分布看作高斯分布,二项分布等等分布,利用概率密度函数或者根据频率,以求出概率大小。

Maximum Likelihood:用于寻找概率密度函数之中的参数μ和Σ的最佳值,即L(μ,Σ).

使Sample所有点的几率乘积最大,使数据最准确。

求出最好的参数后就可以根据参数求出每个数据的概率,就可以作classification

但是分类的精度不高,除了采用更多的feature之外(Σ和μ的维数就等于多少个feature),还可以将class1和2中的Σ1,Σ2的二者值经过加权(根据class1,2数目的比例加权)后的到一个Σ,然后class1,2共用一个Σ,可以提高精度,也更常用。L(μ,Σ)也回相应变成L(μ1,μ2,Σ)=......


这样处理后的boundary会变成一条直线

步骤:

倘若每个feature之间确信没有任何关系,可以利用朴素贝叶斯公式的到更简单的模型

如一直宝可梦是不是神兽,回答是yes & No,就是用二次分布
名字中的朴素体现在所有属性变量是独立的:
P ( A 1 ⋯ A m ∣ C i ) = P ( A 1 ∣ C i ) ⋯ P ( A m ∣ C i )
当属性为离散值时,概率可直接根据频率求得;
当属性为连续值时,可由其服从的概率分布求得;
朴素贝叶斯伯努利分类器:https://blog.csdn.net/D802366y/article/details/108366499
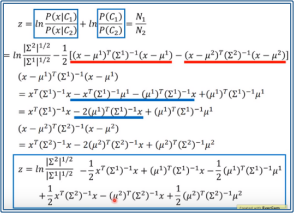
将概率式子和Sigmoid function(https://zhuanlan.zhihu.com/p/24990626)联系起来:

经过一系列化简,我们可以发现z是关于x的一次函数,其中w和b参数可以通过![]() 求得,或者可以直接估计w和b的值,即logistic regression。
求得,或者可以直接估计w和b的值,即logistic regression。