很多人分不清楚分类和回归,我来讲一下,我们经常会碰到这样的问题:
1、如何将信用卡申请人分为低、中、高风险群?
2、如何预测哪些顾客在未来半年内会取消该公司服务,哪些电话用户会申请增值服务?
3、如何预测具有某些特征的顾客是否会购买一台新的计算机?
4、如何预测病人应当接受三种具体治疗方案的哪一种?
5、如何预测一位顾客在一次销售期间将花多少钱?
6、如何预测银行可以安全地贷给贷款人的贷款量?
7、使用 2G 通信网络的手机用户哪些有可能转换到 3G 通信网络?
8、如何有效预测房地产开发中存在的风险?
除此之外,市场经理需要数据分析,以便帮助他来猜测具有某些特征的顾客是否会购买一台新的计算机;医学研究者希望分析乳腺癌数据,预测病人应当接受三种具体治疗方案的哪一种;市场经理希望预测一位顾客在一次销售期间将花多少钱;预测银行可以安全地贷给贷款人的贷款量,这些都是分类与回归的例子。
分类(Classification):分类是指将数据映射到预先定义好的群组或类。因为在分析测试数据之前,类别就已经确定了,所以分类通常被称为有监督的学习。分类算法要求基于数据属性值来定义类别,通常通过已知所属类别的数据的特征来描述类别。
分类就是构造一个分类函数(分类模型),把具有某些特征的数据项映射到某个给定的类别上。
该过程由两步构成:模型创建和模型使用。模型创建是指通过对训练数据集的学习来建立分类模型;模型使用是指使用分类模型对测试数据和新的数据进行分类。其中的训练数据集是带有类标号的,也就是说在分类之前,要划分的类别是已经确定的。通常分类模型是以分类规则,决策树或数学表达式的形式给出。
回归(Regression):用属性的历史数据预测未来趋势。回归首先假设一些已知类型的函数(例如线性函数、Logistic 函数等)可以拟合目标数据,然后利用某种误差分析确定一个与目标数据拟合程度最好的函数。
而回归模式采用连续的预测值。在这种观点下,分类和回归都是预测问题。但在数据挖掘业界,普遍认为:用预测法预测类标号为分类,预测连续值(例如使用回归方法)为预测。许多问题可以用线性回归解决,对于许多非线性问题可以通过对变量进行变化,从而转换为线性问题来解决。
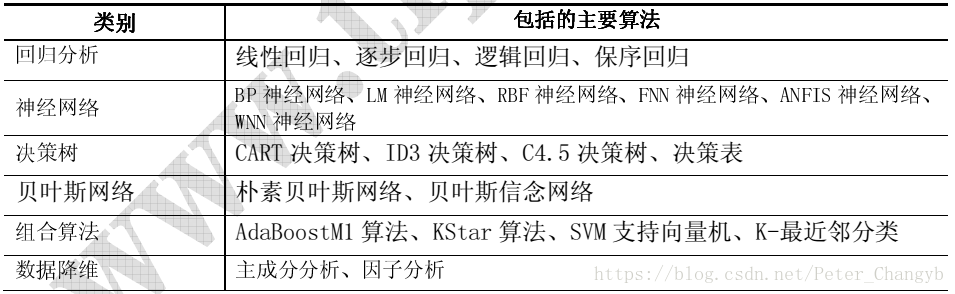
主要算法总结