目录
推荐阅读上篇:CV目标检测面试必备RCNN系列1_crlearning的博客-CSDN博客
前言
在上篇讲解了RCNN以及Fast RCNN的原理,分析了其中还欠缺的问题所在,主要就是预选框的选择依旧导致训练速度慢,所以Faster RCNN应运而生,淘汰Seletive Search作为候选框选择方法,提出使用RPN网络来构建候选框,当然还有特征提出网络,分类和回归分支进行改进。下面来从原理结合代码的角度分析一下
Faster RCNN总体网络结构

通过上面的网络结构图可以看出首先输入一张图片经过特征提取网络得到特征图,然后将特征图复制一份输入到RPN网络得到建议框(就是将基础的anchor进行调整得到的预选框),然后将这些建议框映射到最初的feature map上得到多个特征区域,再将这些特征区域通过RoI pooling得到相同大小(这个过程和Fast RCNN当中的RoI pooling相似),最后通过全连接得到分类结果和box结果。根据上图网络结构我们从下到上的顺序分析,也是训练顺序:
1、特征提取网络下面简称backbone。采用多个卷积操作堆叠,每个卷积操作包括conv+relu+pooling,得到的feature map将输入到RPN和RoI pooling。
2、Region Proposal Networks简称RPN网络。用于生成建议框。
3、RoI pooling。将RPN得到的建议框映射到feature map上,得到的特征区域划分为MxN块对每一块进行最大池化操作。
4、类别分类和回归分支。利用处理好RoIs进行全连接预测,对每个框进行类别预测以及box的位置修正。
下图是backbone为VGG16的网络结构具体结构图:

1、backbone部分直接就是VGG16,一共4个池化,得到的feature map大小为(M/16,N/16)
2、RPN网络结构,首先通过3x3、padding为1的卷积,输出大小(M/16,N/16),分别通过两个1x1卷积,分支上的数字18,36表示输出的维度,9x2,9x4,9表示每个特征点包含的anchor数量,2表示框内背景和有物体的概率,4表示坐标偏移量。
RPN详解
首先分析输出大小是什么?就是每个特征点对应9个anchor,它们是否包含物体,其次对它们进行粗略的估计偏移。
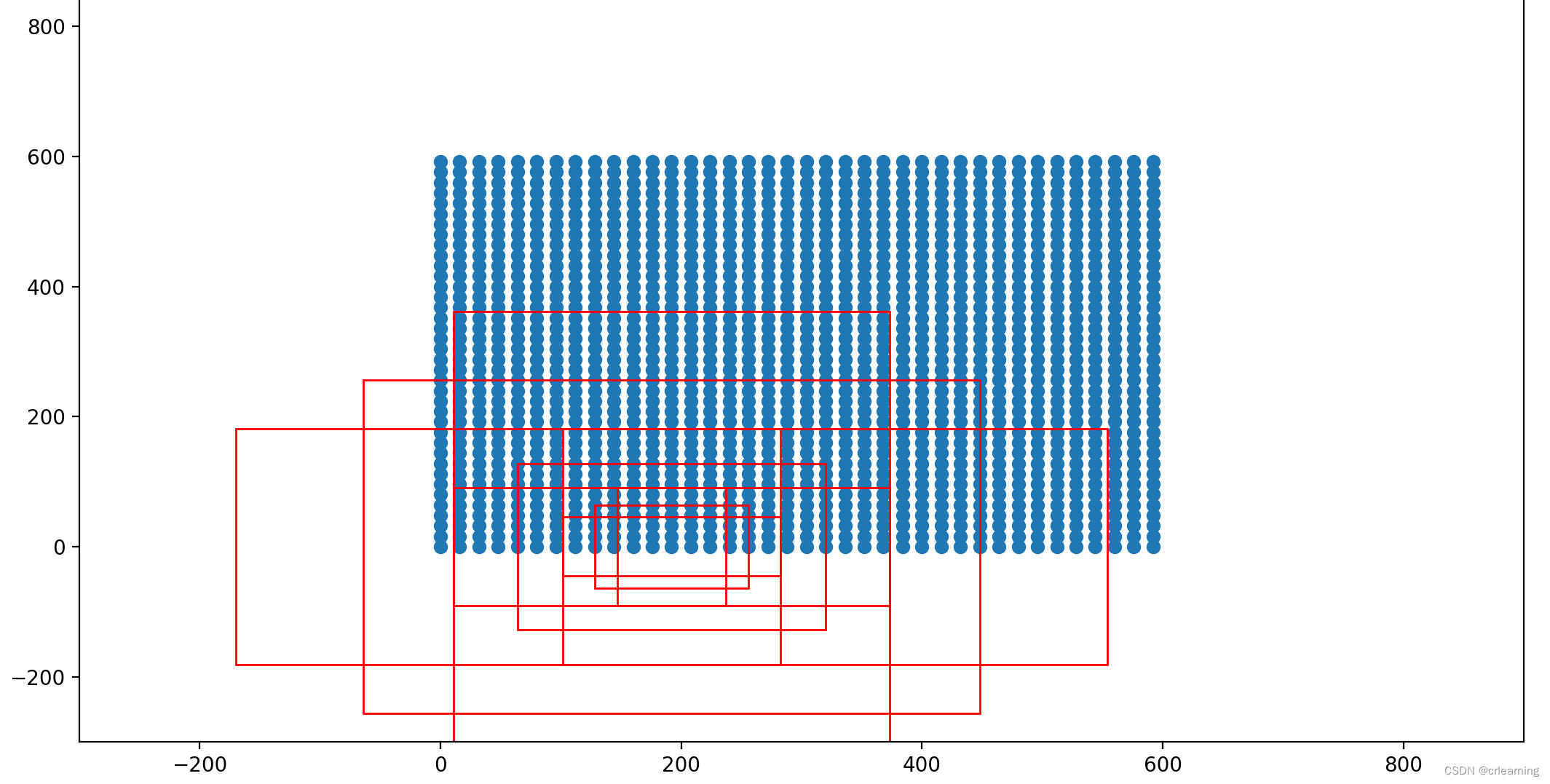
1、其中的9个anchor表示三种形状width:height为(1:1,1:2,2:1),3种大小(8,16,32),这是每个特征点的anchor数量,对于(M/16,N/16)特征图,就有(MxN)/(16x16)x9个anchor。
2、类别分支输出,为(M/16,N/16,9x2),也就是每个特征点一共(MxN)/(16x16)对应的9个anchor中背景的概率和有物体的概率。最终处理后的输出为每个anchor有物体的概率。
# 先进行一个3x3的卷积,可理解为特征整合
self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
# 分类预测先验框内部是否包含物体
self.score = nn.Conv2d(mid_channels, n_anchor * 2, 1, 1, 0)
def forward(self, x, img_size, scale=1.):
# 分类预测先验框内部是否包含物体
rpn_scores = self.score(x)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous().view(n, -1, 2)
# 输出的结果就是(n, (m*n*9)/(16*16), 2)
# 进行softmax概率计算,每个先验框只有两个判别结果
# 内部包含物体或者内部不包含物体,rpn_softmax_scores[:, :, 1]的内容为包含物体的概率
rpn_softmax_scores = F.softmax(rpn_scores, dim=-1)
rpn_fg_scores = rpn_softmax_scores[:, :, 1].contiguous()
rpn_fg_scores = rpn_fg_scores.view(n, -1)3、回归分支输出。为(M/16,N/16,9x4),也就是每个特征点一共(MxN)/(16x16)对应的9个anchor中x,y,w,h的偏移量。
# 先进行一个3x3的卷积,可理解为特征整合
self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
# 回归预测对先验框进行调整
self.loc = nn.Conv2d(mid_channels, n_anchor * 4, 1, 1, 0)
def forward(self, x, img_size, scale=1.):
# 回归预测对先验框进行调整
rpn_locs = self.loc(x)
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
# 输出的结果就是(n, (m*n*9)/(16*16), 4)最后根据分类得分分支和回归分支对起初的先验框进行修正,以及非极大值抑制处理。最终得到可能包含物体并处理好的建议框.
# 将RPN网络预测的位置结果对anchor进行调整转化成建议框
roi = loc2bbox(anchor, loc)
# 对这些框进行处理,防止建议框超出图像边缘
roi[:, [0, 2]] = torch.clamp(roi[:, [0, 2]], min = 0, max = img_size[1])
roi[:, [1, 3]] = torch.clamp(roi[:, [1, 3]], min = 0, max = img_size[0])
# 根据每个框的得分进行排序,取出建议框,为了后续的非极大值抑制
order = torch.argsort(score, descending=True)
# 得分小于n_pre_nms的框进行剔除
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
score = score[order]
# 使用pytorch官方的非极大值抑制,对建议框进行非极大抑制
keep = nms(roi, score, self.nms_iou)
keep = keep[:n_post_nms]
roi = roi[keep]
return roi
以上就完成了RPN代码的整体流程,也就是一个筛选候选框的过程,对比起Fast RCNN的SS算法可谓是大提升,并没有重复的进行卷积运算,更快.
RoI Pooling
直接上代码,原理可以去看看上一篇中Fast RCNN提到的
from torchvision.ops import RoIPool
# 官方提供的ROI借口
self.roi = RoIPool((roi_size, roi_size), spatial_scale)
def forward(self, x, rois, roi_indices, img_size):
# rois(n, number, 4)number为经过RPN的非极大值抑制后每个feature map上有物体的框
rois = torch.flatten(rois, 0, 1)
# rois(n*number, 4)沿着第一维度和第二维度展开
roi_indices = torch.flatten(roi_indices, 0, 1)
rois_feature_map = torch.zeros_like(rois)
# 将roi框对应到feature map的大小
rois_feature_map[:, [0,2]] = rois[:, [0,2]] / img_size[1] * x.size()[3]
rois_feature_map[:, [1,3]] = rois[:, [1,3]] / img_size[0] * x.size()[2]
indices_and_rois = torch.cat([roi_indices[:, None], rois_feature_map], dim=1)
# 利用建议框对公用特征层进行截取
pool = self.roi(x, indices_and_rois)
预测层
# 对ROIPooling后的的结果进行回归预测
self.cls_loc = nn.Linear(2048, n_class * 4)
# 对ROIPooling后的的结果进行分类
self.score = nn.Linear(2048, n_class)
def forward(self, x, rois, roi_indices, img_size):
# 利用classifier网络进行特征提取,拉成一维向量,n代表batchsize(n, m)
# m表示number*7*7
pool = pool.view(pool.size(0), -1)
# 当输入为一张图片的时候,这里获得的f7的shape为[n, 2048]
# 这里根据不同的backbone输出不同
fc7 = self.classifier(pool)
roi_cls_locs = self.cls_loc(fc7)
roi_scores = self.score(fc7)
roi_cls_locs = roi_cls_locs.view(n, -1, roi_cls_locs.size(1))
roi_scores = roi_scores.view(n, -1, roi_scores.size(1))
return roi_cls_locs, roi_scores
训练中Loss计算
loss包括4个部分,rpn二分类损失,rpn框回归损失,预测分类损失,预测框回归损失,详见代码
# 输入真实标签
def forward(self, imgs, bboxes, labels, scale):
# 利用rpn网络获得调整参数、得分、建议框、先验框
rpn_locs, rpn_scores, rois, roi_indices, anchor = self.model_train(x = [base_feature, img_size], scale = scale, mode = 'rpn')
rpn_loc_loss_all, rpn_cls_loss_all, roi_loc_loss_all, roi_cls_loss_all = 0, 0, 0, 0
sample_rois, sample_indexes, gt_roi_locs, gt_roi_labels = [], [], [], []
# n为batch数量,代表几张图片
for i in range(n):
bbox = bboxes[i]
label = labels[i]
rpn_loc = rpn_locs[i]
rpn_score = rpn_scores[i]
roi = rois[i]
# 利用真实框和先验框获得建议框网络应该有的预测结果
# 给每个先验框都打上标签
# gt_rpn_loc [num_anchors, 4]
# gt_rpn_label [num_anchors]
gt_rpn_loc, gt_rpn_label = self.anchor_target_creator(bbox, anchor[0])
# 分别计算建议框网络的回归损失和分类损失
rpn_loc_loss = self._fast_rcnn_loc_loss(rpn_loc, gt_rpn_loc, gt_rpn_label, self.rpn_sigma)
rpn_cls_loss = F.cross_entropy(rpn_score, gt_rpn_label, ignore_index=-1)
rpn_loc_loss_all += rpn_loc_loss
rpn_cls_loss_all += rpn_cls_loss
# 利用真实框和建议框获得classifier网络应该有的预测结果
# 获得三个变量,分别是sample_roi, gt_roi_loc, gt_roi_label
# sample_roi [n_sample, ]
# gt_roi_loc [n_sample, 4]
# gt_roi_label [n_sample, ]
sample_roi, gt_roi_loc, gt_roi_label = self.proposal_target_creator(roi, bbox, label, self.loc_normalize_std)
sample_rois.append(sample_roi)
sample_indexes.append(len(sample_roi) * roi_indices[i][0])
gt_roi_locs.append(gt_roi_loc)
gt_roi_labels.append(gt_roi_label)
sample_rois = torch.stack(sample_rois, dim=0)
sample_indexes = torch.stack(sample_indexes, dim=0)
roi_cls_locs, roi_scores = self.model_train([base_feature, sample_rois, sample_indexes, img_size], mode = 'head')
for i in range(n):
# 根据建议框的种类,取出对应的回归预测结果
n_sample = roi_cls_locs.size()[1]
roi_cls_loc = roi_cls_locs[i]
roi_score = roi_scores[i]
gt_roi_loc = gt_roi_locs[i]
gt_roi_label = gt_roi_labels[i]
roi_cls_loc = roi_cls_loc.view(n_sample, -1, 4)
roi_loc = roi_cls_loc[torch.arange(0, n_sample), gt_roi_label]
# 分别计算Classifier网络的回归损失和分类损失
roi_loc_loss = self._fast_rcnn_loc_loss(roi_loc, gt_roi_loc, gt_roi_label.data, self.roi_sigma)
roi_cls_loss = nn.CrossEntropyLoss()(roi_score, gt_roi_label)
roi_loc_loss_all += roi_loc_loss
roi_cls_loss_all += roi_cls_loss
losses = [rpn_loc_loss_all/n, rpn_cls_loss_all/n, roi_loc_loss_all/n, roi_cls_loss_all/n]
losses = losses + [sum(losses)]
return losses
总结
Faster RCNN再yolov3之前还是非常有影响力的,但是随着yolo系列的快速发展,Faster RCNN已经跟不上实时检测的要求,但是其中的很多知识点还是非常值得我们去学习,其中可以RPN结合FPN提高对小目标的信息提取,二阶段还有Mask RCNN等.
参考文章(极力推荐):
一文读懂Faster RCNN - 知乎 (zhihu.com)
睿智的目标检测27——Pytorch搭建Faster R-CNN目标检测平台_Bubbliiiing的博客-CSDN博客