目录
# 导入必要的包
import os
import numpy as np
import collections
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
1. 模型定义方式(三种)
# (1)Sequential:Direct list
import torch.nn as nn
net1 = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net1) # 没有层名,每层的序号可用于索引

# (1)Sequential: Ordered Dict
import collections
import torch.nn as nn
net2 = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net2) # 每层都有名字,但是读取某一层还是需要用序号索引,层名没有索引功能

# 可以看到,上面两种定义方式没有根本区别
a = torch.rand(4,784)
out1 = net1(a)
out2 = net2(a)
print(out1.shape==out2.shape, out1.shape)

#(2)ModuleList
net3 = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
net3.append(nn.Linear(256, 10)) # 类似List的append操作
print(net3[-1]) # 类似List的索引访问
print(net3)
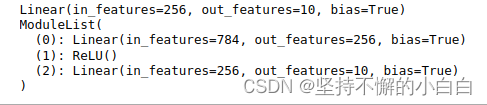
# 注意ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起。此处应报错
out3 = net3(a)

# 这样就没问题了
class Net3(nn.Module):
def __init__(self):
super().__init__()
self.modulelist = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
self.modulelist.append(nn.Linear(256, 10))
def forward(self, x):
for layer in self.modulelist:
x = layer(x)
return x
net3_ = Net3()
out3_ = net3_(a)
print(out3_.shape)

#(3)ModuleDict
net4 = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net4['output'] = nn.Linear(256, 10) # 可以通过名称添加层
print(net4['linear']) # 可以通过名称索引访问
print(net4.output)

注:
nn.ModuleDict可以通过名称索引对应网络层,nn.Sequential不可以- 同样地,
nn.ModuleDict并没有定义一个网络,它只是将不同的模块储存在一起
2. 利用模型块快速搭建复杂网络
以U-Net网络的搭建为例。
# 导入必要的包
import os
import numpy as np
import collections
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
# (1)每个子块内部有两次卷积,这里构建两次的卷积 模型块
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
# (2)左侧模块之间的下采样连接 模型块
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
# (3)右侧模块之间的上采样连接 模型块
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
# (4)输出层处理
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
# 组装模型块
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64) # (1)
self.down1 = Down(64, 128) # (2)
self.down2 = Down(128, 256) # (2)
self.down3 = Down(256, 512) # (2)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor) # (2)
self.up1 = Up(1024, 512 // factor, bilinear) # (3)
self.up2 = Up(512, 256 // factor, bilinear) # (3)
self.up3 = Up(256, 128 // factor, bilinear) # (3)
self.up4 = Up(128, 64, bilinear) # (3)
self.outc = OutConv(64, n_classes) # (4)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
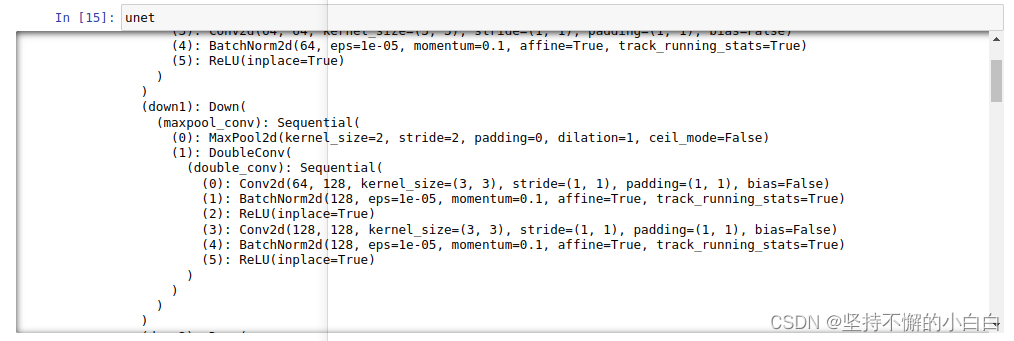
unet = UNet(3,1) # 输入3通道数据,输出1通道数据
unet

3. 模型修改
## 修改特定层
import copy
unet1 = copy.deepcopy(unet)
unet1.outc # 输出层

b = torch.rand(1,3,224,224)
out_unet1 = unet1(b)
print(out_unet1.shape) # 原模型输出
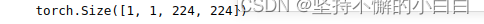
unet1.outc = OutConv(64, 5) # 输出层的输出通道改成5
unet1.outc

out_unet1 = unet1(b)
print(out_unet1.shape) # 修改后的模型输出

# 添加额外输入
class UNet2(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet2, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x, add_variable):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = x + add_variable # 修改点,在输出层的前面添加一个额外输入
logits = self.outc(x)
return logits
unet2 = UNet2(3,1)
c = torch.rand(1,1,224,224)
out_unet2 = unet2(b, c)
print(out_unet2.shape)
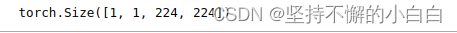
# 添加额外输出
class UNet3(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet3, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits, x5 # 修改点,多输出一层的值
unet3 = UNet3(3,1)
c = torch.rand(1,1,224,224)
out_unet3, mid_out = unet3(b)
print(out_unet3.shape, mid_out.shape)
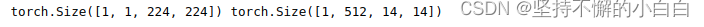
4. 模型保存与读取
#(1.1)CPU或单卡:保存&读取整个模型
torch.save(unet, "./unet_example.pth")
loaded_unet = torch.load("./unet_example.pth")
loaded_unet.state_dict()
#(1.2)CPU或单卡:保存&读取模型权重
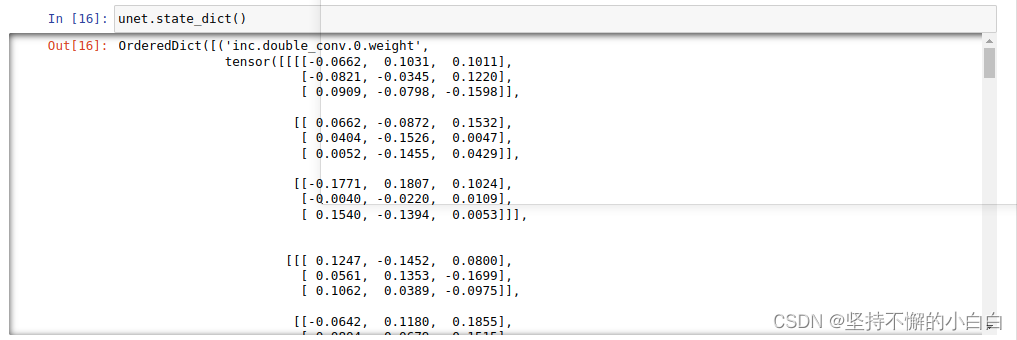
torch.save(unet.state_dict(), "./unet_weight_example.pth")
loaded_unet_weights = torch.load("./unet_weight_example.pth")
unet.load_state_dict(loaded_unet_weights)
unet.state_dict()
#(2.1) 多卡:保存&读取整个模型。注意模型层名称前多了module
# 不建议,因为保存模型的GPU_id等信息和读取后训练环境可能不同,尤其是要把保存的模型交给另一用户使用的情况
os.environ['CUDA_VISIBLE_DEVICES'] = '2,3'
unet_mul = copy.deepcopy(unet)
unet_mul = nn.DataParallel(unet_mul).cuda()
torch.save(unet_mul, "./unet_mul_example.pth")
loaded_unet_mul = torch.load("./unet_mul_example.pth")
loaded_unet_mul
#(2.2) 多卡:保存&读取模型权重。
torch.save(unet_mul.state_dict(), "./unet_weight_mul_example.pth")
loaded_unet_weights_mul = torch.load("./unet_weight_mul_example.pth")
unet_mul.load_state_dict(loaded_unet_weights_mul)
unet_mul = nn.DataParallel(unet_mul).cuda()
unet_mul.state_dict()
#(2.3)另外,如果保存的是整个模型,也建议采用提取权重的方式构建新的模型:
unet_mul.state_dict = loaded_unet_mul.state_dict
unet_mul = nn.DataParallel(unet_mul).cuda()
unet_mul.state_dict()
5. 使用Carvana数据集,实现一个基本的U-Net训练过程
# 导入必要的包
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import torch.optim as optim
import torch.nn as nn
import matplotlib.pyplot as plt
import PIL
from sklearn.model_selection import train_test_split
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 分配训练的GPU
# Carvana数据集下载地址:kaggle.com/competitions/carvana-image-masking-challenge
# 只需要下载其中的train.zip(424.23M)和train_masks.zip(30.54M)
class CarvanaDataset(Dataset):
def __init__(self, base_dir, idx_list, mode="train", transform=None):
self.base_dir = base_dir
self.idx_list = idx_list
self.images = os.listdir(base_dir+"train") # 将kaggle中数据集trian.zip下到指定目录并解压
self.masks = os.listdir(base_dir+"train_masks") # 将kaggle中数据集trian_masks.zip下到指定目录并解压
self.mode = mode
self.transform = transform
def __len__(self):
return len(self.idx_list)
def __getitem__(self, index):
image_file = self.images[self.idx_list[index]]
mask_file = image_file[:-4]+"_mask.gif"
image = PIL.Image.open(os.path.join(base_dir, "train", image_file))
if self.mode=="train":
mask = PIL.Image.open(os.path.join(base_dir, "train_masks", mask_file))
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
mask[mask!=0] = 1.0
return image, mask.float()
else:
if self.transform is not None:
image = self.transform(image)
return image
base_dir = "/home/cloris/Downloads/" # 我电脑里的指定目录
transform = transforms.Compose([transforms.Resize((256,256)), transforms.ToTensor()])
train_idxs, val_idxs = train_test_split(range(len(os.listdir(base_dir+"train_masks"))), test_size=0.3)
train_data = CarvanaDataset(base_dir, train_idxs, transform=transform)
val_data = CarvanaDataset(base_dir, val_idxs, transform=transform)
train_loader = DataLoader(train_data, batch_size=32, num_workers=4, shuffle=True)
val_loader = DataLoader(train_data, batch_size=32, num_workers=4, shuffle=False)
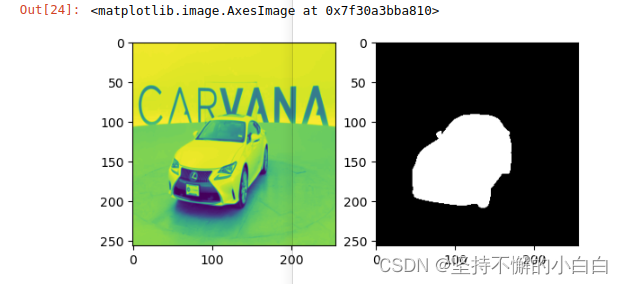
image, mask = next(iter(train_loader)) # 从可迭代对象train_loader中依次取元素
plt.subplot(121)
plt.imshow(image[0,0])
plt.subplot(122)
plt.imshow(mask[0,0], cmap="gray")
# 使用Binary Cross Entropy Loss,之后会尝试替换为自定义的loss
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(unet.parameters(), lr=1e-3, weight_decay=1e-8) # 优化器,Adam梯度下降
unet = nn.DataParallel(unet).cuda() # unet还是上面定义的那个网络
def dice_coeff(pred, target): # dice coefficient:一种集合相似度度量函数,计算两个样本之间的相似度
eps = 0.0001
eps = 0.0001
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + eps) / (m1.sum() + m2.sum() + eps)
def train(epoch):
unet.train()
train_loss = 0
for data, mask in train_loader:
data, mask = data.cuda(), mask.cuda()
optimizer.zero_grad()
output = unet(data)
loss = criterion(output,mask)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
print("current learning rate: ", optimizer.state_dict()["param_groups"][0]["lr"])
unet.eval()
val_loss = 0
dice_score = 0
with torch.no_grad():
for data, mask in val_loader:
data, mask = data.cuda(), mask.cuda()
output = unet(data)
loss = criterion(output, mask)
val_loss += loss.item()*data.size(0)
dice_score += dice_coeff(torch.sigmoid(output).cpu(), mask.cpu())*data.size(0)
val_loss = val_loss/len(val_loader.dataset)
dice_score = dice_score/len(val_loader.dataset)
print('Epoch: {} \tValidation Loss: {:.6f}, Dice score: {:.6f}'.format(epoch, val_loss, dice_score))
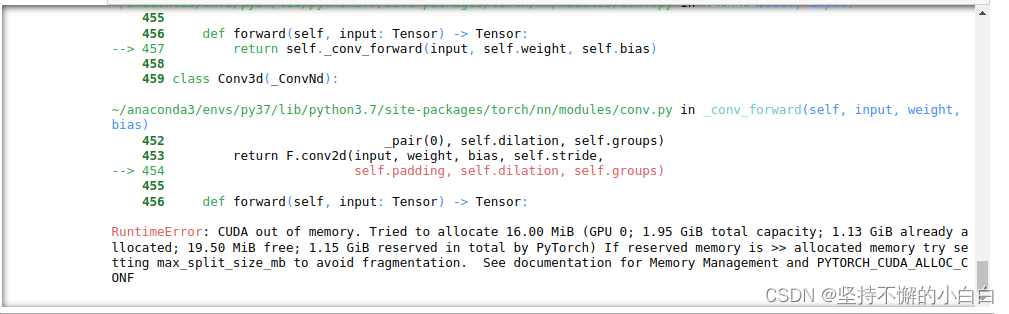
epochs = 100
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
代码正常,报错原因是显卡内存不够用
6. 自定义损失函数
class DiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceLoss, self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = torch.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
newcriterion = DiceLoss()
unet.eval()
image, mask = next(iter(val_loader))
out_unet = unet(image.cuda())
loss = newcriterion(out_unet, mask.cuda())
print(loss)
7. 动态调整学习率
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.8)
epochs = 100
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
scheduler.step()
8. 模型微调
unet.module.outc.conv.weight.requires_grad = False
unet.module.outc.conv.bias.requires_grad = False
for layer, param in unet.named_parameters():
print(layer, '\t', param.requires_grad)
Parameter containing:
tensor([-0.1994], device='cuda:0')
9. 半精度训练
# 演示时需要restart kernel,并运行Unet模块
from torch.cuda.amp import autocast
os.environ['CUDA_VISIBLE_DEVICES'] = '2,3'
class CarvanaDataset(Dataset):
def __init__(self, base_dir, idx_list, mode="train", transform=None):
self.base_dir = base_dir
self.idx_list = idx_list
self.images = os.listdir(base_dir+"train")
self.masks = os.listdir(base_dir+"train_masks")
self.mode = mode
self.transform = transform
def __len__(self):
return len(self.idx_list)
def __getitem__(self, index):
image_file = self.images[self.idx_list[index]]
mask_file = image_file[:-4]+"_mask.gif"
image = PIL.Image.open(os.path.join(base_dir, "train", image_file))
if self.mode=="train":
mask = PIL.Image.open(os.path.join(base_dir, "train_masks", mask_file))
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
mask[mask!=0] = 1.0
return image, mask.float()
else:
if self.transform is not None:
image = self.transform(image)
return image
base_dir = "./"
transform = transforms.Compose([transforms.Resize((256,256)), transforms.ToTensor()])
train_idxs, val_idxs = train_test_split(range(len(os.listdir(base_dir+"train_masks"))), test_size=0.3)
train_data = CarvanaDataset(base_dir, train_idxs, transform=transform)
val_data = CarvanaDataset(base_dir, val_idxs, transform=transform)
train_loader = DataLoader(train_data, batch_size=32, num_workers=4, shuffle=True)
val_loader = DataLoader(train_data, batch_size=32, num_workers=4, shuffle=False)
class UNet_half(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet_half, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
@autocast()
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
unet_half = UNet_half(3,1)
unet_half = nn.DataParallel(unet_half).cuda()
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(unet_half.parameters(), lr=1e-3, weight_decay=1e-8)
def dice_coeff(pred, target):
eps = 0.0001
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + eps) / (m1.sum() + m2.sum() + eps)
def train_half(epoch):
unet_half.train()
train_loss = 0
for data, mask in train_loader:
data, mask = data.cuda(), mask.cuda()
with autocast():
optimizer.zero_grad()
output = unet_half(data)
loss = criterion(output,mask)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val_half(epoch):
print("current learning rate: ", optimizer.state_dict()["param_groups"][0]["lr"])
unet_half.eval()
val_loss = 0
dice_score = 0
with torch.no_grad():
for data, mask in val_loader:
data, mask = data.cuda(), mask.cuda()
with autocast():
output = unet_half(data)
loss = criterion(output, mask)
val_loss += loss.item()*data.size(0)
dice_score += dice_coeff(torch.sigmoid(output).cpu(), mask.cpu())*data.size(0)
val_loss = val_loss/len(val_loader.dataset)
dice_score = dice_score/len(val_loader.dataset)
print('Epoch: {} \tValidation Loss: {:.6f}, Dice score: {:.6f}'.format(epoch, val_loss, dice_score))
epochs = 100
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.8)
for epoch in range(1, epochs+1):
train_half(epoch)
val_half(epoch)
scheduler.step()
引用:
[1] datawhalechina/thorough-pytorch: https://github.com/datawhalechina/thorough-pytorch