论文:https://arxiv.org/abs/1710.09412
代码:https://github.com/facebookresearch/mixup-cifar10
1. 论文核心

(xi,yi)和(xj,yj)是从训练数据中随机抽取的两个样本,且λ∈[0,1]。因此,mixup通过结合先验知识,即特征向量的线性插值应导致相关标签的线性插值,来扩展训练分布。mixup仅需要几行代码即可实现,且引入了最小计算开销。
注意:yi和yj都必须时独热编码的形式。
通俗理解:将输入的数据进行一定比例的混合,标签以相同比例进行线性组合。
2. 代码实现
def mixup_data(x, y, alpha=0.2, use_cuda=True):
'''Returns mixed inputs, pairs of targets, and lambda'''
if alpha > 0:
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
########在train函数中做以下修改,其他地方不做任何修改
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets_a, targets_b, lam = mixup_data(inputs, targets)
outputs = net(inputs)
loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam)
可见,mixup实现起来非常简单。博主将该trick融入自己的项目中,如果需要就开启该功能。
3. 实验效果
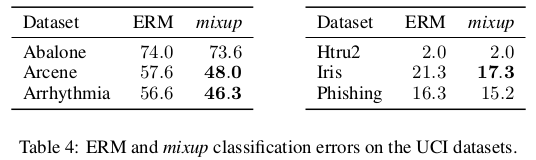
可见,用了mixup,在UCI数据集上得到了更低的错误率。当然,作者还做了很多其他实验,这里不再赘述。
小结:该trick用几十行代码即可实现,并且丝毫不影响模型识别速度,值得尝试。另外,mixup和label smoothing结合起来使用效果更佳。