一、自定义损失函数
- PyTorch中自定义了许多常用损失函数,前面的笔记Linux深入浅出PyTorch(二)中列出了15个损失函数,如MSELoss,L1Loss等
- 随着发展,出现了许多非官方提供的Loss,如DiceLoss,HuberLoss等
- 非官方提供的Loss,专门针对一些非通用的模型,需要通过自定义损失函数方式实现;若需提出全新的损失函数,也需要自定义。
1. 以函数方式定义
def my_loss(output, target):
loss = torch.mean((output - target)**2) # 差的平方再求平均
return loss
2. 以类方式定义
- 比较常用
- Loss 函数部分继承自
-loss,部分继承自_WeightedLoss,_WeightedLoss继承自_loss,_loss继承自nn.Module - 可以将 Loss 当作神经网络的一层来对待,所以自定义损失函数类需要继承自
nn.Module类。
以DiceLoss为例:
- DiceLoss是一种在分割领域常见的损失函数
- Dice 可以理解为是两个轮廓区域的相似程度,用A、B表示两个轮廓区域所包含的点集,定义如下 [2]:
D S C = 2 ∣ X ∩ Y ∣ ∣ X ∣ + ∣ Y ∣ DSC = \frac{2|X∩Y|}{|X|+|Y|} DSC=∣X∣+∣Y∣2∣X∩Y∣ - 也可以表示为(TP,FP,FN分别是真阳性、假阳性、假阴性的个数)[2]:
D S C = 2 T P 2 T P + F N + F P DSC = \frac{2TP}{2TP+FN+FP} DSC=2TP+FN+FP2TP - 实现代码如下:
class DiceLoss(nn.Module): # 继承自nn.Module类
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1) # view:将原Tensor按照行优先的书序排成一维数据
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
# 使用方法
criterion = DiceLoss() # 实例化
loss = criterion(input, targets)
3. 其他常见的自定义损失函数
(1)BCE-Dice Loss
Dice Loss + Binary Cross Entropy(二分类交叉熵损失函数)
class DiceBCELoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceBCELoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice_loss = 1 - (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')
Dice_BCE = BCE + dice_loss
return Dice_BCE
(2)Jaccard/Intersection over Union (IoU) Loss
- 在图像分割领域,IoU定义(TP,FP,FN分别是真阳性、假阳性、假阴性的个数) [2]:
I o U = T P T P + F P + F N IoU=\frac{TP}{TP+FP+FN} IoU=TP+FP+FNTP - 作为Loss function,定义为(X为预测值, Y为真实标签) [2]:
I o U = I ( X ) U ( X ) , I ( X ) = X ∗ Y , U ( X ) = X + Y − X ∗ Y IoU=\frac{I(X)}{U(X)}, I(X)=X*Y, U(X)=X+Y-X*Y IoU=U(X)I(X),I(X)=X∗Y,U(X)=X+Y−X∗Y - 代码如下:
class IoULoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(IoULoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
total = (inputs + targets).sum()
union = total - intersection
IoU = (intersection + smooth)/(union + smooth)
return 1 - IoU
(3)Focal Loss
- focal loss的提出是在目标检测领域,为了解决正负样本比例严重失衡的问题,是由log loss改进而来的 [2]
- 公式如下 [2]:
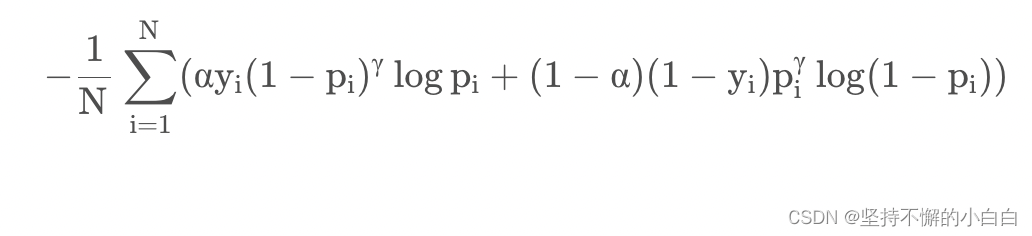
ALPHA = 0.8
GAMMA = 2
class FocalLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(FocalLoss, self).__init__()
def forward(self, inputs, targets, alpha=ALPHA, gamma=GAMMA, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')
BCE_EXP = torch.exp(-BCE)
focal_loss = alpha * (1-BCE_EXP)**gamma * BCE
return focal_loss
注意:自定义损失函数需要数学运算时,最好全程使用PyTorch提供的张量计算接口,这样就不需要单独实现自动求导功能,并且可以直接调用cuda。
二、动态调整学习率
学习率 [3]:
- 梯度下降的过程中更新权重时的超参数;
- 学习率越低,损失函数的变化速度就越慢,容易过拟合;
- 学习率过高容易发生梯度爆炸,loss振动幅度较大,模型难以收敛;
- 选定一个合适的学习率,经过许多轮的训练后,可能会出现准确率震荡或loss不再下降等情况,说明当前学习率已不能满足模型调优的需求,此时可以设计一个适当的学习率衰减策略来改善这种现象,提高精度。这种设置方式在PyTorch中被称为scheduler。
1. 使用官方scheduler
PyTorch在torch.optim.lr_scheduler封装好了一些动态调整学习率的方法,如:
lr_scheduler.LambdaLRlr_scheduler.MultiplicativeLRlr_scheduler.StepLRlr_scheduler.MultiStepLRlr_scheduler.ExponentialLRlr_scheduler.CosineAnnealingLRlr_scheduler.ReduceLROnPlateaulr_scheduler.CyclicLRlr_scheduler.OneCycleLRlr_scheduler.CosineAnnealingWarmRestarts
使用方法如下:
# 选择一种优化器
optimizer = torch.optim.Adam(...)
# 选择上面提到的一种或多种动态调整学习率的方法
scheduler1 = torch.optim.lr_scheduler....
scheduler2 = torch.optim.lr_scheduler....
...
schedulern = torch.optim.lr_scheduler....
# 进行训练
for epoch in range(100):
train(...)
validate(...)
optimizer.step()
# 需要在优化器参数更新之后再动态调整学习率
# scheduler的优化是在每一轮后面进行的
scheduler1.step()
...
schedulern.step()
注意:在使用官方给出的torch.optim.lr_scheduler时,需要将scheduler.step()放在optimizer.step()后面进行使用
2. 自定义scheduler
通过自定义函数adjust_learning_rate来改变param_group中lr的值。
如自定义一个学习率每30轮下降为原来的1/10的scheduler:
def adjust_learning_rate(optimizer, epoch):
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
有了adjust_learning_rate函数的定义,在训练的过程就可以调用它来实现学习率的动态变化:
def adjust_learning_rate(optimizer,...):
...
optimizer = torch.optim.SGD(model.parameters(),lr = args.lr,momentum = 0.9)
for epoch in range(10):
train(...)
validate(...)
adjust_learning_rate(optimizer,epoch)
三、模型微调
小型数据集去训练有几千万参数的大型神经网络是不现实的,想要训练大型的模型,需要:
- 收集大量的数据(成本太高)
或 - 应用迁移学习(transfer learning):将从源数据集学到的知识迁移到目标数据集上
迁移学习的一大应用场景是模型微调(finetune):先找到一个同类的别人训练好的模型,拿过来换成自己的数据,通过训练调整一下参数。
1. 模型微调 — torchvision
PyTorch中提供了许多预训练好的网络模型(VGG,ResNet系列等等),可以使用模型微调,快速用这些预训练模型完成自己的任务。
(1)模型微调流程
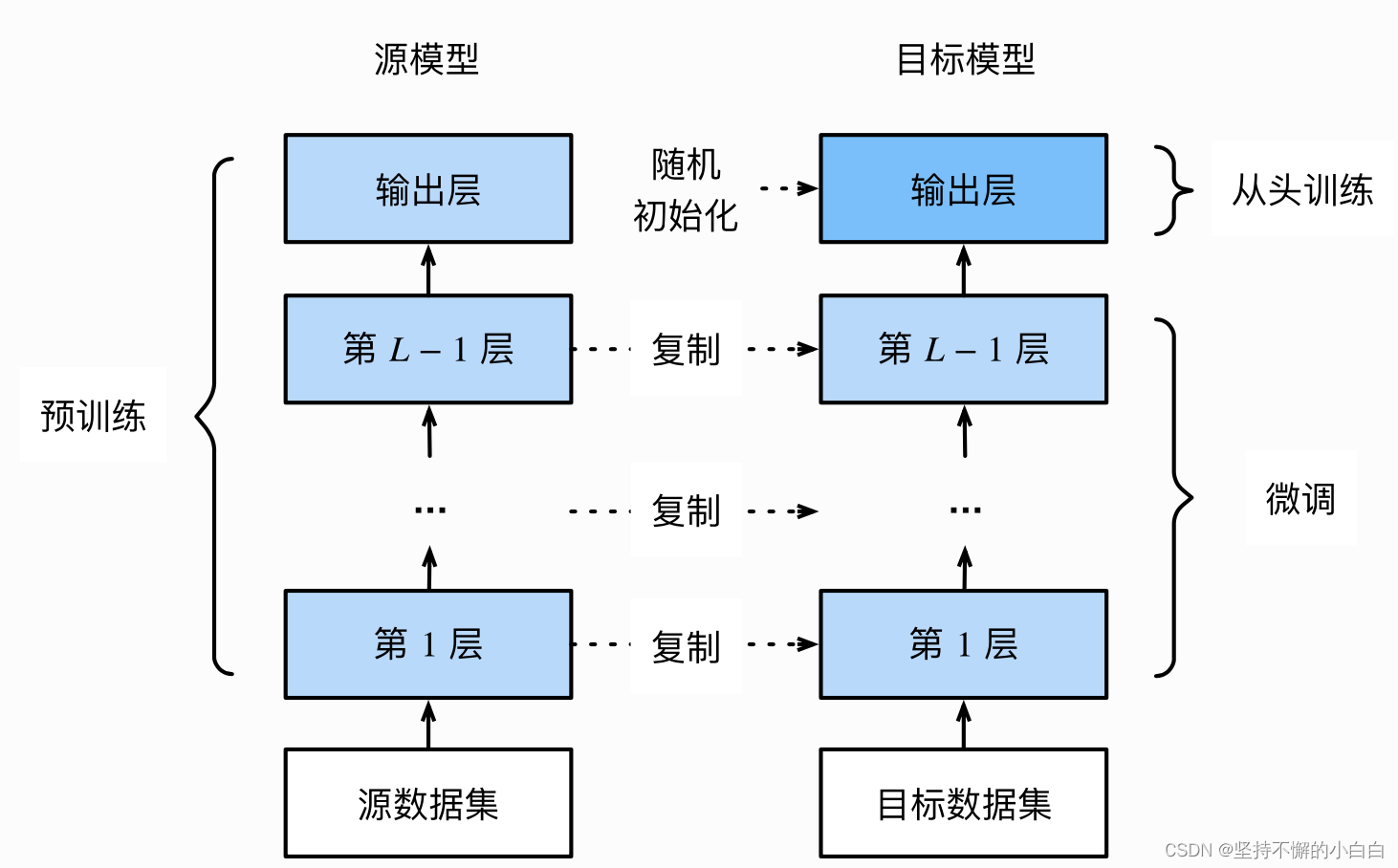
- 在源数据集上预训练一个神经网络模型(即源模型);
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。满足两个假设:
(1)假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集;
(2)假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。 - 为目标模型添加一个输出⼤小为⽬标数据集类别个数的输出层,并随机初始化该层的模型参数;
- 在目标数据集上训练目标模型。从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。如图:
(2)使用已有的模型结构
以torchvision中的常见模型为例,如何在图像分类任务中使用PyTorch提供的常见模型结构和参数:
# 1. 实例化网络
import torchvision.models as models
resnet18 = models.resnet18()
# resnet18 = models.resnet18(pretrained=False) 等价于上面的表达式
alexnet = models.alexnet()
vgg16 = models.vgg16()
squeezenet = models.squeezenet1_0()
densenet = models.densenet161()
inception = models.inception_v3()
googlenet = models.googlenet()
shufflenet = models.shufflenet_v2_x1_0()
mobilenet_v2 = models.mobilenet_v2()
mobilenet_v3_large = models.mobilenet_v3_large()
mobilenet_v3_small = models.mobilenet_v3_small()
resnext50_32x4d = models.resnext50_32x4d()
wide_resnet50_2 = models.wide_resnet50_2()
mnasnet = models.mnasnet1_0()
# 2. 传递pretrained参数
# 通过True或者False来决定是否使用预训练好的权重,默认状态pretrained = False,不使用预训练得到的权重
# pretrained = True,使用在一些数据集上预训练得到的权重
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = models.mobilenet_v2(pretrained=True)
mobilenet_v3_large = models.mobilenet_v3_large(pretrained=True)
mobilenet_v3_small = models.mobilenet_v3_small(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
注意:
- 通常PyTorch模型的扩展为
.pt或.pth,程序运行时会首先检查默认路径中是否有已经下载的模型权重,一旦权重被下载,下次加载就不需要下载了; - 一般情况下预训练模型的下载会比较慢,可以手动下载。预训练模型的权重在Linux和Mac的默认下载路径是用户根目录下的
.cache文件夹。在Windows下就是C:\Users\<username>\.cache\torch\hub\checkpoint,可以用torch.utils.model_zoo.load_url()设置权重的下载地址; - 也可以将自己的权重下载下来放到同文件夹,然后再将参数加载网络:
self.model = models.resnet50(pretrained=False)
self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))
- 若中途下载失败,要先去对应路径下将权重文件删除干净再重新下载,否则可能会报错。
(3)修改预训练模型的方法 [4]
1)只修改输入输出的类别数
#1、只修改输入输出的类别数,即某些网络层的参数(常见的是修改通道数)
import torchvision.models
import torch.nn as nn
model = torchvision.models.resnet50(pretrained=True)
print("原输出通道数:", model.fc) # 原输出是1000通道
# 修改最后线性层的输出通道数
model.fc = nn.Linear(2048,10) # 改成了10通道
print("修改后的输出通道数:", model.fc)
结果如下:

2)替换整个backbone或预训练模型的某一部分
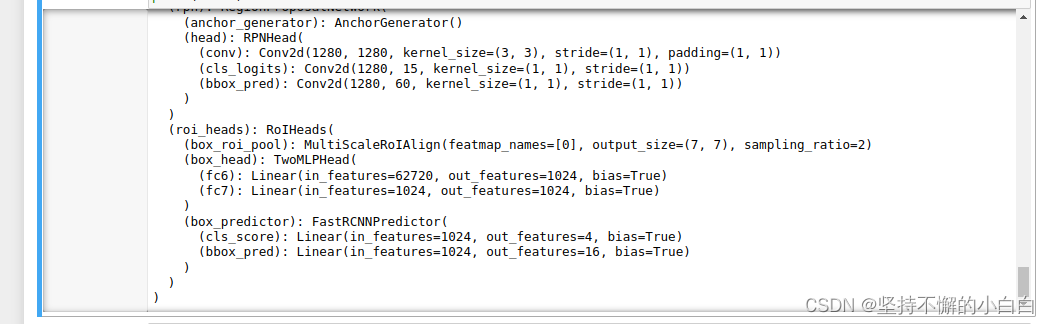
# 2、替换整个backbone或预训练模型的某一部分
# 以下是替换骨干网的示例
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# 先加载一个预训练模型的特征
# only the features:其实就是不包含最后的classifier的两层
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# 需要知道 backbone 的输出通道数,这样才能在替换时保证通道数的一致性
backbone.out_channels = 1280
# 设置RPN的anchor生成器,下面的anchor_generator可以在每个空间位置生成5x3的anchors,即5个不同尺寸×3个不同的比例
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# 定义roipool模块
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
# 将以上模块集成到FasterRCNN中
model = FasterRCNN(backbone,
num_classes=4,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
如下:
3)修改模型网络中间层的结构
(最重要,一般是重写部分中间层再整体替换)
# 3、修改网络中间层的结构(最重要,一般是重写部分中间层再整体替换)
# 以下是在ResNet50的基础上修改的,大部分是复制的源码,但后面新增+修改了一些层
class CNN(nn.Module):
def __init__(self, block, layers, num_classes=9):
self.inplanes = 64
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
#新增一个反卷积层
self.convtranspose1 = nn.ConvTranspose2d(2048, 2048, kernel_size=3, stride=1, padding=1, output_padding=0, groups=1, bias=False, dilation=1)
#新增一个最大池化层
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
#去掉原来的fc层,新增一个fclass层
self.fclass = nn.Linear(2048, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
#新加层的forward
x = x.view(x.size(0), -1)
x = self.convtranspose1(x)
x = self.maxpool2(x)
x = x.view(x.size(0), -1)
x = self.fclass(x)
return x
#加载model
resnet50 = torchvision.models.resnet50(pretrained=True)
cnn = CNN(Bottleneck, [3, 4, 6, 3])
#读取参数
pretrained_dict = resnet50.state_dict()
model_dict = cnn.state_dict()
# 将pretrained_dict里不属于model_dict的键剔除掉
pretrained_dict = {
k: v for k, v in pretrained_dict.items() if k in model_dict}
# 更新现有的model_dict
model_dict.update(pretrained_dict)
# 加载我们真正需要的state_dict
cnn.load_state_dict(model_dict)
# print(resnet50)
print(cnn)
4)快速去除预训练模型本身的网络层并添加新的层
# 4、快速去除预训练模型本身的网络层并添加新的层
# 先将模型的网络层列表化,每一层对应列表一个元素,bottleneck对应一个序列层
net_structure = list(model.children())
# print(net_structure)
#去除最后两层得到新的网络
resnet_modified = nn.Sequential(*net_structure[:-2])
#用以上方法构建新网络如下
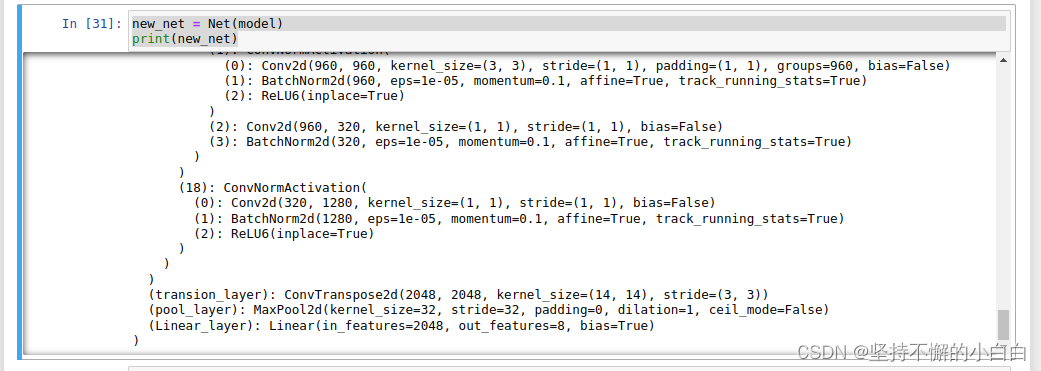
class Net(nn.Module):
def __init__(self , model):
super(Net, self).__init__()
# 取掉model的后两层
self.resnet_layer = nn.Sequential(*list(model.children())[:-2])
self.transion_layer = nn.ConvTranspose2d(2048, 2048, kernel_size=14, stride=3)
self.pool_layer = nn.MaxPool2d(32)
self.Linear_layer = nn.Linear(2048, 8)
def forward(self, x):
x = self.resnet_layer(x)
x = self.transion_layer(x)
x = self.pool_layer(x)
x = x.view(x.size(0), -1)
x = self.Linear_layer(x)
return x
# 实例化
new_net = Net(model) # 这里model是上面2)中代码的model
print(new_net)
如下:
2. 模型微调 — timm
timm库也是一个常见的预训练模型库,里面提供了许多计算机视觉的SOTA模型,可以当作torchvision的扩充版本。这里主要讲timm库预训练模型的使用。
(1)timm库安装
pip install timm
(2)查看预训练模型种类
- 查看
timm提供的预训练模型
# jupyer notebook
# 可以通过timm.list_models()方法
import timm
avail_pretrained_models = timm.list_models(pretrained=True)
len(avail_pretrained_models)
截至今日,timm提供的模型有716个:

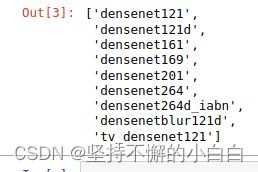
- 查看特定模型的所有种类
# 查询 densenet 系列所有的模型
all_densnet_models = timm.list_models("*densenet*")
all_densnet_models
如下:
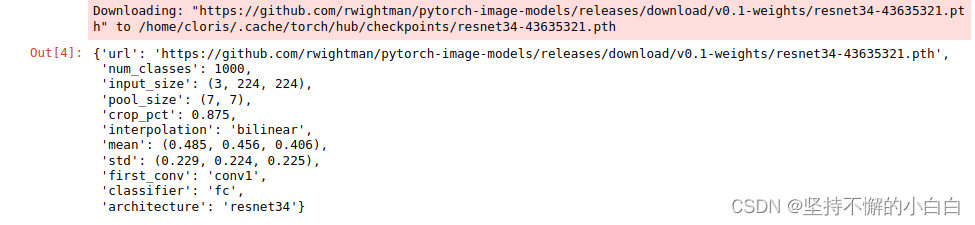
- 查看模型的具体参数
# 通过访问模型的`default_cfg`属性来进行查看
model = timm.create_model('resnet34',num_classes=10,pretrained=True)
model.default_cfg
如下:
还可以查看模型的准确度信息
(3)使用和修改预训练模型
# timm.create_model()方法进行模型的创建
# 传入参数 pretrained=True 来使用预训练模型
import timm
import torch
model = timm.create_model('resnet34',pretrained=True)
x = torch.randn(1,3,224,224)
output = model(x)
output.shape

# 查看某一层的参数
model = timm.create_model('resnet34',pretrained=True)
list(dict(model.named_children())['conv1'].parameters()) # 查看第一层卷积层的参数
# 修改模型(将1000通道改为10通道输出)
model = timm.create_model('resnet34',num_classes=10,pretrained=True)
x = torch.randn(1,3,224,224)
output = model(x)
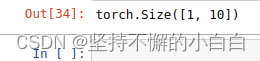
output.shape
# 改变输入通道数
# 传入的图片是单通道的,但是模型需要的是三通道图片
# 添加in_chans=1来改变模型
model = timm.create_model('resnet34',num_classes=10,pretrained=True,in_chans=1)
x = torch.randn(1,1,224,224)
output = model(x)
model # 查看模型, 可以发现模型被改成了1通道输入

(4)模型保存与加载
torch.save(model.state_dict(),'./checkpoint/timm_model.pth') # 保存
model.load_state_dict(torch.load('./checkpoint/timm_model.pth')) # 加载
四、半精度训练
GPU性能分为:算力和显存
- 算力:决定了显卡计算的速度
- 显存:决定了显卡可以同时放入多少数据用于计算
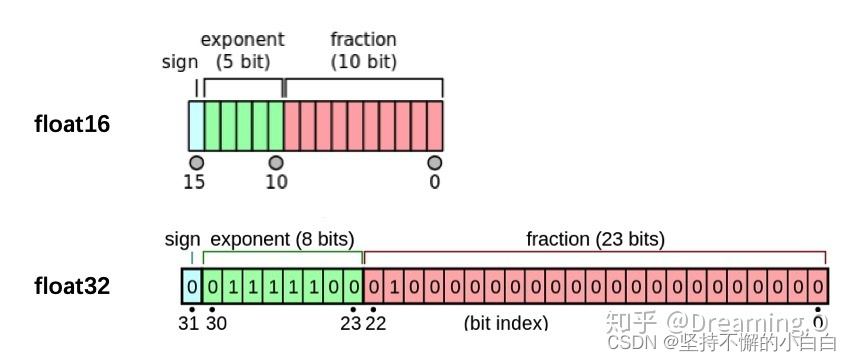
显存数量不变,载入数据更多,则训练速度也会加快,这时数据可使用半精度格式:
# 设置半精度的方式
from torch.cuda.amp import autocast # 载入autocast包
@autocast() # 用autocast装饰forward函数
def forward(self, x):
...
return x
for x in train_loader:
x = x.cuda()
with autocast(): # 将其他部分放入with autocast下面
output = model(x)
...
注:数据本身size比较大的数据适用半精度训练
五、数据增强 — imgaug
- 针对有限数据问题,可以使用数据增强技术,提高数据集的大小和质量;
- 计算视觉领域的数据增强可以使用
imgaug包。
1. imgaug安装
pip install imgaug
2. imgaug使用
- 用
opencv读取图像文件,需要手动改变通道,将读取的BGR图像转换成RGB图像; PIL.Image进行读取时,读取的图片没有shape属性,需要将读取到的img转换为np.array()的形式再进行处理;imageio进行图片读取比较方便
(1)单张图片处理
import imageio
import imgaug as ia
%matplotlib inline
# 图片的读取
img = imageio.imread("./Lenna_original.png")
# 使用Image进行读取
# img = Image.open("./Lenna.jpg")
# image = np.array(img)
# ia.imshow(image)
# 可视化图片
ia.imshow(img)
运行时报错及解决方案:

原因是:python和numpy版本问题导致。我的环境中python==3.6,支持的numpy最高版本是1.19;而numpy.typing出现在numpy>=1.20的版本中,需要升级python>=3.7,然后更新numpy>=1.20。
解决问题后,运行结果如下:

读取数据后,可以做一些操作:
1)对图片做一种操作
from imgaug import augmenters as iaa
# 设置随机数种子
ia.seed(4) # 让每次运行此代码旋转结果都一样
# 实例化方法
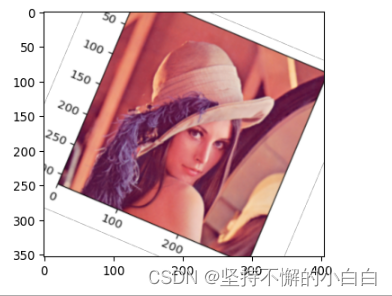
rotate = iaa.Affine(rotate=(-4,45)) # -4至45度之间的旋转操作
img_aug = rotate(image=img) # 处理后是numpy数组格式
ia.imshow(img_aug)
2)对图片进行多种操作
iaa.Sequential(children=None, # 想要应用在图像上的Augmenter集合
random_order=False, # 是否对每个batch使用不同顺序的Augmenter list,设置为True时,不同batch之间图片的处理顺序都会不一样,但是同一个batch内顺序相同
name=None,
deterministic=False, # bool类型, 默认False
random_state=None)
# 构建处理序列
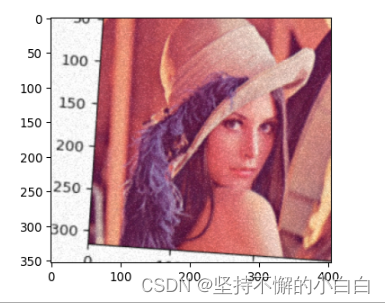
aug_seq = iaa.Sequential([
iaa.Affine(rotate=(-25,25)),
iaa.AdditiveGaussianNoise(scale=(10,60)), # scale噪声方差
iaa.Crop(percent=(0,0.2)) # 0到20%的数值
])
# 对图片进行处理,image不可以省略,也不能写成images
image_aug = aug_seq(image=img)
ia.imshow(image_aug)
结果如下:
注 [5]:
iaa.Affine:
iaa.Affine(
scale={
"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_percent={
"x": (-0.2, 0.2), "y": (-0.2, 0.2)},
rotate=(-25, 25),
shear=(-8, 8))
对图片进行仿射变化,缩放x,y取值范围均为0.8-1.2之间随机值,左右上下移动的值为-0.2-0.2乘以宽高后的随机值,旋转角度为-25到25的随机值,shear剪切(取值范围是0-360),这里-8到8随机值进行图片剪切
iaa.AdditiveGaussianNoise:
iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.3*255), per_channel=0.5)
# loc 噪声均值,scale噪声方差,50%的概率对图片进行添加白噪声并应用于每个通道
iaa.Crop:
iaa.Crop(percent=(0, 0.3),keep_size=True)
# 0-0.3的数值,分别乘以图片的宽和高为剪裁的像素个数,保持原尺寸
(2)批次图片处理
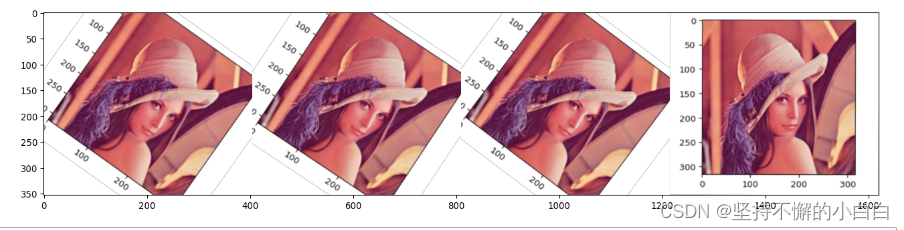
images = [img,img,img,img,] # 将待处理图片放在一个list中
images_aug = rotate(images=images) # 将image改成images,这里只进行仿射变换
ia.imshow(np.hstack(images_aug))
结果如下:
# 对批次的图片使用多种增强方法
aug_seq = iaa.Sequential([
iaa.Affine(rotate=(-25, 25)),
iaa.AdditiveGaussianNoise(scale=(10, 60)),
iaa.Crop(percent=(0, 0.2))
]) # 同样借助Sequential函数
# 传入时需要指明是images参数
images_aug = aug_seq.augment_images(images = images)
ia.imshow(np.hstack(images_aug))
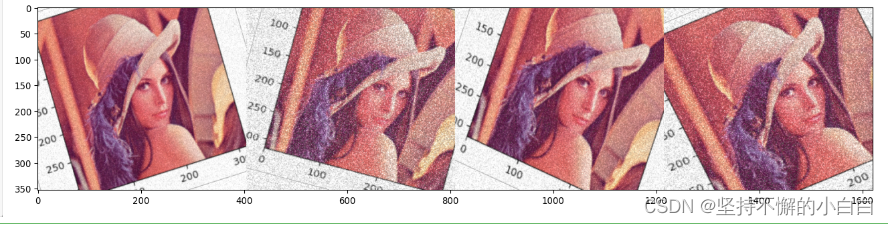
# 对一个batch中的图片,一部分图片应用一部分Augmenters,剩下的图片应用另外的Augmenters。
iaa.Sometimes(p=0.5, # 代表划分比例
then_list=None, # 以p的概率执行then_list的增强方法,默认为None
else_list=None, # 以1-p的概率执行else_list的增强方法,默认为None
# 变换的图片应用的Augmenter只能是then_list或者else_list中的一个
name=None,
deterministic=False,
random_state=None)
(3)不同大小的图片的处理
# 构建pipline
seq = iaa.Sequential([
iaa.CropAndPad(percent=(-0.2, 0.2), pad_mode="edge"), # crop and pad images
iaa.AddToHueAndSaturation((-60, 60)), # change their color
iaa.ElasticTransformation(alpha=90, sigma=9), # water-like effect
iaa.Cutout() # replace one squared area within the image by a constant intensity value
], random_order=True)
# 加载不同大小的图片
images_different_sizes = [
imageio.imread("https://upload.wikimedia.org/wikipedia/commons/e/ed/BRACHYLAGUS_IDAHOENSIS.jpg"),
imageio.imread("https://upload.wikimedia.org/wikipedia/commons/c/c9/Southern_swamp_rabbit_baby.jpg"),
imageio.imread("https://upload.wikimedia.org/wikipedia/commons/9/9f/Lower_Keys_marsh_rabbit.jpg")
]
# 对图片进行增强
images_aug = seq(images=images_different_sizes) # images
# 可视化结果
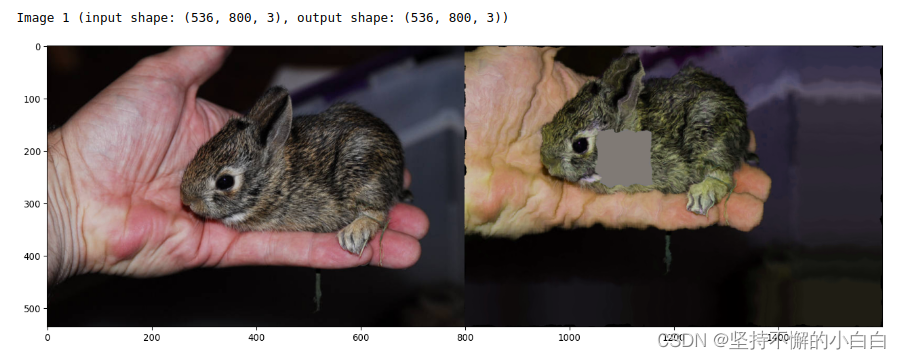
print("Image 0 (input shape: %s, output shape: %s)" % (images_different_sizes[0].shape, images_aug[0].shape)) # 尺寸
ia.imshow(np.hstack([images_different_sizes[0], images_aug[0]])) # 原图及做过图像增强后的图
print("Image 1 (input shape: %s, output shape: %s)" % (images_different_sizes[1].shape, images_aug[1].shape))
ia.imshow(np.hstack([images_different_sizes[1], images_aug[1]]))
print("Image 2 (input shape: %s, output shape: %s)" % (images_different_sizes[2].shape, images_aug[2].shape))
ia.imshow(np.hstack([images_different_sizes[2], images_aug[2]]))
结果如下:


3. imgaug在PyTorch中的应用
# 一种应用模板
import numpy as np
from imgaug import augmenters as iaa
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
# 构建pipline
tfs = transforms.Compose([
iaa.Sequential([
iaa.flip.Fliplr(p=0.5), # 水平0.5的概率翻转
iaa.flip.Flipud(p=0.5), # 垂直0.5的概率翻转
iaa.GaussianBlur(sigma=(0.0, 0.1)), # 高斯扰动 0:不扰动;3:强扰动
iaa.MultiplyBrightness(mul=(0.65, 1.35)),
]).augment_image,
# 不要忘记了使用ToTensor()
transforms.ToTensor()
])
# 自定义数据集
class CustomDataset(Dataset):
def __init__(self, n_images, n_classes, transform=None):
# 图片的读取,建议使用imageio
self.images = np.random.randint(0, 255,
(n_images, 224, 224, 3),
dtype=np.uint8)
self.targets = np.random.randn(n_images, n_classes)
self.transform = transform
def __getitem__(self, item):
image = self.images[item]
target = self.targets[item]
if self.transform:
image = self.transform(image)
return image, target
def __len__(self):
return len(self.images)
def worker_init_fn(worker_id): # 保证了在num_workers>0时对数据的增强是随机的
# Linux系统下num_workers可以设置大于0
imgaug.seed(np.random.get_state()[1][0] + worker_id)
custom_ds = CustomDataset(n_images=50, n_classes=10, transform=tfs)
custom_dl = DataLoader(custom_ds, batch_size=64,
num_workers=4, pin_memory=True,
worker_init_fn=worker_init_fn)
注:其他数据增强库:链接: Albumentations,Augmentor等
六、使用 argparse 进行调参
1. argparse简介
- Python内置标准库
- 将命令行传入的参数进行解析、保存和使用
- 在机器学习中超参数设置形式:先运行
python file.py文件,再设置python file.py --lr 1e-4 --batch_size 32即可
2. argparse使用
步骤如下:
(1)创建ArgumentParser()对象
(2)调用add_argument()方法添加参数
(3)使用parse_args()解析参数
# demo.py
import argparse
# 创建ArgumentParser()对象
parser = argparse.ArgumentParser()
# 添加参数
parser.add_argument('-o', '--output', action='store_true',
help="shows output")
# action = `store_true` 会将output参数记录为True
# type 规定了参数的格式
# default 规定了默认值
parser.add_argument('--lr', type=float, default=3e-5, help='select the learning rate, default=1e-3')
parser.add_argument('--batch_size', type=int, required=True, help='input batch size')
# 使用parse_args()解析函数
args = parser.parse_args()
if args.output:
print("This is some output")
print(f"learning rate:{
args.lr} ")
终端首先进入demo.py文件所在文件夹:
cd ~/PycharmProjects/pytorch_learning
然后输入:
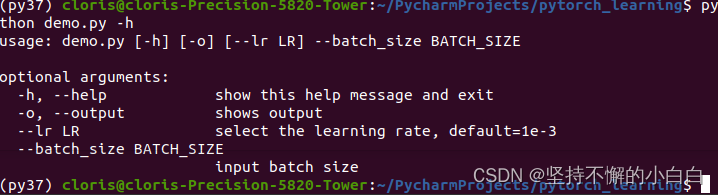
python demo.py -h
可以看到运行的结果如下:
根据上方输入格式要求,输入lr及batch_size的值并得到输出:
python demo.py --lr 3e-4 --batch_size 32 -o
得到结果如下:

注:也可以不使用“–”格式输入参数,只输入数值即可,但是那样会严格按照参数位置进行解析。
3. 更加高效使用argparse修改超参数
将超参数单独写在一个文件(如“config.py”)中,在其他文件导入(”import config")即可。
七、PyTorch模型定义与进阶训练技巧
结合U-Net模型对(三)和(四)所学的内容进行实战。
放在另一个文件里了,链接: PyTorch模型定义与进阶训练技巧实战部分
[1] datawhalechina/thorough-pytorch: https://github.com/datawhalechina/thorough-pytorch
[2] 从loss处理图像分割中类别极度不均衡的状况—keras: https://blog.csdn.net/m0_37477175/article/details/83004746
[3] 一文看懂学习率Learning Rate,从入门到CLR:https://blog.csdn.net/u012526436/article/details/90486021
[4] Pytorch修改预训练模型的方法汇总: https://blog.csdn.net/weixin_42118374/article/details/103761795
[5] 图片数据增强库(imgaug)的标准用法:https://blog.csdn.net/zh_JNU/article/details/85102982