
深度学习中opitmizer是一个十分重要的组成部分,在一些任务中,我们需要给不同 layer 设置不同的学习率以及冻结特定层。为了更好的掌握和使用mmcv,这里留下一些笔记。我会不定期更新mmcv,mmdetection内容,有兴趣的同学可以留言。
首先介绍一些经常出现的梯度优化方法。
SGD
随机梯度下降,随机选取一批样本计算梯度,并更新一次参数。梯度更新公式如下:
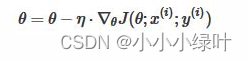
SGD存在一些问题:在梯度平缓的维度下降非常慢,在梯度险峻的维度容易抖动,且容易陷入局部极小值或鞍点。
Momentum
Momentum在每次下降时都加上之前运动方向上的动量,在梯度缓慢的维度下降更快,在梯度险峻的维度减少抖动。
对于在梯度点处具有相同的方向的维度,其动量项增大,对于在梯度点处改变方向的维度,其动量项减小。因此,我们可以得到更快的收敛速度,同时可以减少摇摆。

Nesterov
Nesterov是Momentum的变种。与Momentum唯一区别就是,计算梯度的不同。Nesterov动量中,先用当前的速度 临时更新一遍参数,在用更新的临时参数计算梯度。因此,Nesterov动量可以解释为在Momentum动量方法中添加了一个校正因子。
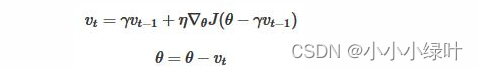
看一下pytorch的源码
Optimizer 是所有优化器的父类,它主要有如下公共方法:
- add_param_group(param_group): 添加模型可学习参数组
- step(closure): 进行一次参数更新
- zero_grad(): 清空上次迭代记录的梯度信息state_dict(): 返回 dict 结构的参数状态
- load_state_dict(state_dict): 加载 dict 结构的参数状态
def _single_tensor_sgd(params: List[Tensor],
d_p_list: List[Tensor],
momentum_buffer_list: List[Optional[Tensor]],
*,
weight_decay: float,
momentum: float,
lr: float,
dampening: float,
nesterov: bool,
maximize: bool,
has_sparse_grad: bool):
for i, param in enumerate(params):
##d_p是参数的梯度
d_p = d_p_list[i]
if weight_decay != 0:
##weight_decay其实是用来正则化的,提高模型泛化能力
d_p = d_p.add(param, alpha=weight_decay)
##参数正则化
if momentum != 0:
##buf=buf*momentum + d_p(1-dampening),buf用来寄存动量
buf = momentum_buffer_list[i]
if buf is None:
buf = torch.clone(d_p).detach()
momentum_buffer_list[i] = buf
else:
buf.mul_(momentum).add_(d_p, alpha=1 - dampening)
if nesterov:
##d_p=d_p + momentun*buf,在梯度上加上动量
d_p = d_p.add(buf, alpha=momentum)
else:
d_p = buf
alpha = lr if maximize else -lr
param.add_(d_p, alpha=alpha)
mmcv构建optimizer源码
在mmcv中,optimizer构造较为复杂,为了给不同 layer 设置不同的学习率以及冻结特定层,我们需要知道如何注册优化器,并利用DefaultOptimizerConstructor针对不同情况构造优化器
注册pytorch中的优化器
# mmcv/runner/optimier/builder.py
import inspect
import torch
from mmcv import Registry, build_from_cfg
OPTIMIZERS = Registry('optimizer') # 定义一个注册器类,用来注册pytorch中的优化器
def register_torch_optimizers():
for module_name in dir(torch.optim): # 遍历torch.optim中的类
if module_name.startswith('__'): # '__'开头,如'__name__'、'__path__'等,表示特殊类跳过
continue
_optim = getattr(torch.optim, module_name) # torch.optim本质是模块,python万物皆对象,它也可以用attr属性
if inspect.isclass(_optim) and issubclass(_optim,torch.optim.Optimizer): # 判断是否是优化器
OPTIMIZERS.register_module(module=_optim) # 这才是注册
register_torch_optimizers() # 导入builder.py时,就会执行
将pytorch中的优化器利用Registry注册,之后,可以通过config来build optimizer。
from .builder import OPTIMIZER_BUILDERS, OPTIMIZERS
@OPTIMIZER_BUILDERS.register_module()
class DefaultOptimizerConstructor:
"""
主要有两个参数optimizer_cfg和paramwise_cfg:
optimizer_cfg确定优化器type、默认的lr、momentum等。其中属性base_lr、base_wd就是optimizer_cfg中的lr与weight_decay。
paramwise_cfg确定个别模块的lr、momentum等。
以optimizer_cfg = dict(type='SGD', lr=0.01, momentum=0.9,weight_decay=0.0001)为例
如果不指定paramwise_cfg,那么调用self.__call__(model),很简单就是返回
SGD({'params':model.parameters,lr='0.01',momentum='0.9',weight_decay='0.0001'})
特别情况,需要用paramwise_cfg来指定个别模块的lr、momentum、weight_decay。比如DCN、depthwise conv、batchnorm
所以关键的介绍paramwise_cfg,它是一个dict,包括以下key-value
- 'custom_keys' (dict): 它的key值是字符串类型,如果custom_keys中的一个key值是一个params的name的子字符串,
那么该params的lr将由custom_keys[key]['lr_mult']与base_lr相乘来计算,同理weight_decay。
值得注意的是,如果params的name与多个custom_keys中的key匹配,将采用最长子字符串,如果长度还一样,按字母排序。
此外,它的value值还是dict字典,可能包括lr_mult和decay_mult字段,同下。
- 'bias_lr_mult'(float): 所有的bias参数(如conv.bias)的lr等于base_lr*bias_lr_mult。
注意,norm的bias参数、DCN的offset层!不由bias_lr_mult指定。
- 'bias_decay_mult' (float): 同上,所有的bias参数(如conv.bias)的weight_decay等于base_wd*bias_decay_mult。
注意,norm的bias参数、DCN的offset层、depthwise conv的bias参数!不由bias_lr_mult指定。
- 'norm_decay_mult' (float): 确定norm的weight和bias参数的weight_decay。
- 'dwconv_decay_mult' (float): 确定depthwise conv的weight和bias参数的weight_decay。
- 'dcn_offset_lr_mult'(float): 确定DCN的offset层的学习率。
- 'bypass_duplicate' (bool): 如果为True,重复的params不会被添加在optimizer
Note:
1. 'dcn_offset_lr_mult'会重载'bias_lr_mult'
2. custom_keys有最高优先级,会覆盖其他参数
"""
def __init__(self, optimizer_cfg, paramwise_cfg=None):
if not isinstance(optimizer_cfg, dict):
raise TypeError('optimizer_cfg should be a dict',
f'but got {
type(optimizer_cfg)}')
self.optimizer_cfg = optimizer_cfg
self.paramwise_cfg = {
} if paramwise_cfg is None else paramwise_cfg
self.base_lr = optimizer_cfg.get('lr', None)
self.base_wd = optimizer_cfg.get('weight_decay', None)
…………
def _is_in(self, param_group, param_group_list):
assert is_list_of(param_group_list, dict)
param = set(param_group['params'])
param_set = set()
for group in param_group_list:
param_set.update(set(group['params']))
return not param.isdisjoint(param_set)
def add_params(self, params, module, prefix='', is_dcn_module=None):
"""
根据paramwise_cfg,将moduel中的参数放入params中
参数:
params (list[dict]): A list of param groups, it will be modified
in place.
module (nn.Module): The module to be added.
prefix (str): The prefix of the module
is_dcn_module (int|float|None):当前的module是否是DCN的子module
"""
# get param-wise options
custom_keys = self.paramwise_cfg.get('custom_keys', {
})
# first sort with alphabet order and then sort with reversed len of str
sorted_keys = sorted(sorted(custom_keys.keys()), key=len, reverse=True)
bias_lr_mult = self.paramwise_cfg.get('bias_lr_mult', 1.)
bias_decay_mult = self.paramwise_cfg.get('bias_decay_mult', 1.)
norm_decay_mult = self.paramwise_cfg.get('norm_decay_mult', 1.)
dwconv_decay_mult = self.paramwise_cfg.get('dwconv_decay_mult', 1.)
bypass_duplicate = self.paramwise_cfg.get('bypass_duplicate', False)
dcn_offset_lr_mult = self.paramwise_cfg.get('dcn_offset_lr_mult', 1.)
# special rules for norm layers and depth-wise conv layers
is_norm = isinstance(module,(_BatchNorm, _InstanceNorm, GroupNorm, LayerNorm))
is_dwconv = (isinstance(module, torch.nn.Conv2d)
and module.in_channels == module.groups)
for name, param in module.named_parameters(recurse=False): # recurse为Fasle,不再递归遍历子module
param_group = {
'params': [param]}
if not param.requires_grad:
params.append(param_group)
continue
if bypass_duplicate and self._is_in(param_group, params):
warnings.warn(f'{
prefix} is duplicate. It is skipped since '
f'bypass_duplicate={
bypass_duplicate}')
continue
# if the parameter match one of the custom keys, ignore other rules
is_custom = False
for key in sorted_keys:
if key in f'{
prefix}.{
name}': # 如果key是name的子字符串!注意sorted_keys是按长度,再按字母排序
is_custom = True
lr_mult = custom_keys[key].get('lr_mult', 1.)
param_group['lr'] = self.base_lr * lr_mult
if self.base_wd is not None:
decay_mult = custom_keys[key].get('decay_mult', 1.)
param_group['weight_decay'] = self.base_wd * decay_mult
break # 找到一个就break
if not is_custom:
# bias_lr_mult affects all bias parameters
# except for norm.bias dcn.conv_offset.bias
if name == 'bias' and not (is_norm or is_dcn_module):
param_group['lr'] = self.base_lr * bias_lr_mult
if (prefix.find('conv_offset') != -1 and is_dcn_module
and isinstance(module, torch.nn.Conv2d)):
# deal with both dcn_offset's bias & weight
param_group['lr'] = self.base_lr * dcn_offset_lr_mult
# apply weight decay policies
if self.base_wd is not None:
# norm decay
if is_norm:
param_group['weight_decay'] = self.base_wd * norm_decay_mult
# depth-wise conv
elif is_dwconv:
param_group['weight_decay'] = self.base_wd * dwconv_decay_mult
# bias lr and decay
elif name == 'bias' and not is_dcn_module:
# TODO: current bias_decay_mult will have affect on DCN
param_group['weight_decay'] = self.base_wd * bias_decay_mult
params.append(param_group)
if check_ops_exist():
from mmcv.ops import DeformConv2d, ModulatedDeformConv2d
is_dcn_module = isinstance(module,(DeformConv2d, ModulatedDeformConv2d))
else:
is_dcn_module = False
for child_name, child_mod in module.named_children():
child_prefix = f'{
prefix}.{
child_name}' if prefix else child_name
self.add_params(
params,
child_mod,
prefix=child_prefix,
is_dcn_module=is_dcn_module)
def __call__(self, model):
if hasattr(model, 'module'): # 如果有module属性,说明是被DataParallel封装后的,需要取出module
model = model.module
optimizer_cfg = self.optimizer_cfg.copy()
# if no paramwise option is specified, just use the global setting
if not self.paramwise_cfg:
optimizer_cfg['params'] = model.parameters()
return build_from_cfg(optimizer_cfg, OPTIMIZERS)
# set param-wise lr and weight decay recursively
params = []
self.add_params(params, model) # 获得优化器的构造参数,确定model参数的lr、momentum等,保存在params中
optimizer_cfg['params'] = params
# OPTIMIZERS就是定义在mmcv/runner/optimier/builder.py中,注册了pytorch中的优化器
return build_from_cfg(optimizer_cfg, OPTIMIZERS)
对不同 layer 设置不同的学习率
optimizer = dict(
_delete_=True,
type='AdamW',
lr=0.0001,
betas=(0.9, 0.999),
weight_decay=0.05,
paramwise_cfg=dict(
custom_keys={
'absolute_pos_embed': dict(decay_mult=0.),
'relative_position_bias_table': dict(decay_mult=0.),
'norm': dict(decay_mult=0.)
}))
当我们想对不同 layer 设置不同的学习率时,可以在custom_keys中用key-value标明,注意,norm的bias参数、DCN的offset层、depthwise conv的bias参数!不由bias_lr_mult指定。
- bias_lr_mult 给特定层或者所有层的 bias_lr 乘上一个系数
- bias_decay_mult 给特定层或者所有层的 bias 模块的 decay 乘上一个系数
冻结特定层解决办法
对于没有 BN 层的模块,我们可以将想冻结的层中的 lr_mult 设置为 0。但是一旦有 BN,lr=0 只是可学习参数不再更新,但是全局均值和方差依然在改,没有实现真正的冻结。 我们可以直接将requires_grad=False.
def _freeze_stages(self):
if self.frozen_stages >= 0:
if self.deep_stem:
self.stem.eval()
for param in self.stem.parameters():
param.requires_grad = False
else:
self.norm1.eval()
for m in [self.conv1, self.norm1]:
for param in m.parameters():
param.requires_grad = False
for i in range(1, self.frozen_stages + 1):
m = getattr(self, f'layer{
i}')
m.eval()
for param in m.parameters():
param.requires_grad = False