一、optimizer 算法介绍
1、Batch Gradient Descent(BGD)
BGD采用整个训练集的数据来计算 cost function 来进行参数更新。
for i in range(iteration):
"""
这是从我写的DNN模型中抽取的部分代码,只需关注 L_model_forward() 和
L_model_backward() 中的参数 X_all_data, y_all_data
"""
A, caches = self.L_model_forward(X_all_data, parameters, activation_list)
grads = self.L_model_backward(y_all_data, parameters, caches, activation_list)
parameters = self.update_parameters(parameters, grads, learning_rate)
缺点:
该优化方法在一次梯度更新过程中,需要对整个数据集求梯度,所以当数据集很大时,计算量会非常大,梯度更新的速度也会变很慢。
2、Stochastic Gradient Descent(SGD)
(SGD)随机梯度下降法,每次更新时只用到了一份样本,梯度更新的速度明显加快,并且可以随时扩增样本。
for i in range(iteration):
permutation = np.random.permutation(X_all_data.shape[1])
for j in permutation: # 分别用每个样本点进行更新
A, caches = self.L_model_forward(X_all_data[:, j], parameters, activation_list)
grads = self.L_model_backward(y_all_data[:, j], parameters, caches, activation_list)
parameters = self.update_parameters(parameters, grads, learning_rate)
对于随机梯度下降法,可能只需要迭代很少的几次数据,就可以使模型收敛。并且当函数非凸时,BGD收敛到局部极小值点后就无法更新了,但是SGD因为取的样本点是随机的,所以可能会跳到更好的局部极小值点继续更新。
缺点:
- SGD 因为更新比较频繁,会造成 cost function 有严重的震荡。
- 通过上述代码可以看到,SGD的更新建立了两个嵌套循环,没有使用numpy中优化的矩阵运算,所以整体速度会比较慢。
3、Mini-Batch Gradient Descent(MBGD)
MBGD是BGD和SGD的中和版本,每次使用一小部分样本进行更新,这样可以减小参数更新过程中的震荡,使收敛更加稳定,另一方面遍历一次全数据集就可以进行多次更新,减少收敛的迭代次数,还能使用Numpy中的矩阵优化加快运算速度。
for i in range(iteration):
for (X_batch, y_batch) in get_batches(X_all_data, y_all_data, batch_size):
A, caches = self.L_model_forward(X_batch, parameters, activation_list)
grads = self.L_model_backward(y_batch, parameters, caches, activation_list)
parameters = self.update_parameters(parameters, grads, learning_rate)
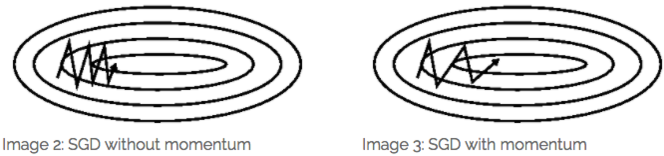
4、Momentum
在更新参数的过程中,如果曲面不同方向的梯度值不同,一般的梯度下降法总是无法找到最佳的更新路径,这时可以使用 momentum 来进行改进,就是在梯度下降过程中给其添加一个惯性,让其有保持原先更新方向的趋势。
算法流程
在当前的 mini-batch 中,计算 dw, db:
偏差修正
由于在计算前几个平均值的时候,
的影响比较大,可能会使得求得的前几个均值
的值偏小,所以需要对偏差进行修正。修正的方法如下:
随着 t 值的增大,
的值趋向于1,所以偏差修正的影响越来越小。在上述算法中,有两个超参数
,
的值通常取0.9。在动量梯度下降法中,一般不考虑偏差修正。
动量梯度下降算法的解释
在碗形的 cost function 中,指向最低点的路径更新才是有效的,而垂直该方向的路径更新是无效的,在动量梯度下降法中,由于求平均值的作用,无效的路径更新由于符号相反,会相互抵消,留下的是近似的有效的更新路径。
5、Nesterov Accelerated Gradient(NAG)
梯度更新规则
NAG是对Momentum的改进,可以理解为先对参数进行估计,然后使用估计后的参数来计算误差。即用
来近似当做参数下一步会变成的值,则在计算梯度时,不是在当前位置,而是在未来的位置上。用一张图来形象的对比下momentum和nesterov momentum的区别(图片来自:一篇写的很好的博客):
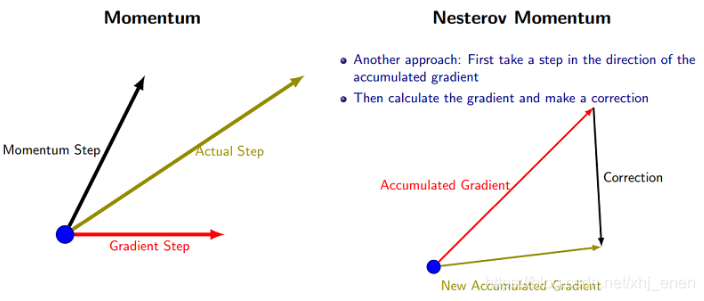
参数更新步骤如下:
缺点:
通过观察上述方法,我们会发现这个算法中有一步需要计算
,这就意味着需要重新走一次前向传播和反向传播,这会导致整个计算步骤比Momentum慢至少一倍。因此在实际中一般不会直接这么用,而是采用如下变形版本。
上述公式可以写成Keras风格:
6、Adagrad(Adaptive gradient algorithom)
通常,我们在每一次更新参数时,对于所有的参数使用的都是相同的学习率 。而AdaGrad算法的思想是:每一次更新参数时,对不同的参数使用不同的学习率。简而言之,Adagrad有如下特点:
- 每一次迭代,学习率不同
- 对于每一个参数,学习率不同
优点:
对于梯度较大的参数,
相对较大,则学习率
较小;对于梯度较小的参数,则刚好相反。这样就可以使得参数在平缓的地方下降的稍微快些,不至于徘徊不前。
缺点:
由于在计算
时是累加梯度的平方,这会导致最后
较大,从而导致
,梯度消失。
7、Adadelta
Adadelta是对Adagrad的改进版本,为了克服Adagrad的两个缺点:
- 学习率的持续下降,最终导致梯度消失
- 需要手动设置学习率
为了解决第一个问题,Adadelta采用指数加权平均的方式,只累加前 w 个窗口的梯度的平方:
当
取0.9,就相当于累加了前10个梯度的平方。
为了解决第二个问题,Adadelta中不再需要设置
。参数更新的具体算法如下:
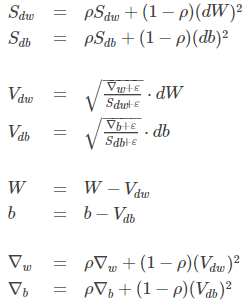
其中
的作用是防止分母为0,通常取
。
8、RMSprop
RMSprop 是 Geoff Hinton 提出的一种自适应学习率方法。和Adadelta一样,RMSprop使用指数加权平均(指数衰减平均)只保留过去给定窗口大小的梯度,使其能够在找到凸碗状结构后快速收敛。
在实际使用过程中,RMSprop已被证明是一种有效且实用的深度神经网络优化算法。目前它是深度学习人员经常采用的优化算法之一。keras文档中关于RMSprop写到:This optimizer is usually a good choice for recurrent neural networks.
9、Adam(Adaptive Moment Estimation)
Adam实际上是把momentum和RMSprop结合起来的一种算法,是最常用的一种算法,被广泛用于各种结构的神经网络。算法流程如下:

二、算法选择
实践表明,RMSprop,Adadelta和Adam表现的相当鲁棒,而且Adam算法是目前使用最多的,而且公认效果最好的。
[1]Ruder S . An overview of gradient descent optimization algorithms[J]. 2016.