1. PySpark简介
PySpark 是Spark官方提供的一个Python类库,内置了完全的Spark API,可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行。在安装好的Spark集群中,bin/pyspark 是一个交互式的程序,可以提供交互式编程并执行Spark计算。
PySpark和Spark框架对比:
Spark集群(Yarn)角色
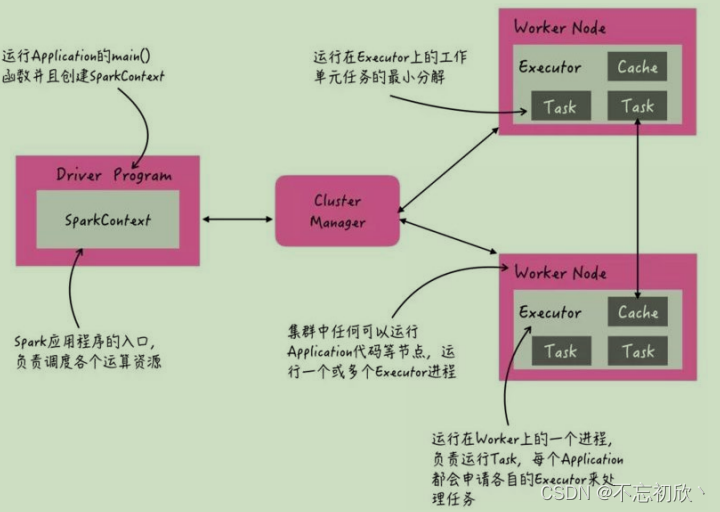
当Spark Application运行在集群上时,主要有四个部分组成
- Master(ResourceManager):
集群大管家,整个集群的资源管理和分配 - Worker(NodeManager):
单个机器的管家,负责在单个服务器上提供运行容器,管理当前机器的资源 - Driver:
单个Spark任务的管理者,管理Executor的任务执行和任务分解分配,类似YARN的ApplicationMaster - Executor:具体干活的进程, Spark的工作任务(Task)都由Executor来负责执行
2. PySpark应用程序
Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象,如下两步构建:
- 创建SparkConf对象:设置Spark Application基本信息,比如应用的名称AppName和应用运行Master
- 基于SparkConf对象,创建SparkContext对象
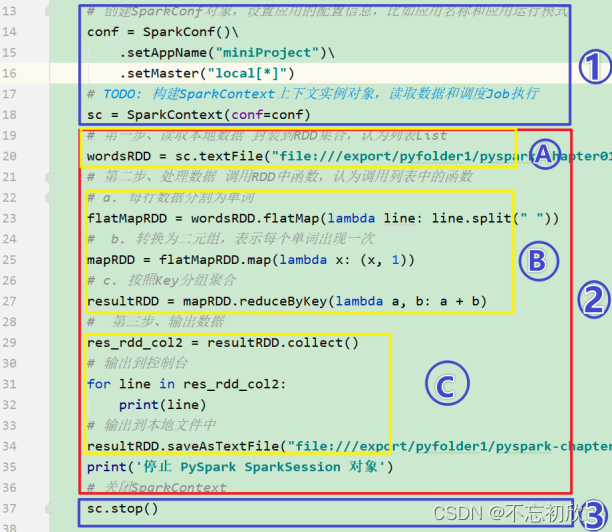
2.1 PySpark实现WordCount
from pyspark import SparkContext,SparkConf
import os
# 配置环境变量
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ["PYSPARK_PYTHON"]="/root/anaconda3/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"]="/root/anaconda3/bin/python"
if __name__ == '__main__':
# 1) 创建SparkConf对象,设置应用的配置信息,比如应用名称和应用的运行模式
conf = SparkConf().setAppName('WordCount').setMaster('local[*]')
# 2) 构建SparkContext上下文实例对象,读取数据和调度Job执行
sc = SparkContext(conf=conf)
# 3) 读取数据,封装到RDD集合,认为列表list
# 本地文件协议: file:///
# HDFS协议: hdfs://node1:8020/
rdd_init = sc.textFile('file:///export/data/workspace/data/words.txt')
# 4) 处理数据,调度RDD函数,对每行数据分割为单词
rdd_flapMap = rdd_init.flatMap(lambda line: line.split(' '))
# 5) 转换为二元祖,每个单词出现一次
rdd_map = rdd_flapMap.map(lambda word: (word,1))
# 6) 分组聚合统计操作,按照key分组聚合
rdd_res = rdd_map.reduceByKey(lambda agg,curr : agg+curr)
# 7) 输出打印结果
print(rdd_res.collect())
# 8) 输出结果到本地文件中
rdd_res.saveAsTextFile("file:///export/data/workspace/data/rst.txt")
# 9) 关闭 sc对象
sc.stop()
WordCount执行流程
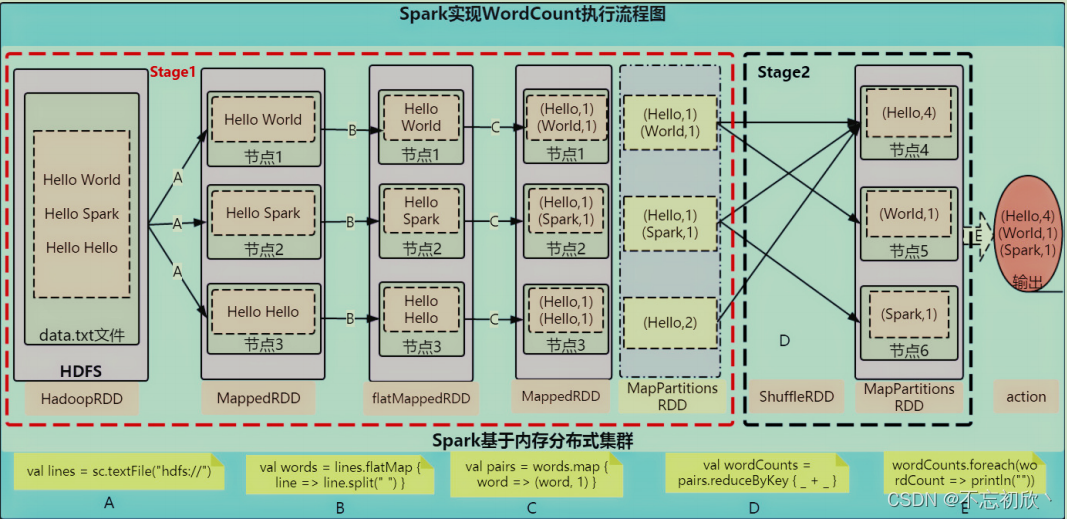
WordCount执行流程分析:
Spark Application应用程序运行时,无论client还是cluster部署模式DeployMode,当Driver Program和Executors启动完成以后,就要开始执行应用程序中MAIN函数的代码。
- 构建SparkContex对象和关闭SparkContext资源,都是在Driver Program中执行,上图中①和③都是:
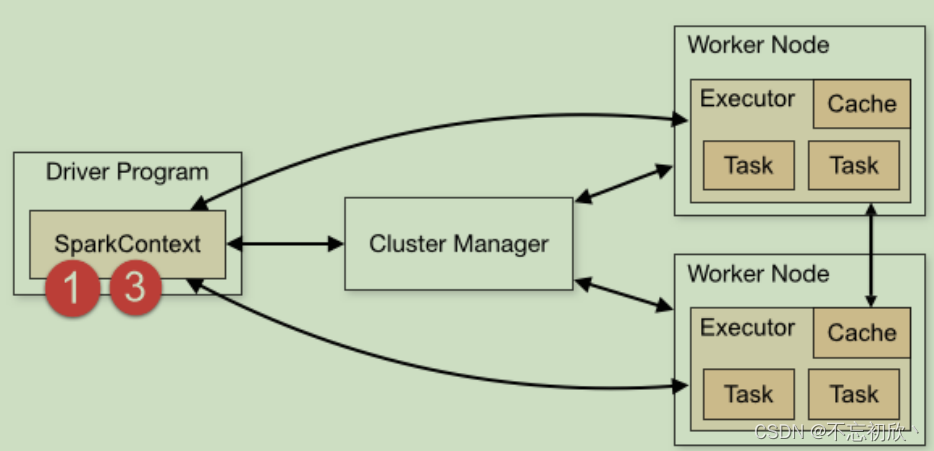
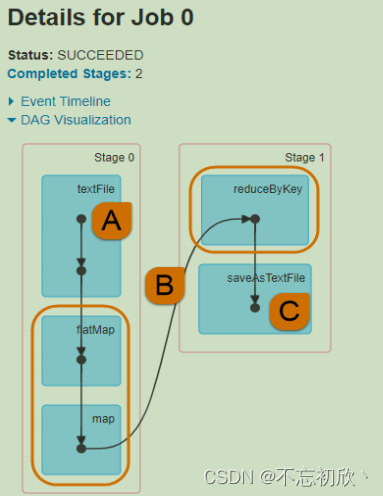
- 上图中②的加载数据【A】、处理数据【B】和输出数据【C】代码,都在Executors上执行,从WEB UI监控页面可以看到此Job(RDD#action触发一个Job)对应DAG图,如下所示:
从WordCount执行流程来看,非数据处理的部分有Driver工作,数据处理的部分由Executor工作。
3. PySpark 执行原理
PySpark宗旨是在不破坏Spark已有的运行时架构,在Spark架构外层包装一层Python API,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序,其运行时架构如下:

详细原理如下图:
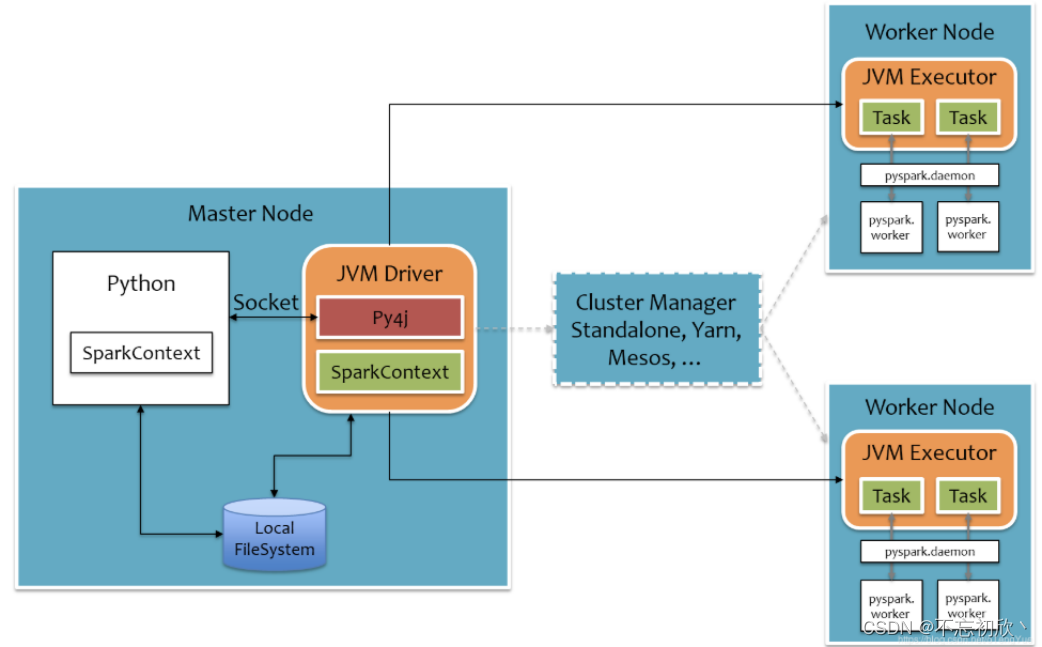
Python On Spark Driver端由JVM执行,Executor端由JVM做命令转发,底层由Python解释器进行工作。其中白色部分是新增的Python进程
在Driver端:通过Py4j实现在Python中调用Java的方法,即将用户写的PySpark程序”映射”到JVM中,例如,用户在PySpark中实例化一个Python的SparkContext对象,最终会在JVM中实例化Scala的SparkContext对象
在Executor端:则不需要借助Py4j,因为Executor端运行的Task逻辑是由Driver发过来的,那是序列化后的字节码,虽然里面可能包含有用户定义的Python函数或Lambda表达式,Py4j并不能实现在Java里调用Python的方法,为了能在Executor端运行用户定义的Python函数或Lambda表达式,则需要为每个Task单独启一个Python进程,通过socket通信方式将Python函数或Lambda表达式发给Python进程执行
参考:
https://www.cnblogs.com/Ao0216/p/16376113.html
https://spark.apache.org/docs/latest/rdd-programming-guide.html