目录
Spark 内核调度
Spark任务调度:如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算
DAG
有向无环图,代表的是spark任务的执行流程图;
示例:
DAG图的作用:标识代码的逻辑运行流程;
DAG图的产生:一个action算子会将其前面一串的RDD依赖关系执行,也就是说一个action会产生一个DAG图;
Job和Action的关系
1个action会产生一个DAG,而一个DAG会在程序运行中产生一个Job;
所以
1action=1DAG=1Job在一个Application中,可以有多个Job,每一个Job内含一个DAG,同时每一个Job都是由一个Action产生的
DAG和分区之间的关联
DAG是Spark代码的逻辑执行图,其最终作用是为了构建物理上的Spark详细执行计划;
由于Spark是分布式执行的,所以DAG与分区也有关联;带有分区交互的DAG是在程序运行之后由spark决定的
DAG的宽窄依赖和阶段划分
窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区;
宽依赖(shuffle):父RDD的一个分区,将数据发给子RDD的多个分区;(需要依赖网络IO)
区分宽窄依赖:看RDD之间有无分叉;
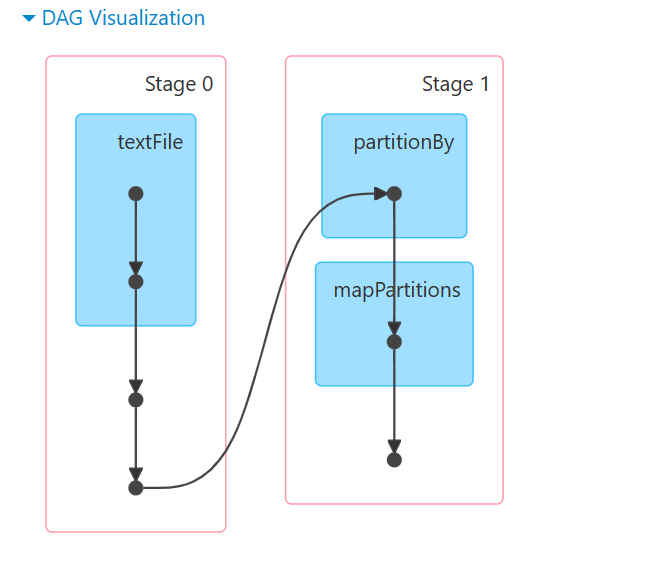
阶段划分:按照宽依赖划分不同的Stage
划分依据:从后向前,遇到宽依赖就划分出一个阶段,成为Stage,如图:
由此可以看出,每一个阶段的内部一定是窄依赖;
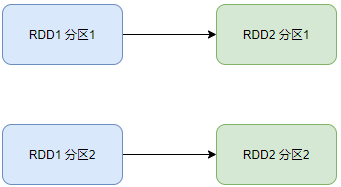
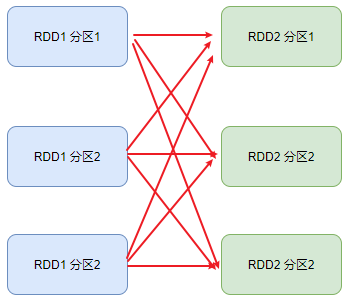

内存迭代计算
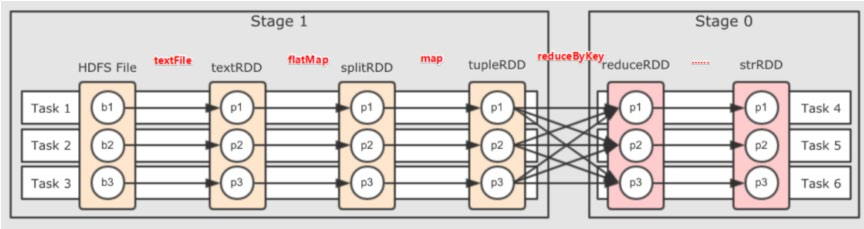
如图,在每一个阶段的内部,有多个Task并行计算,每一个Task是一个线程,线程的相关运算均在内存中完成;这样的多个Task,就形成了并行的内存计算管道;
Task的数量收受到全局并行度的限制,大部分的算子都会依循全局并行度的要求,规划自己的分区;如上图所示,设置了全局并行度为3,rdd算子的并行度也是3(有3个Task)
一般来说,只设置全局并行度,不为计算算子单独设置并行度(否则内存迭代管道会减少,内存迭代管道的长度也会缩短)(有的排序算子需要设置并行度,比如说进行全局排序)
Spark并行度
所谓的并行,指的是在同一时间内,有多少个task在运行;
并行度的设置

全局并行度的设置:
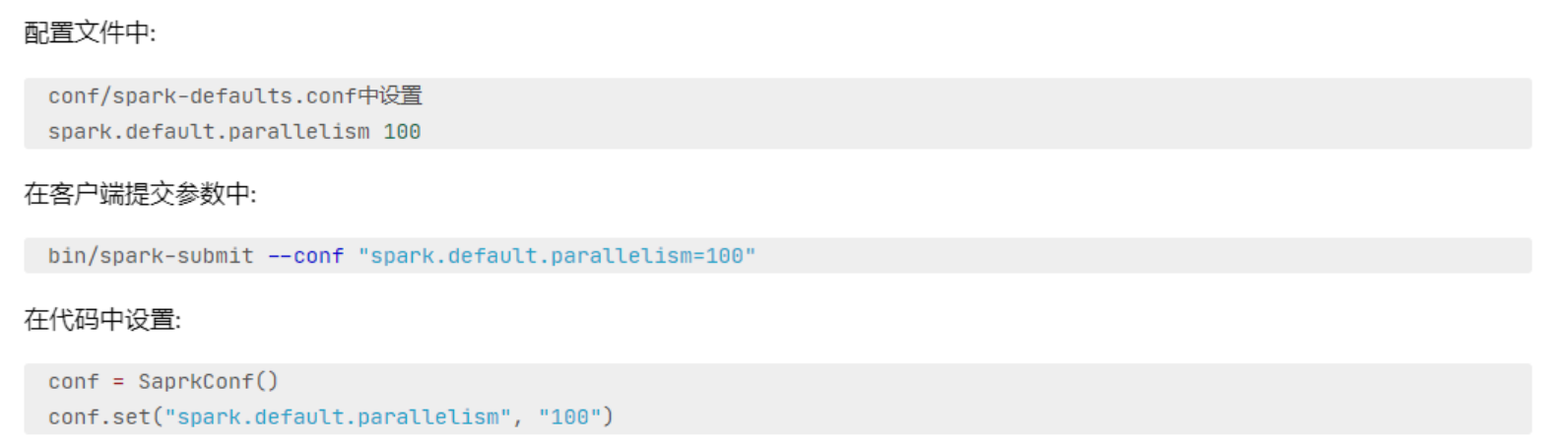
集群中如何规划并行度
设置为CPU总核心数的2-10倍;
原因:

注意:并行度的设置只与CPU的总核心数有关;
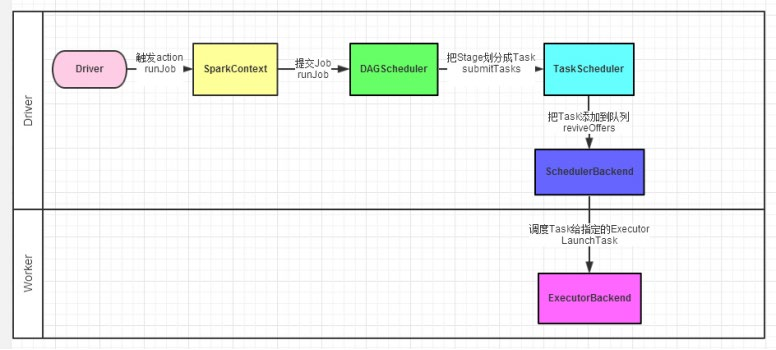
Spark任务调度流程
spark的任务调度由Driver来完成,包括以下内容:

Driver内的两个组件:
①DAG调度器:将逻辑的DAG图进行处理,最终得到逻辑上的Task划分
②Task调度器:基于DAG的产出,来规划这些逻辑的task应该在哪些物理的executor上运行,并监控管理其运行
spark的程序调度流程:

如下图所示: