Pyspark
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Pyspark基础入门3
#博学谷IT学习技术支持
前言
Spark是一款用于大规模数据处理分布式的分析引擎

今天主要分享的RDD
一、RDD的基本介绍
RDD是一个抽象的数据模型, RDD本身并不存储任何的数据, 仅仅是一个数据传输的管道, 在这个管道中,作为使用者, 只需要告知给RDD应该从哪里读, 中间需要进行什么样的转换逻辑操作, 以及最后需要将结果输出到什么位置即可, 一旦启动后, RDD会根据用户设定的规则, 完成整个处理操作
二、RDD的五大特性和五大特点
- 五大特性:
1- (必须的) RDD可分区的
2- (必须的) 每一个RDD都是由一个计算函数产生的
3- (必须的) RDD之间是存在着依赖关系
4- (可选的) 对于KV类型的数据, 是存在分区函数,对于KV类型的RDD默认是基于Hash 分区方案
5- (可选的) 移动数据不如移动计算(让计算程序离数据越近越好)
- 五大特点:
1- RDD是可分区的: 分区是一种逻辑分区, 仅仅定义分区的规则,并不是直接对数据进行分区操作, 因为RDD本身不存储数据
2- RDD是只读的: 每一个RDD都是不可变的, 如果想要改变, 处理后会得到一个新的RDD, 原有RDD保存原样
3- RDD之间存在依赖关系: 每个RDD之间都是有依赖关系的, 也称为血缘关系, 一般分为两种依赖(宽依赖/窄依赖)
4- RDD可以设置cache(缓存): 当计算过程中, 一个RDD被多个RDD所依赖的时候, 可以将这个RDD结果缓存起来, 这样后续使用这个RDD的时候, 可以直接获取, 不需要重新计算
5- RDD的checkpoint(检查点): 与缓存类似, 都是可以将中间某一个RDD的结果保存起来, 只不过checkpoint支持持久化保存
三、如何构建RDD
1- 通过parallelized Collections构建RDD: 并行本地集合方式 (测试)
2- 通过 External Data构建RDD: 加载外部文件的方式 (测试/开发)
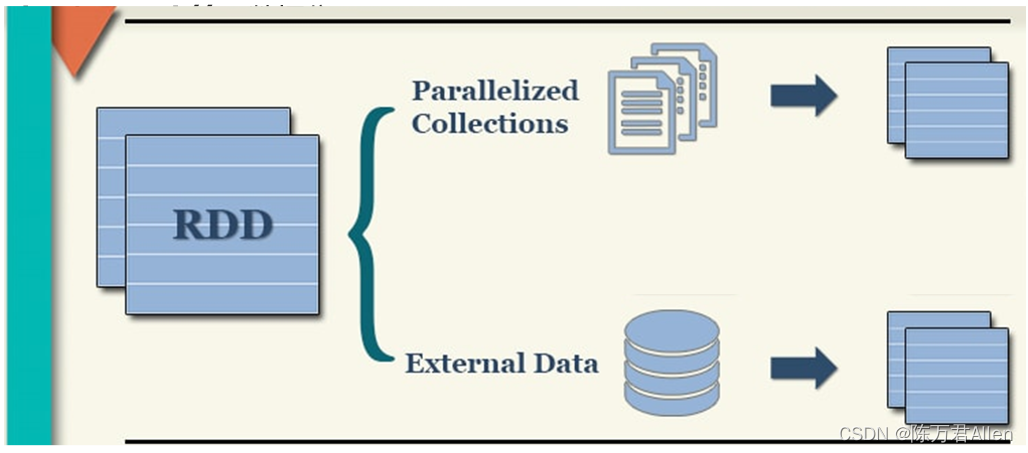
1.通过并行化本地的方式构建RDD
from pyspark import SparkContext, SparkConf
import os
# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("如何构建RDD方式一: 并行本地集合")
# 1. 创建SparkContext核心对象
conf = SparkConf().setAppName("create_rdd_01").setMaster("local[2]")
sc = SparkContext(conf=conf)
# 2. 读取数据集: 本地集合
rdd_init = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10],3)
# 3. 打印结果数据
print(rdd_init.collect())
print(rdd_init.getNumPartitions()) # 获取这个RDD有多少个分区
print(rdd_init.glom().collect()) # 获取每个分区中的数据
# 4- 释放资源
sc.stop()
2. 通过读取外部数据源方式
from pyspark import SparkContext, SparkConf
import os
# 锁定远端环境, 确保环境统一
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("如何构建RDD方式二: 读取外部数据集")
# 1. 创建SparkContext核心对象
conf = SparkConf().setAppName("create_rdd_02").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 2. 读取数据集:
rdd_init = sc.textFile("file:///export/data/workspace/ky06_pyspark/_02_SparkCore/data/")
# 3. 打印结果
print(rdd_init.collect())
print(rdd_init.getNumPartitions())
print(rdd_init.glom().collect())
"""
[
[
'hadoop hive hive hadoop sqoop',
'sqoop kafka hadoop sqoop hive hive',
'hadoop hadoop hive sqoop kafka kafka'
],
[
'kafka hue kafka hbase hue hadoop hadoop hive',
'sqoop sqoop kafka hue hue kafka'
]
]
[
['hadoop hive hive hadoop sqoop', 'sqoop kafka hadoop sqoop hive hive'],
['hadoop hadoop hive sqoop kafka kafka'],
['kafka hue kafka hbase hue hadoop hadoop hive'],
[],
['sqoop sqoop kafka hue hue kafka']]
"""
# 4- 释放资源
sc.stop()
总结
今天给大家分享的是Pyspark基础入门3基本的RDD操作。