一般而言,数据分析工作的目标非常明确,即从特定的角度对数据进行分析,提取有用
信息,分析的结果可作为后期决策的参考。
扩展库pandas是基于扩展库numpy和matplotlib的数据分析模块,是一个开源项目,提
供了大量标准数据模型,具有高效操作大型数据集所需要的功能,可以说pandas是使Python
能够成为高效且强大的数据分析行业首选语言的重要因素之一。
在各领域都存在数据分析需求,我们在实际应用和开发时经常会发现,很少有数据能够
直接输入到模型和算法中使用,基本上都需要进行一定的预处理,例如处理重复值、异常值、
缺失值以及不规则的数据,pandas提供了大量函数和对象方法来支持这些操作。
pandas常用数据类型
- Series,带标签的一维数组
- DatatimeIndex,时间序列
- DataFrame,带标签且大小可变的二维表格结构
- Panel,带标签且大小可变的三维数组
我主要学习前3种结构的基本用法
一维数组与常用操作
>>> import pandas as pd
>>> import matplotlib.pyplot as plt
>>> # 设置输出结果列对齐
>>> pd.set_option('display.unicode.ambiguous_as_wide',True)
>>> pd.set_option('display.unicode.east_asian_width',True)
>>> # 自动创建从0开始的非负整数索引
>>> s1=pd.Series(range(1,20,5))
>>> s1
0 1
1 6
2 11
3 16
dtype: int64
>>> # 使用字典创建Series,使用字典的键作为索引
>>> s2=pd.Series({
'语文':90,'数学':92,'Python':98,'物理':87,'化学':92})
>>> s2
语文 90
数学 92
Python 98
物理 87
化学 92
dtype: int64
>>> # 修改指定索引对应的值
>>> s1[3]=-17
>>> s1
0 1
1 6
2 11
3 -17
dtype: int64
>>> s2['语文']=94
>>> s2
语文 94
数学 92
Python 98
物理 87
化学 92
dtype: int64
>>> abs(s1) # 对s1所有数据求绝对值
0 1
1 6
2 11
3 17
dtype: int64
>>> s1+5 # s1所有的值加5
0 6
1 11
2 16
3 -12
dtype: int64
>>> s1.add_prefix(2) # s1的每行索引前面加上数字2
20 1
21 6
22 11
23 -17
dtype: int64
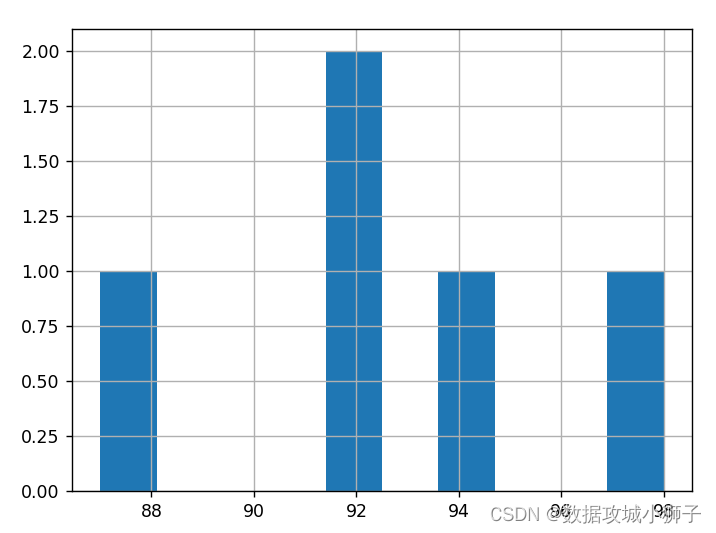
>>> s2.hist() # s2数据的直方图
<Axes: >
>>> plt.show()
>>> s2.add_suffix('_张三') # s2的每行索引后面加上_张三
语文_张三 94
数学_张三 92
Python_张三 98
物理_张三 87
化学_张三 92
dtype: int64
>>> s2.idxmax() # s2最大值的索引
'Python'
>>> s2.between(90,94,inclusive=True) # 测试s2的值是否在指定区间内
Warning (from warnings module):
File "<pyshell#26>", line 1
FutureWarning: Boolean inputs to the `inclusive` argument are deprecated in favour of `both` or `neither`.
语文 True
数学 True
Python False
物理 False
化学 True
dtype: bool
>>> s2.between(90,94,inclusive='both') #FutureWarning显示参数变化了 测试s2的值是否在指定区间内
语文 True
数学 True
Python False
物理 False
化学 True
dtype: bool
>>> s2[s2>90] # 查看s2中90分以上的数据
语文 94
数学 92
Python 98
化学 92
dtype: int64
>>> s2[s2>s2.median()] # 查看s2中大于中值的数据
语文 94
Python 98
dtype: int64
>>> round((s2**0.5)*10,1) # s2与数字之间的运算
语文 97.0
数学 95.9
Python 99.0
物理 93.3
化学 95.9
dtype: float64
>>> s2.median() # s2的中值
92.0
>>> s2.nsmallest(2) # s2中最小的两个值
物理 87
数学 92
dtype: int64
>>> # 两个等长Series对象之间可以进行四则运算和幂运算
>>> # 只对两个Series对象中都有的索引对应的值进行计算
>>> # 非共同索引对应的值为空值NaN
>>> pd.Series(range(5))+pd.Series(range(5,10)) # 两个Series对象相加
0 5
1 7
2 9
3 11
4 13
dtype: int64
>>> pd.Series(range(5)).pipe(lambda x,y,z:(x**y)%z,2,5) # 每个值的平方对5的余数
0 0
1 1
2 4
3 4
4 1
dtype: int64
>>> pd.Series(range(5)).pipe(lambda x,y,z:(x+y)*z,3,3)# 每个值+3再乘以3
0 9
1 12
2 15
3 18
4 21
dtype: int64
>>> pd.Series(range(5)).apply(lambda x:x+3)# 每个值加3
0 3
1 4
2 5
3 6
4 7
dtype: int64
>>> pd.Series(range(5)).std() # 标准差
1.5811388300841898
>>> pd.Series(range(5)).var() # 无偏方差
2.5
>>> pd.Series(range(5)).sem() # 无偏标准差
0.7071067811865476
>>> any(pd.Series([3,0,True])) # 查看是否存在等价于True的值
True
>>> all(pd.Series([3,0,True])) # 查看是否所有值等价于True
False
时间序列与常用操作
'''
start起始日期,end结束日期,periods生成的数据数量
freq时间间隔,D天,W周,H小时
M月末最后一天,MS月初第一天
T分钟,Y年末最后一天,YS年初第一天
'''
>>> #间隔5天
>>> pd.date_range(start='20190601',end='20190630',freq='5D')
DatetimeIndex(['2019-06-01', '2019-06-06', '2019-06-11', '2019-06-16',
'2019-06-21', '2019-06-26'],
dtype='datetime64[ns]', freq='5D')
>>> #间隔1周
>>> pd.date_range(start='20190601',end='20190630',freq='W')
DatetimeIndex(['2019-06-02', '2019-06-09', '2019-06-16', '2019-06-23',
'2019-06-30'],
dtype='datetime64[ns]', freq='W-SUN')
>>> #间隔2天,5个数据
>>> pd.date_range(start='20190601',freq='2D',periods=5)
DatetimeIndex(['2019-06-01', '2019-06-03', '2019-06-05', '2019-06-07',
'2019-06-09'],
dtype='datetime64[ns]', freq='2D')
>>> #间隔3小时,8个数据
>>> pd.date_range(start='20190601',freq='3H',periods=8)
DatetimeIndex(['2019-06-01 00:00:00', '2019-06-01 03:00:00',
'2019-06-01 06:00:00', '2019-06-01 09:00:00',
'2019-06-01 12:00:00', '2019-06-01 15:00:00',
'2019-06-01 18:00:00', '2019-06-01 21:00:00'],
dtype='datetime64[ns]', freq='3H')
>>> #3:00开始,间隔1分钟,12个数据
>>> pd.date_range(start='201906010300',freq='T',periods=12)
DatetimeIndex(['2019-06-01 03:00:00', '2019-06-01 03:01:00',
'2019-06-01 03:02:00', '2019-06-01 03:03:00',
'2019-06-01 03:04:00', '2019-06-01 03:05:00',
'2019-06-01 03:06:00', '2019-06-01 03:07:00',
'2019-06-01 03:08:00', '2019-06-01 03:09:00',
'2019-06-01 03:10:00', '2019-06-01 03:11:00'],
dtype='datetime64[ns]', freq='T')
>>> #间隔1月,月末最后一天
>>> pd.date_range(start='20190101',end='20191231',freq='M')
DatetimeIndex(['2019-01-31', '2019-02-28', '2019-03-31', '2019-04-30',
'2019-05-31', '2019-06-30', '2019-07-31', '2019-08-31',
'2019-09-30', '2019-10-31', '2019-11-30', '2019-12-31'],
dtype='datetime64[ns]', freq='M')
>>> #间隔1年,6个数据,年末最后一天,用A好像也行
>>> pd.date_range(start='20190101',freq='A',periods=6)
DatetimeIndex(['2019-12-31', '2020-12-31', '2021-12-31', '2022-12-31',
'2023-12-31', '2024-12-31'],
dtype='datetime64[ns]', freq='A-DEC')
>>> #间隔1年,6个数据,年初第一天
>>> pd.date_range(start='20190101',freq='AS',periods=6)
DatetimeIndex(['2019-01-01', '2020-01-01', '2021-01-01', '2022-01-01',
'2023-01-01', '2024-01-01'],
dtype='datetime64[ns]', freq='AS-JAN')
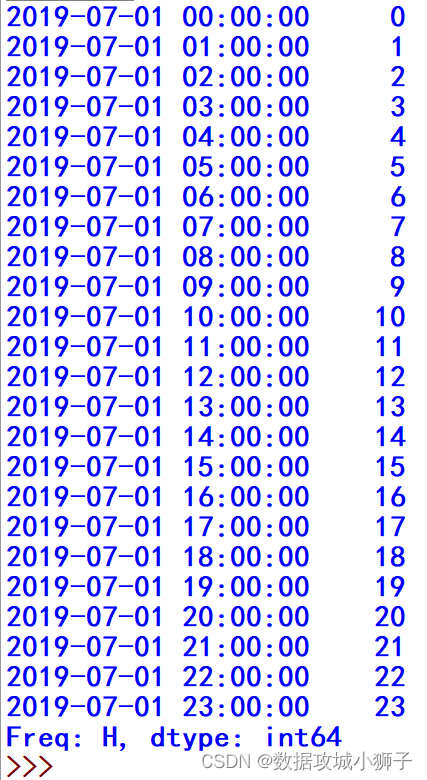
>>> #使用日期时间做索引,创建Series对象
>>> data=pd.Series(index=pd.date_range(start='20190701',periods=24,freq='H'),data=range(24))
>>> data
>>> data[:5] # 前5条数据
2019-07-01 00:00:00 0
2019-07-01 01:00:00 1
2019-07-01 02:00:00 2
2019-07-01 03:00:00 3
2019-07-01 04:00:00 4
Freq: H, dtype: int64
>>> data.resample('3H').mean() # 3小时重采样,计算均值
2019-07-01 00:00:00 1.0
2019-07-01 03:00:00 4.0
2019-07-01 06:00:00 7.0
2019-07-01 09:00:00 10.0
2019-07-01 12:00:00 13.0
2019-07-01 15:00:00 16.0
2019-07-01 18:00:00 19.0
2019-07-01 21:00:00 22.0
Freq: 3H, dtype: float64
>>> data.resample('5H').sum() # 5小时重采样,求和
2019-07-01 00:00:00 10
2019-07-01 05:00:00 35
2019-07-01 10:00:00 60
2019-07-01 15:00:00 85
2019-07-01 20:00:00 86
Freq: 5H, dtype: int64
>>> data.resample('5H').ohlc() # 5小时重采样,统计OHLC值
open ... close
2019-07-01 00:00:00 0 ... 4
2019-07-01 05:00:00 5 ... 9
2019-07-01 10:00:00 10 ... 14
2019-07-01 15:00:00 15 ... 19
2019-07-01 20:00:00 20 ... 23
[5 rows x 4 columns]
>>> pd.set_option("display.max_columns",6) # 自定义显示列数
>>> data.resample('5H').ohlc() # 5小时重采样,统计OHLC值
open high low close
2019-07-01 00:00:00 0 4 0 4
2019-07-01 05:00:00 5 9 5 9
2019-07-01 10:00:00 10 14 10 14
2019-07-01 15:00:00 15 19 15 19
2019-07-01 20:00:00 20 23 20 23
>>> # 所有日期替换为第二天
>>> data.index=data.index+pd.Timedelta('1D')
>>> data[:5]
2019-07-02 00:00:00 0
2019-07-02 01:00:00 1
2019-07-02 02:00:00 2
2019-07-02 03:00:00 3
2019-07-02 04:00:00 4
Freq: H, dtype: int64
>>> pd.Timestamp('20190323').day_name() # 查看指定日期是周几
'Saturday'
>>> pd.Timestamp('201909300800').is_leap_year # 查看指定日期所在年是否为闰年
False
>>> day=pd.Timestamp('20191025')
>>> print(day.quarter,day.month) # 查看指定日期所在的季度和月份
4 10
>>> day.to_pydatetime() # 转换为python的日期时间对象
datetime.datetime(2019, 10, 25, 0, 0)
>>> print(day.to_pydatetime())
2019-10-25 00:00:00
二维数组DataFrame
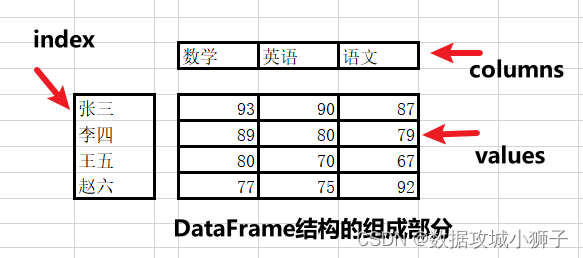
>>> import numpy as np
>>> import pandas as pd
>>> # 在[1,20]区间上生成5行3列15个随机数
>>> # 使用index参数指定索引,columns参数指定每列标题
>>> df=pd.DataFrame(np.random.randint(1,20,(5,3)),index=range(5),columns=['A','B','C'])
>>> print(df)
A B C
0 7 14 12
1 7 8 17
2 13 6 14
3 1 2 3
4 19 12 19
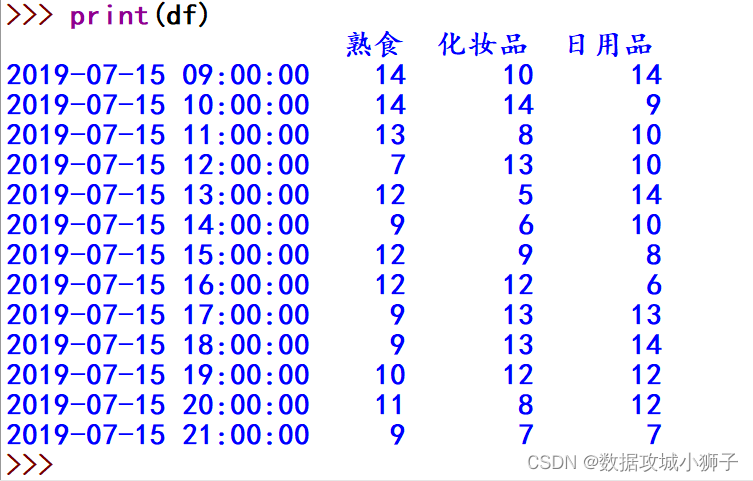
>>> # 模拟2019年7月15日某超市熟食、化妆品、日用品每小时的销量
>>> # 使用时间序列作为索引
>>> df=pd.DataFrame(np.random.randint(5,15,(13,3)),index=pd.date_range(start='201907150900',end='201907152100',freq='H'),columns=['熟食','化妆品','日用品'])
>>> print(df)
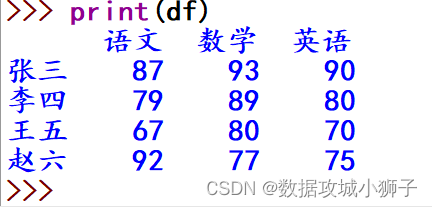
>>> # 模拟考试成绩,使用人名字符串作为索引
>>> df=pd.DataFrame({
'语文':[87,79,67,92],'数学':[93,89,80,77],'英语':[90,80,70,75]},index=['张三','李四','王五','赵六'])
>>> print(df)
>>> # 自动对B列数据进行扩充,使其与A列数据一样多
>>> df=pd.DataFrame({
'A':range(5,10),'B':3})
>>> print(df)
A B
0 5 3
1 6 3
2 7 3
3 8 3
4 9 3