论文

论文:Transformers in Remote Sensing: A Survey
论文地址:https://arxiv.org/abs/2209.01206
[2209.01206] Transformers in Remote Sensing: A Survey (arxiv.org)
Transformers in Remote Sensing: A Survey - 专知论文 (zhuanzhi.ai)
项目地址:https://github.com/VIROBO-15/Transformer-in-Remote-Sensing
GitHub - VIROBO-15/Transformer-in-Remote-Sensing
摘要
在过去的十年里,基于深度学习的算法在遥感图像分析的不同领域中得到了广泛的应用。最近,基于变压器Transformer的架构,最初引入于自然语言处理,已经渗透到计算机视觉领域,其中自我注意机制已经被用来取代流行的卷积算子来捕捉长距离依赖。在计算机视觉最新进展的启发下,遥感领域也见证了越来越多的视觉转换器用于各种任务的探索。虽然一些调查的重点一般是计算机视觉中的变压器,但据我们所知,我们是第一次系统地审查在遥感中基于变压器的最新进展。我们的调查涵盖了60多种最新的基于变压器的方法,用于遥感领域的不同遥感问题:甚高分辨率(VHR)、高光谱(HSI)和合成孔径雷达(SAR)图像。我们通过讨论变压器在遥感方面的不同挑战和开放问题来结束调查。
1 引言
在过去的几十年里,遥感成像技术有了长足的进步。现代机载传感器以更高的空间、光谱和时间分辨率覆盖地球表面,从而在许多研究领域发挥关键作用,包括生态学、环境科学、土壤科学、水污染、冰川学、土地测量和地壳分析。遥感成像的自动分析带来了独特的挑战,例如,数据通常是多模式的(例如,光学或合成孔径雷达传感器),位于地理空间(地理位置),通常在全球范围内,数据量不断增长。
深度学习,特别是卷积神经网络(CNN)已经主导了计算机视觉的许多领域,包括目标识别、检测和分割。这些网络通常将RGB图像作为输入,并执行一系列卷积、局部归一化和池化操作。CNN通常依赖于大量的训练数据,所得到的预先训练的模型然后被用作各种下游应用的通用特征提取器。计算机视觉中基于深度学习的技术的也在许多遥感任务方面取得了重大进展,包括高光谱图像分类、变化检测和极高分辨率卫星实例分割。
卷积运算是CNN的主要组成部分之一,它捕捉输入图像中元素(如轮廓和边缘信息)之间的局部相互作用。CNN编码偏移,例如空间连通性和平移等变性。这些特性有助于构建可泛化和高效的体系结构。然而,CNN中的局部感受场限制了对图像中的长期依赖关系的建模(例如,远距离部件关系)。此外,卷积是与内容无关的,因为卷积过滤器的权重是固定的,对所有输入施加相同的权重,而不考虑它们的性质。最近,视觉转换器(VITs)[1]在计算机视觉的各种任务中表现出了令人印象深刻的性能。VITs基于自我注意机制,该机制通过学习序列元素之间的关系来有效地捕获全局交互。最近的工作[2]、[3]表明,VITs具有依赖于内容的远程交互建模能力,并且可以灵活地调整其接受域以对抗数据中的干扰和学习有效的特征表示。因此,VITs及其变体已被成功地用于许多计算机视觉任务,包括分类、检测和分割。
随着VITs在计算机视觉方面的成功,遥感领域也见证了在许多任务中使用基于变压器的框架的显著增长(见图1),例如,非常高分辨率的图像分类、变化检测、全景锐化、建筑物检测和图像字幕。这开启了新一波有希望的遥感研究,采用了不同的方法,要么利用ImageNet预培训[4]-[6],要么使用视觉转换器进行遥感预训练[7]。类似地,文献中存在基于纯变压器设计[8]、[9]的方法,或者利用基于变压器和CNN的混合方法[10]-[12]。因此,由于针对不同遥感问题的基于变压器的方法的迅速涌入,要跟上最近的进展,正变得越来越具有挑战性。
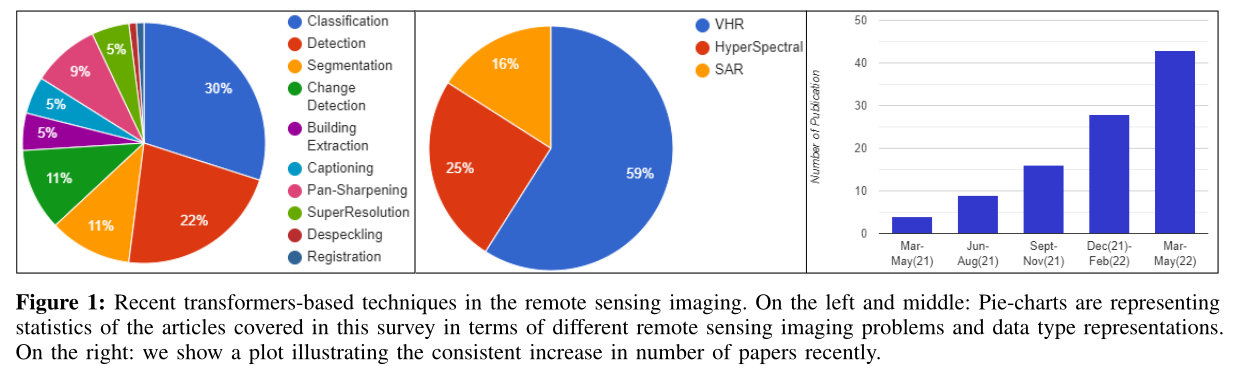
在这项工作中,我们回顾了这些进展,并介绍了在流行的遥感领域中基于变压器的最新方法。综上所述,我们的主要贡献如下:
- 我们将全面概述遥感成像中基于变压器的模型。据我们所知,我们是第一个提出关于遥感变压器的综述,从而弥合了计算机视觉和遥感在这一快速增长和流行领域的最新进展之间的差距。
- 我们概述了CNN和变压器,讨论了它们各自的优点和缺点。
- 我们回顾了60多篇基于变压器的研究文献,讨论了遥感领域的最新进展。
- 在综述的基础上,讨论了变压器在遥感领域面临的不同挑战和研究方向。
本文件的其余部分安排如下:第二节讨论与遥感成像有关的其他调查。在第三节中,我们概述了遥感中的不同成像方式,而第四节简要概述了CNN和视觉转换器。然后,我们在第七节中回顾了基于变压器的方法在甚高分辨率(VHR)成像(第五节)、高光谱图像分析(第六节)和合成孔径雷达(SAR)方面的进展。在第八节中,我们总结了我们的综述,并讨论了未来的研究方向。
2 相关工作
在过去的十年中,一些文献对遥感成像中的机器学习技术进行了回顾。Tuia等人。[13]比较和评价了不同的主动学习算法在有监督遥感图像分类任务中的应用。[14]的工作集中在高光谱图像分类问题上,并回顾了与机器学习和视觉技术相关的最新进展。朱等人。[15]全面回顾了深度学习技术在遥感图像分析中的应用。他们的工作提供了对现有方法的全面审查,并描述了有关遥感深度学习的资源清单。Ma等人。[16]回顾遥感中关于图像分辨率和研究区域的主要深度学习概念。为此,他们的工作研究了不同的遥感任务,如图像配准、融合、场景分类、目标分割等。
最近,随着自然语言处理(NLP)中基于转换器的模型的突破[17],基于转换器的方法在计算机视觉社区内出现了显著的激增。可汗等人。[18]概述了视觉中的变压器模型,重点介绍了识别、生成性建模、多模式、视频处理和低级视觉任务。Shamshad等人。[19]调查变压器模型在医学成像中的使用,重点关注不同的医学成像任务,如分割、检测、重建、配准和临床医学报告生成。[20]的工作概述了使用变压器对视频数据建模的日益增长的趋势。他们的工作还比较了视觉转换器在不同视频任务中的表现,比如动作识别。
与上述调查不同的是,我们的工作回顾了基于变压器的方法在遥感热门领域的最新进展。据我们所知,这是第一次全面介绍变压器在遥感方面的情况,特别是在甚高分辨率、高光谱和合成孔径雷达图像分析方面的进展。
3 遥感图像数据
遥感图像通常从一系列来源和数据收集技术获得。遥感图像数据通常具有空间分辨率、光谱分辨率、辐射分辨率和时间分辨率。空间分辨率指的是图像中的每个像素大小以及相应像素所代表的地球表面面积。空间分辨率表征了成像场景中可以分离的小而精细的特征。光谱分辨率是指传感器通过识别更窄的波长(例如,10 nm)来收集有关场景的信息的能力。另一方面,辐射分辨率表征了每个像素中信息的范围,传感器的动态范围越大,意味着图像中要识别的细节越多。时间分辨率是指在地面上相同位置的连续图像之间所花费的时间,这些图像是由感应器获取来。在这里,我们简要讨论常用的遥感成像类型,图2所示的例子很少。

超高分辨率图像 Very High-resolution Imagery
近年来,超高分辨率(VHR)卫星传感器的出现为产生更高空间分辨率的图像铺平了道路,这些图像有助于土地利用变化检测、基于对象的图像分析(目标检测和实例分割)、精确农业耕作(如作物、土壤和病虫害管理)和应急反应。此外,传感器技术的这些最新进展以及基于深度学习的新技术使人们能够使用VHR遥感图像来分析沿海和内陆水域的生物物理和生物地球化学过程。如今,光学传感器以更精细的空间分辨率(例如,10至100厘米/像素)产生地球表面的全色和多光谱图像。
高光谱图像 Hyperspectral Imagery
在这里,场景中的每个像素都是使用具有精细波长分辨率的连续光谱来捕捉的。连续光谱的波长延伸到可见光以外,包括从紫外线(UV)到红外(IR)的波长。通常,高光谱图像的光谱分辨率是用波数和纳米(Nm)表示的。用来测量像素的最常用的连续光谱是中红外,即近红外和可见光波段。为了获得高光谱图像,有不同的电磁测量方法,如拉曼光谱、X射线光谱、太赫兹光谱、三维超声成像、磁共振和共聚焦激光显微镜扫描仪,它们可以测量特定激发波长下每个像素的整个发射光谱。高光谱图像具有高维、精细光谱分辨率强的特点。这些图像提供了广泛的应用,包括环境科学[21]和采矿[22]。与常规图像只包含可见光谱内的原色(红、绿、蓝)不同,高光谱图像包含丰富的光谱信息,可以反映感兴趣物品的物理结构和化学成分。在遥感领域,高光谱图像的自动分析是一个活跃的研究课题。
合成孔径雷达图像 Synthetic Aperture Radar Imagery
地球观测卫星每天通过发射和接收电磁信号产生大量的合成孔径雷达图像。在过去的几十年里,SAR图像因其更高的空间分辨率、全天候能力、去噪工具(如CAESAR)以及最近在SAR特定图像处理方面的进展而变得流行起来。合成孔径雷达图像可用于多种应用,包括地理定位、目标检测、基本雷达的功能以及复杂环境下的地球物理特征估计,如粗糙度、含水率和密度。此外,合成孔径雷达图像可用于灾害管理(浮油探测、冰层追踪)、林业和水文学。
4 从CNN 到 Vision Transformer
在本节中,我们首先对CNN进行简要概述,然后对最近用于不同视觉任务的视觉转换器进行简要描述。
A. 卷积神经网络 Convolutional Neural Networks
卷积神经网络(CNN)已经主导了各种计算机视觉任务,包括图像分类[23]和目标检测[24]。CNN通常由两个主要部分组成:卷积层和池层。卷积层通过将输入中的局部区域与一组核进行卷积来生成特征地图。这些特征服从非线性函数,对于每个卷积层重复相同的过程。在CNN中,池化层对特征地图执行下采样操作(通常利用最大或平均操作)。在不同的现有CNN架构中,卷积层和池层之后是一组完全连通层,其中最后一个完全连通层是计算每个对象类别分数的Softmax。
流行的CNN主干 Popular CNN Backbones
在这里,我们简要讨论文献中不同的流行的CNN主干架构。
AlexNet:Krizevsky等人。[23]提出了一种用于图像分类任务的CNN体系结构AlexNet。AlexNet由五个卷积层和三个全连通层组成。提出的网络结构利用纠错线性单元(REU)来提高训练效率。该网络包含6000万个参数和50万个神经元,并在大规模ImageNet数据集上进行网络训练[25]。采用不同的数据增强技术来增加训练集。在ImageNet 2012大赛中,AlexNet以39.7%和18.9%的前1名和前5名错误率取得了具有竞争力的表现。
VGGNet:不同于AlexNet、Simonyan和Zisserman[26]介绍的一种名为VGGNet的体系结构,该体系结构总共由16层组成。该网络接受224×224大小的输入图像,有大约1.38亿个参数。它使用不同的数据增强技术,包括网络训练期间的规模抖动。VGGNet结构包括3×3滤波器的卷积层,其中接收场在每个像素处以一个像素的步长进行卷积。VGGNet包含多个池化层,以两个像素的跨度在2×2窗口上执行空间池化。此外,VGGNet包含两个完全连接的层,后跟一个用于产生输出预测的Softmax。VGG架构在2014年ImageNet分类挑战中实现了最高的分类准确率。
RESNET:与AlexNet和VGGNet不同,他等人。[27]引入残差神经网络(ResNet)来堆叠残差块来构建网络。RESNET为培训网络提供了一种剩余学习方法,这种方法比以前使用的同行深入得多。它不是学习未引用的函数,而是将层显式地重新表示为参考层输入的学习残差函数。大量的经验证据表明,剩余网络更容易优化,从更高的深度获得更高的精度。
基于CNN的体系结构的发展导致了新技术、改进的硬件(例如GPU和TPU)、更好的优化方法和许多开源库的兴起。感兴趣的读者可以浏览与CNN遥感方法相关的调查论文[15]、[16]。以前的工作已经分析了CNN能够捕获图像特定的归纳偏差,从而提高了它们在学习更好的特征表示方面的有效性。然而,CNN并不捕获有助于增强表示的表现力的长范围依赖关系。接下来,我们将简要介绍能够对图像中的远程依赖关系进行建模的视觉转换器。
B. 视觉变形器 Vision Transformer
最近,基于变形器的模型在许多计算机视觉和语言处理(NLP)任务中取得了可喜的结果。V Aswani等人。[17]首先介绍了作为注意力驱动的机器翻译应用模型的转换器。为了捕获远程依赖关系,转换器使用自我关注层,而不是传统的递归神经网络,后者努力编码序列元素之间的这种依赖关系。
为了有效地捕获输入图像中的远程依赖关系,[1]的工作引入了用于图像识别任务的视觉转换器(VITs),如图3所示。VITs[1]将图像解释为一系列补丁,并通过与NLP任务中使用的类似的传统变压器编码器对其进行处理。VITs在通用视觉数据方面的成功不仅在计算机视觉的不同领域引起了人们的兴趣,而且在遥感领域也引起了兴趣,近年来在遥感领域探索了许多基于VIT的技术来完成各种任务。
接下来,我们将简要描述变压器中自我注意的关键组成部分。
自注意力 Self-Attention
自我注意机制一直是转换器的一个组成部分,因为它捕获了远程依赖关系,并编码了所有序列令牌之间的交互(补丁嵌入)。自我注意的关键思想是学习自我对齐,即通过聚合序列中所有其他标记的全局知识来更新标记[28]。给定2D图像,该过程开始于将图像展平成一系列2D块
,其中C表示通道数,H和W表示图像的高度和宽度,P×P是每个单独块的尺寸,
表示块的总数。使用E维线性可学习投影层来投影这些平坦的面片,并可以表示为矩阵
。自我关注的目的是理解所有M个嵌入之间的相互作用,这是通过引入三个可学习的权重矩阵来修改输入X到查询(如
) 、关键字(如
)和值(如
)来实现的,其中Eq=Ek。该序列X首先被投影到这些权重矩阵上,以获得
,
和
。相对关注矩阵
为
 。
。
掩码自注意力 Masked Self-Attention
所有实体都关注通常的自我关注层。在变压器模型[17]的解码器中使用的这些自我注意块被屏蔽,以防止关注随后的未来实体,该模型被训练以预测序列中的下一个实体。该任务通过具有掩码的逐元素乘法运算来执行,其中M是上三角矩阵。在这里,掩码自关注力表现为

其中◦代表Hadamard product 矩阵乘法。在掩码自注意力中,当预测序列中的实体时,未来实体的注意力等级被设置为零。
多头自注意力 Multi-Head Attention
多头注意(MHA)包括多个自我注意块,这些自我注意块在通道上同时串联,以捕捉不同嵌入序列之间不同的复杂交互。多头自我注意的每个头部都有自己的可学习权重矩阵,分别表示为、
和
,其中i=0,···,(h−1)其中h表示多头自我注意中的头部个数。因此,我们可以表达,
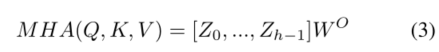
其中,每个头部的输出被串联以形成单个矩阵,而
计算头部的线性变换。
流行的Transformer主干 Popular Transformers Backbones
在这里,我们简要讨论一些最新的基于变压器的主干。
VIT:[1]的工作引入了一种体系结构,其中直接利用一个纯转换器来对图像块序列进行图像分类。VIT架构设计不使用特定于图像的归纳偏差(例如,平移等价性和局部性),并且在大规模ImageNet21k或JFT-300M数据集上执行预训练。
Swin:刘等人。[29]通过引入可产生层次化特征体系结构来改进VIT设计表示。Swin变换具有关于输入图像大小的线性计算复杂性,其中效率是通过将自注意计算限制在非重叠的局部窗口而实现的,同时允许跨窗口连接。
PVT:[30]的工作引入了金字塔视觉转换器(PVT)架构,以执行像素级密集预测任务。PVT体系结构利用一个逐渐缩小的金字塔和一个空间缩减关注层来生成高分辨率的多尺度特征地图。与具有相似参数的CNN相比较,PVT主干在目标检测和分割任务上取得了令人印象深刻的性能。
变压器提供了独特的特性,这些特性对不同的视觉任务很有用。与计算静态过滤器的CNN中的卷积运算相比,自关注中的过滤器是动态计算的。此外,输入点数的排列和变化对自我注意几乎没有影响。最近的研究[2]、[3]探索了视觉转换器的不同有趣的特性,并将它们与CNN进行了比较。例如,最近[2]的工作表明,视觉转换器对严重的闭塞、区域移位和扰动更健壮。接下来,基于图4所示的分类,我们对遥感中的变压器进行了回顾。
遥感领域 Transformer的应用示意图

5 VHR图像中Transformer
在这里,我们回顾了基于变压器的方法,用于解决超高分辨率(VHR)图像中的不同问题。
A. 场景分类
遥感场景分类是一个具有挑战性的问题,其中的任务是自动将语义类别标签与包含真实物体和不同土地覆盖类型的给定高分辨率图像相关联。在现有的基于视觉变换的VHR场景分类方法中,Bazi等人提出了基于视觉变换的VHR场景分类方法。[4]探索[1]标准视觉转换器架构(VIT)的影响,并研究用于生成加法数据的不同数据增强策略。此外,他们的工作还评估了在保持分类精度的同时通过修剪层来压缩网络的影响。
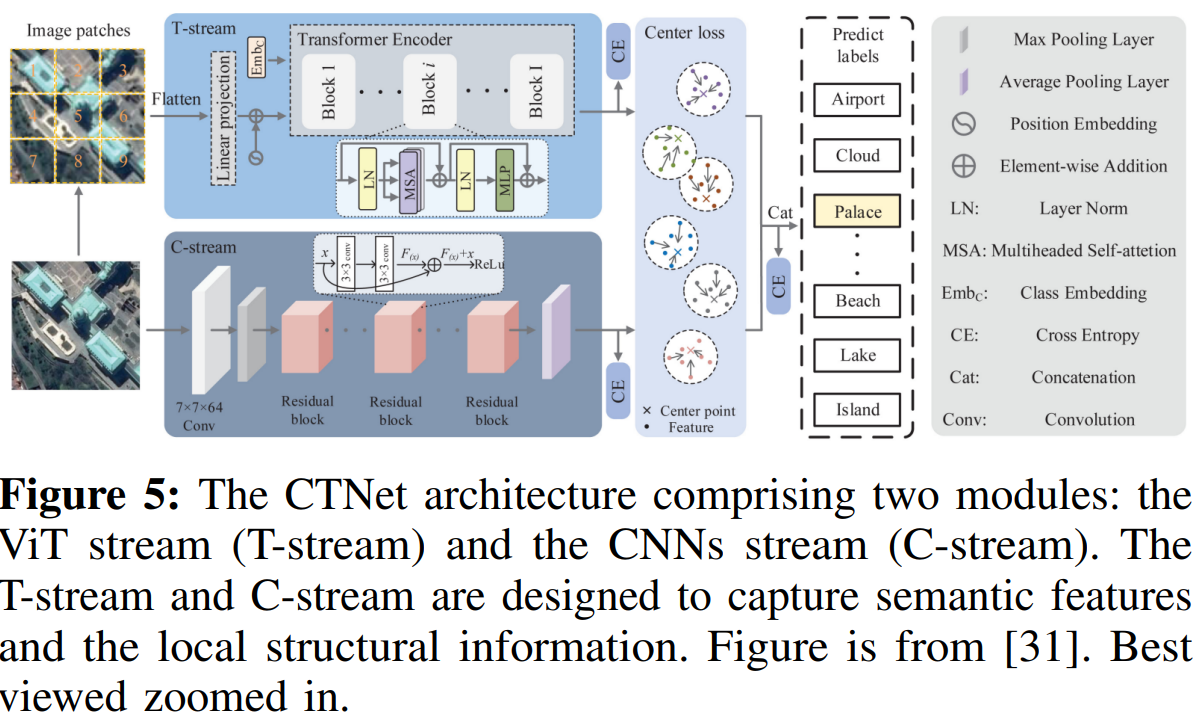
[31]的工作引入了一个联合CNN-transformers框架,其中有一个CNN流和另一个VIT流,如图5所示。来自两个流的特征被级联,整个框架使用包括交叉熵和中心损失的联合损失函数进行训练,以优化两个流的体系结构。张某等人。[32]介绍了一种名为遥感变压器(TRS)的框架,该框架通过用多头自我注意取代空间卷积来努力结合神经网络和变压器的优点。由此产生的多头自我注意瓶颈具有较少的参数,并且与其他瓶颈相比被证明是有效的。文献[5]提出了一种双流Swin变压器网络(TSTNet),该网络由两个流组成:原始流和边流。原始流提取标准图像特征,而边缘流包含可微的边缘Sobel算子模块,并提供边缘信息。在此基础上,引入加权特征融合模块,有效地融合了两个数据流的特征,提高了分类性能。[6]的工作引入了一个基于转换器的框架,该框架带有一个旨在生成同质和异质补丁的补丁生成模块。补丁生成模块直接生成异质补丁,而同质补丁则通过超像素分割方法得到。
遥感预训练 Remote Sensing Pre-training
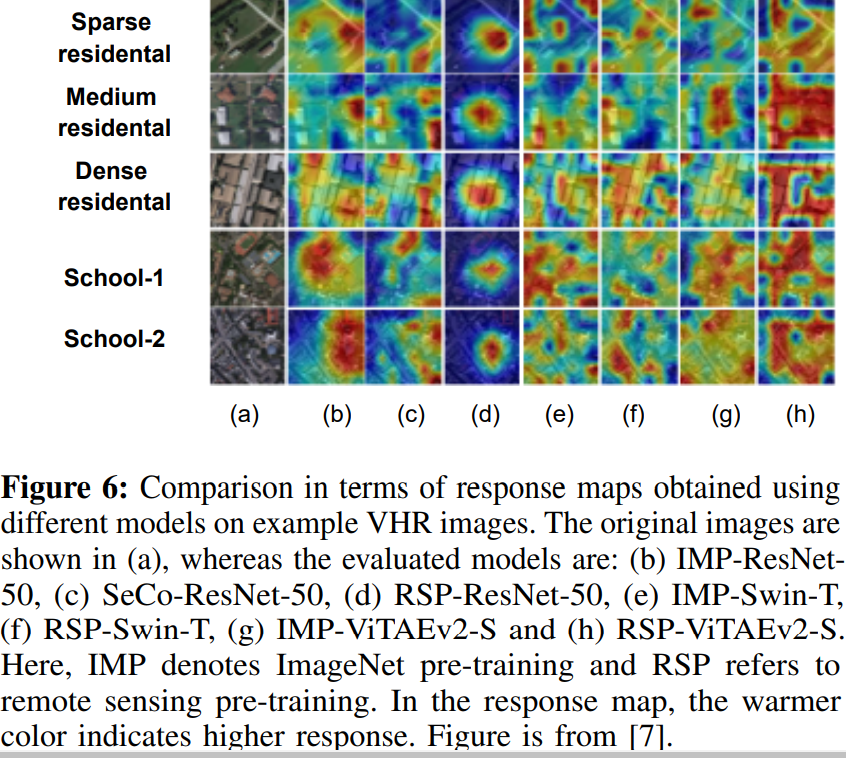
与前述只使用变压器或使用在ImageNet数据集上预先训练的骨干网络的CNN-变压器混合设计的方法不同,[7]最近的工作是在大规模Million AID遥感数据集上从头开始培训视觉变压器骨干,如Swin[33]。然后,针对包括场景分类在内的不同任务对训练后的主干模型进行微调。图6显示了使用Grad-CAM++[34]获得的不同ImageNet(IMP)和遥感预训练(RSP)模型的响应图。可以观察到,与IMP模型相比,RSP模型通过更多地关注重要目标来学习更好的语义表征。此外,基于变压器的主干,如Swin-T,由于自我注意机制,更好地捕获上下文信息。此外,诸如ViTAEv2-S这样的主干结合了CNN和变压器以及RSP的优点,可以获得更好的识别性能。

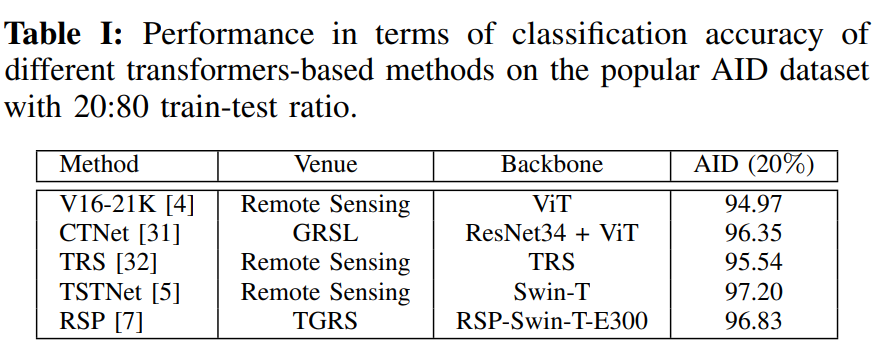
表I显示了上述分类方法在最常用的VHR分类基准之一:AID[35]上的比较。AID数据集包含从多源传感器获取的图像。数据集具有高度的类内差异,因为图像来自不同的国家、不同的时间和季节以及不同的成像条件。数据集共有10,000张图像和30个类别。性能是根据所有类别的平均分类准确率来衡量的。有关AID的更多细节,请参阅[35]。除了对Million-AID数据集执行初始预训练的RSP之外,这里的所有方法都使用在ImageNet基准上预训练的模型。
B. 目标检测
VHR成像中的目标定位是一个极具挑战性的问题,因为不同的目标类别具有极大的尺度差异和多样性。这里的任务是同时识别和定位(矩形或定向边界框)属于不同对象的所有实例图像中的类别。现有的大多数方法采用了一种混合策略,结合了现有的两级和单级检测器中CNN和变压器的优点。除了混合策略,很少有近期的工作也探索基于DETR的变压器目标检测范例[36]。
基于混合CNN-Transformer的方法 Hybrid CNN-Transformers based Methods
[37]的工作引入了局部感知Swin变压器(LPSW)主干,以改进用于检测VHR图像中小目标的标准变压器。提出的LPSW努力结合了变压器和CNN的优点,以提高局部感知能力,从而获得更好的检测性能。使用不同的检测器对所提出的方法进行了评估,例如MASK RCNN[38]。[39]的工作介绍了一种基于变压器的检测体系结构,其中预先训练的CNN用于提取特征,而变压器适用于处理遥感图像的特征金字塔。张某等人。[40]介绍了一种检测框架,利用一个高效的变压器作为分支网络,以提高CNN对全局特征的编码能力。此外,还采用产生式模型将输入的遥感航空影像扩展到主干网的前方。[41]的工作提出了一个基于RetinanNet的检测框架,在骨干网络和后处理网络之间使用特征金字塔转换器(FPT)来生成有语义意义的特征。FPT支持跨尺度的不同级别的要素之间的交互。[42]的工作引入了一个框架,其中采用转换器来对采样特征之间的关系进行建模,以便对它们进行适当的分组。因此,无需任何后处理操作即可获得更好的分组和边界框预测。该方法有效地消除了背景信息,有助于提高检测性能。
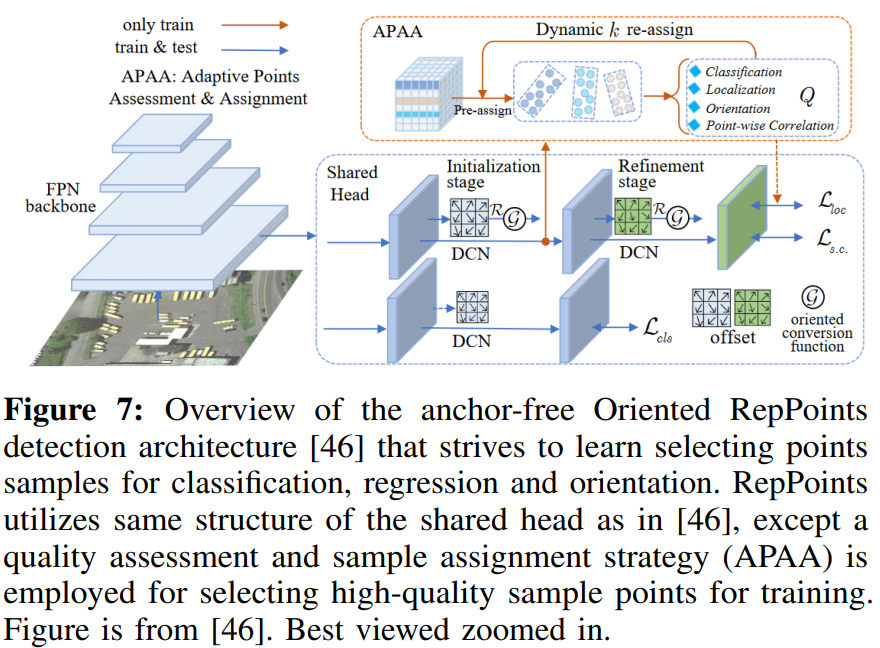
张某等人。[43]介绍了一种将深度可分卷积的局部特性与MLP的全局(信道)特性相结合的混合架构。[44]的工作引入了一个两级无角度检测器,其中RPN和回归都是无角度的。他们的工作还评估了建议的基于变压器主干的检测器(Swin-Tiny)。刘等人。[45]提出了一种称为TransConvNet的混合网络结构,旨在通过聚合全局和局部信息来结合CNN和转换器的优点,以更好地关注上下文来解决CNN的旋转不变性。此外,设计了一种自适应特征融合网络,用于从多个分辨率获取信息。[46]的工作介绍了一种检测框架,称为定向Rep-Points,它利用灵活的自适应点作为表示。提出的无锚点学习方法从分类、定位和定向三个方面学习选择点样本。具体地说,为了学习任意定向空中目标的几何特征,引入了一种质量评估和样本分配方案,该方案测量和识别用于训练的高质量样本点,如图7所示。此外,他们的方法利用空间约束来惩罚位于定向框之外的样本点,以实现点的稳健学习。
基于DETR的检测方法 DETR-based Detection Methods
最近很少有方法研究将基于变压器的DETR检测框架[36]用于VHR成像中的定向目标检测。[47]的工作使标准DETR适用于面向对象检测。在他们的方法中,通过用深度可分离的卷积取代标准的注意机制,为变压器设计了高效的编码器。戴等人。[48]提出了一种基于变压器的检测器,称为AO2-DETR,其中采用面向对象的提案生成方案来显式生成面向对象的提案。此外,他们的方法包括一个面向自适应的建议细化模块,该模块被设计为通过消除区域特征和对象之间的未对齐来计算旋转不变特征。此外,利用旋转感知匹配损失来执行用于没有重复预测的直接集合预测的匹配处理。
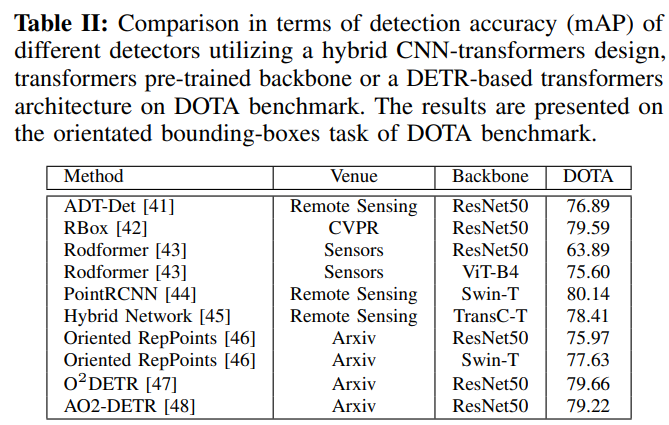
表II显示了上述检测方法在最常用的VHR检测基准DOTA上的比较[49]。该数据集包括2806张大型航空图像,涉及15个不同类别的物体:飞机、棒球场、篮球场、足球场、桥梁、场地跑道、小型车辆、轮船、大型车辆、网球场、环形交叉路口、游泳池、港口、储油罐和直升机。检测性能精度用平均平均精度(MAP)来衡量。关于DOTA的更多细节,我们参考[49]。结果表明,这些最新的方法大多获得了相似的检测精度,但使用Swin-T主干时性能略有改善。
C. 图像变化检测
在遥感中,图像变化检测是检测地球表面变化的一项重要任务,在农业[50]、[51]、城市规划[52]和地图修订[53]中有着广泛的应用。这里,任务是生成通过比较多时相或双时相图像而获得的变化图,所得到的二值变化图中的每个像素根据相应位置是否已改变而具有零值或一值。在最近的基于变压器的变化检测方法中,Chen等人。[54]提出了一种双时相图像转换器,封装在基于深度特征差分的框架中,用于对时空上下文信息进行建模。在该框架中,编码器被用来捕获基于令牌的时空中的上下文。然后,将得到的上下文化标记馈送到解码器,在那里在像素空间中精炼特征。郭某等人。[55]提出了一种深度多尺度暹罗结构,称为MSPSNet,它利用并行卷积结构(PCS)和自我注意。MSPSNet通过PCS对不同的时间图像进行特征融合,然后进行基于自我关注的特征求精,进一步增强多尺度特征。[56]的工作引入了一种基于Swin Transformer的网络,该网络具有暹罗U形结构,称为SwinSUNet,用于变化检测。提出的SwinSUNet由三个模块组成:编码器、融合和解码器。该编码器将输入图像转换为令牌,并通过使用分层Swin变换来产生多尺度特征。所得到的特征在具有线性投影和Swin变换器块的融合中串联。解码器包含在Swin变换器块内的上采样和合并,以逐步生成变化预测。
Wang等人。[57]介绍了一种称为UV ACD的体系结构,该体系结构将CNN和转换器相结合以进行变化检测。在UV ACD中,高层语义特征通过CNN主干提取,而转换器通过捕捉时态信息交互来生成更好的变化特征。[58]的工作引入了一种混合架构,TransUNetCD,它努力结合变压器和UNet的优点。这里,编码器提取从CNN中提取的特征,并用全局上下文信息来丰富它们。然后对相应的要素取消采样并进行合并利用多尺度特征获取全局-局部特征进行定位。[59]的工作介绍了一种混合多尺度转换器,称为混合TransCD,它通过多个感受域利用不同的标记来捕获细粒度和大对象特征。
表III显示了上述变化检测方法在最常用的基准上的比较:WHU[60]和Levir[61]。WHU数据集由一对高分辨率(0.075m)图像组成。这里,图像的大小是32507×15354。LEVIR数据集包括637对高分辨率(0.5m)图像。这些图像的大小为1024×1024。绩效是根据相对于变更类别的F1分数来衡量的。图8在WHU-CD数据集的示例图像上与SwinSUNet进行了不同方法的定性比较。
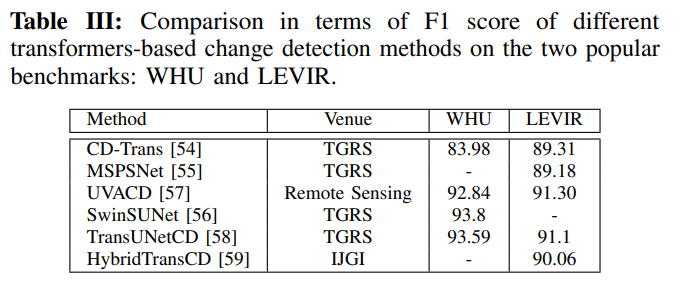
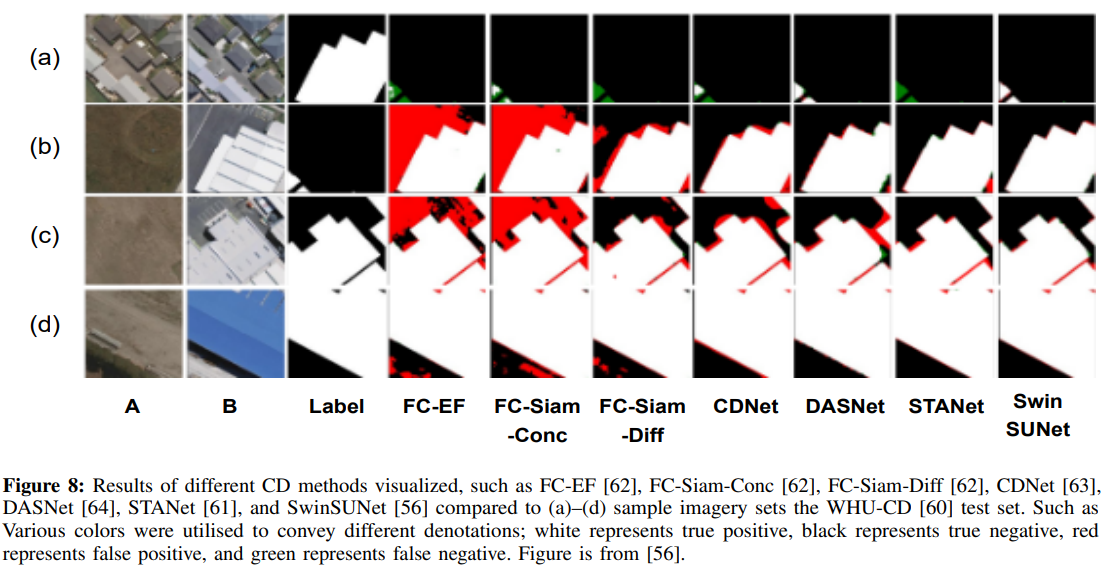
图8:可视化的不同CD方法的结果,例如FC-EF[62]、FC-SIAM-CONC[62]、FC-SIAM-DIFF[62]、CDNet[63]、DASNet[64]、STANet[61]和SwinSUNet[56]与(A)-(D)样本图像集WHU-CD[60]测试集进行比较。诸如五颜六色的颜色被用来表达不同的外延;白色代表真肯定,黑色代表真否定,红色代表假阴性,绿色代表假阴性。该图来自[56]。
D. 图像分割
在遥感中,通过像素级分类自动将图像分割成语义类别是一个具有挑战性的问题,具有广泛的应用前景,包括地质调查、城市资源管理、灾害管理和监测。现有的大多数基于变压器的遥感图像分割方法通常采用混合设计,目的是结合神经网络和变压器的优点。[65]的工作介绍了一个基于轻型变压器的框架Efficient-T,该框架包含一种隐式边缘增强技术。所提出的Efficient-T采用分层Swin变换和MLP头。在[66]中引入了一种称为CCTNet的耦合CNN-Transers框架,旨在将CNN捕获的边缘和纹理等局部细节与通过Translers获得的全局上下文信息相结合,用于遥感图像中的目标分割。此外,还引入了测试时间增加和后处理步骤等不同的模块,以去除推理中的孔洞和小物体,从而恢复出完整的分割图像。在[67]中引入了一种名为STransFuse的CNN-Transformers框架,该框架提取多个尺度上的粗粒度和细粒度特征表示,然后利用自注意机制自适应地组合。[68]的工作提出了一种混合体系结构,其中捕捉远程依赖关系的Swin变压器主干与U型解码器相结合,该U型解码器采用基于深度可分离卷积的Arous空间金字塔池块以及SE块来更好地保留图像中的局部细节。[69]的工作利用预先训练好的Swin Transformer主干,结合U-Net、特征金字塔网络和金字塔场景分析网络三种解码器设计,对航空图像进行语义分割。
我们在Tab IV中展示,在两个最常用的语义切分数据集:Potsdam[70]和Vaihingen[71]上对上述方法进行了定量比较。Potsdam数据集包括38个斑块,每个斑块的分辨率为6000×6000像素,在Potsdam市上空采集,地面采样距离为5厘米。该数据集有六个类别。Vaihingen数据集包括33个样本,其中每个样本的分辨率从1996×1995到3816×2550像素。在这里,地面采样距离为9厘米。此数据集包含与Potsdam相同的类别。性能是根据使用真阳性、假阳性、假阴性和真阴性计算的总体准确率(OA)来衡量的。图9显示了在Potsdam数据集上Trans-CNN和其他方法之间的定性比较。
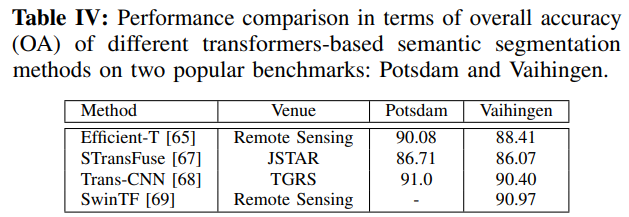
图9:混合Trans-CNN与其他现有分割方法之间的定性比较。这些例子来自Potsdam数据集。


建筑提取 Building Extraction
最近还探索了基于变压器的技术来解决建筑物提取问题,其任务是自动识别遥感图像中的建筑物和非建筑物像素。在[72]中引入了一个双路径转换器框架,该框架努力学习空间和通道方向上的长期依赖关系。[73]的工作提出了一个变压器框架,STEB-UNet,包括基于Swin Transformer的编码助推器,该编码助推器从从不同尺度生成的多级特征中捕获语义信息。编码器助推器进一步集成在融合了局部和大规模语义特征的U形网络设计中。一种基于转换器的体系结构,称为BuildFormer,包括基于窗口的线性关注、卷积MLP以及批归一化在[74]中被引入。[75]的工作探索了建立不同区域的提取模型的泛化问题,并提出了一种转移学习方法来将模型从一个区域微调到另一个不可见区域的子集。
除了语义图像分割和使用转换器进行建筑物提取之外,[37]最近的一项工作探索了实例分割问题,其中的任务是自动将每个像素分类到图像中的一个对象类中,同时还区分多个对象实例。他们的方法旨在结合神经网络和变压器的优点,通过设计一个局部感知Swin变压器主干来增强局部和全局特征信息。
E. 其他
除了上面讨论的问题之外,基于变压器的技术也被用于其他vhr遥感任务,例如图像字幕和超分辨率。
图像字幕 Image Captioning
遥感图像中的图像字幕是一个具有挑战性的问题,其任务是生成对给定图像的语义自然描述。最近很少有作品探索使用变压器进行图像字幕。[103]的工作介绍了一个框架,其中标准变压器通过集成剩余连接、丢弃层和自适应融合特征来适应遥感图像字幕生成。此外,还利用强化学习技术进一步改进了字幕生成过程。文献[107]提出了一种编解码器的体系结构,该结构首先从编码器的不同层次的CNN中提取多尺度特征,然后在解码器中使用多层聚合转换器来有效地利用多尺度特征来生成句子。[108]的工作介绍了基于令牌的掩码转换器的主题框架,其中主题令牌被集成到编码器中,并在解码器中充当用于捕获改进的全局语义关系的先验。
图像超分辨率 Image Super Resolution
遥感图像超分辨率是从低分辨率图像中恢复高分辨率图像的任务。最近的一些著作探索了用于这一任务的变压器。在[111]中引入了一种基于变压器的多级增强结构,它利用了不同阶段的特征。所提出的多级结构可以与传统的超分辨率技术相结合,以融合多分辨率的低维和高维特征。[113]提出了一种融合局部和全局特征信息的CNN-Transform混合结构,以实现超分辨率。[109]的工作探讨了多幅图像的超分辨率问题,其中的任务是将同一场景的多幅低分辨率遥感图像合并成一幅高分辨率的图像。这里,介绍了一种基于变换的方法,包括具有残差块的编码器、融合模块和基于超像素卷积的解码器。
为了总结变形器在VHR图像中的回顾,我们在表5中对文献中的不同技术进行了全面的概述。(具体论文链接见github)
VHR图像中Transformer的应用***


6. 高光谱图像中的Transformer
如前所述,高光谱图像由几个光谱品牌表示,分析高光谱数据在广泛的问题中至关重要。在这里,我们介绍了最近基于变压器的方法不同的高光谱成像(HSI)任务的回顾。
A. 图像分类
在这里,任务是自动分类,并为通过高光谱传感器获取的图像中的每个像素分配一个类别标签。接下来,我们首先回顾最近的工作,这些工作要么是基于纯变压器设计,要么是利用混合CNN-变压器方法。然后,我们讨论了几种最新的基于变换的融合不同模式的高光谱图像分类方法。
基于纯Transformer的方法 Pure Transformers-based Methods
在现有的工作中,[114]的方法引入了来自转换器的双向编码器表示,称为HSIBERT,它致力于捕获全局依赖。所提出的体系结构是灵活的,可以从不同的区域推广,需要执行预训练。在[8]中引入了一个基于变压器的主干,称为SpectralFormer,它可以接受像素或斑块状的输入,并被设计为从附近的高光谱波段捕获光谱局部序列信息。SpectralFormer利用跨层跳跃连接,通过学习跨层的软残差,从浅层到深层循环信息,从而产生分组频谱嵌入。为了避免卷积核的固定几何结构问题,文[115]提出了一种光谱-空间变换网络,该网络包括空间注意模块和光谱关联模块。而当空间注意通过将所有输入特征通道与空间核权重聚合在一起来连接局部区域,通过整合对应的掩蔽特征地图的所有空间位置来实现光谱关联。在[9]中,变压器也在空间和光谱维度进行了探索。在这里,引入了一个框架,包括学习捕获沿光谱维度的交互作用的光谱自我注意和设计用于关注沿空间维度的特征的空间自我注意。然后,来自光谱和空间自我注意的结果特征被组合并输入到分类器。
基于混合CNN-Transformer的方法 Hybrid CNN-Transformers based Methods
最近的几项工作探索了结合CNN和Transformers的优点,以更好地捕捉高光谱图像分类的局部信息和远程相关性。为此,在[116]中引入了一种称为CTN的卷积变换网络,它利用中心位置编码,通过将像素位置与光谱特征相结合来生成空间位置特征,并通过卷积变换来进一步获得局部-全局特征,如图10所示。文献[117]提出了一种高光谱图像变换(HIT)分类方法,该方法将卷积嵌入到变换结构中,以进一步整合局部空间上下文信息。该方法包括两个主要模块,其中一个模块称为光谱自适应三维卷积投影,用于通过光谱自适应三维卷积层从高光谱图像中生成空间光谱局部信息。另一个模块名为Conv-Permuator,它使用纵深卷积来分别沿光谱、高度和宽度维度捕获空间光谱表示。
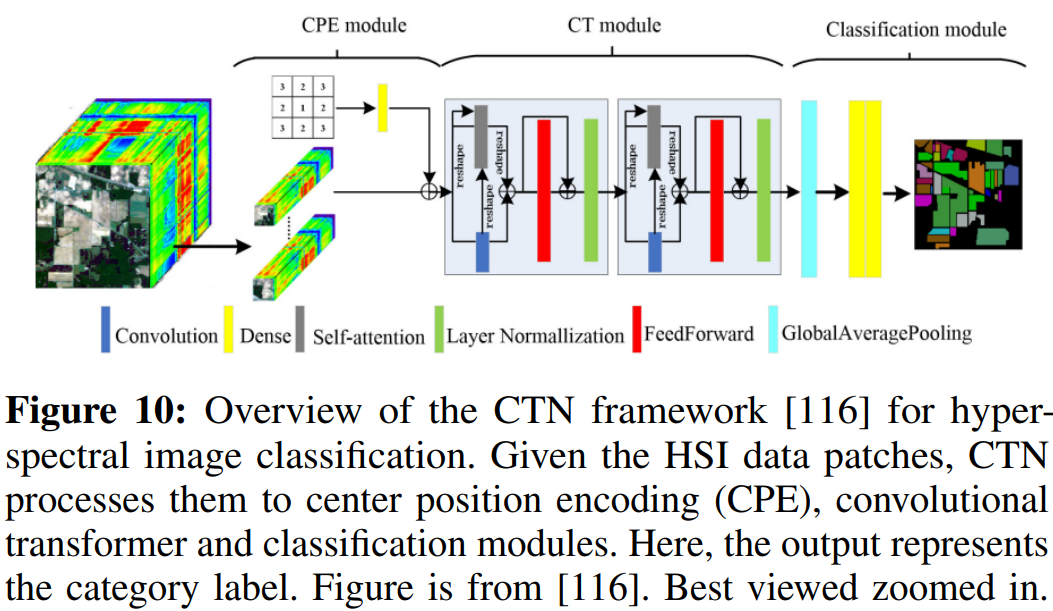
文献[12]介绍了一种多尺度卷积变压器,它能有效地捕捉空间频谱信息,并可与变压器网络集成。此外,定义了自监督预任务,其在编码器中屏蔽中心像素的令牌,而其余令牌被输入到解码器,以便重建对应于中心像素的光谱信息。在[118]中,提出了一种光谱-空间特征标记化转换器,称为SSFTT,用于生成光谱-空间特征和语义特征。SSFTT包括通过使用3D和2D卷积产生低级别光谱和空间特征的特征提取模块一层。此外,在SSFTT中使用了高斯加权特征标记器进行特征变换,然后输入到变换编码器进行特征表示。因此,采用线性层来产生样品标签。赵等人。[116]提出了一种卷积变换网络(CTN),该网络采用中心位置编码将光谱特征与像素位置相结合。该体系结构引入了卷积变换块,有效地集成了高光谱图像斑块的局部和全局特征。Yang等人。[117]介绍了一种高光谱图像转换器(HIT)框架,其中卷积运算被嵌入到转换器设计中,以便也整合本地空间上下文信息。HIT框架由光谱自适应3D卷积投影组成,用于捕获局部空间光谱信息。此外,HIT框架采用了卷积置换模块,该模块使用深度卷积来显式捕获不同维度上的空间光谱信息:高度、宽度和光谱。文献[118]提出了一种光谱-空间特征标记化转换器,称为SSFTT,它由一个用于编码浅光谱-空间特征的光谱-空间特征提取方案和一个产生转换后的特征作为编码器输入的特征变换模块组成。
基于多模融合变压器的方法 Multi-modal Fusion Transformers based Methods
最近很少有基于变换的工作也在探索融合不同的模式,如高光谱、合成孔径雷达、激光雷达用于高光谱图像分类。在[119]中引入了多模式融合变压器,MFT包括一种数据融合方案,用于从多模式数据(例如,激光雷达、合成孔径雷达)以及标准的高光谱补丁令牌中导出变压器中的类别令牌。此外,MFT中的注意机制将来自高光谱和其他模式的标记的信息融合为集成特征的新标记。[120]的工作介绍了一种方法,其中利用光谱序列变换来沿光谱维度从高光谱图像中提取特征,并利用空间分层变换来以分层方式从高光谱和激光雷达数据中生成空间特征。
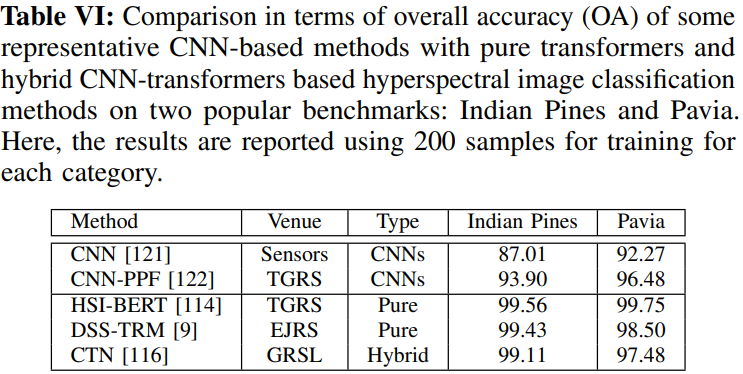
表VI显示了两种流行的高光谱图像分类基准:Indian Pines和Pavia,比较了几种典型的基于CNN的方法与基于纯变换和混合CNN变换的方法。Indian Pines的数据集是通过机载可见光/红外成像光谱仪(A VIRIS)获取的美国印第安纳州西北部的传感器。这里,图像在空间维度上包括145×145个像素,地面采样距离(GSD)为20米,有220个光谱波段,覆盖400-2500 nm的波长范围。去掉噪声频段后,保留了200个频谱品牌。原始数据集包含16个类,其中几个方法丢弃了较小的类。其余类别的训练样本数目为每班200个。Pavia数据集包括通过反射光学系统成像光谱仪(ROSIS)传感器在意大利帕维亚上空获取的图像。这里,图像在空间维度上由610×340个像素组成,GSD为1.3米,103个光谱波段覆盖从430到860 nm。该数据集包含9个类别,每个类别的训练样本数量为200个。通常用三个指标来定量评价方法的性能:总体精度、平均精度和卡帕系数。总体准确率(OA)表示正确分类测试样本的比例,而平均准确率(AA)反映每个类别的平均识别准确率。卡帕系数是指由模型生成的分类图与可用地面实况之间的一致性。图11给出了在PAVIA数据集上HSIBert[114]和其他现有的基于CNN的方法之间的定性比较。
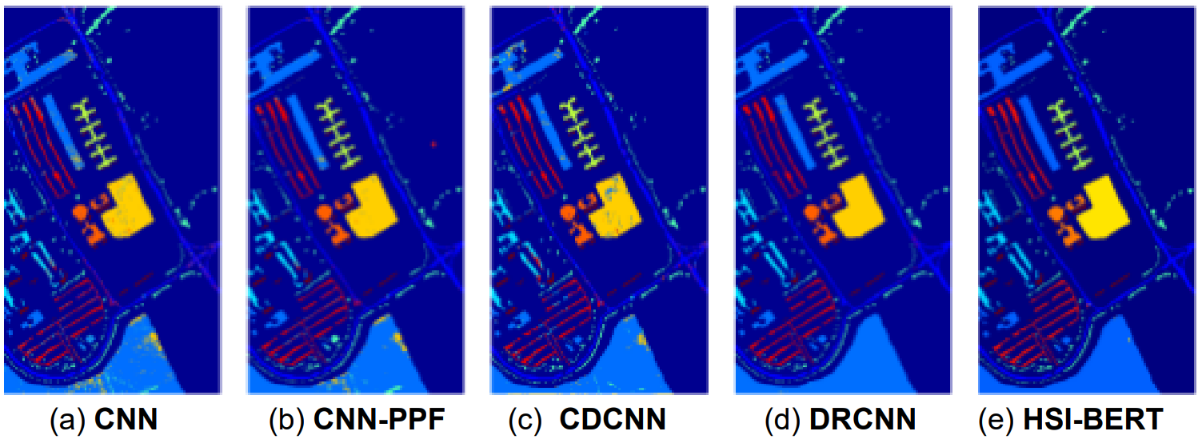
B. 高光谱全息锐化
在高光谱全色锐化问题中,任务是利用配准的全色图像的空间信息对低分辨率的高光谱图像进行空间增强,同时保持低分辨率图像的光谱信息。全息锐化在遥感中的各种任务中扮演着重要的角色,包括分类和变化检测。此前,基于CNN的方法在这项任务中显示出了令人振奋的结果。最近,通过利用有用的全局上下文信息,基于转换器的方法已经对这个问题取得了良好的效果。由[139]提出的多尺度空间光谱相互作用变换MSIT包括一个卷积变换编码器,用于从低分辨率和全色图像中提取多尺度局部和全局特征。[137]的工作引入了一种体系结构,其中全局特征使用变压器构建,局部特征使用浅层CNN计算。同时学习以金字塔方式提取的这些多尺度特征。该方法进一步引入了同时考虑空间损失和频谱损失的损失公式,用于使用真实数据进行训练。梁等人。[136]提出了一种PMACNet框架,在该框架中,低分辨率图像的感兴趣区域和回归到高分辨率图像的残差都在并行的CNN结构中学习。然后,基于学习到的感兴趣区域,利用像素方式的注意模块来调整残差。
文献[141]提出了一种基于变换的回归网络,利用Swin变换进行空间和光谱信息的特征提取模型。[142]的工作引入了一种基于转换器的方法,其中多光谱和全色特征被表述为关键字和查询,以实现跨模式的特征的联合学习。此外,本工作还使用了一个可逆的神经模块来进行特征的有效融合,以生成全息图像。Bandara等人。[133]提出了一种包括全色和高光谱图像独立特征提取、软注意机制和光谱-空间融合模块的框架。通过学习不同特征的跨特征空间依赖关系来提高全息图像的质量。
为了总结高光谱成像中变压器的回顾,我们在表7中对现有文献中的技术进行了全面的概述。
高光谱图像中Transformer的应用***

7. 合成孔径雷达图像中的Transformer
如前所述,合成孔径雷达图像是由电磁波信号构成的,通过传感器平台传输到地球表面。由于不受昼夜雾等环境条件的影响,合成孔径雷达具有独特的特性。在这里,我们回顾了最近的基于变压器的方法,用于SAR成像任务。
A.合成孔径雷达图像解译
分类 Classfication
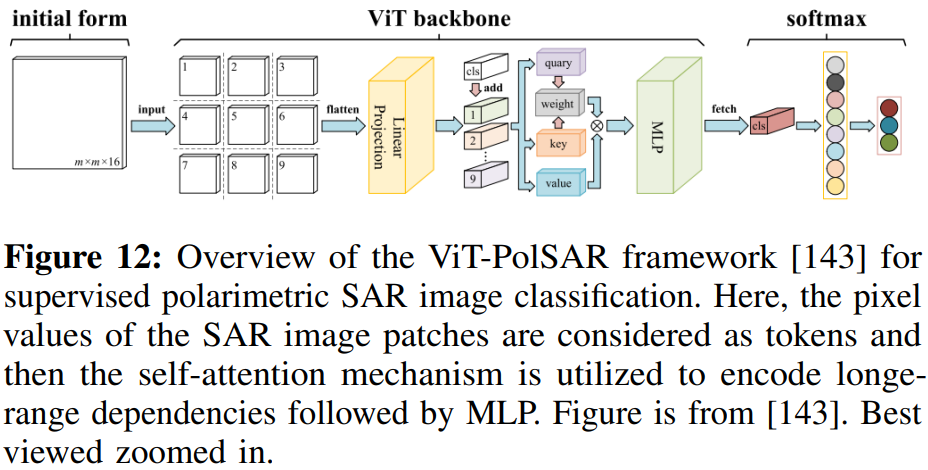
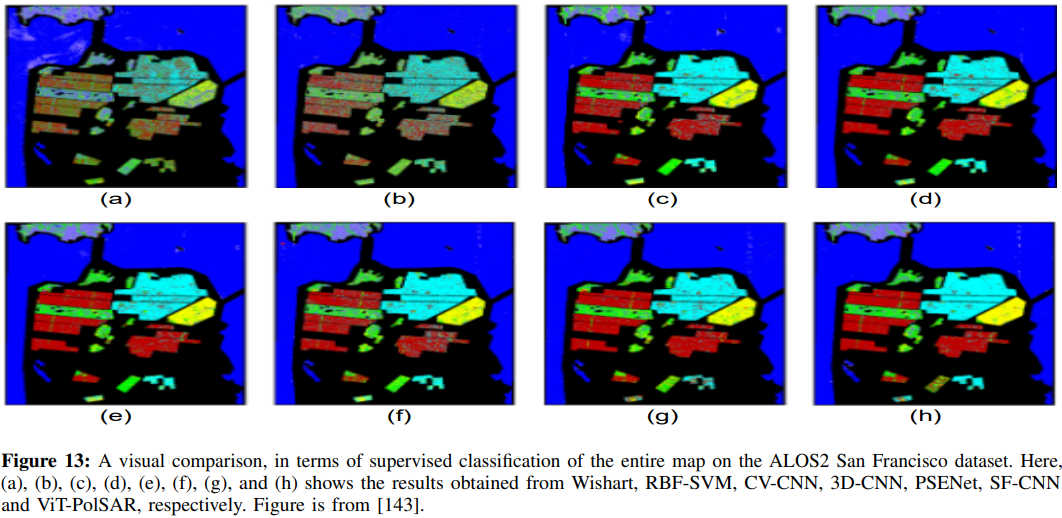
准确地对SAR图像中的目标类别进行分类是一个具有挑战性的问题,具有许多现实世界的应用。最近,人们探索了用于SAR图像的自动解译和目标识别的转换器。[143]的工作探索了用于极化SAR(PolSAR)图像分类的视觉转换器。在该框架中,将图像块的像素值作为特征,利用自注意机制获取长距离依赖关系,然后使用多层感知器(MLP)和可学习类特征来集成特征。在该框架内使用了对比学习技术以减少冗余并执行分类任务。图12显示了该框架的概述,图13给出了监督分类方面的定性比较。
除了前面提到的纯基于变压器的方法之外,文献中也存在利用CNN和变压器的混合方法。[144]的工作提出了一种全局-局部网络结构(GLNS)框架,该框架结合了CNN和转换器的优点用于SAR图像分类。提出的GLNS采用了轻量级的CNN和一个高效的视觉转换器来捕捉局部和全局特征,这些特征随后被融合来执行分类任务。除了标准的全监督学习,还在有限的监督机制中探索了转换器,例如,小样本SAR图像分类。蔡等人。[145]介绍了一种基于空间变换网络对基于CNN的地物进行空间对齐的方法,称为ST-PN。
分割和检测 Segmentation and Detection
SAR图像中的检测和分割对于农作物识别、目标检测和地形测绘等不同的应用是至关重要的。在SAR图像中,由于斑点的出现,分割可能具有挑战性,斑点是一种乘性噪声,随着后向散射雷达幅度的增加而增加。在最近的基于变压器的方法中,[146]的工作引入了一个名为GCBANet的框架,用于合成孔径雷达舰船实例分割。在GCBANet框架内,使用全局上下文块来编码空间整体远程依赖关系。此外,还引入了一种边界感知盒子预测技术来预测船舶边界。夏等人。[147]介绍了一种名为CRTransSar的方法,该方法结合了CNN和转换器的优点,可以捕获用于SAR目标检测的局部和全局信息。建议的CRTransSar通过构建具有注意力和卷积块的主干来工作。文献[148]提出了一种地理空间变换框架,该框架包括图像分解、多尺度地理空间上下文关注和重构步骤,用于在SAR图像中检测飞机。文献[149]提出了一种用于SAR图像中飞机检测的特征关系增强框架。该框架采用融合金字塔结构,将不同层次和尺度的特征结合在一起。
此外,还采用了上下文注意力增强技术来提高复杂背景下的定位精度。除了舰船和飞机检测,[150]最近的工作引入了一种基于变压器的框架,用于在SAR图像中对油罐目标进行3D检测。在该框架中,将入射角作为先验标记输入到变压器,之后是利用散射中心来改进预测的特征描述运算符。
B. 其他
除了对合成孔径雷达图像的分类、检测和分割外,很少有工作是针对图像去噪等其他合成孔径雷达成像问题而进行的。
合成孔径雷达图像去斑化 SAR Image Despeckling
由于一种称为斑点的乘性噪声引起的图像退化,上述对合成孔径雷达成像的解释是具有挑战性的。近几年来,人们已经探索出了用于SAR图像去斑的变压器。[161]的工作介绍了一种基于变换的框架,该框架包括一个编码器,它学习不同SAR图像区域之间的全局依赖关系。利用合成斑点数据利用复合损耗函数以端到端的方式训练基于变压器的网络。
合成孔径雷达图像中的变化检测 Change Detection in SAR Images
合成孔径雷达图像会受到成像噪声的影响,这给检测高分辨率(HR)合成孔径雷达数据中的变化带来了挑战。最近,文献[163]提出了一种自监督的对比表示学习技术,其中分层表示是使用卷积增强的变换来构造的,以区分来自HRSAR图像的变化。当在本地窗口内执行自我注意计算时,引入了基于卷积的模块以实现跨窗口的交互。
合成孔径雷达图像配准 SAR Image Registration
变化检测等几个应用涉及对可能在不同成像条件下获取的多个合成孔径雷达图像进行联合分析和处理。因此,需要精确的SAR图像配准,其中对参考图像和感测图像进行配准。[165]最近的工作探索了用于大尺寸SAR密集匹配配准的变压器。在弱纹理条件下,采用混合细胞神经网络-变换进行图像配准。首先,通过下采样的原始SAR图像进行粗配准。然后,从先前的粗配准步骤中选择配准点的聚类中心。然后,使用CNN转换器模块执行图像对的配准。最后,对得到的点对子集进行积分,通过RANSAC实现最终的全局变换。
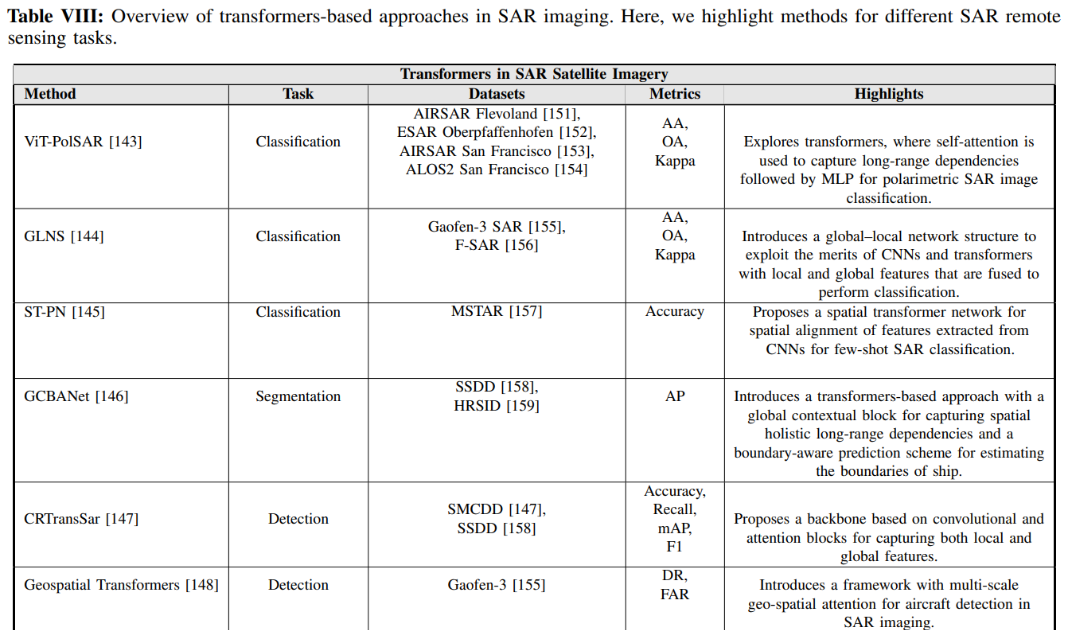
综上所述,我们对现有的合成孔径雷达图像Transformer技术在表8进行了全面的概述。
合成孔径雷达图像中Transformer的应用***
8 讨论和结论
在这项工作中,我们对遥感成像中的变压器进行了广泛的概述:超高分辨率(VHR),高光谱和合成孔径雷达(SAR)。在这些不同的遥感图像中,我们进一步讨论了基于转换器的各种任务的方法,如分类、检测和分割。我们的调查涵盖了60多部基于变压器的遥感研究文献。我们观察到转换器在不同的遥感任务中获得良好的性能,这可能是由于它们捕获远程依赖的能力以及它们的表示灵活性。此外,几种标准变压器架构和主干的公开可用使探索它们在遥感成像问题中的适用性变得更容易。
开放的研究方向:如前所述,大多数现有的基于变压器的识别方法采用针对ImageNet数据集对主干进行了预培训。一个例外是在大规模遥感数据集上探索预培训视觉转换器的工作[7]。然而,在这两种情况下,预培训都是在监督下进行的。一个开放的方向是通过考虑大量的未标记的遥感成像数据,以自我监督的方式探索大规模的预训练。
我们的调查还显示,大多数现有的方法通常使用混合体系结构,其目标是结合卷积和自我关注的优点。然而,众所周知,变压器计算全局自我注意的计算成本较高。最近的几项工作探索了不同的改进变压器的设计包括减少计算开销[167]、高效混合CNN-变压器主干[168]以及用于图像和视频分类的统一架构[169]。此外,由于变压器使用了更多的训练数据,因此在遥感成像中需要构建更大规模的数据集。对于本工作中讨论的大多数问题,特别是在目标检测的情况下,通常使用重骨干来实现更好的检测精度。然而,这大大减慢了航空探测器的速度。一个有趣的开放方向是设计基于轻型变压器的主干来对遥感图像中的探测定向目标进行分类。另一个开放的研究方向是探索基于变换的模型对诸如SAR和UA V等异质图像源的适应性(例如,变化检测)。
在这次调查中,我们还观察到了几种现有的以即插即用方式利用变压器进行遥感的方法。这导致需要设计有效的特定于领域的体系结构组件和损耗公式来进一步提高性能。此外,对经过遥感基准预训练的视觉转换器模型的对抗性特征空间及其可转移性的研究也很有趣。
引用文献
共169篇,见