目录
发展历程
论文阅读
小结
发展历程
在阅读Faster RCNN论文之前有必要先了解一下RCNN,SPPNet和Fast RCNN,这样才能了解到faster RCNN的改进点。
RCNN
RCNN是Regions with CNN features,是将CNN应用到目标检测问题上的一个里程碑。借助CNN网络良好的特征提取和分类性能,通过RegionProposal方法实现目标检测问题。
Rich feature hierarchies for accurate object detection and semantic segmentation
算法主要有四个步骤:
- 候选区域选择(Region proposal),一般通过selective search来选择大概2k个候选区。
- CNN特征提取,将候选区送入CNN网络提取特征。
- 对提取出来的特征进行SVM分类。
- 边界回归(bounding-box regression)得到精确的目标区域,对分类出来的前景目标进行定位和合并。

RCNN存在几个问题:
- 候选区域选择是独立于CNN网络的,每张图片需要耗费大量的时间在候选区选取上,每张图片大概需要2s。另外提取出来的信息也需要单独存放在磁盘上,占用了大量的磁盘资源
- 提取出来的候选区由于尺寸各不相同,所以要先将它们压缩成统一尺寸再送入CNN网络,这样会丢失候选框的尺寸信息
- 提取出来大约2k的候选框分别送入CNN提取特征,而提取的候选框有很多重叠,所以导致了大量的重复计算,是计算资源的浪费。
SPP Net
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
RCNN中每一个proposal region都需要送入CNN进行特征提取,这样非常耗时。所以SPP Net提出整体提取特征,只在分类前做一次region截取。
具体改进如下:
- 直接用整张图片送入CNN进行特征提取,这样有两点好出。a.可以取消候选区进行尺寸压缩后送入CNN提取特征,这样防止了候选框在压缩过程中的信息丢失,是针对RCNN不足中第二点的改进。b.不需要提取出来的2k候选框分别进行CNN特征提取,这样节省了大量的计算量,是针对RCNN不足中第三点的改进。
- 将CNN网络的最后一个pool层替换成SPP(Spatial Pyramid Pooling空间金字塔池化层),可以通过stride区域映射过来的不同尺寸的proposal,通过SPP转化成统一的M*N尺寸。

SPP层就是为了将不同尺寸的proposal对应的feature map转化成统一尺寸的feature map,如上图以其中一个proposal对应的feature map为例,假设这个feature map的尺寸是M*N*256,将这个feature map的每一个channel以4*4,2*2和1*1来划分格子,每个格子里面做max pooling,这样就得到了256个21(4*4+2*2+1)数字的数组,然后合并得到尺寸为21*256的feature map。所有proposal对应的feature map都这样操作,就会得到统一的尺寸,然后进行FC连接。
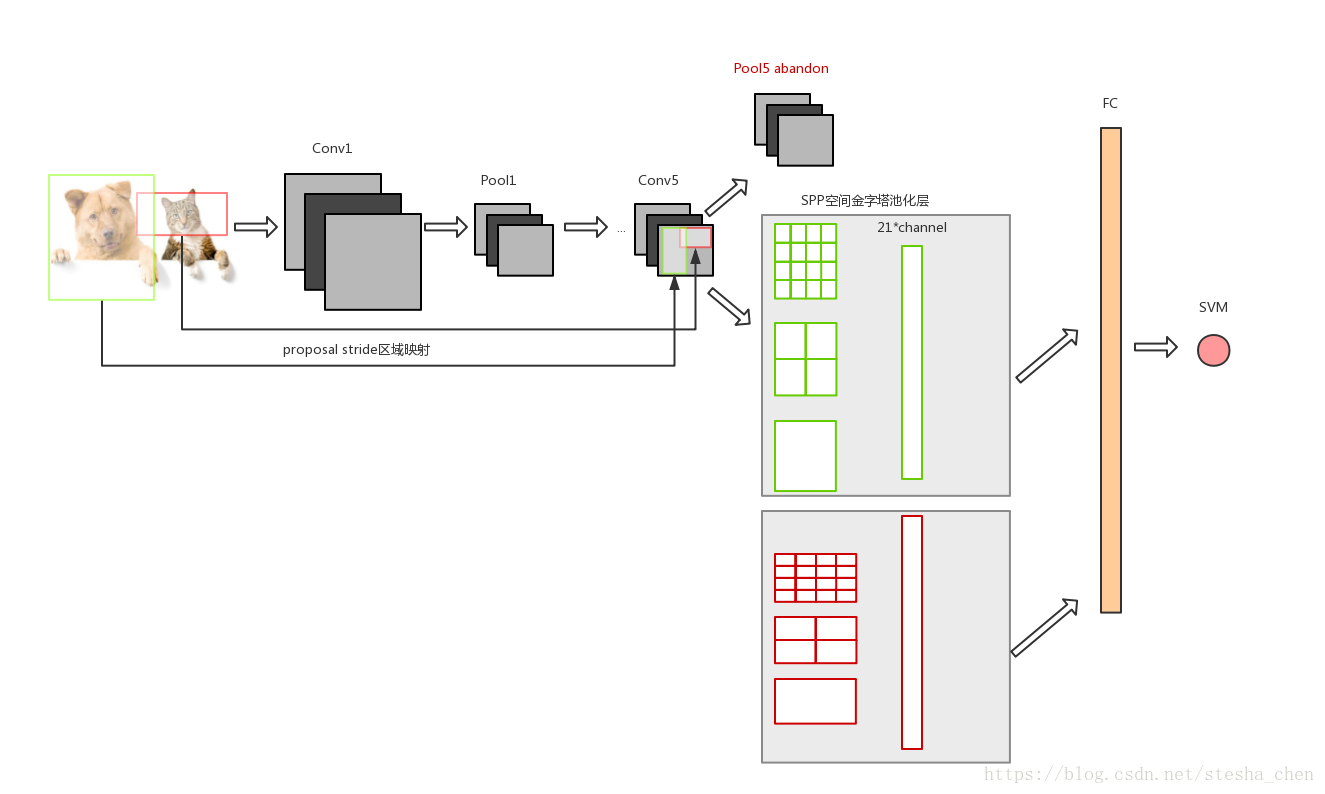
SPP Net有效解决了proposal重复计算的问题,使速度提升了很多,但是仍然有可以改进的地方:
- 和RCNN一样,region的提取,CNN提取特征,SVM分类和bounding box regression这四个步骤还是分开进行的
- proposal region的提取仍然非常耗时
Fast RCNN
改进以下两点:
- 将之前使用的SVM分类算法改成了softmax算法,并且将softmax分类和bbox regression合并成了一个多任务的模型,使这两个任务共享卷积层,共同进步。
- 针对SPPNet层改进成了RoI Pooling层,可以看成是SPPNet的简化版本。不像SPPNet会分成三种尺寸,RoI Pooling就将经过卷积计算后的region分割成H*W,然后在每个区域求max pooling,这样所有的region都成为了H*W尺寸。

Fast RCNN将softmax分类和bbox regression合并成了一个网络,使网络大大简化了,极大的加快了训练和预测的速度,为Faster RCNN的提出打下了重要的基础。
论文阅读
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
1.简介
现在物体定位的发展是由region proposal选取方法和基于region的卷积运算来推动的。本来在RCNN中基于region的卷积运算非常耗时,但是因为region共享卷积运算的提出大大减少了计算量。在最近的Fast RCNN中如果忽略region proposal选取的时间,几乎可以达到了实时检测的效果。所以现在region proposal的选取就是瓶颈。
Selective Search是最流行的一种region proposal选取的方法,在CPU上大概需要耗时2秒。EdgeBoxes选取proposal的方法最好的平衡了速度和质量,大概需要耗时0.2秒。无论如何,proposal选取方法在定位网络上耗费了不少时间。
有一点需要注意,基于region的CNN计算现在都是在GPU上进行的,这也是它的运算加速的原因,而proposal的选取都是在CPU上,这是不公平的。所以现在有一个方法就是重新实现proposal选取算法,利用GPU加速。这对工程师而言可能是一种有效的方法,但是也会失去和region的CNN算法共享计算的机会。
在本文中,我们会提出一种算法上的改进,用深度卷积神经网络来计算proposal,这是一种优雅并且有效的解决方法。会让proposal的选取在物体定位网络中几乎不耗时。这就是Region Proposal Networks简称RPNs,可以共享卷积运算,所以消耗是非常小的,一张图片大概10毫秒。
我们的观察发现,卷积运算的feature map不仅可以做region检测,还可以生成region proposal。在卷积运算出来的features后面我们增加了新的卷积层构建了一个RPN网络可以和bbox regression和物体打分并列。RPN是全卷积网络可以训练来生成proposal。
引入了anchor box作为各种尺度和纵横比的参照物,这避免了穷举各种尺度和宽高比的图像或过滤器。这个模型在单一尺度图像的训练和测试时表现优异,因而运行速度大为受益。
2.Faster RCNN
我们的物体定位算法叫做Faster RCNN,由两部分组成,一部分是生成region的卷积网络,另一部分是对region进行检测的检测器,整个系统都是一个单一统一的网络。、
2.1Region Proposal Networks
RPN网络的输入是任意尺寸的图片,输入是矩形的proposal框,后续会对这个框中的物体有一个打分。RPN是全卷积网络,我们最终目标是希望RPN能够和Fast RCNN中提到的检测网络共享卷积层。我们观察了Zeiler和Fergus模型有5个可以共享的卷基层,Simonyan和Zisserman模型有13个可以共享的卷积层。
为了产生proposal区域,我们用的窗口在卷积运算最后生成的feature map上滑动,每个滑动窗口都映射到一个更加低维度的特征,这个特征后面再连接两个并列的全连接层,一个是框回归层,一个是打分层。在这篇文章中我们使用的是
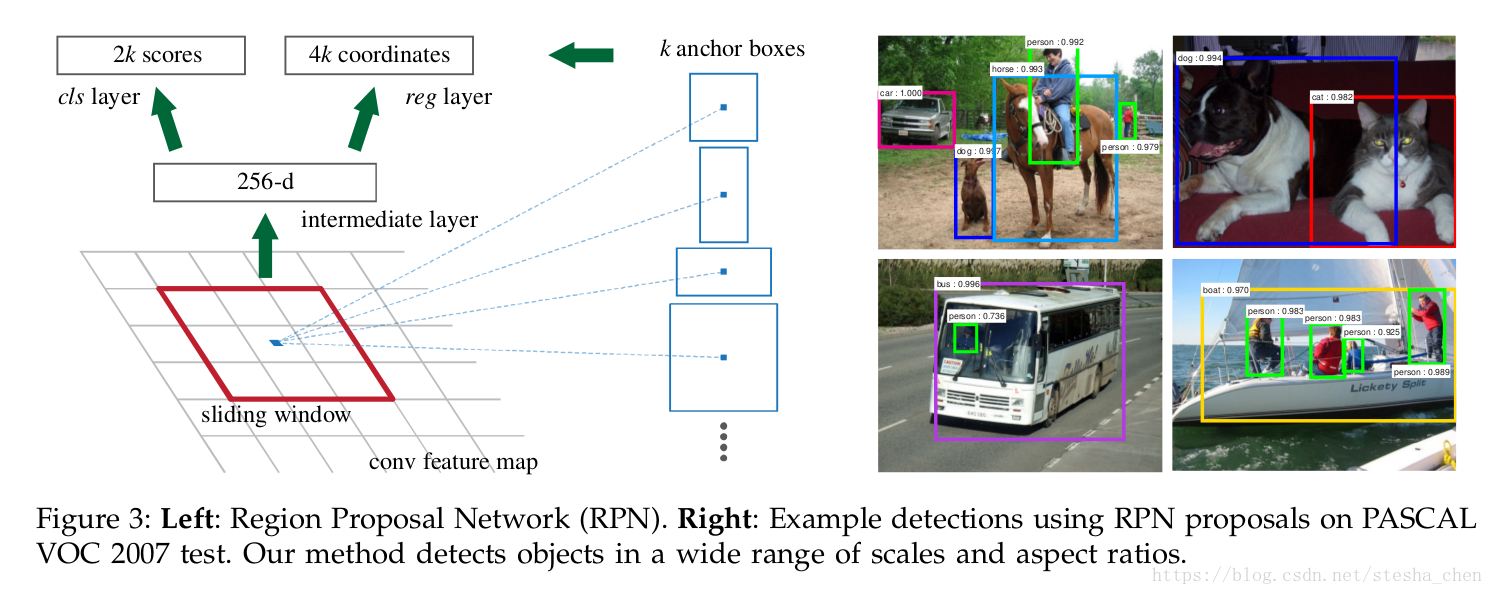
如上图左边是RPN的示意图,用3x3做滑动窗口其实在代码上可以表示为一个kernel为3x3的卷积运算。
2.1.1Anchors
对于滑动的窗口,我们也预测出一些备选框,每个滑动窗口最多k个备选框,因此reg层输出是4k个值对应k个proposal,而cls层输出是2k个值,表示这k个框内是物体和不是物体的概率。这k个框是一个参考框,我们叫做anchors。每个anchor都是以滑动窗口的中心为中心,然后按照一定的尺寸和比例而生成。一般情况我们会有三个尺寸和三个比例,因此每个位置一共是9个anchors。如果最后一层的feature map是那么anchor的个数就是
个。
备注:在代码实现中sliding window是用3x3的卷积运算实现,padding是same,所以slide window的中心点其实就对应到256-d的每个像素点的位置,所以代码中的anchor位置是基于256-d这一层的每个像素点作为中心点来计算的。理解了就会发现其实跟论文示意图中表达的是一个意思。
平移不变anchors
我们方法有一个重要特性就是平移不变性。无论是anchor还是相对anchor来计算proposal的方法都有这个特性。如果在一张图片上移动一个物体,proposal也应该移动,并且同样的方法应该能在新的位置预测出新的proposal。作为对比,MultiBox方法使用k-means产生了800个anchors,却不能保持平移不变性。因此MultiBox不能保证在物体平移后产生同样的推荐。同时平移不变性可以减少模型的大小。
多尺度anchor作为回归参照物
anchor是解决多尺度问题的一种新颖形式。
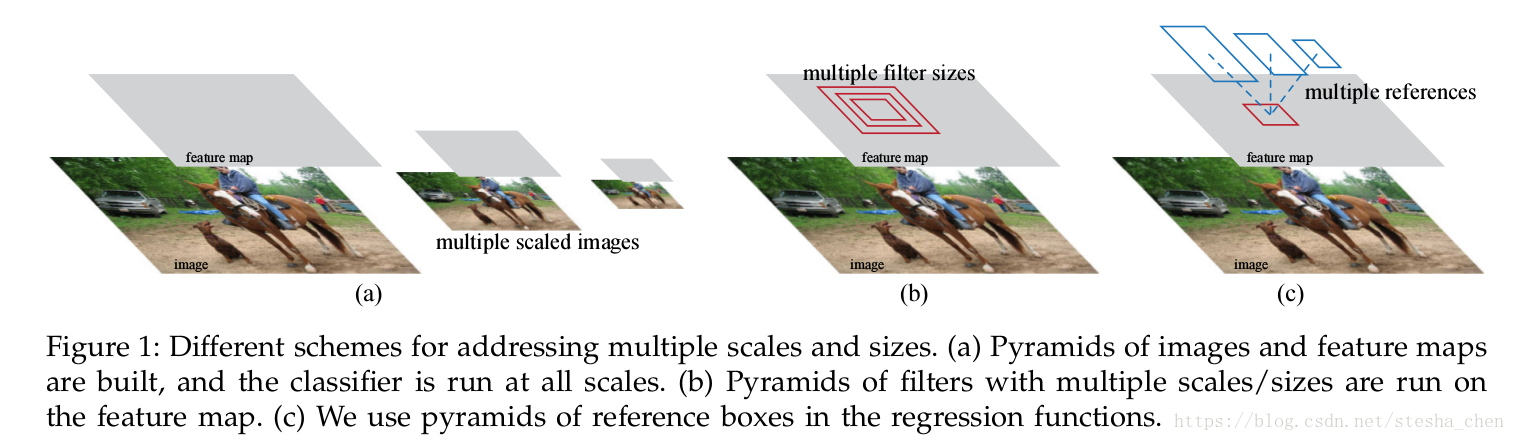
看上图,a是图像和特征金字塔的形式,图像会被缩放到各种尺度,特征图在每个尺度进行计算,这样是有效的,但是耗时。b是过滤器的金字塔形式,就是会在特征图上多个尺度进行滑窗,不同缩放比例的模型都分开训练。c是参考框金字塔的形式,我们对anchor进行多种尺度的设计,这样可以在单一尺度的图像上计算卷积特征,共享特征没有额外计算开销。
备注:因为我们并不知道需要定位的物体框是什么形状,所以以前要么就是对原始图像进行各种尺寸压缩,要么就是多种尺寸进行滑窗,这样的计算量都是非常大。现在设计了多尺度的anchor,我们只需要用卷积运算计算一张图片的feature map,然后对feature map进行多尺度anchors的预测,接着用reg来修正框就可以了,非常方便。
2.1.2 Loss函数
为了训练RPNs网络,我们对每个anchor设置了一个二分的label,是物体还是不是物体。
我们对以下两种anchor分配正标签:
- 和真实的box框有最高的IoU
- 和任意真实box框有高于0.7的IoU
这样分配下来一个真实框可能会有很多个标记为正样本的anchors,一般情况下第二个条件能够挑选出很多个正样本,但是我们还是设置了第一个条件,以防最高分的IoU都达不到0.7。我们对所有非正标签的anchor中选出跟所有真实框的IoU都小于0.3的anchor设置为负样本。既不是正样本也不是负样本的就不参与训练了。
有了这些定义,我们要最小化目标函数:
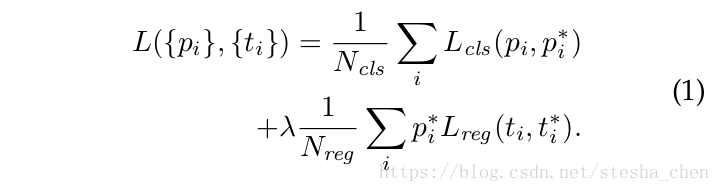
表示minibatch中的第i个anchor,
表示这个anchor里面是一个物体的概率,
表示真是概率,如果是物体就是1,不是就为0,
是预测bounding box的4个坐标参数,
是真实的box相对一个正样本anchor的坐标参数。
,R是smoothL1
表示只有对正样本(
)才计算reg loss,负样本不计算。
这两个loss分别除以了和
,并且增加了一个用来平衡的参数
。在公式1中
是minibatch的尺寸,我们实验时是256,
是anchor的个数,一般是2400左右。默认
设置为10,这样两个式子就平衡了。但是我们的实验发现结果对
的值并不敏感,不过当
为10的时候精确度最高。并且归一化的操作(loss除以N的计算)也不是必须的,可以简化。

对于bounding box的回归,那4个坐标参数可以如下计算:
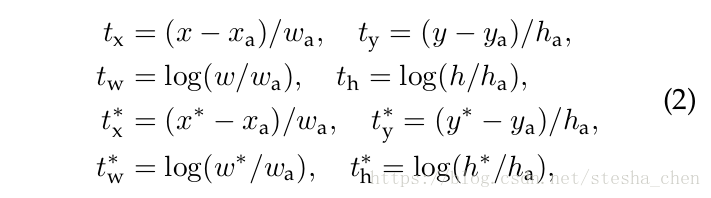
分别表示矩形框的中心坐标和长宽,
表示预测框的信息,
表示anchor的信息,
表示真实框的信息。其他参数的表示都是同样规律。这个公式表示bounding box从一个anchor框回归到一个最近的真实框。其实就是预测框相对anchor的偏移和缩放,和真实框相对anchor的偏移和缩放。
2.1.3训练RPNs
RPNs可以通过反向传播和随机梯度下降进行完整的训练。一个minibatch中的一张图片可能包含很多个正样本anchor和负样本anchor。我们可以对所有的正负样本anchor来优化loss,但是可能会导致负样本处于主导地位(因为负样本数可能更多),所以对一张图片我们随机选择256个anchor去计算loss,其中正样本和负样本比例是1比1。如果正样本不足128个,就用负样本补齐。
对所有新增的网络层,参数初始化为均值为0,标准方差为0.01的高斯分布。其他层的参数都用ImageNet分类网络训练出来的参数进行初始化。前60,000个minibatch,learning rate为0.001,后20,000个minibatch,learning rate为0.0001.momentum为0.9,weight decay为0.0005.
2.2 RPN和Fast RCNN分享feature
到现在为止,我们已经介绍了如何训练网络生成proposal框,而没有介绍物体检测的CNN网络如何使用这些proposal框。对于检测网络我们还是使用Fast RCNN,下面就来介绍一下由Fast RCNN和RPN分享卷积层组成的网络结构。
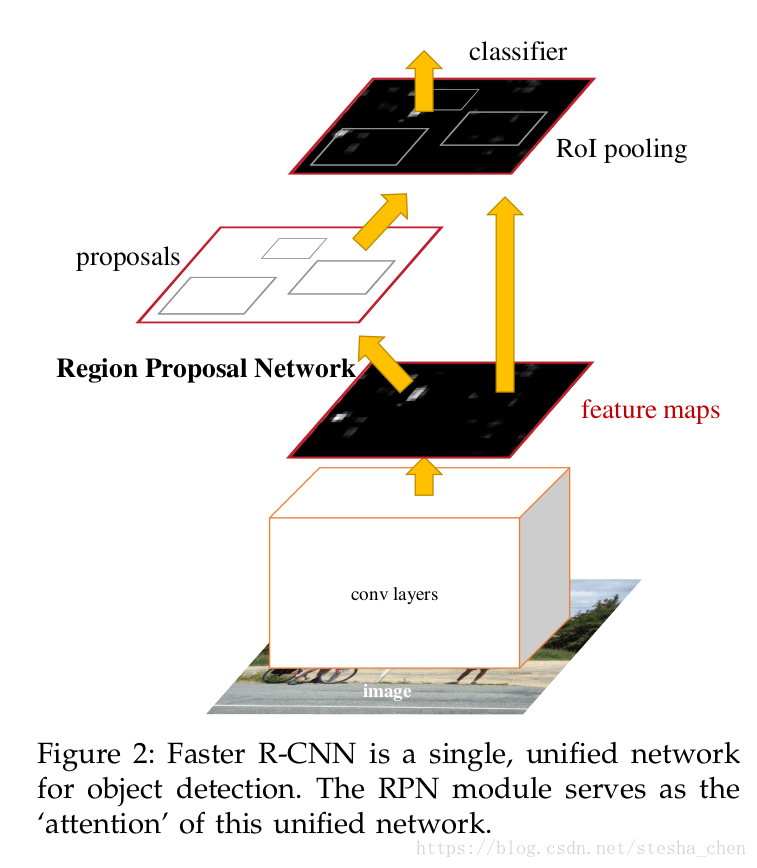
RPN和Fast RCNN都是单独训练的,在训练的过程中他们会以不同的方式修改卷积层的参数,因此我们需要开发一种技术能够让两个网络分享卷积层,而不是学习两个单独的网络。
- 交替训练。在这个方法里面,我们先训练RPN,然后用proposal训练Fast RCNN,然后网络会被Fast RCNN做一些参数值的调整,然后再用这些值初始化RPN,在这篇论文中的所有试验都是用的这种方式。
- 近似联合训练。这种方法是在训练的时候将RPN和Fast RCNN合并成一个网络,如上图Feature2展示的。在每一次SGD迭代中,前向传播生成了proposal,在训练Fast RCNN检测器的时候我们就把这个proposal当前是预先计算出来的。反向传播跟普通的一样,这个时候共享层的反向传播信号是从RPN和Fast RCNN的loss合并来的。这种方法很容易实现,但是这种方式会忽略w,r,t这些衍生参数,所以我们还是要对proposal box坐标参数做训练,所以这种方式只能叫做近似联合训练。实验下来,这种方法能够产生类似的结果,但是跟交替训练比可以减少25%-50%的时间。
- 非近似联合训练。就是将bounding box的坐标参数也一起求梯度,但是需要一个RoI Warping,这个不在本文讨论范围之内。
交替训练的4步
- 训练RPN,这个时候网络已经用ImageNet预先训练好的参数初始化过了。
- 通过RPN生成的proposal,训练Fast RCNN检测网络,这个检测网络也是用ImageNet预先训练好的参数初始化过了。这个时候RPN和Fast RCNN还没有共享网络。
- 用检测网络去初始化RPN网络,然后固定那些共享层的参数,只训练RPN新增的网络层。
- 保证分享的卷积层参数固定,fine-tune Fast RCNN独有的网络层。
这样两个网络就共用了同样的卷积层,生成了一个统一的网络。一个类似的交替训练是在很多次迭代里面都进行交替,但是我们发现只有微不足道的改进。
备注:Faster RCNN的网络训练也是一个比较复杂的过程,需要了解清楚训练方式。
2.3实现细节
anchor一共有三种面积,128*128,256*256,512*512,然后每个面积有三种长宽比1:1,1:2,2:1.我们会忽略超过边界的anchor,比如一张1000x600的图片,卷积层4次尺寸缩减后得到feature map的size近似(方便计算)60x40,那么anchor的个数是60*40*9,近似20000个。如果超过边界的忽略掉大概还会有6000个anchor,如果anchor全部保留,数量就太大了,而且很多都没有意义。在test的时候我们还是有可能会生成超过边界的box,这种情况需要裁剪到边界内。
一些RPN的proposal可能会和其他的高度重合,为了避免重复,我们需要根据他们的分数使用NMS(非极大值抑制),并且IoU阀值为0.7来进行筛选,这样我们会去掉大约2000个框。NMS不会影响检测的精度,但是可以减少proposal。在NMS之后,根据排行来选择检测的框。
备注:NMS方法,对于有重叠的框,如果某个框跟最高分的框的IoU大于阀值0.7就删除,小于则保留。没有重叠的框全部保留。这个方法的意思是重叠度很高的框就可以删掉了,重叠度不高的框可能会对打分最高的框有区域上的补充,所以保留。
3.实验结果
略
小结:
Faster RCNN的主要共享就是提出了RPN网络,大大加快了proposal框的生成速度,让定位网络进入了实时定位的时代。这个网络的代码也会相对复杂一些,所以在下一篇介绍代码实现。
以上是本文所有内容,感谢阅读,欢迎讨论。