什么是字体反爬
网页开发者自己创造一种字体,因为在字体中每个汉字都有其代号,那么以后再网页中不会直接显示这个文字的效果。而是显示其代号,因此即使获取了网页的文本内容。也只是获取到文字的代号,而不是文字本身。
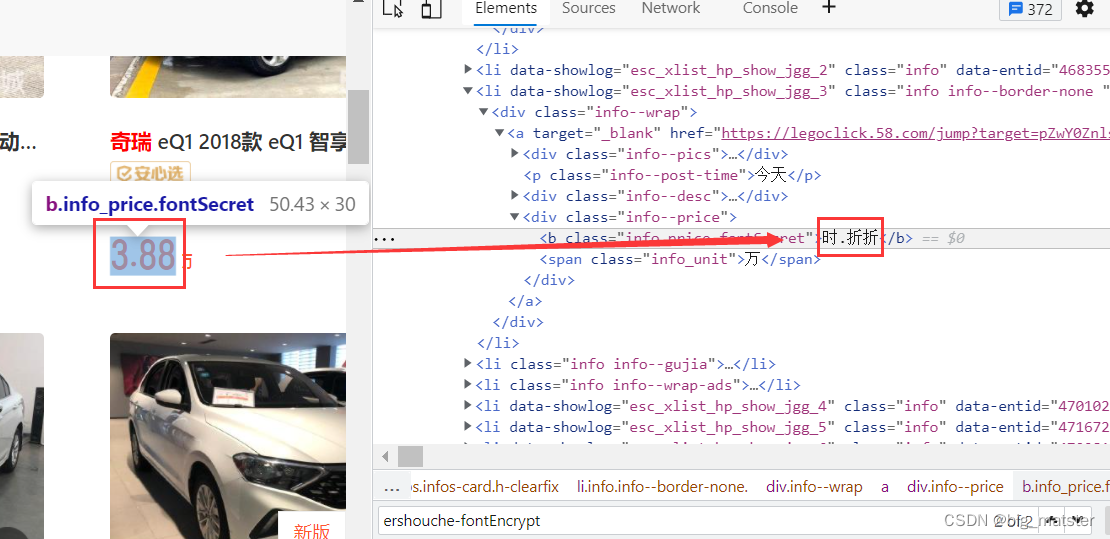
简单来说,字体反爬指的是浏览器页面上的字符和调试窗口或者源码中的内容,显示的不一样,这就是字体反爬虫。
编码原理
- bit: 由0和1构成的二进制。
- Byte(z字节): 1字节由八个连续二进制位,或2个16进制数表示。
- 字符:计算机中使用的数字、字母、符号。
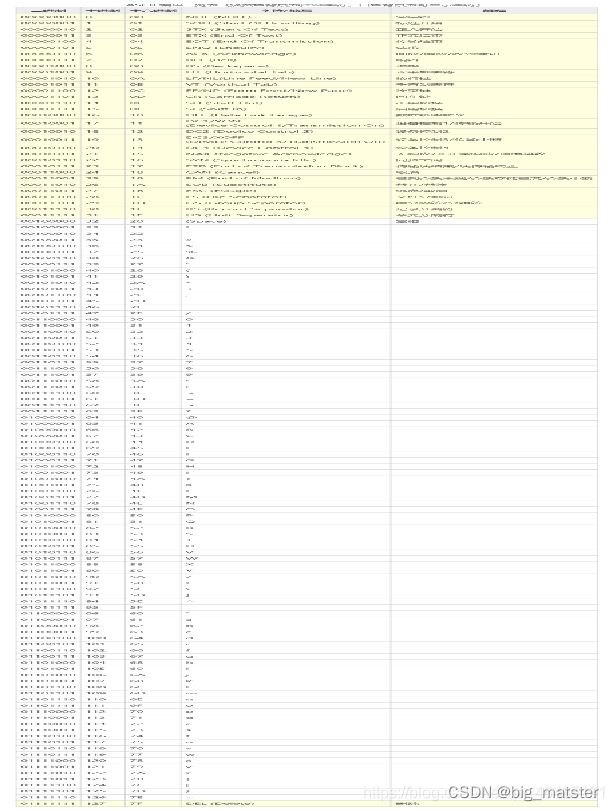
ASCII编码对照表
ASCII码
ASCII 码使用指定的7位或8位二进制数组合来表示128或256种可能的字符。标准ASCII码也叫基础ASCII码,使用7位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符。
Unicode码
Unicode码
Unicode为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF(十六进制),有110多万,每个字符都有一个唯一的Unicode编号,这个编号一般写成16进制,在前面加上U+。例如:”爬“的Unicode是U+722C。它是一种规定,Unicode本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
理论上可以直接把Unicode编号直接转换成二进制进行存储,而Unicode并不是这么操作,因为除了这种直接转换成二进制的方案外,还有其他方案,主要有UTF-8,UTF-16,UTF-32,gbk。(UTF-8、UTF-16、UTF-32……都是 Unicode编码 的一种实现。)
utf-8编码方式
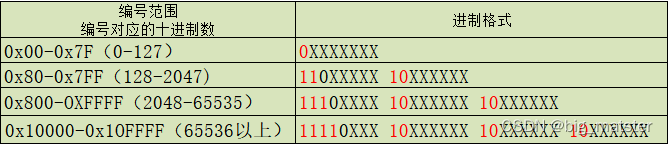
UTF-8最大特点,都是其是一种变长的编码方式,它可以使用1-4个字节表示一个符号,根据不同的符号变化字节的长度。