Python 爬虫之 Scrapy(带例子 macOS 环境)
1、概念
Scrapy是一个Python编写的开源网络爬虫框架,它是一个被设计用于爬取网络数据、提取结构性数据的框架。
Scrapy 使用了Twisted异步网络框架,可以加快我们的下载速度。
官方文档地址:Scrapy
2、工作流程
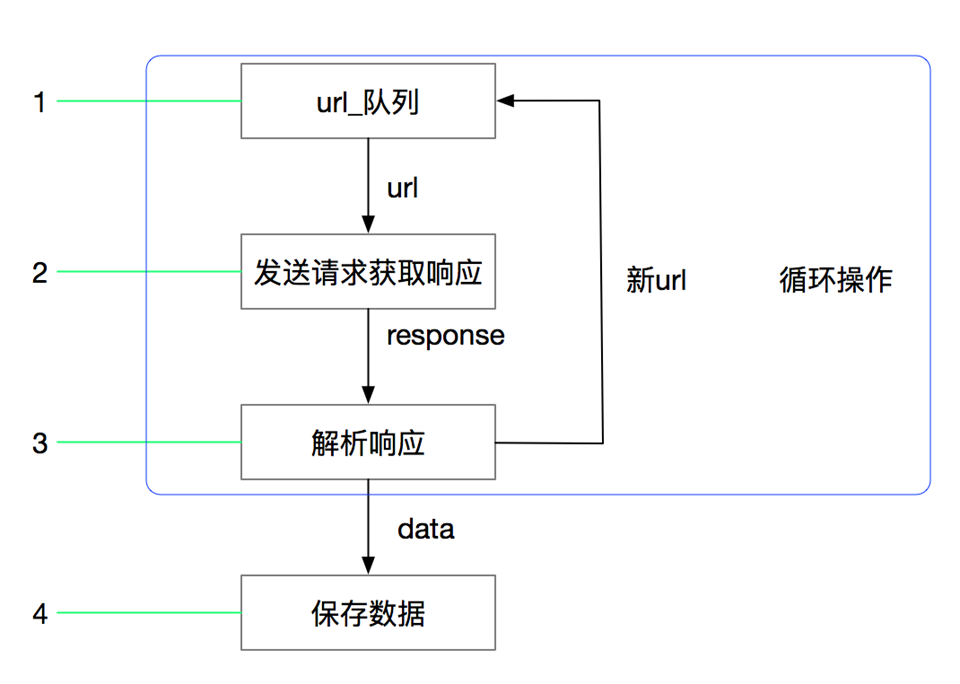
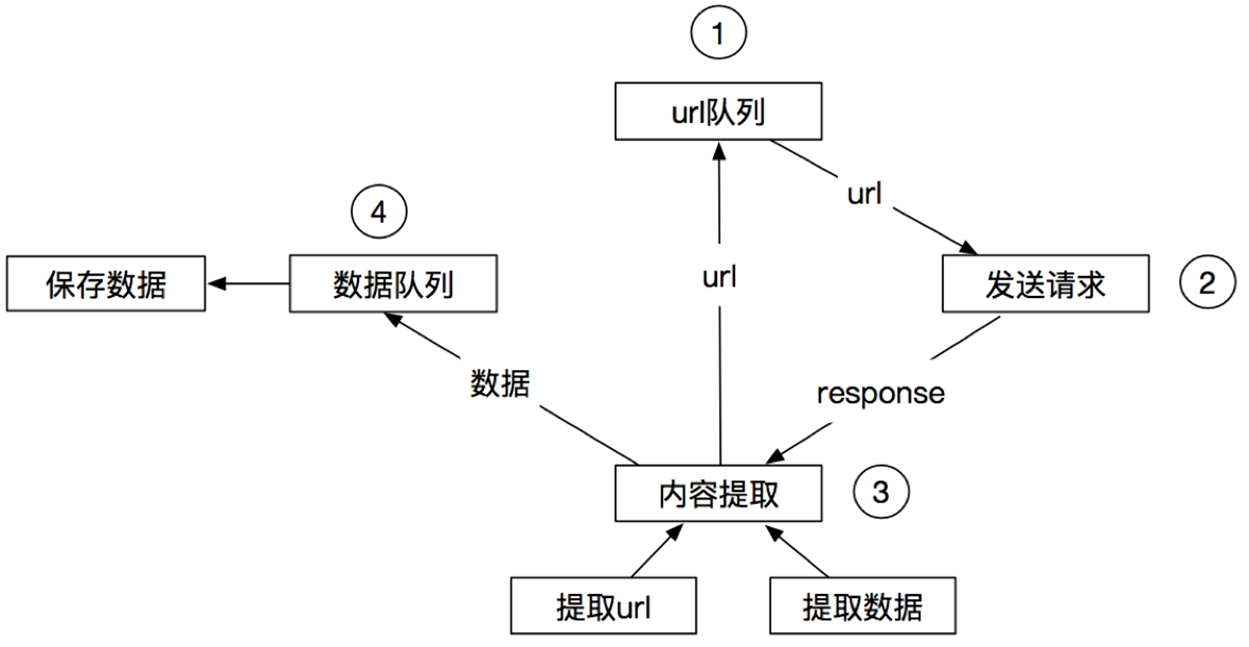
- 爬虫中起始的url构造成request对象 —> 爬虫中间件 —> 引擎 —> 调度器
- 调度器把request —> 引擎 —> 下载中间件 —> 下载器
- 下载器发送请求,获取response响应 —> 下载中间件 —> 引擎 —> 爬虫中间件 —> 爬虫
- 爬虫提取url地址,组装成request对象 —> 爬虫中间件 —> 引擎 —> 调度器,重复步骤2
- 爬虫提取数据 —> 引擎 —> 管道处理和保存数据
2.1 基本爬虫流程
2.2 基本爬虫模块关系
2.3 Scrapy工作流程
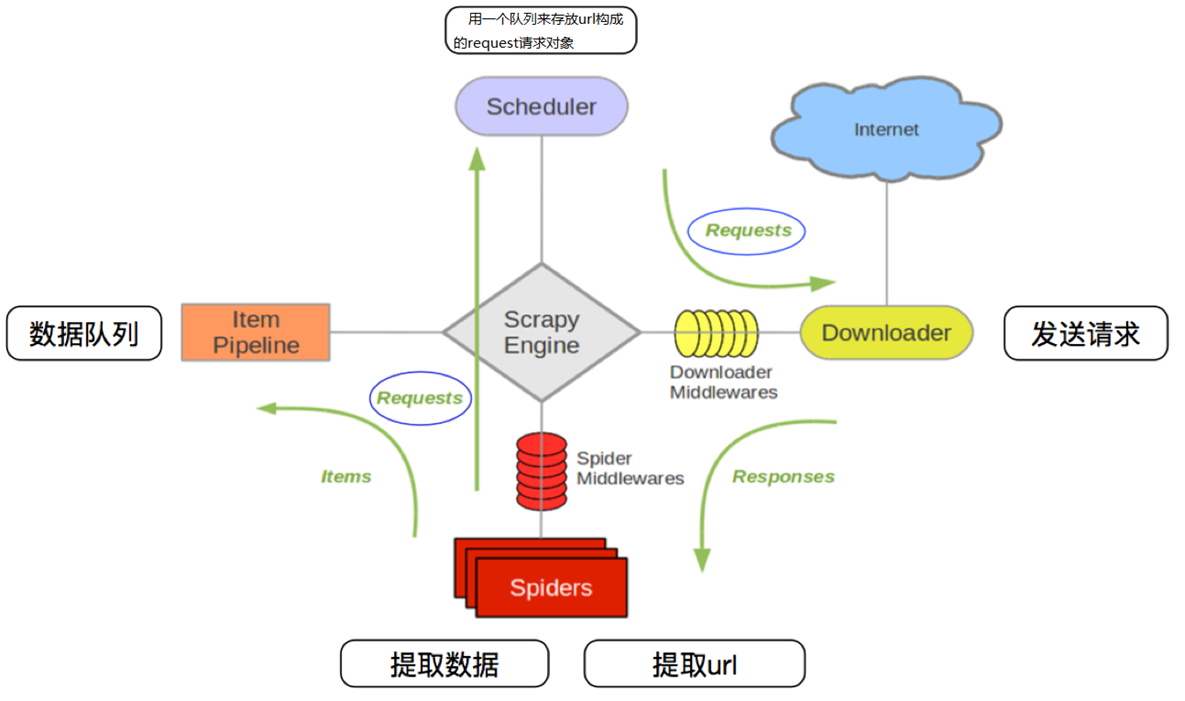
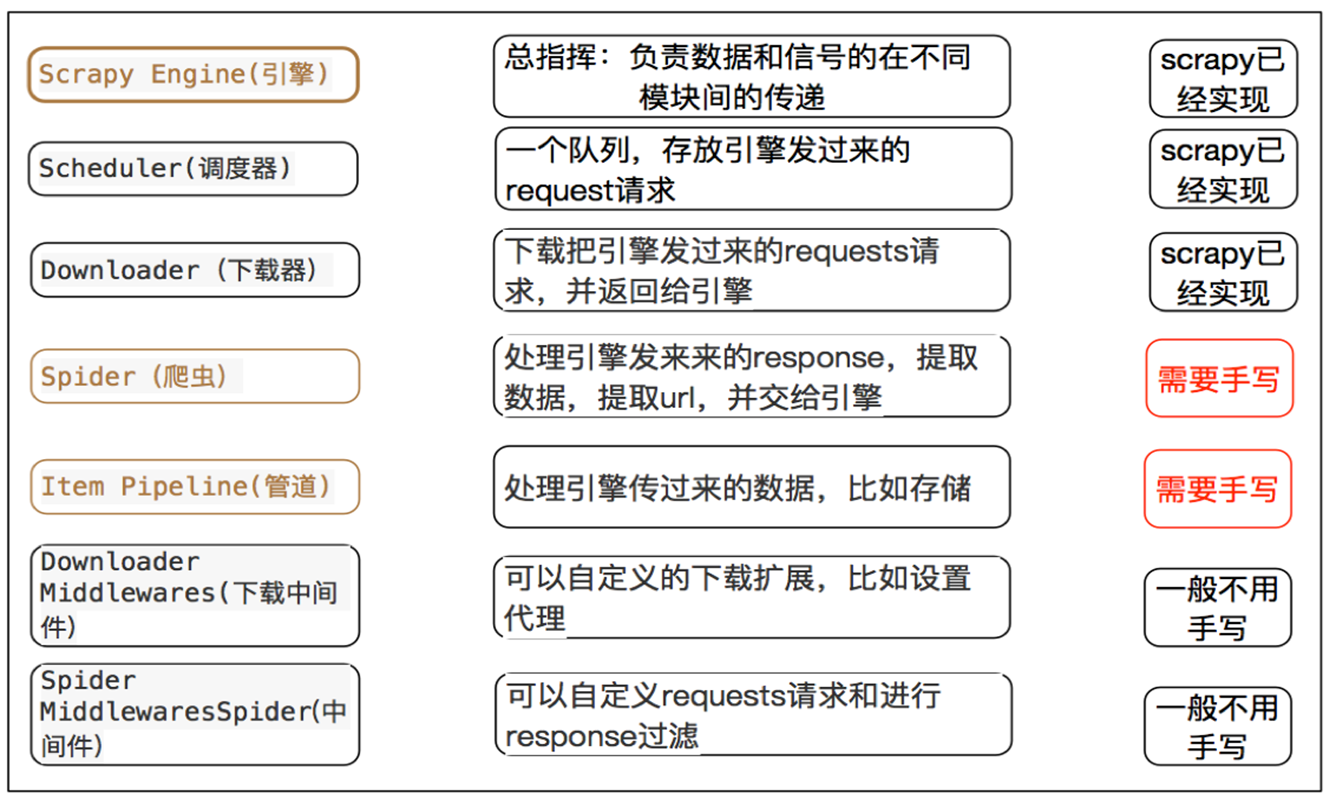
3、Scrapy中每个模块的具体作用
4、实例(美剧天堂最近100更新内容爬取)

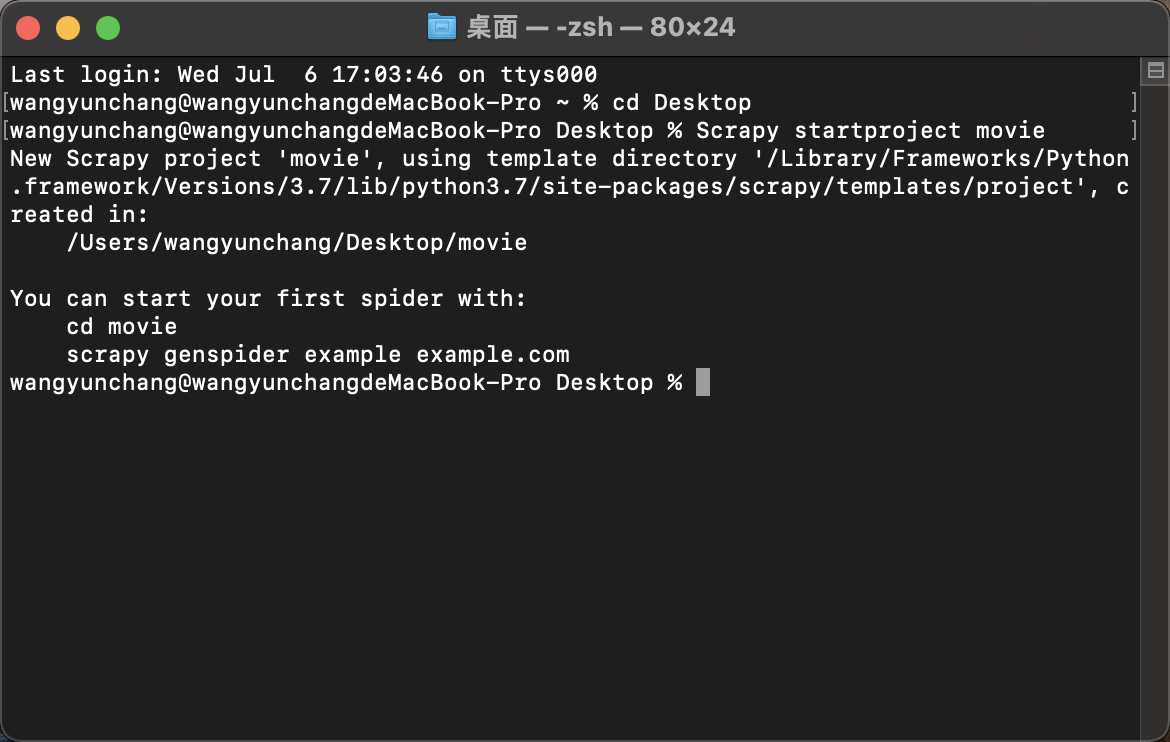
4.1 创建工程
cd Desktop # 我习惯项目都放在桌面
Scrapy startproject movie
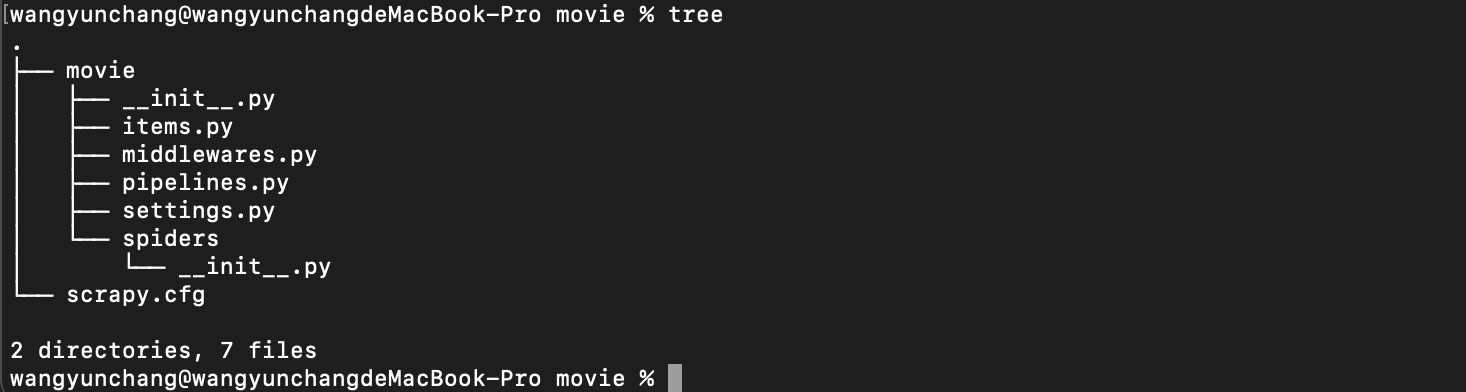
可在桌面看到带有如下目录的文件夹,那么工程就创建成功了。
4.2 创建爬虫程序
cd movie # 用 cd 先进入 movie 目录
Scrapy genspider meiju meijutt.tv # 创建了一个叫 meiju 的爬虫
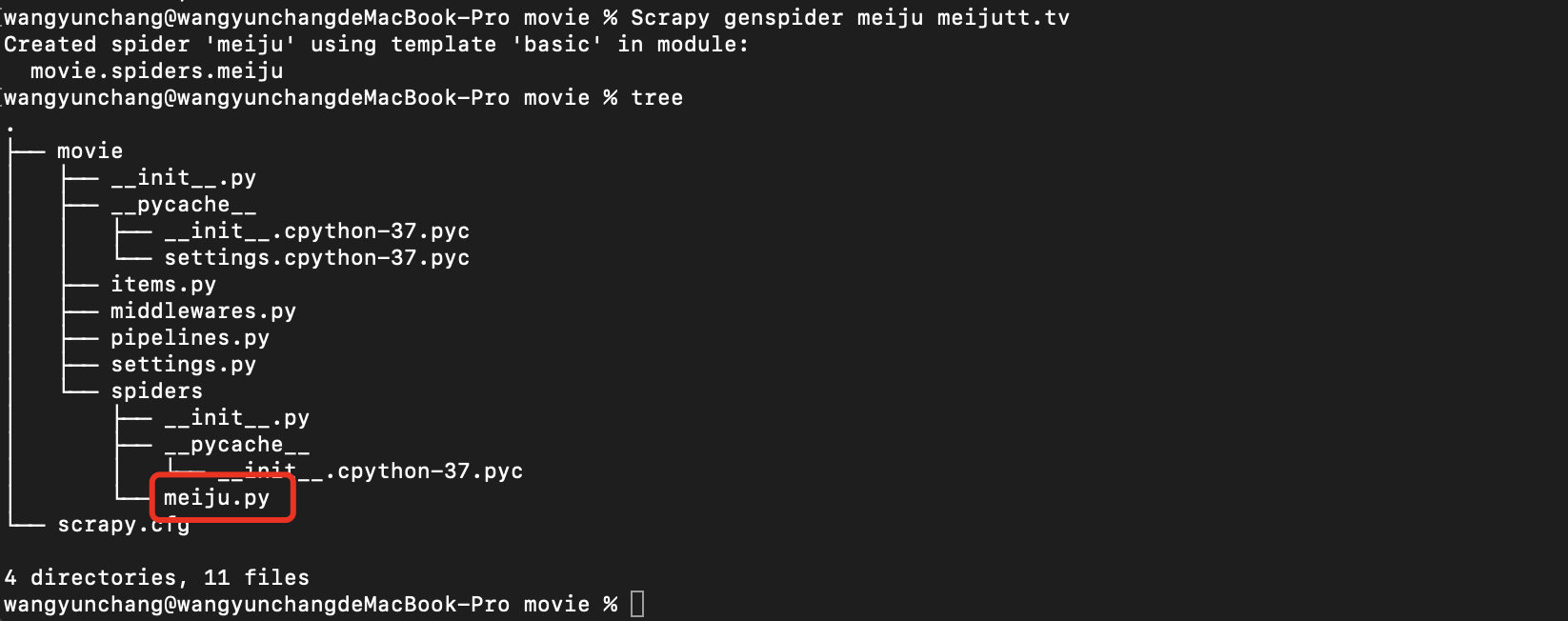
查看 spiders 目录可以看到多了一个 meiju.py,就是我们刚创建的爬虫。
4.3 编辑爬虫
- pipelines和items文件,负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- middlewares用来定义和实现中间件的功能
- settings 整个项目的配置文件
- spiders/目录下是我们的爬虫文件
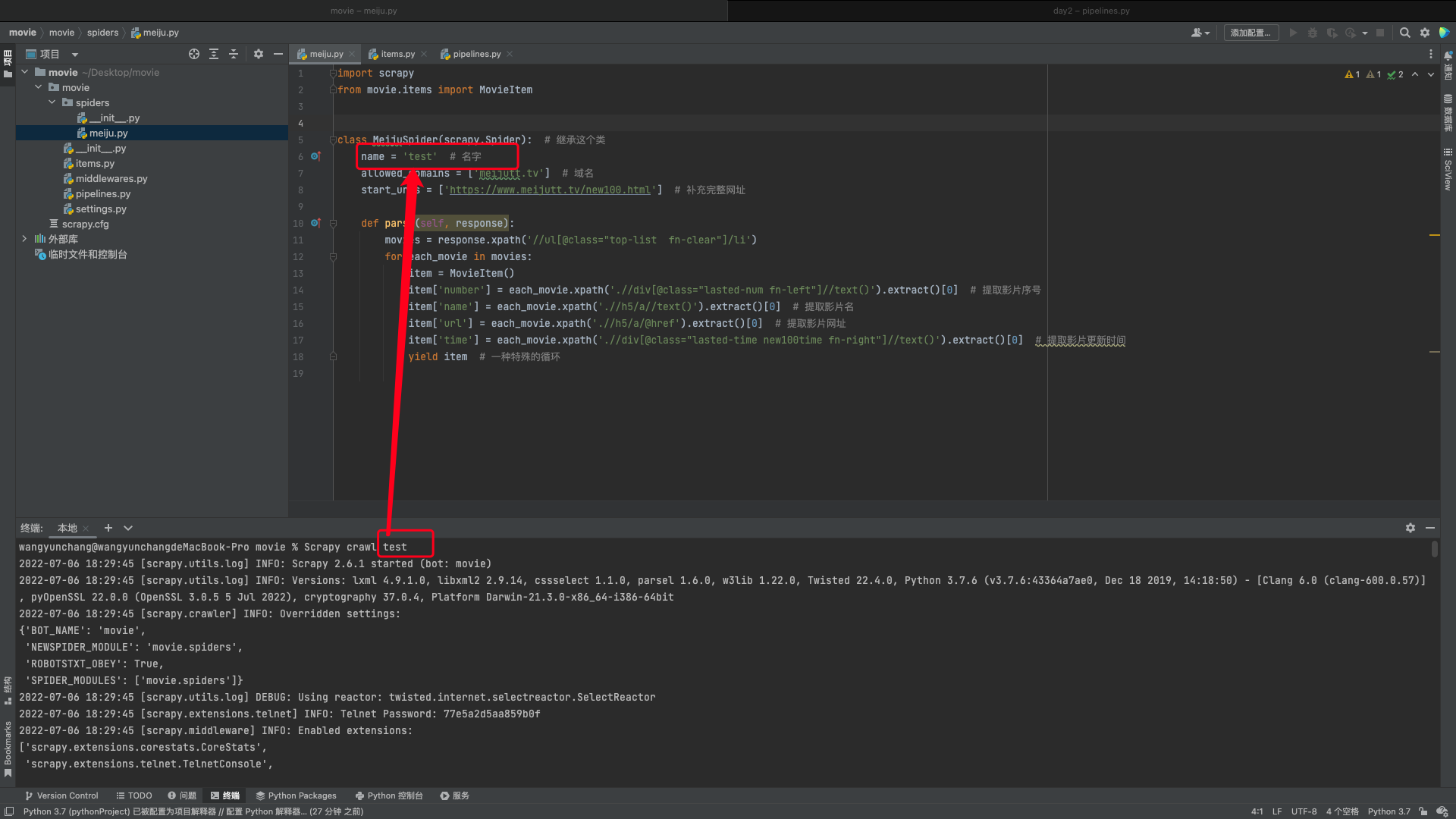
4.3.1 meiju.py
import scrapy
from movie.items import MovieItem
class MeijuSpider(scrapy.Spider): # 继承这个类
name = 'test' # 名字
allowed_domains = ['meijutt.tv'] # 域名
start_urls = ['https://www.meijutt.tv/new100.html'] # 补充完整网址
def parse(self, response):
movies = response.xpath('//ul[@class="top-list fn-clear"]/li') # 选中所有的属性class值为"top-list fn-clear"的ul下的li标签内容
for each_movie in movies:
item = MovieItem()
item['number'] = each_movie.xpath('.//div[@class="lasted-num fn-left"]//text()').extract()[0] # 提取影片序号
item['name'] = each_movie.xpath('.//h5/a//text()').extract()[0] # 提取影片名
item['url'] = each_movie.xpath('.//h5/a/@href').extract()[0] # 提取影片网址
item['time'] = each_movie.xpath('.//div[@class="lasted-time new100time fn-right"]//text()').extract()[0] # 提取影片更新时间
yield item # 一种特殊的循环
4.3.2 items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MovieItem(scrapy.Item):
# define the fields for your item here like:
number = scrapy.Field()
name = scrapy.Field()
url = scrapy.Field()
time = scrapy.Field()
# pass
4.3.3 设置配置文件 settings.py
添加上这一句:
ITEM_PIPELINES = {
'movie.pipelines.MoviePipeline': 100}
4.3.4 设置数据处理脚本 pipelines.py
import json
class MoviePipeline(object):
def process_item(self, item, spider):
return item
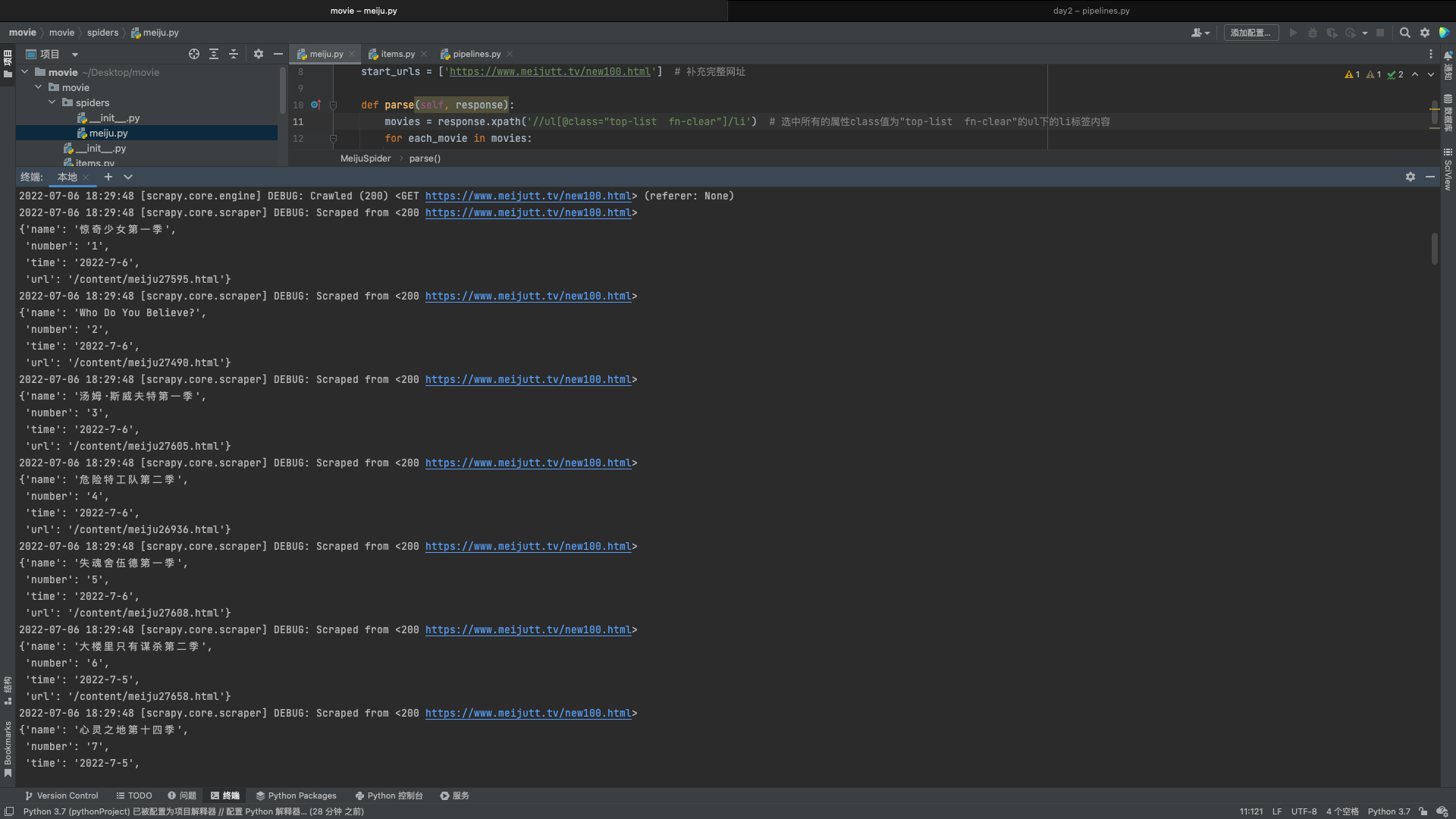
4.4 启动爬虫
在爬虫程序 meiju.py 目录下启动终端
Scrapy crawl test # 启动的名字和你前面给他取的名字对应,注意不是文件名!!!也不是函数名!!!
出现如下图所示,就是成功爬取我们需要的内容了