一、基本环境
- win10
- PyCharm
- Python 3.6
二、scrapy 环境搭建
安装两个python模块:Twisted、scrapy。在cmd中安装会快捷一点。
- 安装Twisted: 执行 pip install twisted
- 安装scrapy:执行 pip install scrapy
【注】安装完成后,执行 pip list 检查以下上述两个模块是否安装成功。
三、在pycharm创建一个Scrapy项目
1.在pycharm中创建一个普通项目(Pure Project 即可),如下图。
2.在cmd中cd至项目所在文件夹,执行 scrapy startproject ScrapyDemo,如下。
【注】也可在pycharm自带的Terminal中执行 crapy startproject ScrapyDemo。

执行完之后,pycharm中的项目如下图
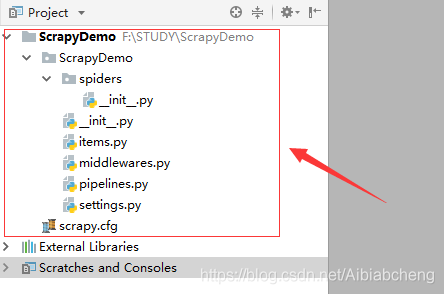
各文件功能解释
../ScrapyDemo/ 爬虫项目 ScrapyDemo/ 爬虫文件夹 __init__.py 必须存在 items.py 字段 可以写需要爬取对象的类 middlewares.py 中间件 pipelines.py 管道文件 settings.py 爬取配置 spiders/ 开发位置 scrapy.cfg 项目配置
四、写一个可以运行的scrapy示例
下面示例的功能是爬取博主第一页博文的基本属性(标题、类型、url、发布时间、阅读量),结果如下图。
扫描二维码关注公众号,回复: 10843212 查看本文章

1.写完代码后的项目结构如下图。
2.各文件代码
(1)items.py
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ArticleItem(scrapy.Item):
title = scrapy.Field() # 文章标题
type = scrapy.Field() # 文章类型(原创/转载/翻译)
url = scrapy.Field() # 文章链接
date = scrapy.Field() # 文章发布日期
read_num = scrapy.Field() # 文章阅读量(2)在 ScrapyDemo / spiders 下新建文件 spiderDemo.py
import scrapy
from ScrapyDemo.items import ArticleItem
class CSDNArticle(scrapy.Spider) :
name = 'get_scdn_article' # 爬虫名称
allowed_domains = ['blog.csdn.net/Aibiabcheng'] # 爬虫域
start_urls = ['https://blog.csdn.net/Aibiabcheng'] # 爬虫地址
def output_article(self, article_list): # 输出
for item in article_list :
print(item['type'], '\t' ,item['title'])
print(item['date'], '\t', item['read_num'], '\t', item['url'], '\n')
def parse(self, response) :
article_list = []
res = response.xpath('//div[@class=\"article-list\"]/div')
for item in res :
try :
# 获取 文章属性
type = item.xpath('./h4/a/span/text()').extract()[0]
url = item.xpath('./h4/a/@href').extract()[0]
title = item.xpath('./h4/a/span[@class=\'article-type type-1 float-none\']/following::text()').extract()[0].strip()
date = item.xpath('./div[@class=\'info-box d-flex align-content-center\']/p/span[@class=\'date\']/text()').extract()[0].strip()
read_num = item.xpath('./div[@class=\'info-box d-flex align-content-center\']/p/span[@class=\'read-num\']/span[@class=\'num\']/text()').extract()[0]
# 创建对象 并 赋值
article = ArticleItem()
article['title'] = title
article['type'] = type
article['url'] = url
article['date'] = date
article['read_num'] = read_num
article_list.append(article) # 暂存
except :
continue
self.output_article(article_list) # 输出(3)修改文件 settings.py.
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # 此处为修改
# 添加如下,按照自己实际的填写
DEFAULT_REQUEST_HEADERS = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36",
'Accept': 'image/webp,image/apng,image/*,*/*;q=0.8',
}(4)在 ScrapyDemo 下新建文件 start.py.
from scrapy import cmdline
cmdline.execute("scrapy crawl get_scdn_article".split()) # get_scdn_article为spiderDemo中的name3.在 pycharm 中运行 scrapy 项目。
(1)选择“Edit Configurations…”
(2)添加新的 Configurations, 选择 python; 然后进行配置。
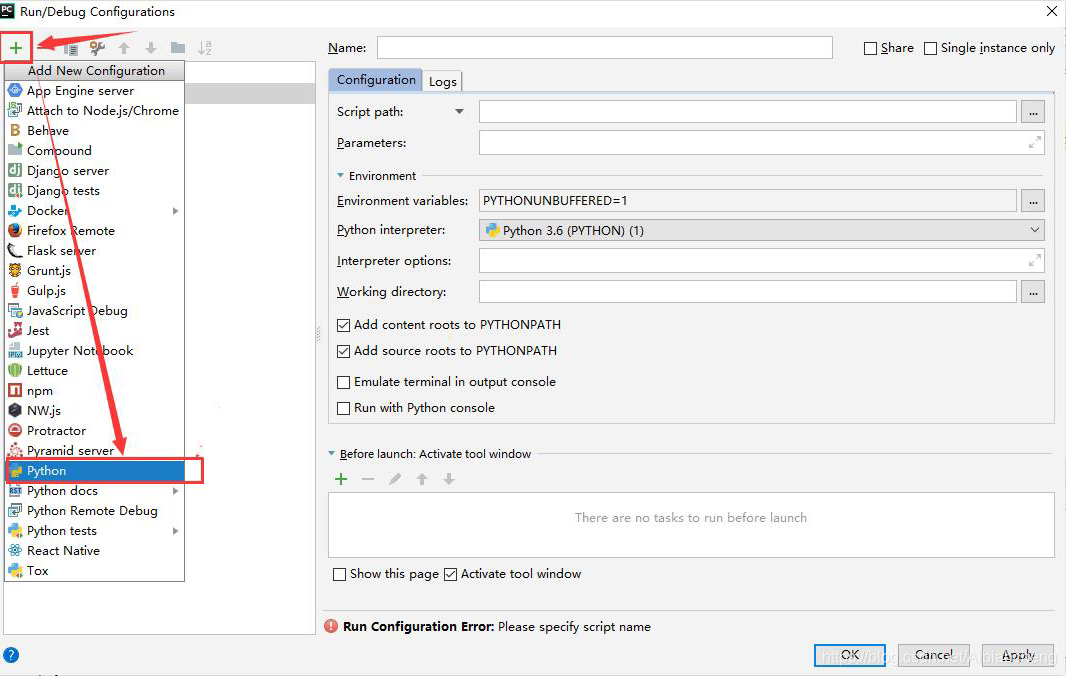
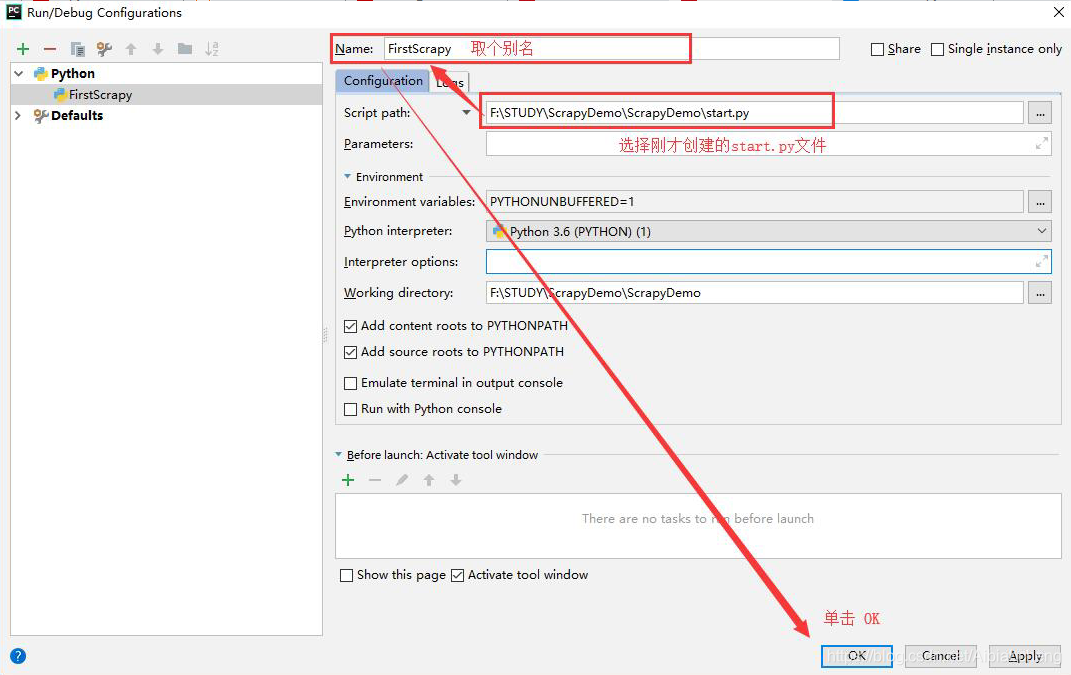
(3)像运行普通python程序一样,执行即可。运行成功如下图。
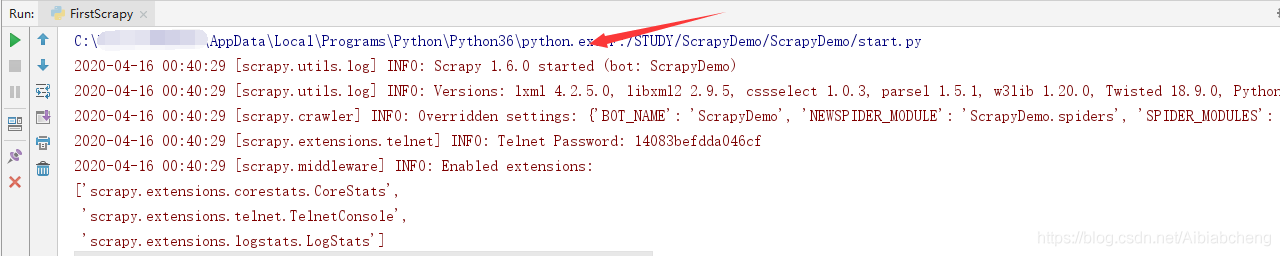
【注1】:首次运行可能会遇到 error:ModuleNotFoundError: No module named 'win32api'
解决办法:pip install pypiwin32
