前言
本篇博文将介绍一下在ImageNet 2014 年斩获目标定位竞赛的第一名,图像分类竞赛的第二名的网络结构VGG。VGG 是 Visual Geometry Group 的缩写,是这个网络创建者的队名,作者来自牛津大学.
VGG论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》作为一篇会议论文在2015年的ICLR大会上发表
Visual Geometry Group实验室链接:https://www.robots.ox.ac.uk/~vgg/
VGG 最大的特点就是它在之前的网络模型上,通过比较彻底地采用 3x3 尺寸的卷积核来堆叠神经网络,从而加深整个神经网络的层级。并且VGG论文给出了一个非常振奋人心的结论:卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用
网络模型分析
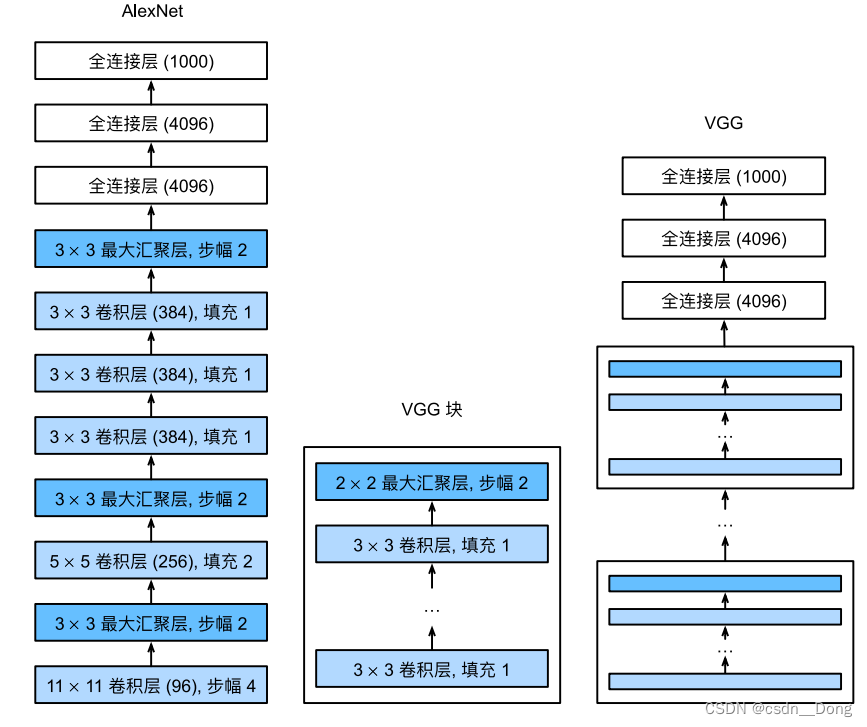
与AlexNet、LeNet⼀样,VGG⽹络可以分为两部分:第⼀部分主要由卷积层和汇聚层组成,第⼆部分由全连接层组成。从AlexNet到VGG,它们本质上都是块设计,如下图:
VGG各层配置信息如下图:
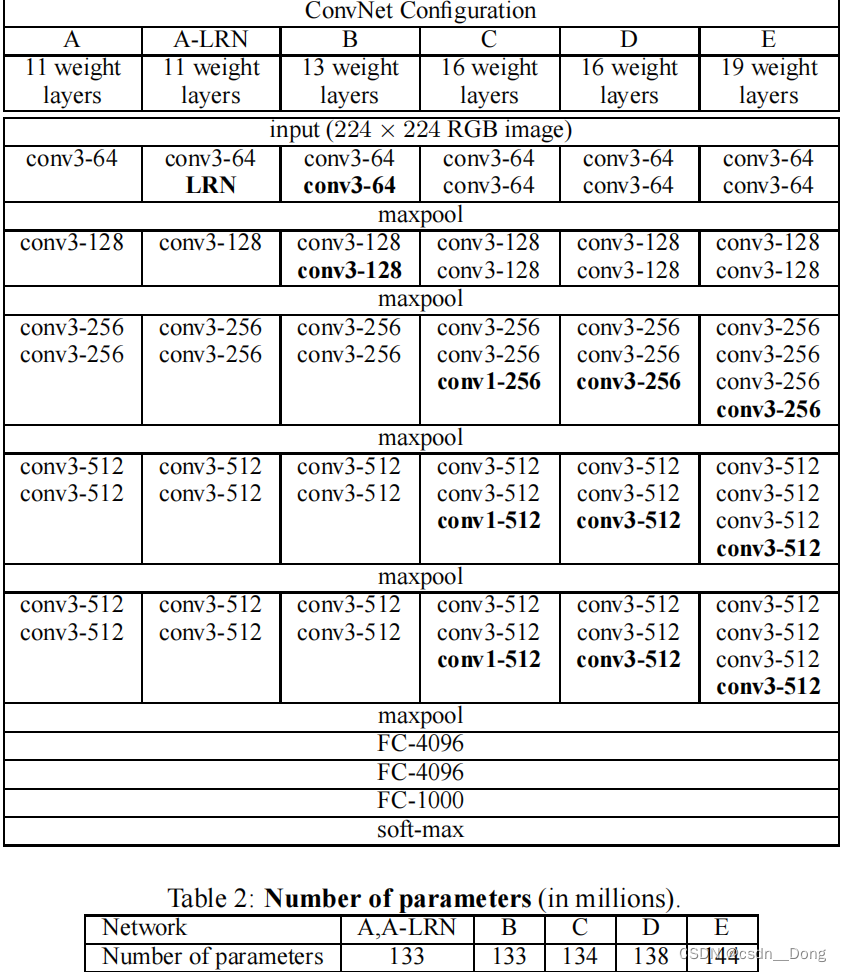
注意:ConvNet配置(以列显示)。配置的深度增加从左边(A)到右边(E),随着更多的层被添加(添加的层以黑体显示)。卷积层的参数卷积层的参数被表示为"卷积场大小-通道数"(例如图中Conv3-64代表卷积核尺寸3X3,通道是64)。为了简洁起见,ReLU激活函数没有显示。
从VGG-16上图可以看出,它主要包括下列模型
- GG-11(8Conv+3FC)
原始VGG⽹络有5个卷积块,其中前两个块各有⼀个卷积层,后三个块各包含两个卷积层。第⼀个模块有64个
输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该⽹络使⽤8个卷积层和3个全连接
层,因此它通常被称为VGG-11 - VGG-13(10Conv+3FC)
- VGG-16(13Conv+3FC)
- VGG-19 (16Conv+3FC)
VGG 选择的是在 AlexNet 的基础上加深它的层数,但是它有个很显著的特征就是持续性的添加 3x3 的卷积核。而AlexNet 有 5 层卷积层,从上面的网络结构图我们可以看出来,VGG 就是针对这 5 层卷积层进行改造,共进行了 6 种配置
六种配置的效果展示图如下:
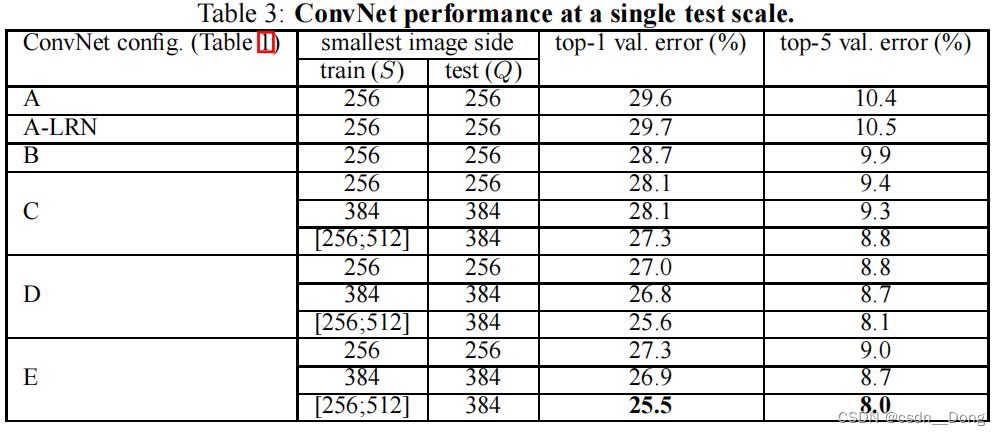
从上面的效果图中,我们发现VGG19是最好的。但是,VGG-19 的参数比 VGG-16 的参数多了好多。由于VGG-19需要消耗更大的资源,因此实际中VGG-16使用得更多。而且VGG-16网络结构十分简单,并且很适合迁移学习,因此至今VGG-16仍在广泛使用,下面我们主要来讨论一下VGG16的网络结构
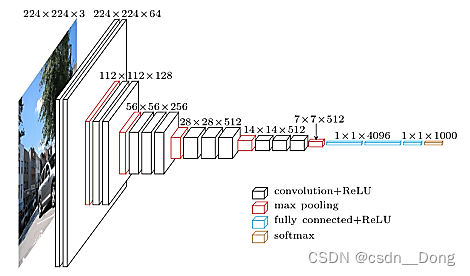
从上图可以看到网络的第一个卷积层的通道数为,然后每一层Max Pooling之后卷积层的通道数都成倍的增加,最后界三个全连接层完成分类任务。总的来说VGGNet的贡献可以概括如下两点
-
所有隐藏层都使用了ReLU激活函数,而不是LRN(Local Response Normalization),因为LRN浪费了更多的内存和时间并且性能没有太大提升。
-
使用更小的卷积核和更小的滑动步长。和AlexNet相比,VGG的卷积核大小只有3x3和1x1两种。卷积核的感受野很小,因此可以把网络加深,同时使用多个小卷积核使得网络总参数量也减少了。
网络模型特点总结
优点
使用3x3卷积核替代7x7卷积核
-
3x3 卷积核是能够感受到上下、左右、重点的最小的感受野尺寸。并且,2 个 3x3 的卷积核叠加,它们的感受野等同于 1 个 5x5 的卷积核,3 个叠加后,它们的感受野等同于 1 个 7x7 的效果。
-
由于感受野相同,3个3x3的卷积,使用了3个非线性激活函数,增加了非线性表达能力,使得分割平面更具有可分性。
-
使用3x3卷积核可以减少参数,假设现在有 3 层 3x3 卷积核堆叠的卷积层,卷积核的通道是 C 个,那么它的参数总数是 3x(3Cx3C) = 27C^2 。同样和它感受野大小一样的一个卷积层,卷积核是 7x7 的尺寸,通道也是 C 个,那么它的参数总数就是 49C^2。而且通过上述方法网络层数还加深了。三层3x3的卷积核堆叠参数量比一层7x7的卷积核参数链还要少。
-
总的来说,使用3x3卷积核堆叠的形式,既增加了网络层数又减少了参数量。
更深的网络结构
- 相比于AlexNet只有5层卷积层,VGG系列加深了网络的深度,更深的结构有助于网络提取图像中更复杂的语义信息
缺点
- 它的缺点在于,参数量有140M之多,需要更大的存储空间,其中绝大多数的参数都是来自于第一个全连接层,并且VGG有3个全连接层
最后自我总结
使用更小的卷积核的网络是NiN(Network In Network)
Network In Network。使用1x1卷积核的主要好处:
-
增加网络的深度,使用多个1x1卷积核,在保持feature map 尺寸不变(即不损失分辨率)的前提下,可以大幅增加非线性表达能力,把网络做得很deep。
-
进行卷积核通道数的降维和升维。
-
实现跨通道的交互和信息整合。
总结就是:1x1 卷积核的好处是不改变感受野的情况下,进行升维和降维,同时也加深了网络的深度。
为甚么VGG那么的耗费资源咋用内存
VGGNet的详细情况。让我们把VGGNet作为一个案例进行更详细的分析。整个VGGNet由CONV层和POOL层组成,前者执行3x3卷积,步长为1,后者执行2x2最大池化,步长为2(无填充)。我们可以写出处理过程中每一步的表示的大小,并跟踪表示的大小和权重的总数
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
正如卷积网络所常见的那样,注意到大部分的内存(还有计算时间)都用在早期的CONV层,而大部分的参数都在最后的FC层。在这个特定的案例中,第一个卷积层包含了100M的权重,而总的来说是140M。
计算方面的考虑
构建ConvNet架构时需要注意的最大瓶颈是内存瓶颈。许多现代GPU有3/4/6GB的内存限制,最好的GPU有大约12GB的内存。有三个主要的内存来源需要跟踪。
来自中间卷的大小。这些是ConvNet每一层的激活的原始数量,还有它们的梯度(大小相等)。通常情况下,大部分激活都在ConvNet的早期层(即第一个Conv层)。但如果有一个聪明的实现,只在测试时运行ConvNet,原则上可以大量减少这些激活,只存储任何一层的当前激活,而抛弃下面各层的先前激活。
从参数大小来看。这些数字保存着网络参数,它们在反向传播过程中的梯度,如果使用动量、Adagrad或RMSProp进行优化,通常还有一个步长缓存。 因此,仅存储参数向量的内存通常必须乘以至少3左右的系数。
每一个ConvNet的实现都必须维护杂项内存,比如图像数据批次,也许还有它们的增强版本,等等。
一旦你对数值的总数有了一个粗略的估计(用于激活、梯度和杂项),就应该把这个数字转换成GB大小。取值的数量,乘以4得到原始的字节数(因为每个浮点都是4个字节,或者可能乘以8的双精度),然后多次除以1024,得到KB、MB和最后GB的内存量。如果你的网络不合适,"使其合适 "的常见启发式方法是减少批量大小,因为大部分的内存通常被激活所消耗。
参考文档
CS231n: Convolutional Neural Networks for Visual Recognition.