前言
该论文的四位作者何恺明、张祥雨、任少卿和孙剑如今在人工智能领域里都是响当当的名字,当时他们都是微软亚研的一员。微软亚研是业内为数不多的,能够获得科技巨头持续高投入的纯粹学术机构。ResNet 论文< Deep Residual Learning for Image Recognition>被引用数量悄然突破了10万加。
论文摘要
更深的神经网络更难训练。我们提出了一个残差学习框架,以减轻训练的网络,这些网络比以前使用的网络要深得多。我们明确地将各层重新表述为学习参考层输入的残差函数(residual functions),而不是学习未参考的函数( unreferenced functions)。我们提供了全面的经验证据,表明这些残差函数网络更容易优化,并能从大大增加的深度的网络中中获得准确性。在ImageNet数据集上,我们我们评估了深度为152层的残差网络8倍于VGG网络的深度。比VGG网络更深,但仍然具有较低的复杂性。这些残差网的组合在ImageNet测试集上实现了3.57%的误差。这一结果在2015年ILSVRC分类任务中获得了第一名。我们还提出了对对CIFAR-10的100层和1000层的分析。表征的深度对于许多视觉识别任务来说是非常重要的。仅仅由于我们极深的表征,我们在COCO物体检测数据集上获得了28%的相对改进。我们还在ImageNet检测、ImageNet定位、COCO检测和COCO分割等任务中获得了第一名。
残差网络解决了什么问题
我们前面介绍 VGG 和 GoogleNet 的时候就已经提到过,在深度学习模型的前进道路上,一个重要的研究课题就是神经网络结构究竟能够搭建多深。在很长的一段时间里,研究人员对神经网络结构有一个大胆的预测,那就是更深的网络架构能够带来更好的泛化能力
那么接下来的挑战就是,如何构建更深的网络,训练更深的网络,以及更深的网络有更好的泛化性能。
首先面临的第一个问题就是模型训练时的梯度“爆炸”(Exploding)或者“消失”(Vanishing)
为了解决这个问题,研究学者们提出了很多的技术手段比如 “线性整流函数”(ReLu),“批量归一化”(Batch Normalization),“预先训练”(Pre-Training),“归一化初始化”(normalized initialization)等等。
第二个问题是退化问题
随着网络深度的增加,精度达到饱和(这可能并不奇怪),然后迅速下降,也就是模型的准确度变差了
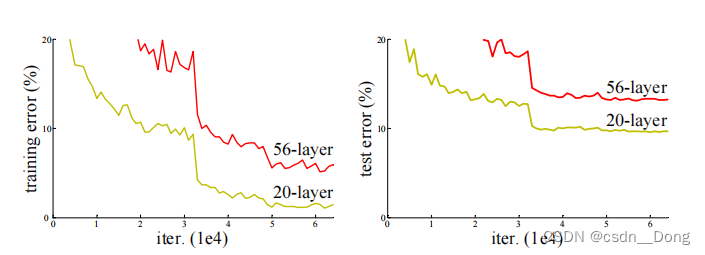
如上图:20层和56层的 "普通 "网络。更深的网络有较高的训练误差,因此测试误差也较大
我们从 GoogleNet 的思路可以看出,网络结构是可以加深的,比如对网络结构的局部进行创新。而这篇论文,就是追随 GoogleNet 的方法,在网络结构上提出了一个新的结构,叫 “残差网络”(Residual Network),简称为 ResNet,从而能够把模型的规模从几层、十几层或者几十层一直推到了上百层的结构,而不出现退化,这就是这篇文章的最大贡献。
从模型在实际数据集中的表现效果来看,ResNet 的错误率只有 VGG 和 GoogleNet 的一半,模型的泛化能力随着层数的增多而逐渐增加。这其实是一件非常值得深度学习学者振奋的事情,因为它意味着深度学习解决了一个重要问题,突破了一个瓶颈。
论文中的核心方法-深度残差学习框架
我们先假设有一个隐含的基于输入 x 的函数 H。这个函数可以根据 x 来进行复杂的变换,比如多层的神经网络。然而,在实际中,我们并不知道这个 H 到底是什么样的。那么,传统的解决方式就是我们需要一个函数 F 去逼近 H。

而这篇文章提出的“残差学习”的方式,就是不用 F 去逼近 H,而是去逼近 H(x) 减去 x 的差值。在机器学习中,我们就把这个差值叫作“残差”,也就是表明目标函数和输入之间的差距。当然,我们依然无法知道函数 H,在实际中,我们是用 F 去进行残差逼近。
F(x)=H(x)-x,当我们把 x 移动到 F 的一边,这个时候就得到了残差学习的最终形式,也就是 F(x)+x 去逼近未知的 H。
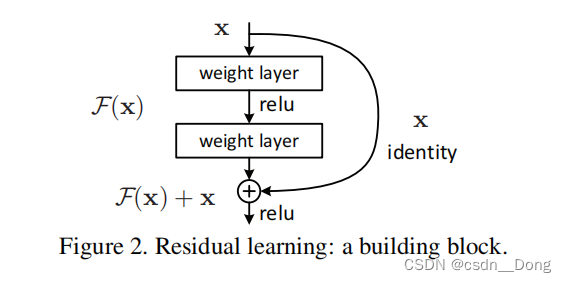
在这个公式里,外面的这个 x 往往也被称作是“捷径”(Shortcuts)。什么意思呢?有学者发现,在一个深度神经网络结构中,有一些连接或者说层与层之间的关联其实是不必要的。我们关注的是 ,什么样的输入就应当映射到什么样的输出,也就是所谓的“等值映射”(Identity Mapping)。
遗憾的是,如果不对网络结构进行改进,模型无法学习到这些结构。那么,构建一个从输入到输出的捷径,也就是说,从 x 可以直接到 H(或者叫 y),而不用经过 F(x),在必要的时候可以强迫 F(x) 变 0。也就是说,捷径或者是残差这样的网络架构,在理论上可以帮助整个网络变得更加有效率,我们希望算法能够找到哪些部分是可以被忽略掉的,哪些部分需要保留下来。
在真实的网络架构中,作者们选择了在每两层卷积网络层之间就加入一个捷径,然后叠加了 34 层这样的架构。从效果上看,在 34 层的时候 ResNet 的确依然能够降低训练错误率。于是,作者们进一步尝试了 50 多层,再到 110 层,一直到 1202 层的网络。最终发现,在 110 层的时候能够达到最优的结果。而对于这样的网络,所有的参数达到了 170 万个。
为了训练 ResNet,作者们依然使用了批量归一化以及一系列初始化的技巧。值得一提的是,到了这个阶段之后,作者们就放弃了 Dropout,不再使用了
相关的工作
残差表示
VALD,Fisher Vector都是是对残差向量编码来表示图像,在图像分类,检索表现出优于编码原始向量的性能。
在low-level的视觉和计算机图形学中,为了求解偏微分方程,广泛使用的Multigrid方法将系统看成是不同尺度上的子问题。每个子问题负责一种更粗糙与更精细尺度的残差分辨率。Multigrid的一种替换方法是层次化的预处理,层次化的预处理依赖于两种尺度的残差向量表示。实验表明,这些求解器要比对残差不敏感的求解器收敛更快。
shortcut连接
shortcut连接被实验和研究了很久。Highway networks也使用了带有门函数的shortcut。但是这些门函数需要参数,而ResNet的shortcut不需要参数。而且当Highway networks的门函数的shortcut关闭时,相当于没有了残差函数,但是ResNet的shortcut一直保证学习残差函数。而且,当Highway networks的层数急剧增加时,没有表现出准确率的上升了。总之,ResNet可以看成是Highway networks的特例,但是从效果上来看,要比Highway networks好
深度残差学习
残差学习
根据多层的神经网络理论上可以拟合任意函数,那么可以利用一些层来拟合函数。问题是直接拟合H(x)还是残差函数,由前文,拟合残差函数F(x) = H(x) - x更简单。虽然理论上两者都能得到近似拟合,但是后者学习起来显然更容易。
作者说,这种残差形式是由退化问题激发的。根据前文,如果增加的层被构建为同等函数,那么理论上,更深的模型的训练误差不应当大于浅层模型,但是出现的退化问题表面,求解器很难去利用多层网络拟合同等函数。但是,残差的表示形式使得多层网络近似起来要容易的多,如果同等函数可被优化近似,那么多层网络的权重就会简单地逼近0来实现同等映射,即F(x) = 0。
实际情况中,同等映射函数可能不会那么好优化,但是对于残差学习,求解器根据输入的同等映射,也会更容易发现扰动,总之比直接学习一个同等映射函数要容易的多。根据实验,可以发现学习到的残差函数通常响应值比较小,同等映射(shortcut)提供了合理的前提条件。
通过shortcut同等映射
F(x)与x相加就是就是逐元素相加,但是如果两者维度不同,需要给x执行一个线性映射来匹配维度:
用来学习残差的网络层数应当大于1,否则退化为线性。文章实验了layers = 2或3,更多的层也是可行的。
用卷积层进行残差学习:以上的公式表示为了简化,都是基于全连接层的,实际上当然可以用于卷积层。加法随之变为对应channel间的两个feature map逐元素相加。
网络模型分析
作者由VGG19设计出了plain 网络和残差网络,如下图中部和右侧网络。然后利用这两种网络进行实验对比。

左到右分别是VGG,没有残差的PlainNet,有残差的ResNet
设计网络的规则:1.对于输出feature map大小相同的层,有相同数量的filters,即channel数相同;2. 当feature map大小减半时(池化),filters数量翻倍。
对于残差网络,维度匹配的shortcut连接为实线,反之为虚线。维度不匹配时,同等映射有两种可选方案:
第一种方法:直接通过zero padding 来增加维度(channel)。
第二种方法是用1x1卷积,1x1卷积他在空间维度不做任何变化(宽高不变),通道(channel)做出改变。当快捷方式跨越两种大小的特征映射时,让输出通道是输入通道2倍,它们将以2的步幅执行。
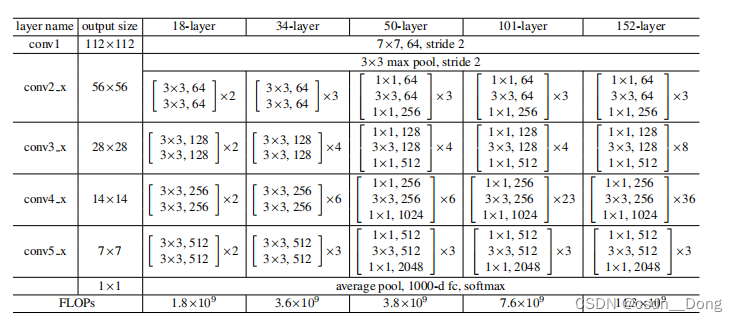
上表是Resnet不同的结构,上表一共提出了5中深度的ResNet,分别是18,34,50,101和152,我们发现所有的网络都有5个卷积块,conv1,conv2_x,conv3_x,conv4_x,conv5_x。他们的区别在于conv2_x,conv3_x,conv4_x,conv5_x,这几个卷积快,中的残差块组成的不同。特别注意的是50-layer和34-layer中的浮点运算复杂度并不是倍数增长的,这里面就是用到了更深的瓶颈结构设计。
图中网路的层是如何计算的:
- resnet18:(conv1)+ (conv2_x)+ (conv3_x)+ (conv4_x)+ (conv5_x)+ (FC) = 1+(2 * 2)+(2 * 2)+(2 * 2)+ (2 * 2)+1 = 1+16+1 = 18
- resnet34:(conv1)+ (conv2_x)+ (conv3_x)+ (conv4_x)+ (conv5_x)+ (FC) = 1+(2 * 3)+(2 * 4)+(2 * 6)+ (2 * 3)+1 = 1+32+1 = 34
图中给出的残差块的个数是怎么得出的
猜测可能作者做了大量的测试调参数得出来得,因为没有规律,我们也可以针对我们自己的任务自己调整和优化,并不是一层不变的。
特殊设计-更深的瓶颈结构
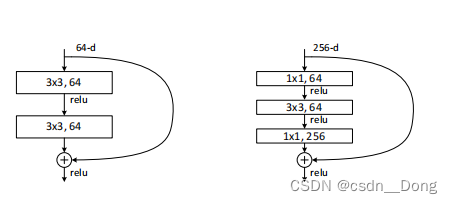
作者探索的更深的网络。 考虑到时间花费,将原来的building block(残差学习结构)改为瓶颈结构,如上图三层的设计。首端和末端的1x1卷积用来削减(用1x1的卷积从256映射到64)和恢复维度(用1x1的卷积从64映射到256),相比于原本结构,只有中间3x3成为瓶颈部分。这两种结构的时间复杂度相似。此时投影法映射带来的参数成为不可忽略的部分(当输入维度的增大),所以要使用zero padding的同等映射。
替换原本ResNet的残差学习结构,同时也可以增加结构的数量,网络深度得以增加。生成了ResNet-50,ResNet-101,ResNet-152. 随着深度增加,因为解决了退化问题,性能不断提升。
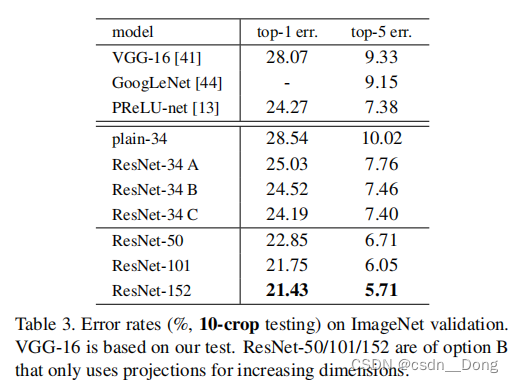
- 上图中ResNet-34A:使用零填充的快捷方式用于增加维数,并且所有的快捷方式都是无参数的
- 上图中ResNet-34B:部分shorcut做投影,投影增加维度,其他shortcuts are identity
- 上图中ResNet-34C:所有的shortcut都做投影
ResNet-34B和ResNet-34C 差别不是很大,而做投影又是一个比较昂贵的操作,带来了大量的计算复杂度,所以不划算,之后我们所说的resnet都是B这种操作。
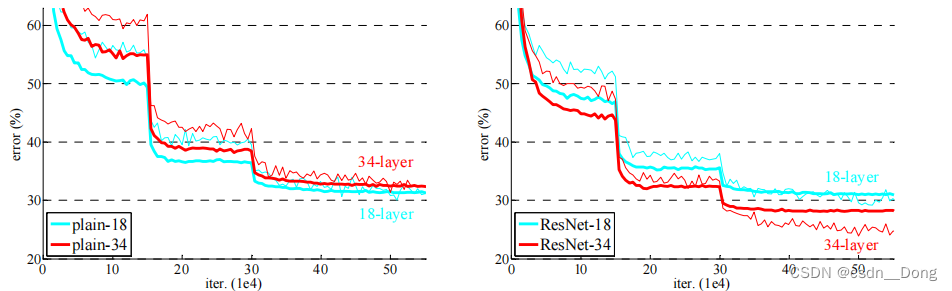
上图是在ImageNet上训练错误率的对比,左边是普通网络(plain)和右边带残差块的网络。
作者最后在Cifar-10上尝试了1202层的网络,结果在训练误差上与一个较浅的110层的相近,但是测试误差要比110层大1.5%。作者认为是采用了太深的网络,发生了过拟合。
ResNet 贡献
引入残差块,能够训练很深的网络,解决了随着网络的加深带来的退化。
参考文档
https://www.cnblogs.com/alanma/p/6877166.html
https://mp.weixin.qq.com/s/-O_VhTS4KFBVB8aDJ4l5ig
https://mp.weixin.qq.com/s/lT5HRA2Q3T-aIJhjBol51Q
写在最后
强烈推荐阅读ResNet论文,论文中又很多的图表,清晰容易理解,而且ResNet又是一篇经典之作。
欢迎大家留言讨论,熬夜写文不易,如果对你有帮助,给个赞!