基础知识
在这里需要知道一些基础知识,才能理解本文的内容,若只想实现内容可跳过本部分
什么是cookie
cookie,有时我们也用其复数形式 cookies,是服务端保存在浏览器端的数据片段。以 key/value的形式进行保存。每次请求的时候,请求头会自动包含本网站此目录下的 cookie 数据。网站经常使用这个技术来识别用户是否登陆等功能。
可以单纯的把cookie理解成保存客户端相关信息的一个东西,如:当你在网上登录的时候,会有一系列标识着你身份的信息,服务器会在返回登录界面的时候,把这些信息夹在响应中传给客户端,也就区别了普通的login页面与用户登录后的界面,有了这个信息以后,服务器就能知道你是这个用户,运行你登录。
它是一种解决HTTP协议无状态的方案,浏览器每次发请求的时候,都会携带cookie信息,可以随意打开一个页面,打开开发者工具,抓取任意一个包就可以找到cookie信息,如下:
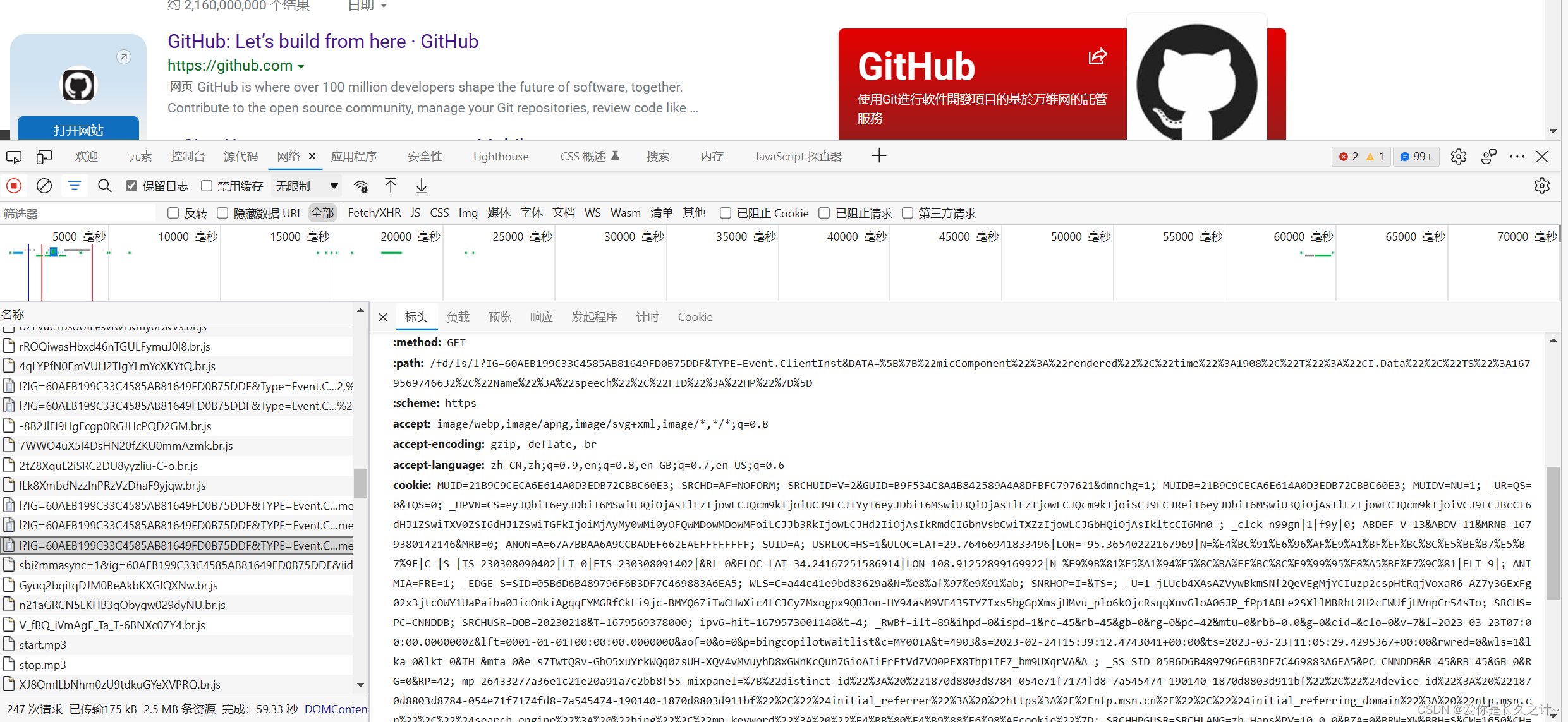
因此在实现GitHub登录之前,我们需要先登录一次,获取cookie信息,随后在爬虫中使用cookie参数进行无需账号密码的登录。
准备工作
在这部分,需要准备爬虫发请求所需要的各种数据,通过对GitHub登录过程进行抓包分析。
无痕模式进入GitHub网页------》打开开发者工具(F12)------》点击保留日志------》点击sign in------》输入你的账号密码并登录------》点击session------》找到Cookie,具体如图所示:
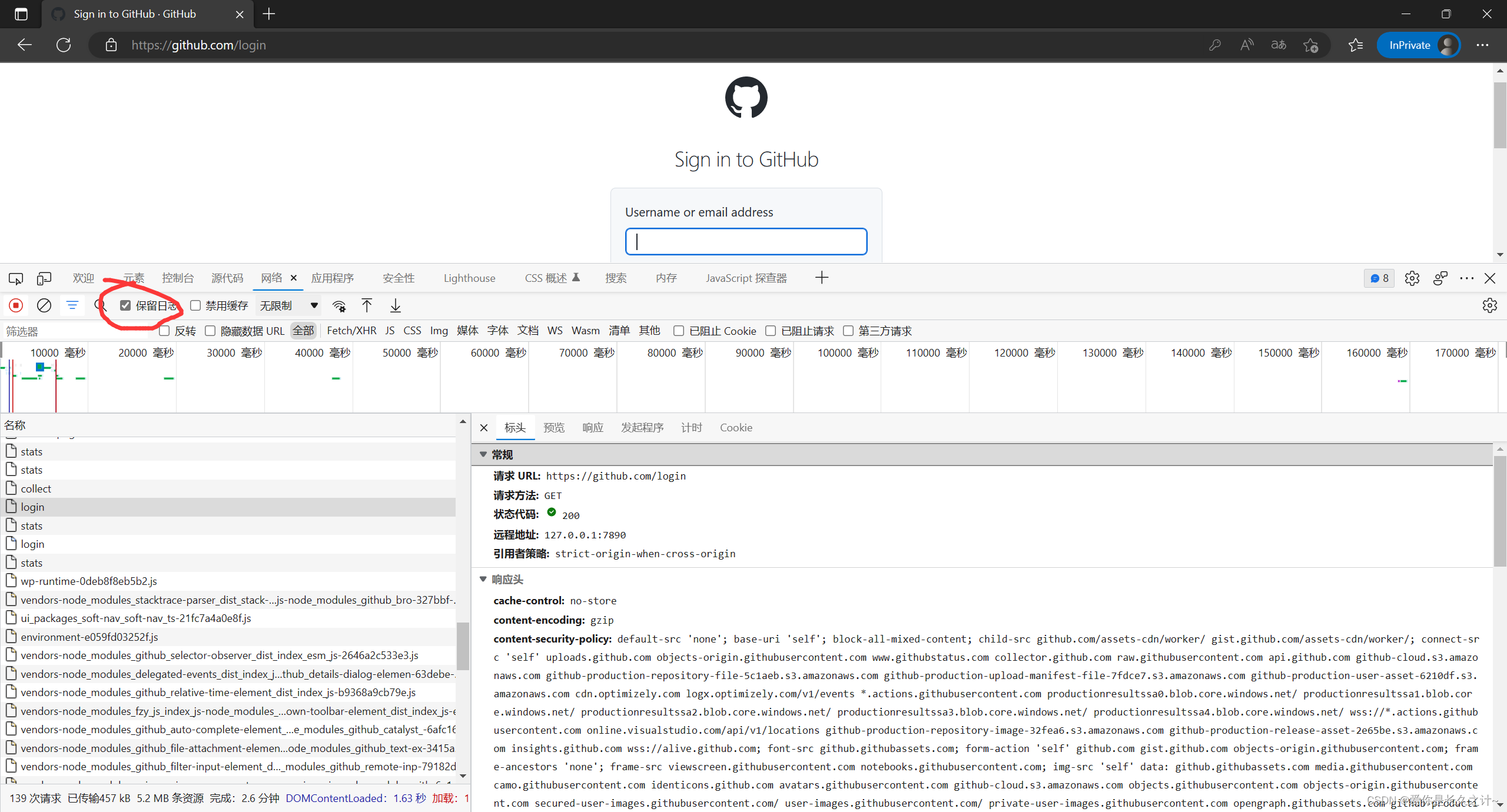
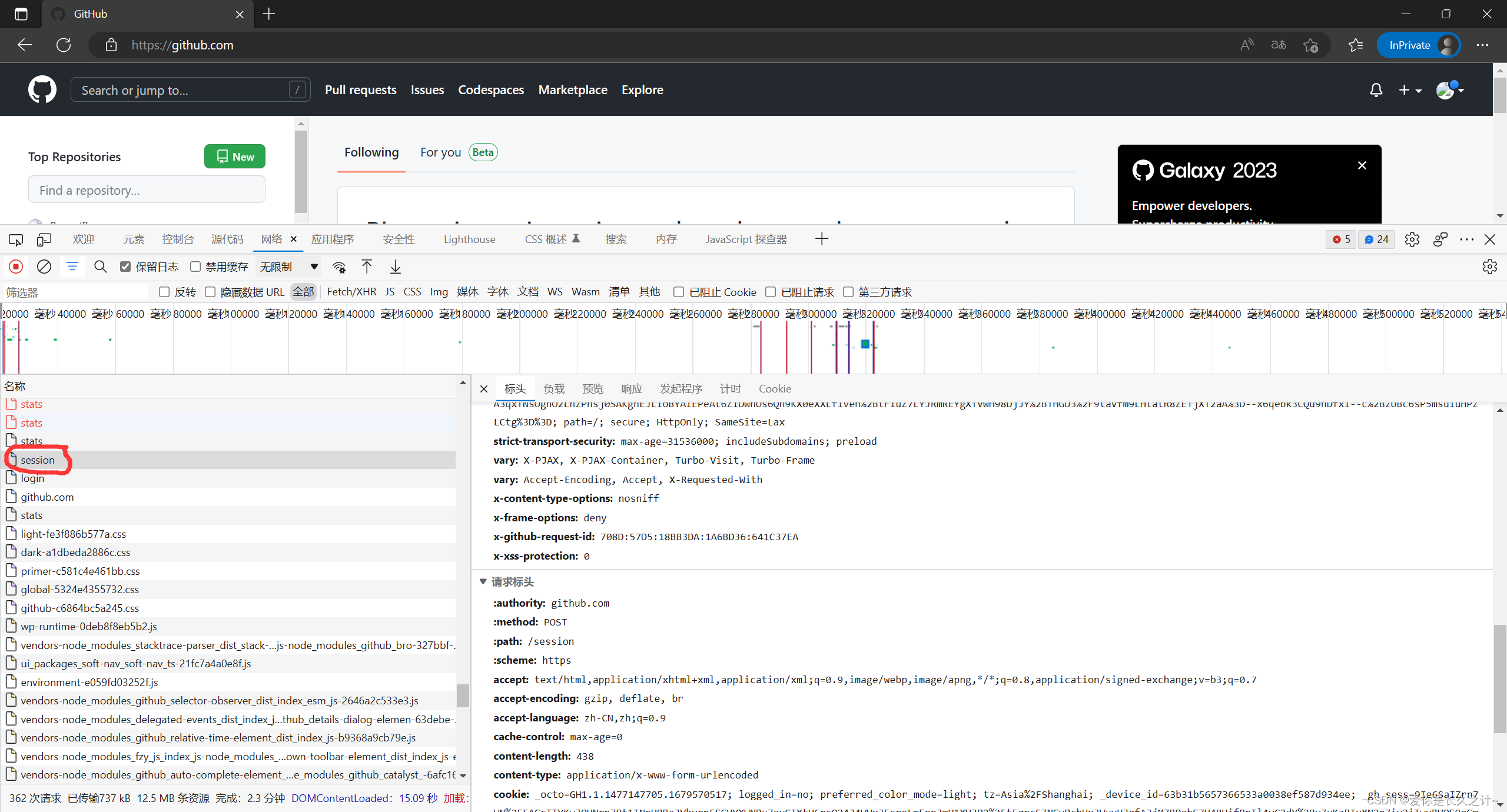
在这里就能找到cookie信息,将其复制下来,随后生成cookies字典
代码部分
import requests
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36 QIHU 360SE',
}
def login():
# 我们登录了以后 抓包把cookie拷到headers中 设置"Cookie"参数
# 这是没有cookie的 爬到后 title会有 .GitHub
ur = 'https://github.com/你的用户名'
response1 = requests.get(url=ur, headers=headers)
with open('github_without_cookie.html', 'wb') as f:
f.write(response1.content)
# 可以在headers中直接设置cookie 也可以在get中设置cookies参数
# cookies = {"cookie中的name":"cookie的value"}
cookieStr = '这里是你的cookie字段的值'
# 这将你的cookie字符串变成由多个key-word组成的字典
cookies = {
cookie.split('=')[0]: cookie.split('=')[-1] for cookie in cookieStr.split('; ')}
print(cookies)
response2 = requests.get(url=ur, headers=headers, cookies=cookies)
with open('github_with_cookie.html', 'wb') as f:
f.write(response2.content)
if __name__ == "__main__":
login()
注意:有两个部分的信息需要按照你的实际情况来填,一个是你的GitHub昵称,一个是你的cookie
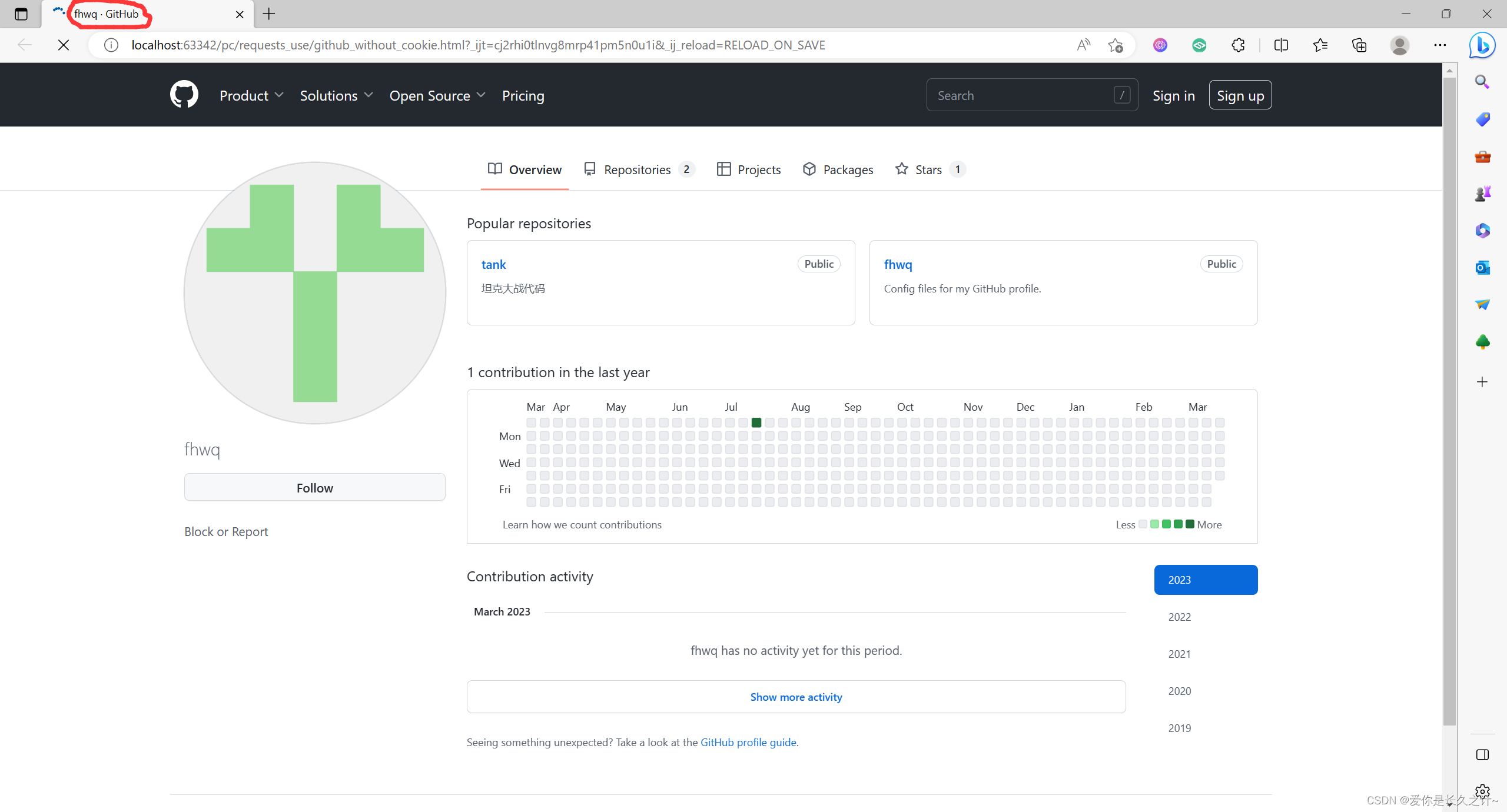
在完成之后,同文件夹会有两个html文件,分别对应无cookie的界面以及有cookie的界面,其中正确登录的界面应如下所示:
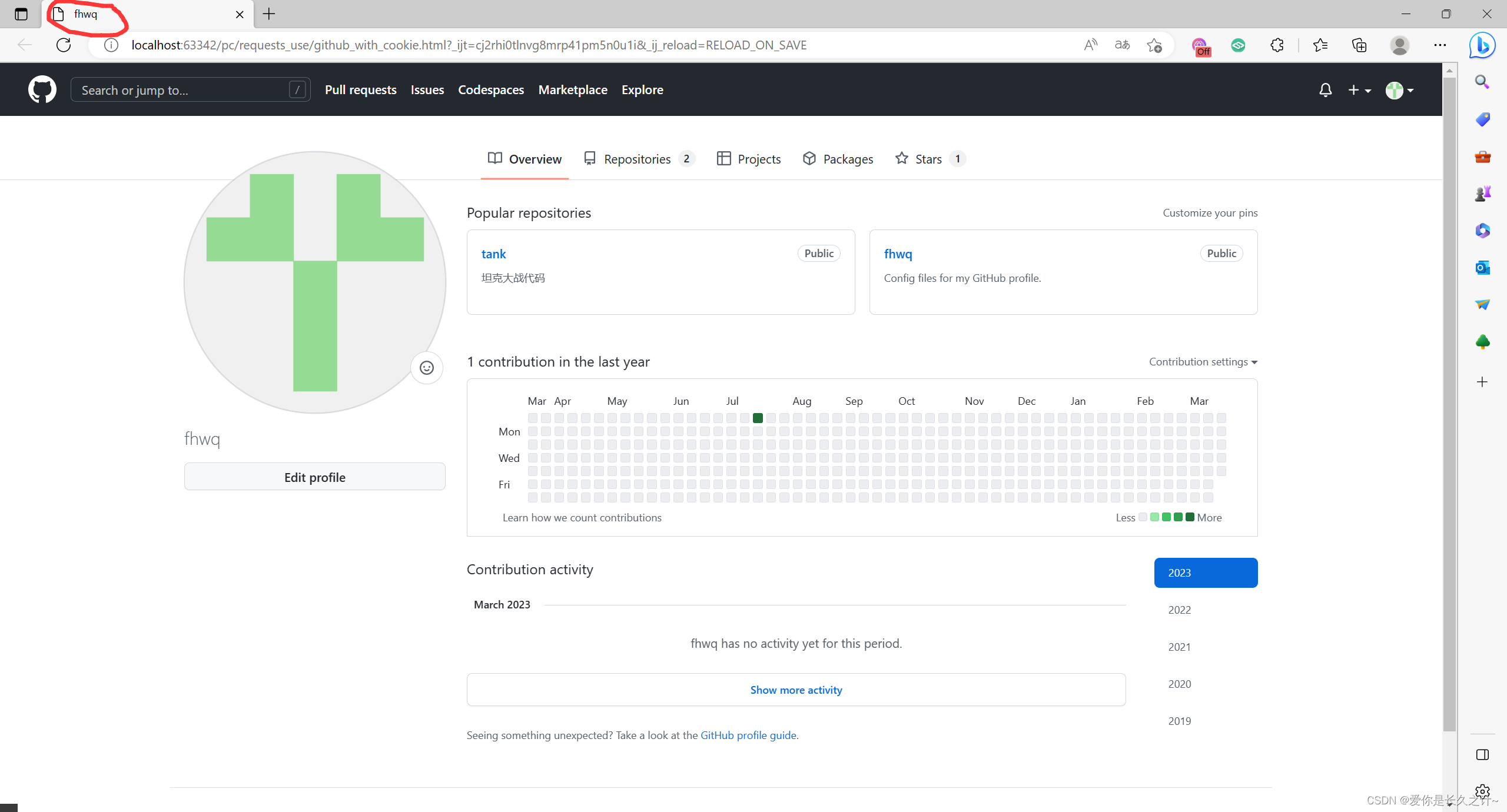
如出现上面的界面,就表示你成功使用cookie登录了!而无cookie的界面,在title处会多出来一个.GitHub