Jetson Nano tensorrt部署YOLOX流程
1. 起因
之前项目本来是cpu跑,后来硬件对于视频编解码来不及,于是整个项目换到GPU环境上重构.由于之前部署用的模型是yolov5效果很差并且yolox是易于新手部署的,于是用yolox重新训了一版模型,效果有很大提升.昨天部署到边缘盒子中需要在盒子里重新做模型转换因此有了这篇Blog,这篇Blog主要记录一下部署流程.
2. 开始
部署流程大致如下:
- 训练好模型,导出onnx
- onnx转tensorrt
- 改写前处理/后处理部分,以及输入输出,利用tensorrt推理
- 编译进行测试
- 整合项目
这篇Blog默认是已经有了onnx模型以后的流程,模型训练以及导出onnx在官方代码库中都有很好的实现,根据自己需要导出就行.其实yolox是非常易于部署的,官方差不多已经把整套流程都写好了,这也是为什么拿它当例子的原因,应该可以算得上部署的“hello world”了吧
2.1 onnx转tensorrt
将转出的onnx模型scp传到Nano中,Nano应该是默认配置好了tensorrt环境的,所以只需要找到trtexec就可以直接转换了
可以看出我们需要的车型分类以及单轮双轮都检测出来了,然后测试没问题之后把这部分代码移植到项目中,最终实际推理时间也能达到准实时,符合要求.
我的环境下直接去/usr/src/tensorrt/bin/下就有这个,然后运行转换命令
./trtexec --onnx=yolox.onnx --saveEngine=yolox.trt --fp16
这里我默认batchsize就是1,所以不用添加optShapes(min,max).另外workspace也是用默认值就好
2.2 C++部分
我们需要用c++结合opencv,tensorrt重写模型的前处理以及后处理,这部分官网给出了demo,我们只需要拷贝下来然后根据自己需要修改一下.
首先去下载代码https://github.com/Megvii-BaseDetection/YOLOX/tree/main/demo/TensorRT/cpp
然后修改CMakeLists中的链接库路径,查看cudnn等可以试试下面命令
ls /usr/lib/aarch64-linux-gnu | grep dnn
看到了对应的一些链接库文件,说明我们只需要把link_directories设置为这个路径
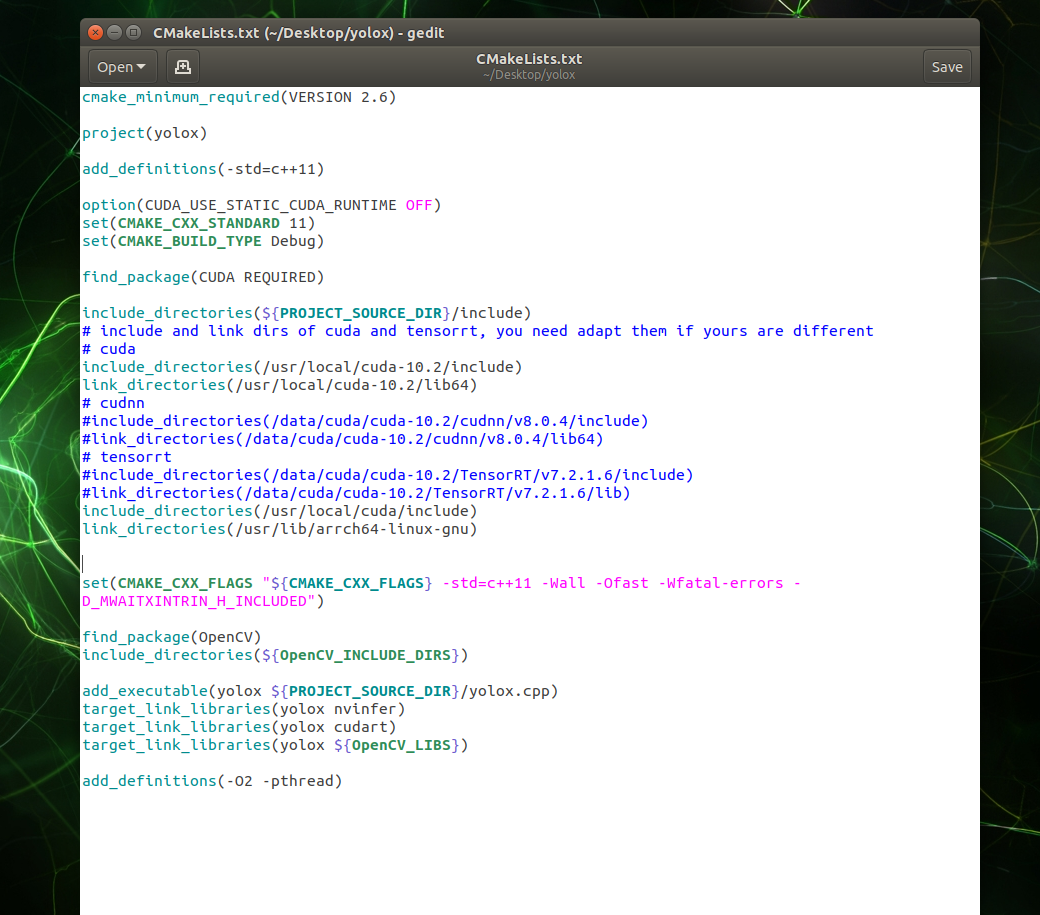
最终修改后的CMakeLists.txt如下
接下来修改cpp中的一些设置
首先是输入和输出的名字,这些是导出onnx时绑定的,你得去看export onnx时设置的input和output,这个要对应上.比如我导出时input是images,output是output,所以这里修改INPUT_BLOB_NAME="images"
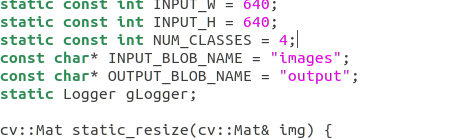
然后根据自己的模型预测结果修改预测类别数和名字

剩下的如果没有对yolox进行改进或者没有添加处理步骤,其他都都不需要改
2.3 编译并测试
万事俱备开始编译
cmake .
make -j8
就可以看到yolox这个可执行文件,然后进行测试
./yolox ./yolox.trt -i ./imgs/1.png
下面是输入的图片以及输出的预测图片


可以看出我们需要的车型分类以及单轮双轮都检测出来了,然后测试没问题之后把这部分代码移植到项目中,并将nms和置信度设置添加到config文件中,最终实际推理时间也能达到准实时符合要求.
3. 总结
其实这些并不难,难点都在针对各种实际问题设计高效算法这才是最需要思考的,部署这部分多玩几次自然就熟练了.