文章目录
1. HBase的实现原理
1.1 HBase功能组件
- HBase的实现包括三个主要的功能组件:
(1)库函数:链接到每个客户端
(2)一个Master主服务器
(3)许多个Region服务器 - 主服务器Master负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡
- Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求
- 客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据
- 客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
1.2 表和Region
开始只有一个Region,后来不断分裂
Region拆分操作非常快,接近瞬间,因为拆分之后的Region读取的仍然是原存储文件,直到“合并”过程把存储文件异步地写到独立的文件之后,才会读取新文件
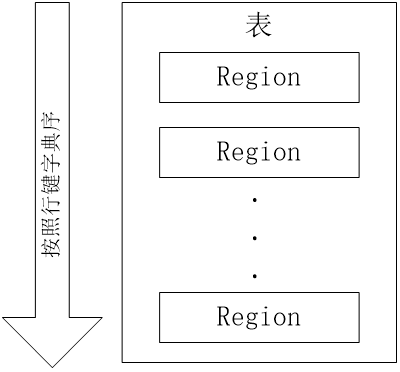
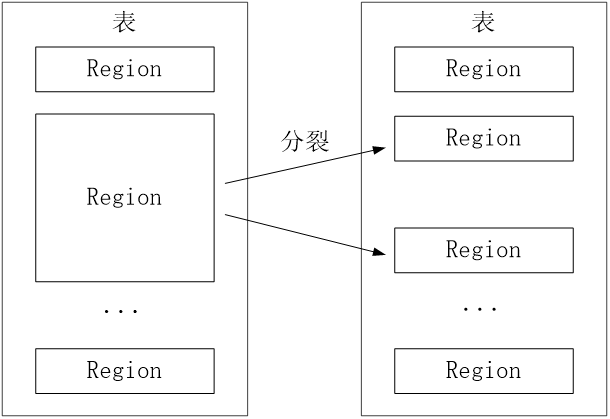
- 每个Region默认大小是100MB到200MB(2006年以前的硬件配置)
- 每个Region的最佳大小取决于单台服务器的有效处理能力
- 目前每个Region最佳大小建议1GB-2GB(2013年以后的硬件配置)
- 同一个Region不会被分拆到多个Region服务器
- 每个Region服务器存储10-1000个Region
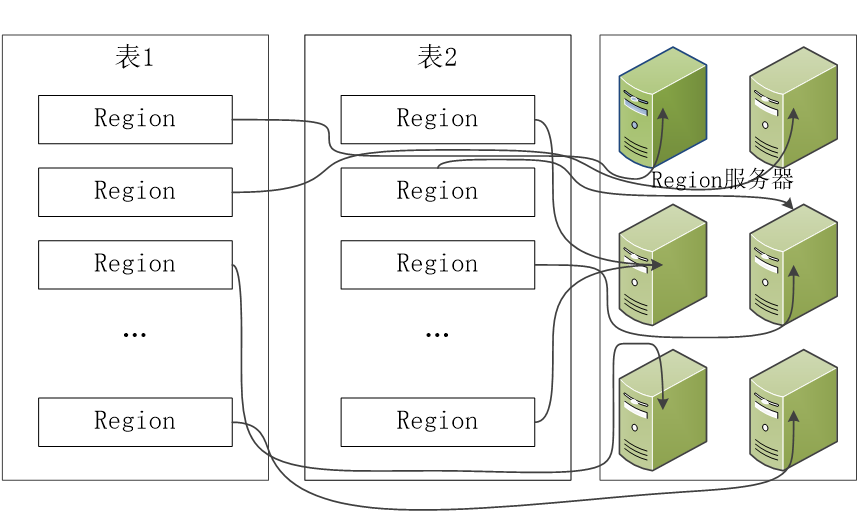
1.3 Region的定位
-
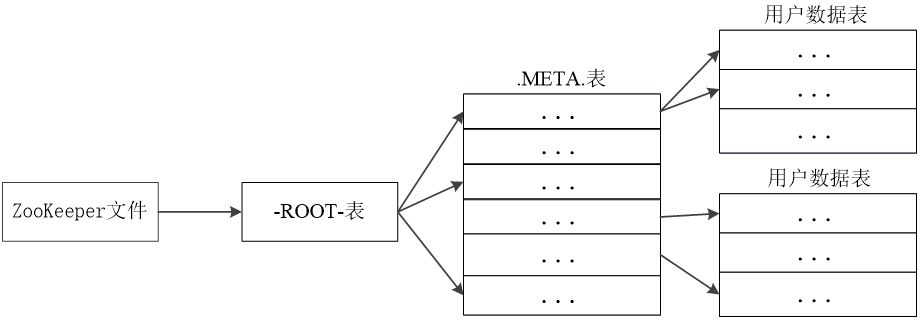
元数据表,又名.META.表,存储了Region和Region服务器的映射关系
-
当HBase表很大时, .META.表也会被分裂成多个Region
-
根数据表,又名-ROOT-表,记录所有元数据的具体位置
-
-ROOT-表只有唯一一个Region,名字是在程序中被写死的
-
Zookeeper文件记录了-ROOT-表的位置
-
为了加快访问速度,.META.表的全部Region都会被保存在内存中
-
假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为128MB,那么,上面的三层结构可以保存的用户数据表的Region数目的计算方法是:
-
(-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的 Region可以寻址的用户数据表的Region个数)
-
一个-ROOT-表最多只能有一个Region,也就是最多只能有128MB,按照每行(一个映射条目)占用1KB内存计算,128MB空间可以容纳128MB/1KB=217行,也就是说,一个-ROOT-表可以寻址217个.META.表的Region。
-
同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是128MB/1KB=217。
-
最终,三层结构可以保存的Region数目是(128MB/1KB) × (128MB/1KB) = 234个Region
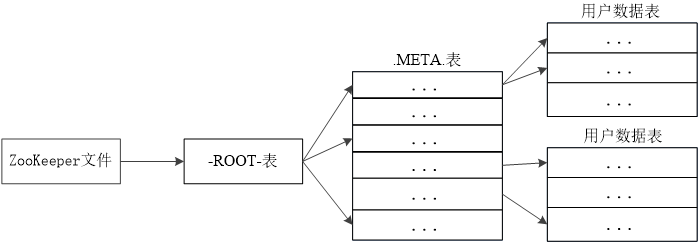
客户端访问数据时的“三级寻址” -
为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题
-
寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器
2. HBase运行机制
2.1 HBase系统架构
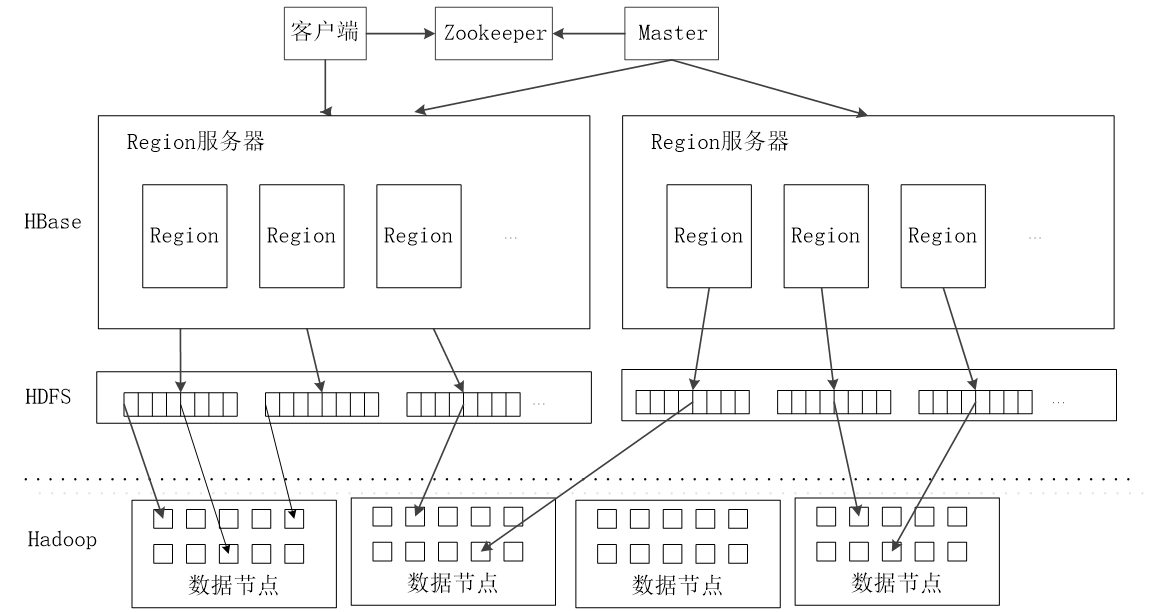
- 客户端
客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程 - Zookeeper服务器
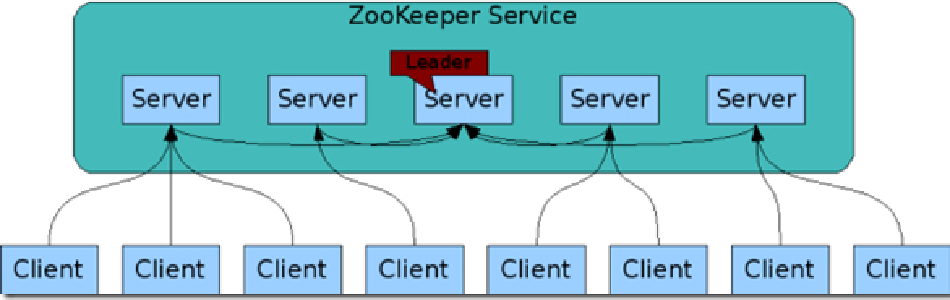
Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题
Zookeeper是一个很好的集群管理工具,被大量用于分布式计算,提供配置维护、域名服务、分布式同步、组服务等。
-
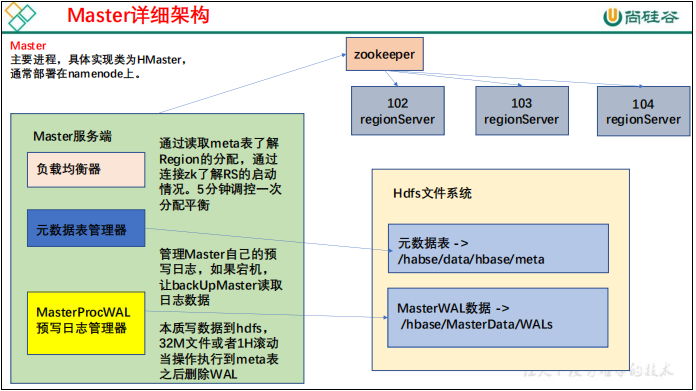
Master
主服务器Master主要负责表和Region的管理工作:- 管理用户对表的增加、删除、修改、查询等操作
- 实现不同Region服务器之间的负载均衡
- 在Region分裂或合并后,负责重新调整Region的分布
- 对发生故障失效的Region服务器上的Region进行迁移
-
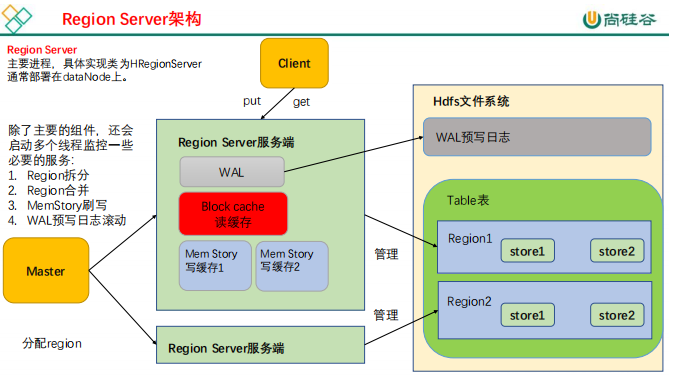
Region服务器
- 负责数据 cell 的处理,例如写入数据 put,查询数据 get 等
- 拆分合并 region 的实际执行者,有 master 监控,有 regionServer 执行。
2.2 Region服务器工作原理
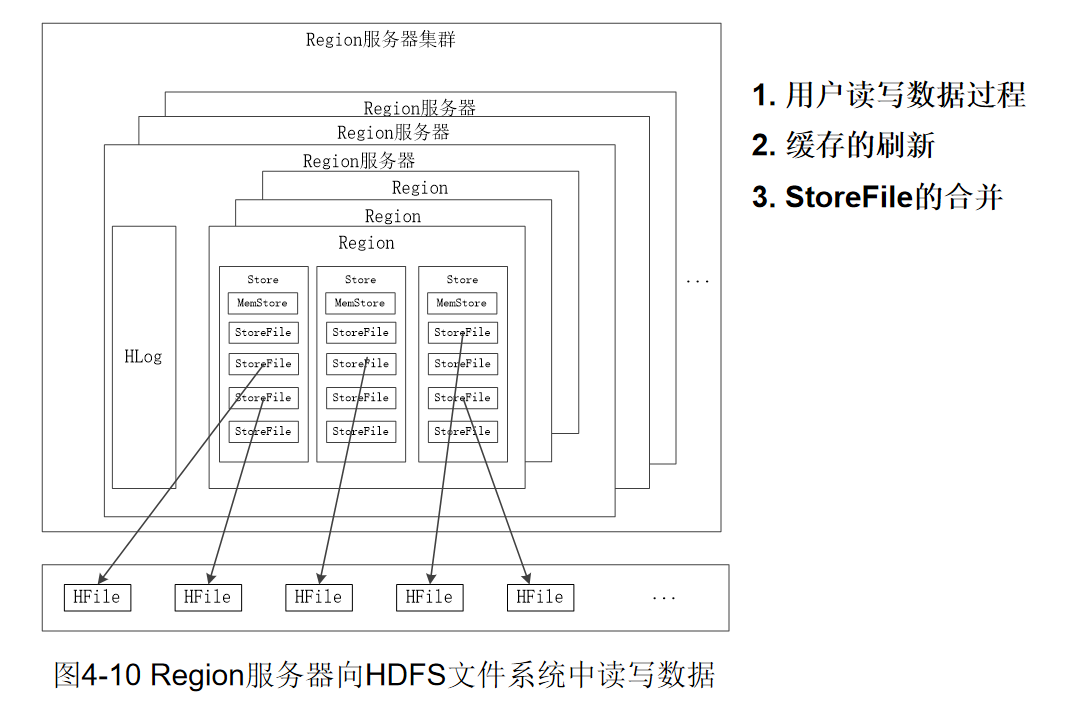
-
用户读写数据过程
- 用户写入数据时,被分配到相应Region服务器去执行
- 用户数据首先被写入到MemStore(缓存)和Hlog(日志)中,Hlog先写入,memstore后写入。
- 只有当操作写入Hlog之后,commit()调用才会将其返回给客户端
- 当用户读取数据时,Region服务器会首先访问MemStore缓存,如果找不到,再去磁盘上面的StoreFile中寻找
-
缓存的刷新
- 系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记
- 每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件(那storefile太多了如何减少呢?)
- 每个Region服务器都有一个自己的HLog 文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务
-
StoreFile的合并
- 每次刷写都生成一个新的StoreFile,数量太多,影响查找速度
- 调用Store.compact()把多个合并成一个
- 合并操作比较耗费资源,只有数量达到一个阈值才启动合并
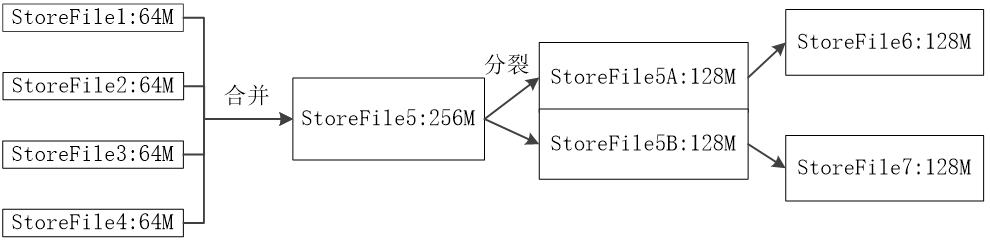
2.3 Store工作原理
Store是Region服务器的核心
多个StoreFile合并成一个
单个StoreFile过大时,又触发分裂操作,1个父Region被分裂成两个子Region
2.4 HLog工作原理
- 分布式环境必须要考虑系统出错。HBase采用HLog保证系统恢复
- HBase系统为每个Region服务器配置了一个HLog文件,它是一种预写式日志(Write Ahead Log)
- 用户更新数据必须首先写入日志后,才能写入MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘,该缓存内容才能被刷写到磁盘
- Zookeeper会实时监测每个Region服务器的状态,当某个Region服务器发生故障时,Zookeeper会通知Master
- Master首先会处理该故障Region服务器上面遗留的HLog文件,这个遗留的HLog文件中包含了来自多个Region对象的日志记录
- 系统会根据每条日志记录所属的Region对象对HLog数据进行拆分,分别放到相应Region对象的目录下,然后,再将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器
- Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入到MemStore缓存中,然后,刷新到磁盘的StoreFile文件中,完成数据恢复
- 共用日志优点:提高对表的写操作性能;缺点:恢复时需要分拆日志
3. HBase应用方案
3.1 HBase实际应用中的性能优化方法
-
行键(Row Key)
行键是按照字典序存储,因此,设计行键时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为行键的一部分,由于是字典序排序,所以可以使用Long.MAX_VALUE - timestamp作为行键,这样能保证新写入的数据在读取时可以被快速命中。 -
InMemory
创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到Region服务器的缓存中,保证在读取的时候被cache命中。 -
Max Version
创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1)。 -
Time To Live
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(2 * 24 * 60 * 60)。
3.2 HBase性能监视
-
Master-status(自带)

HBase Master默认基于Web的UI服务端口为60010,HBase region服务器默认基于Web的UI服务端口为60030.如果master运行在名为master.foo.com的主机中,mater的主页地址就是http://master.foo.com:60010,用户可以通过Web浏览器输入这个地址查看该页面可以查看HBase集群的当前状态。 -
Ganglia
Ganglia是UC Berkeley发起的一个开源集群监视项目,用于监控系统性能
-
OpenTSDB
OpenTSDB可以从大规模的集群(包括集群中的网络设备、操作系统、应用程序)中获取相应的metrics并进行存储、索引以及服务,从而使得这些数据更容易让人理解,如web化,图形化等
-
Ambari
Ambari 的作用就是创建、管理、监视 Hadoop 的集群