一、关于Requests和xpath
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、 冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。 XPath 是一门在XML文档中查找信息的语言。XPath 可用来在 XML 文档 中对元素和属性进行遍历。XPath是W3CXSLT标准的主要元素,并且XQuery 和XPointer都构建于XPath表达之上。因此,对XPath的理解是很多高级XML 应用的基础。
1.requests功能特性
1)Requests完全满足今日web的需求。
2)Keep-Alive & 连接池
3)国际化域名和 URL
4)带持久 Cookie 的会话
5)浏览器式的 SSL 认证
6)自动内容解码
7)基本/摘要式的身份认证
8)优雅的 key/value Cookie
9)自动解压
10)Unicode 响应体

11)HTTP(S) 代理支持
12)文件分块上传
13)流下载
14)连接超时
15)分块请求
16)支持.netrc Requests支持Python2.6—2.7以及3.3—3.7,而且能在PyPy下完美运行。
2.安装Requests和lxml
pip install requests
pip install lxml
3.xpath安装
在chrome浏览器上搜索xpath helper,google商城会自动跳出是否安装到浏览器,点击确认即可。
二、爬虫流程
1)找到数据所在url->发送请求->请求成功->接收数据
2)解析数据
3)保存数据
三、爬取茅台官网财务报告
1)确定网址
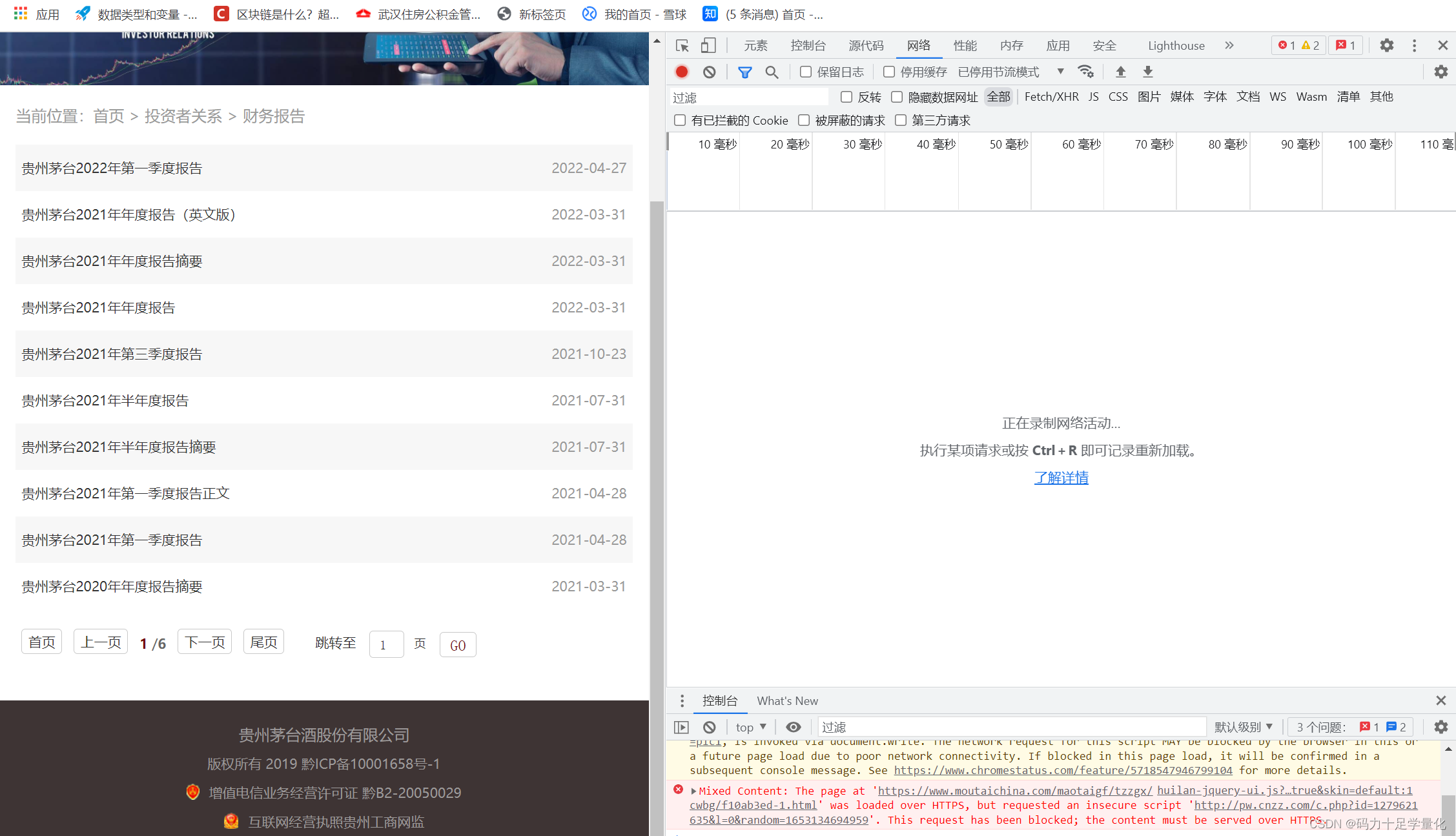
①建议使用Chrome浏览器,按一下F12,会跳出开发者工具界面如下:
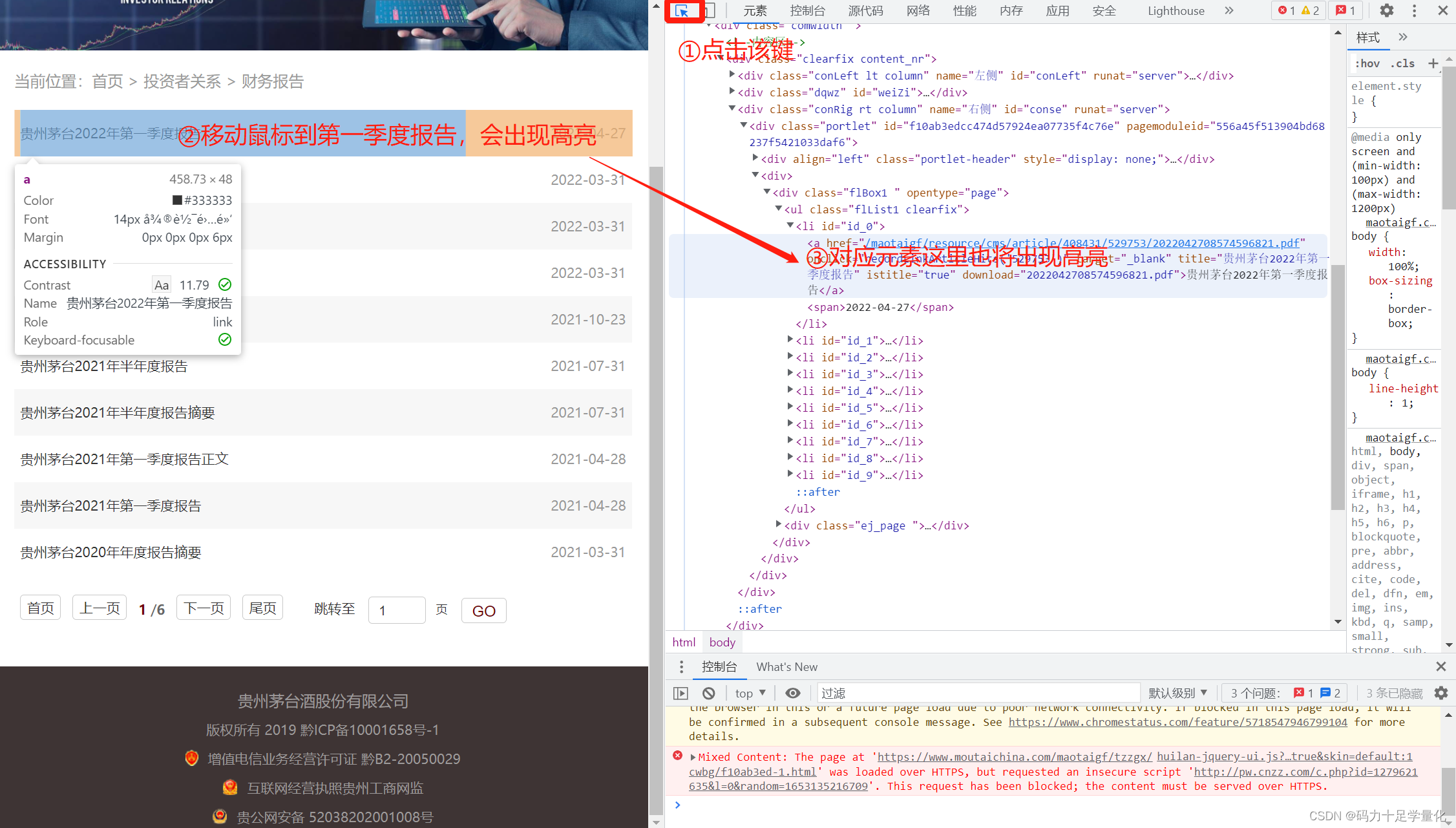
②点击检查按键,移动鼠标到目标文件,可看到元素里对应的内容也出现高亮。
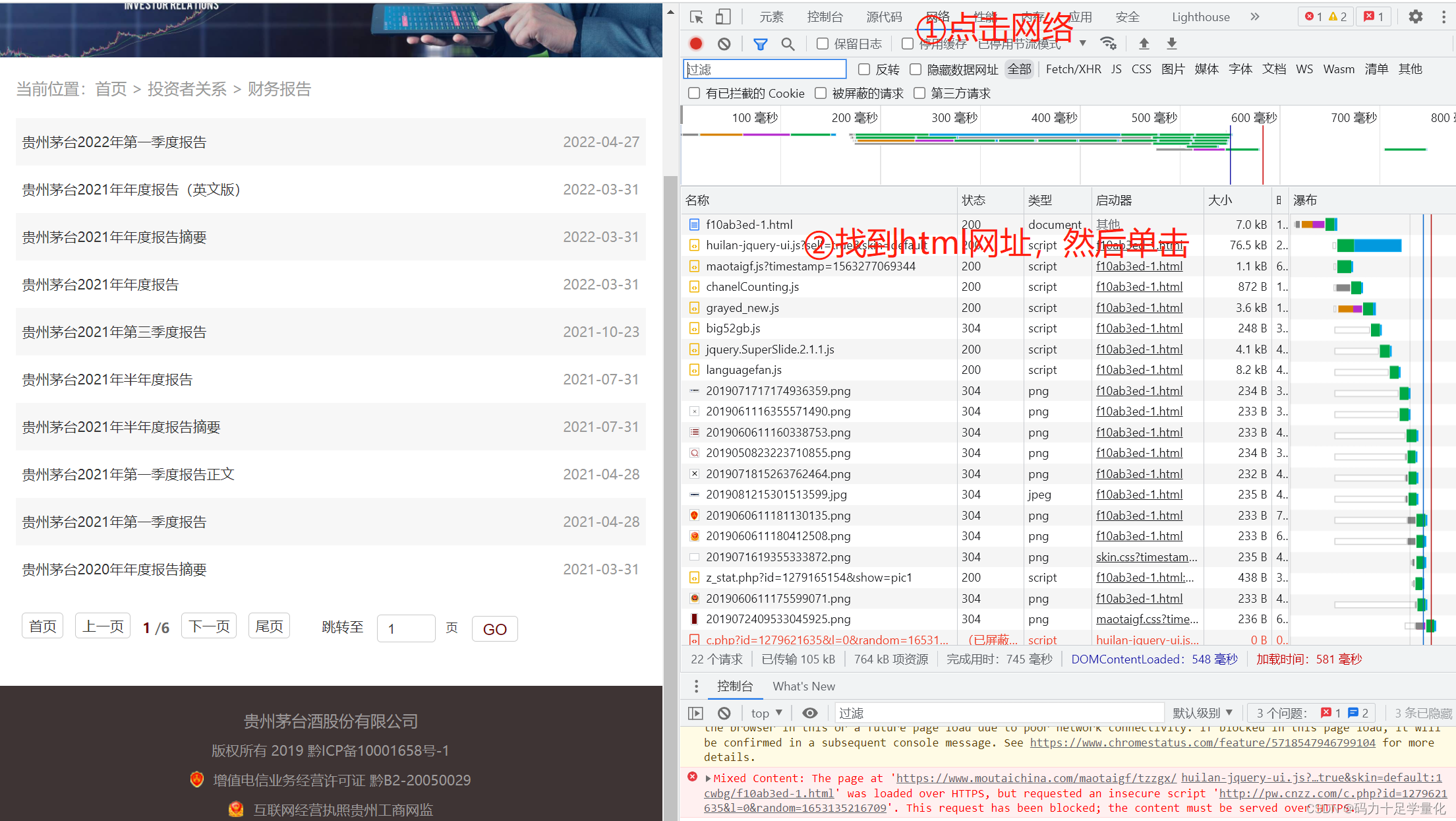
③单击网络图标,然后找到html文件,单击一下,即可出现标头,找到里面的请求网址,
这就是我们需要的网址。
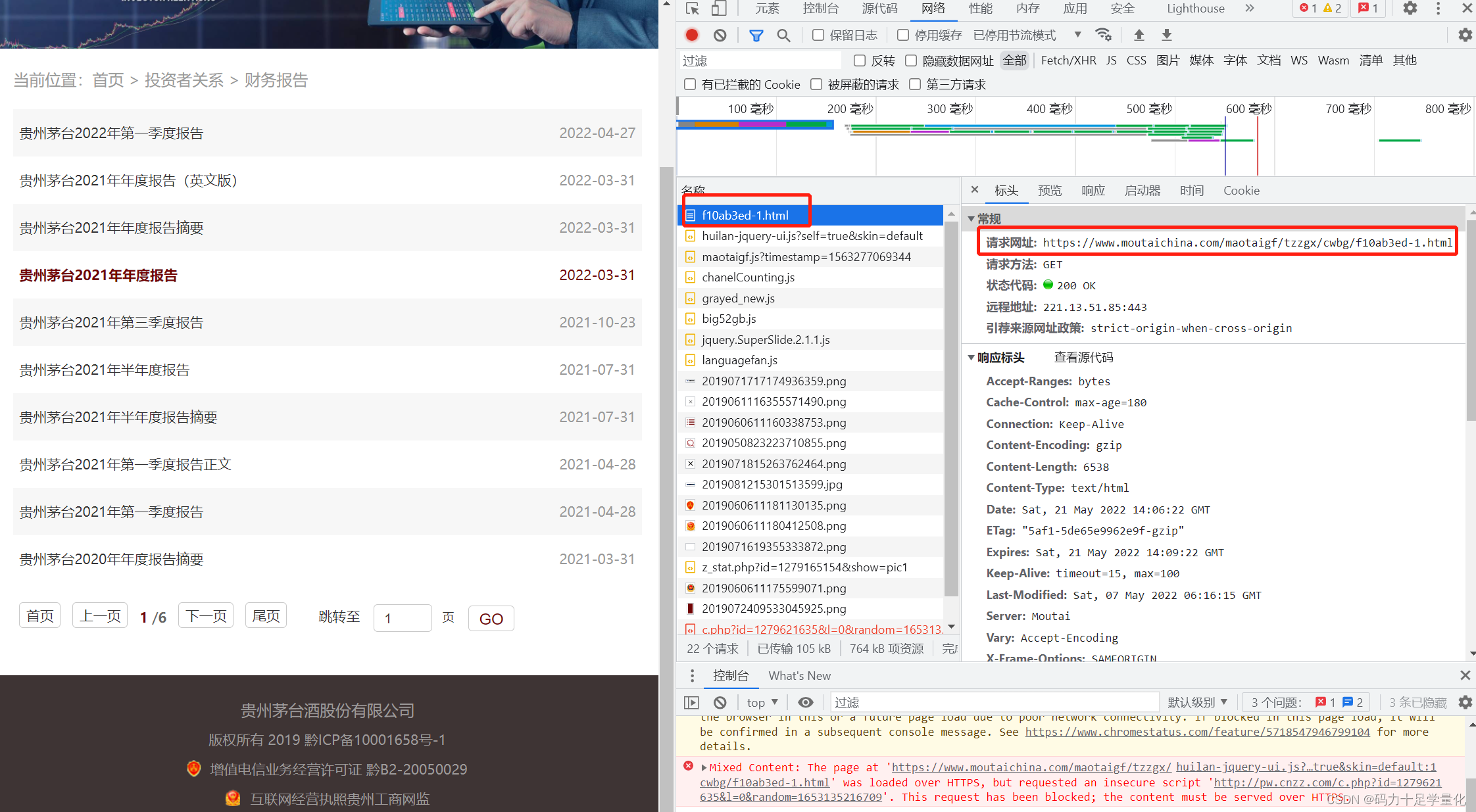
④以此类推,我们可以找出6页财务报告的网址如下:
第一页:https://www.moutaichina.com/maotaigf/tzzgx/cwbg/f10ab3ed-1.html
第二页:https://www.moutaichina.com/maotaigf/tzzgx/cwbg/f10ab3ed-2.html
第三页:https://www.moutaichina.com/maotaigf/tzzgx/cwbg/f10ab3ed-3.html
第四页:https://www.moutaichina.com/maotaigf/tzzgx/cwbg/f10ab3ed-4.html
第五页:https://www.moutaichina.com/maotaigf/tzzgx/cwbg/f10ab3ed-5.html
第六页:https://www.moutaichina.com/eportal/ui?pageId=408431¤tPage=6&moduleId=f10ab3edcc474d57924ea07735f4c76e&staticRequest=yes
⑤ 给对应网址发送请求
import requests
url="https://www.moutaichina.com/maotaigf/tzzgx/cwbg/f10ab3ed-1.html"
response=requests.get(url=url,timeout=30)
print(response.text)
⑥ 输出结果,出现乱码
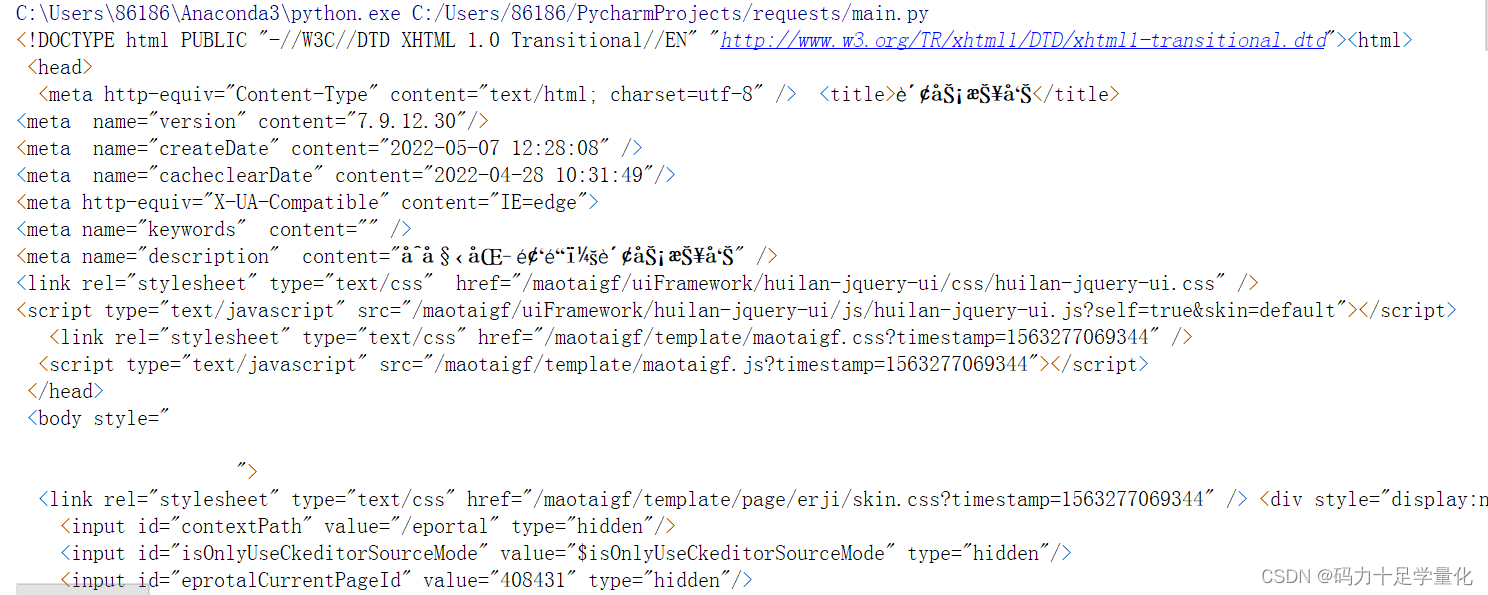
# 获取对应编码
response.encoding=response.apparent_encoding
⑦ 乱码问题解决
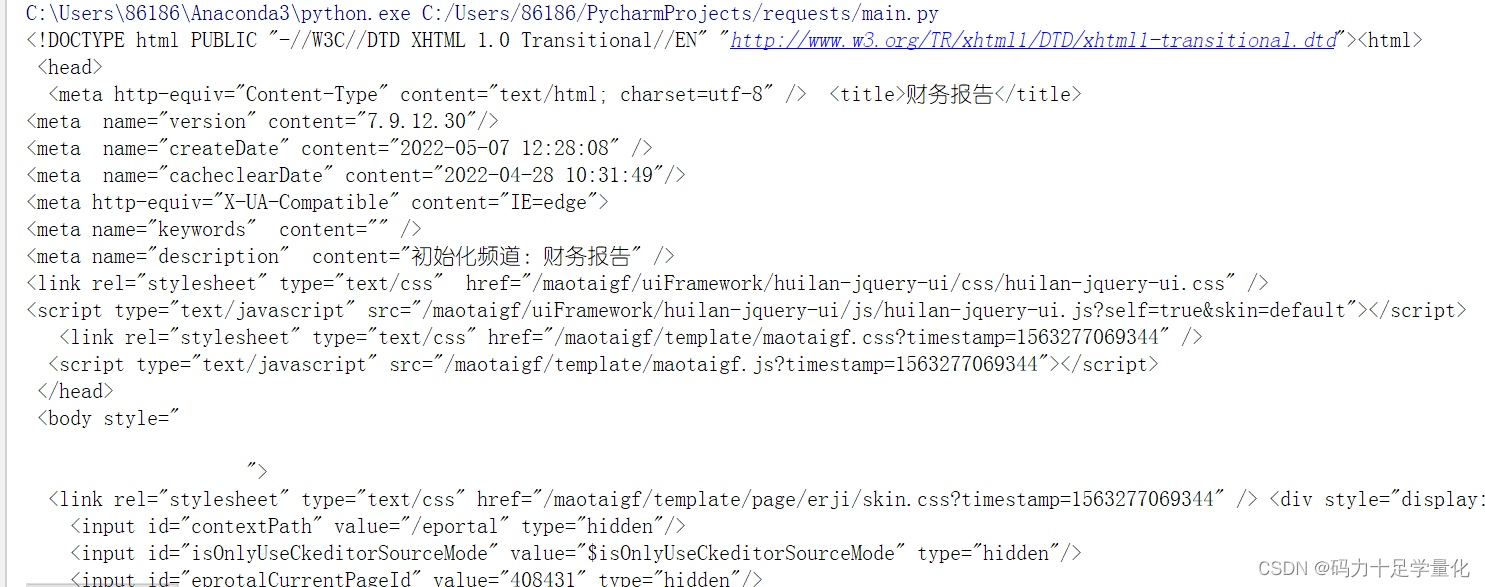
2)解析页面
from lxml import etree
# 将文本数据转换为HTML对象
mt_html=etree.HTML(mt_html)
① 利用xpath提取信息
a.点击chrome浏览器右上角拓展程序按钮,单击xpath出现如下画面。
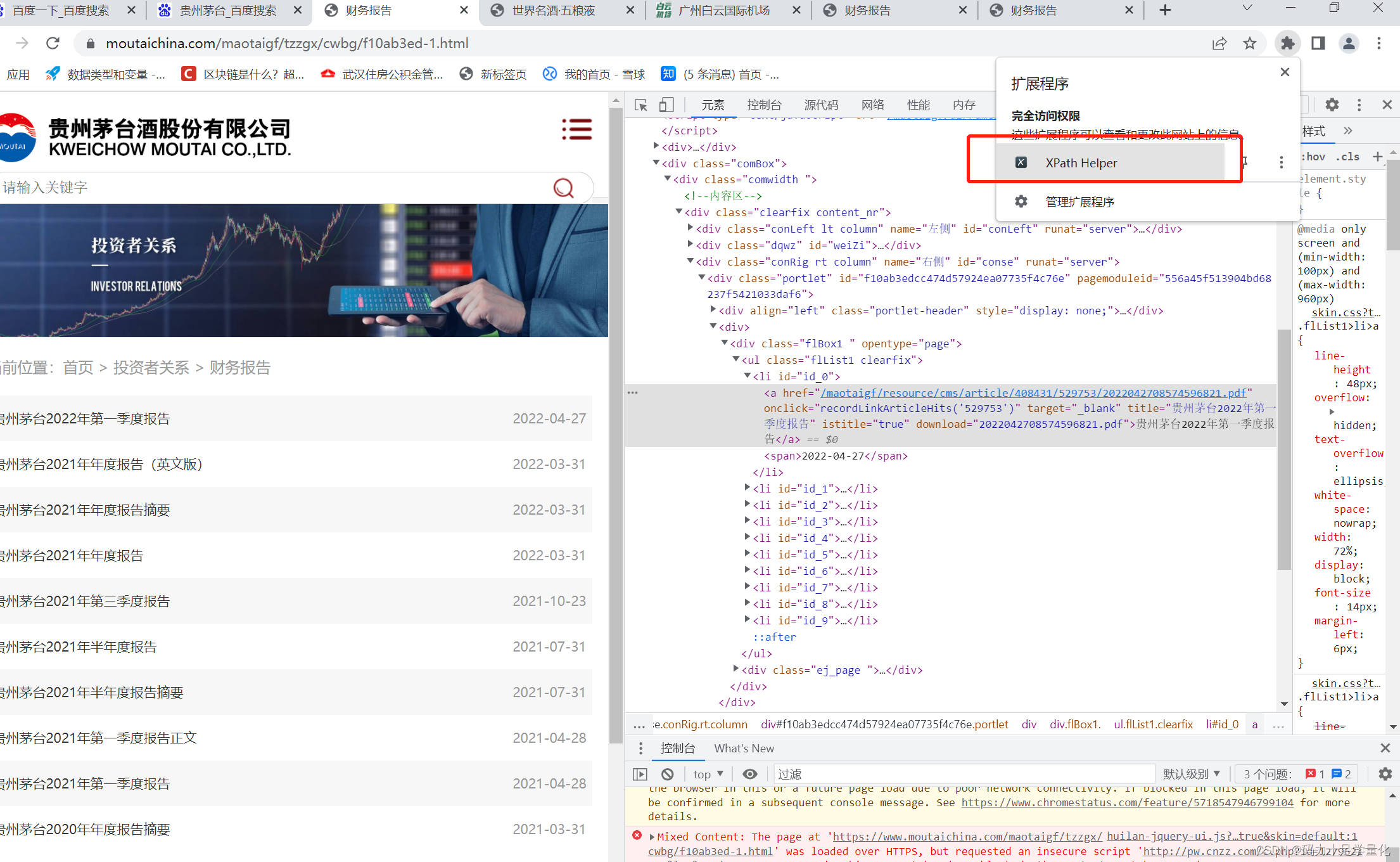
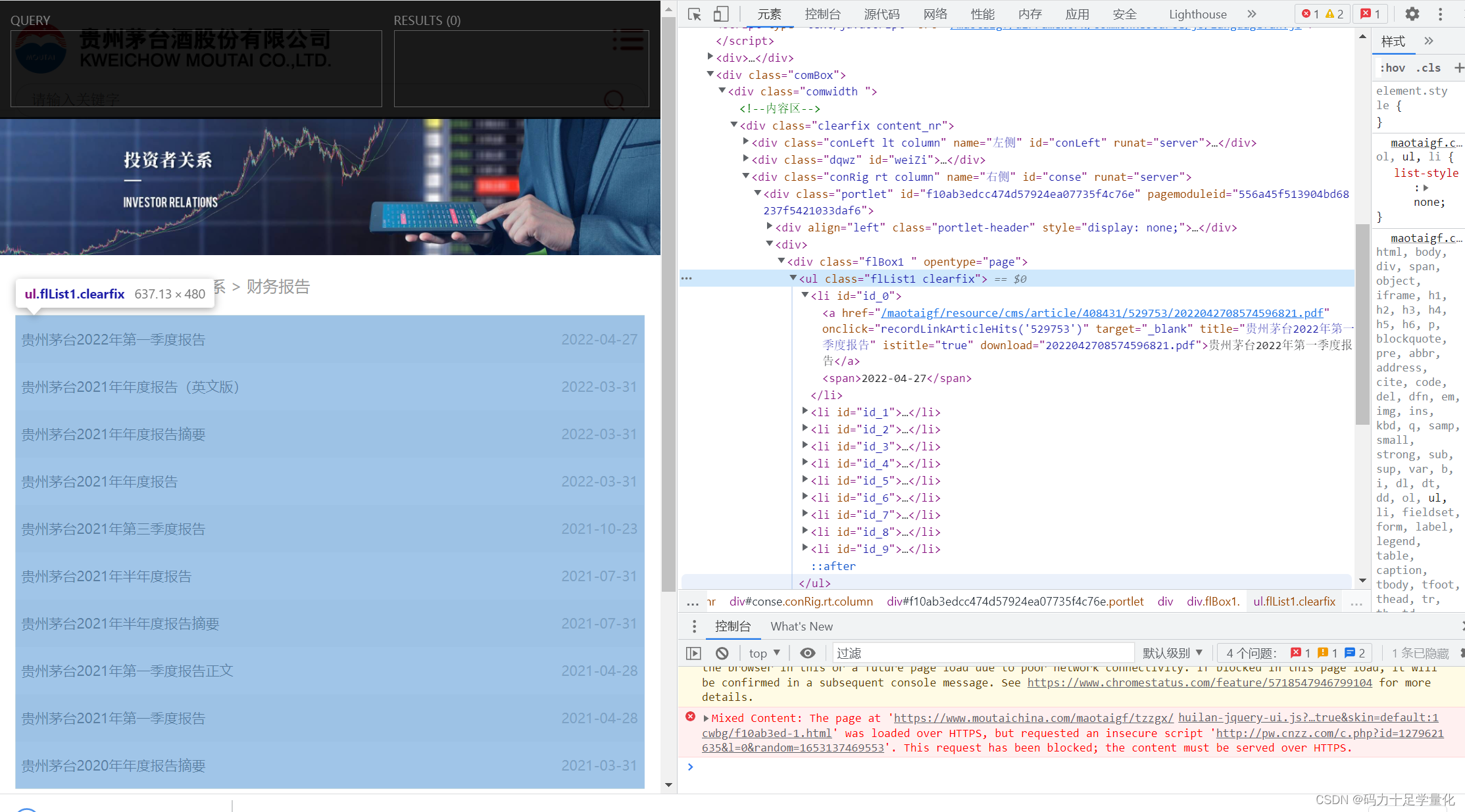
b.右击需要复制的标签,选择复制xpath

c.进一步完成xpath路径,定位到下载连接
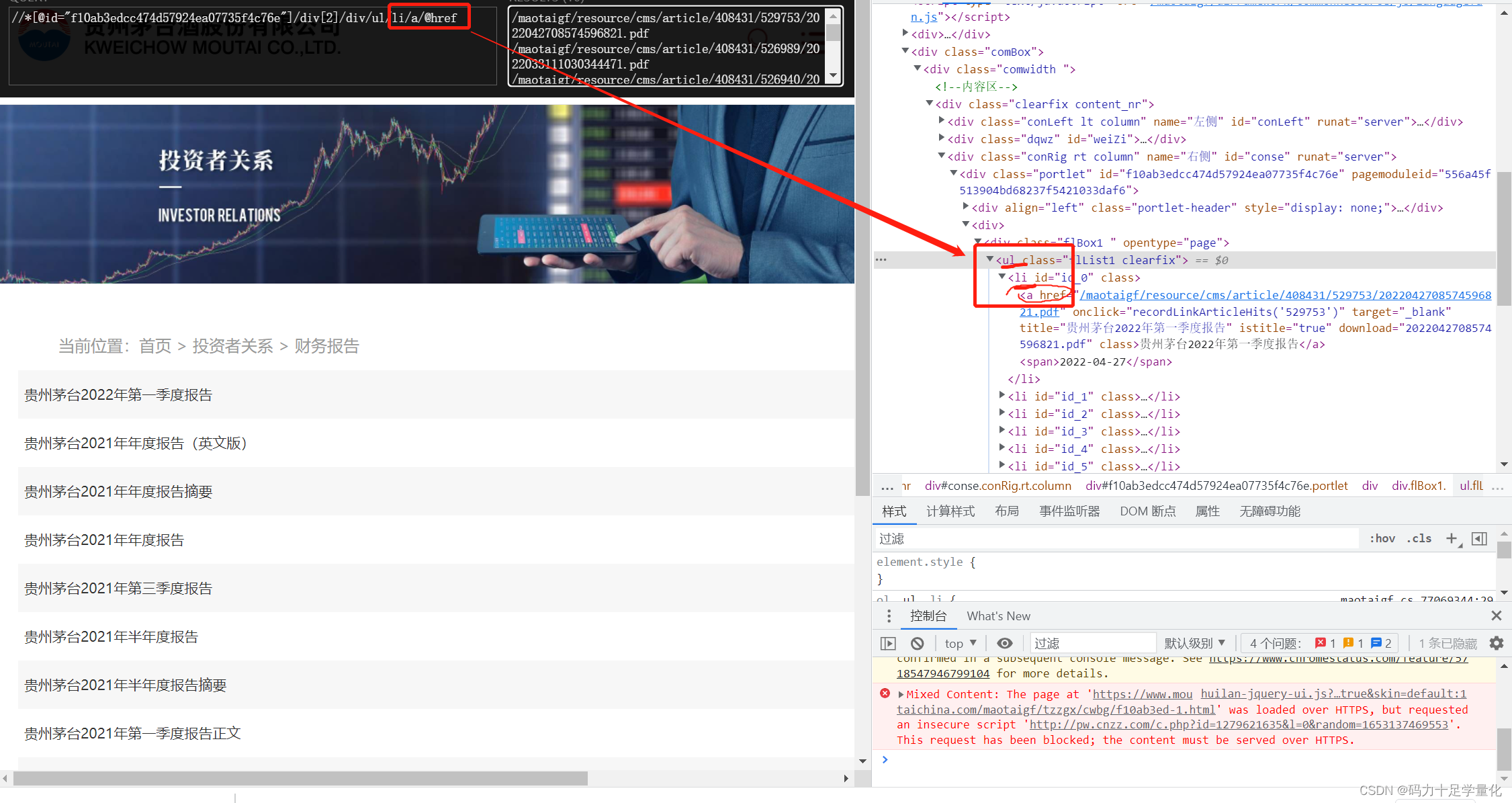
# 提取出url(pdf连接)
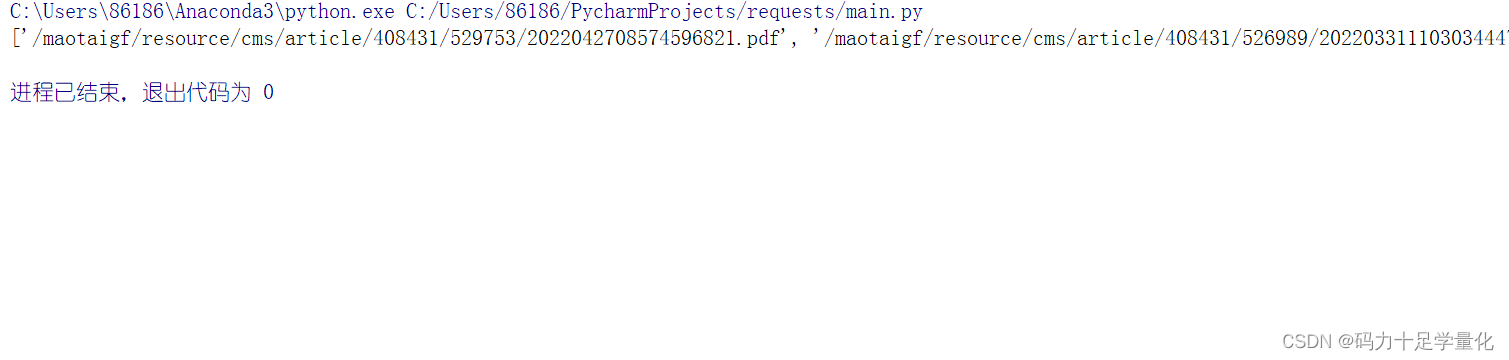
href_list = mt_html.xpath('//*[@id="f10ab3edcc474d57924ea07735f4c76e"]/div[2]/div/ul/li/a/@href')
print(href_list)
输出结果
d.同理获取文件名
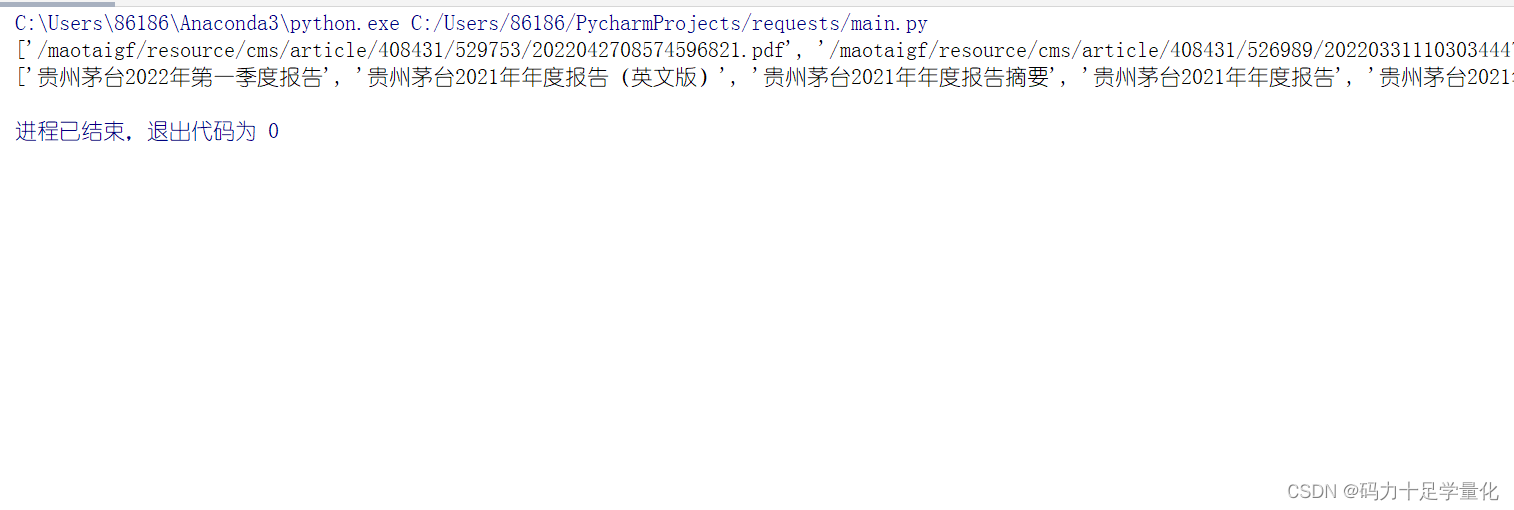
# 提取文件名
title_list=mt_html.xpath('//*[@id="f10ab3edcc474d57924ea07735f4c76e"]/div[2]/div/ul/li/a/@title')
② 拼接网址
将列表种的元素逐个去除,进行字符串拼接
for i in range(len(href_list)):
print(i)
# 网址拼接
url="https://www.moutaichina.com/"+href_list[i]
# pdf-->数据 二进制数据.content
pdf_content=requests.get(url).content
输出结果,二进制结果

③文件路径
save_path=r"..\\requests\\财务报表\\"+title_list[i]+".pdf"
④保存数据
步骤:打开文件,写入数据,关闭文件
with open(save_path,"wb") as f:
"""
写入二进制形式
--------- ---------------------------------------------------------------
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
'U' universal newline mode (deprecated)
========= ===============================================================
"""
f.write(pdf_content)
print(f"下载{
title_list[i]}.pdf成功...")
三、完整代码

输出结果

4)处理财务报告网址
对比6页财务报告信息,我们发现其前五页网址只有页面不同,第六页则与其他不同,那么我们只需要对这6个网址进行处理即可。

5)完整代码



6)总结 如此便可下载所有财务报告,如需要源码,可私聊,对量化投资感兴趣的,欢迎交流。