本节内容给出基于CTC和基于注意力机制的两种场景文本识别方法,并给出各自的优势与局限性
3.2.2.1 基于CTC的无需分割的场景文本识别方法
基于时序连接序列(CTC)的自然场景文本识别算法。
时序连接序列(CTC)算法早期由Graves等人(2016)提出,用以训练循环神经网络(Cho 等,2014;Hochreiter 和Schmidhuber,1997),并直接标记未分割的特征序列。CTC 算法在多个领域均证明了它的优异性能,例如语音识别(Graves 等,2013;Graves 和Jaitly,2014)和联机手写文本识别(Graves等,2009;Graves,2012)。
对于自然场景文本识别言,CTC 算法通常作为转录层,通过计算条件概率将深度卷积神经网络或循环神经网络提取的特征序列直接解码为目标字符串序列。 得益于CTC 算法在语音处理领域的成功应用,一些研究人员(Su 和Lu,2014;He 等,2016b;Shi 等,2017b)率先将其应用于自然场景文本识别算法中以改善解码性能。例如,Shi 等人(2017b)将自然场景文本识别任务视为序列识别任务,并提出了一个可端到端训练的网络模CRNN(convolutional recurrent neural network),其结构如图 所示。
该方法不仅无需逐字符分割的繁复操作,而且充分结合了深度卷积神经网络和循环神经网络的优点,有效改善了自然场景文本识别算法的性能。此后,大量基于CTC 算法解码的自然场景文本识别算法(Liu等,2016b; Su 和Lu,2017; Yin 等,2017; Wang 和Hu,2017;Gao 等,2018,2019;Qi 等,2019)展现出了优秀的识别性能。然而,一些研究人员(Liu 等,2018a)认为CTC 算法趋向于产生高度尖锐和过度自信的预测分布,这是过拟合的表现。为了解决上述难点,Liu 等人(2018a)引入最大条件熵的正则化项增强其泛化性,并鼓励CTC 算法探索更多可行的有效路径。Feng 等人(2019b)将CTC 算法与焦点损失函数相融合,以解决样本类别极度不均衡的自然场景文本识别问题。Hu 等人(2020)应用图卷积神经网络改善基于CTC 算法解码的自然场景文本识别算法的识别精度和鲁棒性。
虽然CTC 算法具有很好的解码性能,并进一步推动了自然场景文本识别领域的发展,但是它也面临着一些局限性:
(1)CTC 算法的底层理论基础相对复杂,直接应用CTC 算法解码将会造成很大的计算消耗;
(2)CTC 算法容易产生高度尖锐和过度自信的预测分布(Miao 等,2015),当出现重复字符时,解码性能下降;
(3)由于CTC 算法自身结构和实现方式的限制,它很难应用于2 维的预测问题,例如不规则的自然场景文本识别问题(不规则的自然场景文本识别是指待识别的文本在自然场景文本图像中的分布呈现特殊的空间结构而非水平方向)。
为了解决CTC 算法无法应用于不规则的自然场景文本识别任务,Wan 等人(2019)通过沿着高度方向增加维度,扩展原始的CTC 算法。尽管该方法在一定程度上改善了识别性能,但是并没有从根本上解决CTC 算法应用于二维预测任务的难点。因此,基于CTC 的自然场景文本识别算法仍然存在使用场景的限制。将CTC 算法应用于解决2 维预测问题是未来领域研究中一个有潜力的研究方向。
3.2.2.2基于注意力机制的无需分割的场景文本识别方法
基于注意力机制的自然场景文本识别算法。
注意力机制由Bahdanau 等人(2015)提出,早期用于改善机器翻译算法的性能。注意力机制以人类的注意力特点为原型,即当人们在观察事物时,目光往往聚焦到感兴趣的事物上而忽略无用信息的干扰。同样地,注意力机制可以自动地分配不同时刻的权重,达到“注意”的目的。在机器翻译领域,注意力机制的特点是可以自动搜寻并高亮与当前预测词相关的句子成分,辅助生成预测词。近年来,注意力机制在多个领域都取得了优异的性能,例如图像描述(He等,2019)、文本识别(Shi 等,2019)和遥感图像分类(Wang 等,2019d) 等。对于自然场景文本识别而言,注意力机制常常与循环神经网络结合使用,作为转录层,生成目标字符串序列。
受启发于机器翻译领域注意力机制的成功应用,大量基于注意力机制解码的自然场景文本识别算法(Lee 和Osindero,2016;Shi 等,2016,2019;Yang等,2017,2019;Cheng 等,2018;Luo 等,2019;Li 等,2019; Zhan 等, 2019; Zhang 等, 2019b; Baek 等,2019a;Zhan 和Lu,2019)得到广泛研究。相关算法大致包括:
(1)应用注意力机制解决二维的预测问题。对于不规则的自然场景文本识别而言,文本字符的不规则排布显著增加了识别的难度。注意力机制能够通过高亮字符所在位置的特征,有效弥补不规则文本和水平平直文本之间的特征差异。因此,一些研究人员(Yang 等,2017;Li 等,2019;Huang等,2020)提出了2 维的注意力机制,用于改善不规则自然场景文本识别问题。
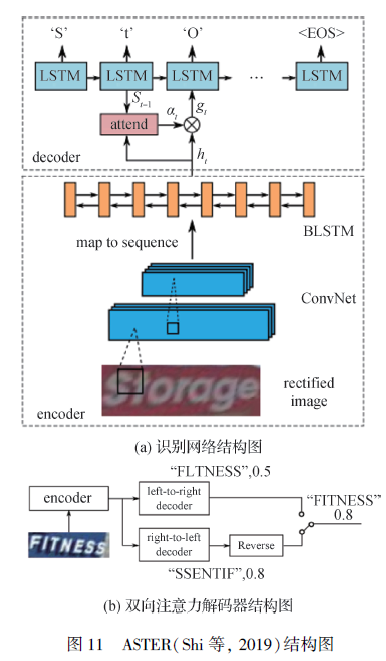
(2)改善隐式语言模型的建模过程。一些研究认为注意力机制解码算法中的glimpse 向量不足以表征待预测字符的特征。因此,Chen 等人(2020)设计了自适应的门控机制,通过引入高阶统计语言模型作为监督信息,改善注意力机制内部字符级隐式语言模型的建模过程。__Wang 等人(2018a)通过加入历史预测字符的特征, 构建了记忆力增强的注意力机制,改善自然场景文本识别算法的识别性能。Shi 等人(2019)认为常规的基于注意力机制的预测转录模块只能捕获单一方向的语义信息,因此提出了ASTER(attentional scene text recognizer with flexible rectification),它使用了双向的注意力解码器以捕获两个方向的互补语义特征,其网络及双向的注意力解码器结构如图11 所示。
(3)并行处理优化、降低计算复杂度。虽然基于循环神经网络结构的注意力机制能够捕获长期的上下文信息,但是计算量大、耗时较多。因此,一些研究(Zhu 等,2019;Wang 等,2019b;Sheng 等,2019;Yu 等,2020)应用注意力机制的变体,即Transformer(Vaswani,2017),来改善注意力机制的并行处理,降低基于注意力机制解码的自然场景文本识别算法的计算复杂度。
(4)解决注意力漂移问题。注意力漂移问题是指注意力机制不能准确地定位到与当前解码位置相对应的文本图像特征序列。一些研究(Cheng 等,2017;Yue 等,2020)增加额外的监督信息改善注意力漂移现象。Cheng 等人(2017)提出了专注注意力网络。该方法通过在注意力机制中引入单字符位置监督,引导识别器学习待解码字符与对应的文本图像特征序列的对齐关系。Yue 等人(2020)增加了位置强化分支,将语义信息与位置信息特征融合解码。该方法不仅改善了注意力漂移问题,而且改善了识别模型对于非语义文本的泛化性。
部分研究人员(Wang 等,2019c;Huang 等,2020;Zhu等,2019)通过级联注意力模块的方式缓解注意力漂移现象。特别地,Wang 等人(2020b) 认为注意力漂移现象源于循环神经网络的递归结构。因此,他们将注意力机制的对齐操作从参照历史解码信息过程中解耦出来。该方法有效缓解了长文本的注意力漂移问题,进一步改善了自然场景文本识别性能。
基于注意力机制的自然场景文本识别算法已经逐渐成为领域的主流解码算法,并展现了优于其他传统方法的优越性能。相比于CTC 算法,注意力机制不仅进一步提升了自然场景文本识别算法的识别性能,而且可以很容易地扩展到2 维的预测问题上,例如不规则自然场景文本识别任务。
然而,注意力机制也面临着一些局限性:
(1)注意力机制需要计算文本图像特征与预测字符之间的对齐关系,这会引入额外的存储消耗。
(2)对于较长的输入文本图像而言,注意力机制很难准确地预测出目标字符串序列。因为注意力机制存在漂移现象,一旦出现对齐错误,后续的文本很难正确识别。
(3)领域中基于注意力机制解码的自然场景文本识别算法主要集中于字符类别数量较少的语种,例如英文和法文。对于拥有类别字符数量的语种,例如中文,较少获得领域内研究人员的关注。