文本识别
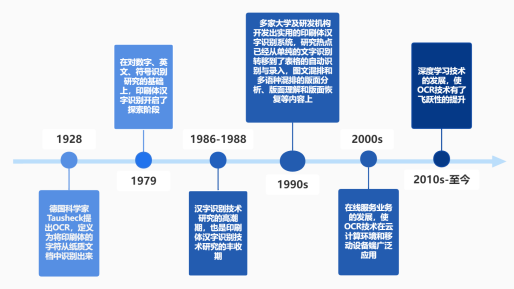
俗称光学字符识别,英文全称是Optical Character Recognition(简称OCR),它是利用光学技术和计算机技术把印刷体或手写体文本进行读取识别,转化成计算机和人都能够识读的格式。此间OCR技术是关键一环。OCR技术中,印刷体的文本识别是最成熟的一个,因其开展最早。早在1929年就被欧美国家利用来处理大量的报刊杂志、文件和单据报表等。经过40多年的发展和完善,文本识别技术更加成熟,逐步实现了信息处理的“电子化”。
1979 - 1985年汉字OCR进入探索阶段
在对数字、英文、符号识别研究的基础上,自上世纪70年代末,国内就有少数单位的研究人员对汉字识别方法进行了探索,发表了一些论文,研制了少量模拟识别软件和系统。这个阶段漫长,成果不多,但是却孕育了下一个阶段的丰硕果实。
1986年初到1988年底,是汉字识别技术研究的高潮期
也是印刷体汉字识别技术研究的丰收期。总共有11个单位进行了14次印刷体汉字识别的成果鉴定,这些系统对样张识别能达到高指标:可以识别宋体、仿宋体、黑体、楷体,识别的字数最多可达6763个,字号从3号到5号,识别率高达99.5%以上,识别速度在286微机条件下能够达到10~14字/秒,但对真实文本识别率大大下降,这是由于以上系统对印刷体文本形状变化(如文本模糊、笔划粘连、断笔、黑白不均、纸质质量差、油墨反透等等)的适应性和抗干扰性比较差造成的。但是这三年研制的识别系统为印刷体汉字识别系统的实用化打下了基础,是识别系统从研制到实用化必经的过程。
印刷体汉字识别(文本识别)自1986年掀起高潮以来,清华大学电子工程系、中国科学院计算所智能中心、北京信息工程学院、沈阳自动化研究所等多家单位分别研制并开发出了实用化的印刷体汉字识别系统。尤其是由清华大学电子工程系研制的清华TH一OCR产品和由汉王集团开发的尚书OCR产品,它们始终都处于技术发展的最前沿,并占据着最大的市场份额,代表着印刷体汉字识别技术的发展潮流。目前,印刷体汉字识别技术的研究热点已经从单纯的文本识别转移到了表格的自动识别与录入,图文混排和多语种混排的版面分析、版面理解和版面恢复,名片识别,金融票据识别和古籍识别等内容上。并且出现了许多相关的识别系统,如:文通科技推出的名片识别系统、身份证识别系统和“慧视”屏幕文本图像识别系统等等。这些新的识别系统的出现,标志着印刷体汉字识别技术的应用领域得到了广阔的扩展。
2000年以后在线服务业务高速发展
OCR技术在云计算环境和移动设备端得到了广泛的应用。随着近年深度学习的不断发展,基于神经网络的OCR技术打破了传统OCR技术的框架,在识别效率以及准确率上都有了质的飞跃。