3.1.3 常用的文本检测模型
R-CNN、Fast R-CNN、Faster R-CNN
1)R-CNN(CVPR 2014, TPAMI 2015)
2014年论文《Rich feature hierarchies for accurate object detection and semantic segmentation Tech report》提出R-CNN模型,即Regions with CNN features。这篇论文可以算是将CNN方法应用到目标检测问题上的开山之作。
R-CNN的算法原理:

RCNN算法分成四个步骤:
(1)获取输入图像
(2)提取大约2000个自下而上的候选区域
(3)使用大型卷积神经网络(CNN)计算每个建议的特征
(4)使用特定分类的线性支持向量机(SVM)对每个区域进行分类。
实验结果:
表1显示了VOC 2010数据集上的实验完整结果。实验将R-CNN方法与四个强Baseline进行了比较,其中包括SegDPM,它将DPM检测器与语义分割系统的输出相结合,并使用额外的检测器间上下文和图像分类器重新排序。最密切的比较是与Uijlings等人研究的UVA系统,因为R-CNN的系统使用相同的区域候选算法。为了对区域进行分类,UVA的方法构建了一个四级空间金字塔,并使用密集采样的SIFT、扩展的OpponentSIFT和RGBSIFT描述符对其进行填充,每个向量使用4000字的码本进行量化。采用直方图相交核支持向量机进行分类。与UVA的多特征非线性核SVM方法相比,R-CNN在mAP方面取得了很大的改进,从35.1%提高到53.7%,同时速度也更快。R-CNN的方法在VOC 2011/12测试中达到了类似的性能(53.3%mAP)。
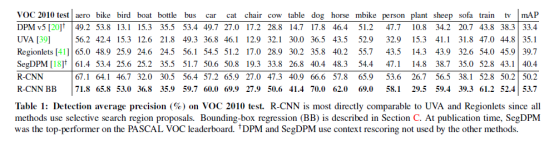
图3将R-CNN与ILSVRC 2013年比赛的参赛作品以及赛后的OverFeat结果进行了比较。R-CNN获得了31.4%的mAP,明显领先于OverFeat第二好的24.3%。为了了解AP在不同类别上的分布情况,还提供了方框图,并在表8中的文章末尾提供了一个perclass AP表。大多数竞争对手提交的资料(OverFeat、NEC-MU、UvAEuvision、Toronto A和UIUC-IFP)都使用了卷积神经网络,这表明CNN如何应用于目标检测存在显著差异,导致结果差异很大。

首先查看CNN不在PASCAL进行微调,即所有CNN参数仅在ILSVRC 2012上进行预训练后的结果。逐层分析性能(表2第1-3行)表明,fc7的特征概括起来比fc6的特征更差。这意味着,在不降低地图质量的情况下,可以删除29%或1680万个CNN参数。更令人惊讶的是,删除fc7和fc6会产生非常好的结果,尽管pool5功能仅使用CNN 6%的参数计算。CNN的大部分提取特征的能力来自其卷积层,而不是更大的密集连接层。这一发现表明,仅使用CNN的卷积层就可以计算任意大小图像的稠密特征图(从HOG的意义上讲)的潜在效用。这种表示方式将支持在pool5特性的基础上使用滑动窗口检测器(包括DPM)进行实验。
在VOC 2007 trainval上微调了CNN的参数后,现在来看一下CNN的结果。改进是惊人的(表2第4-6行):微调将mAP提高了8.0个百分点,达到54.2%。fc6和fc7的微调带来的提升要比pool5大得多,这表明从ImageNet学习到的pool5功能是通用的,大部分改进都是通过学习特定领域的非线性分类器获得的。
所有R-CNN变体的性能都明显优于三个DPMBaseline(表2第8-10行),包括使用功能学习的两个。与只使用HOG功能的最新版本DPM相比,R-CNN的mAP提高了20多个百分点:54.2%比33.7%,相对提高了61%。HOG和sketch令牌的组合比单独的HOG产生2.5个mAP,而HSC比HOG提高了4个mAP(与它们的专用DPM Baseline进行内部比较时,两者都使用性能低于开源版本的非公开DPM实现)。这些方法分别实现了29.1%和34.3%的MAP。

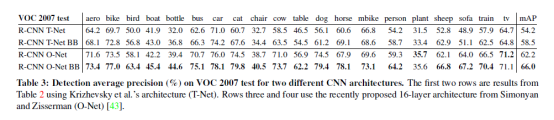
在表3中,实验展示了使用Simonyan和Zisserman最近提出的16层深度网络进行VOC 2007测试的结果。该网络是最近ILSVRC 2014分类挑战赛中表现最好的网络之一。该网络具有由13层3×3卷积核组成的同质结构,其中穿插有5个最大池层,顶部有3个完全连接的层。对于OxfordNet,实验将该网络称为“O-Net”,对于TorontoNet,实验将baseline称为“T-Net”。
为了在R-CNN中使用O-Net,实验从Caffe模型Zoo1下载了VGG ILSVRC 16层模型的公开预训练网络权重,然后使用与T-Net相同的协议对网络进行微调。唯一的区别是根据需要使用较小的小批量(24个示例),以适应GPU内存。表3中的结果表明,使用O-Net的RCNN显著优于使用T-Net的R-CNN,将mAP从58.5%增加到66.0%。然而,在计算时间方面有一个相当大的缺点,O-Net的向前传递大约比T-Net长7倍。
效果:R-CNN在pascal voc2007上的检测结果从DPM HSC的34.3%直接提升到了66%(mAP)。
R-CNN速度慢的原因:对图像提取region proposal(2000个左右)之后将每个proposal当成一张图像进行后续处理(利用CNN提取特征+SVM分类),实际上对一张图像进行了2000次提取特征和分类的过程。
2)Fast R-CNN(ICCV 2015)
Fast R-CNN的算法原理:
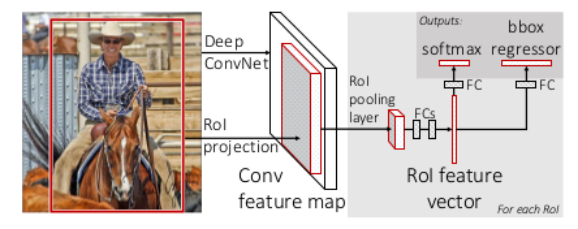
Fast R-CNN算法步骤:
(1)输入待检测图像
(2)利用Selective Search算法在输入图像中提取出2000个左右的候选区域,
(3)将这些候选区域输入到CNN进行特征提取
(4)对于卷积特征层上的每个候选区域进行RoI Pooling操作,得到固定维度的feature map;
(5)提取到的特征输入全连接层,然后用Softmax进行分类,对候选区域的位置进行回归。
实验结果:
在VOC07上,实验比较了Fast R-CNN、R-CNN和SPPnet。所有方法都从相同的预训练VGG16网络开始,并使用边界框回归。VGG16 SPPnet结果由SPPnet BB的作者计算得出。SPPnet在培训和测试期间使用五个量表。与SPPnet相比,Fast R-CNN的改进表明,尽管Fast R-CNN使用单尺度训练和测试,但微调conv层可以大幅提高mAP(从63.1%提高到66.9%)。R-CNN获得了66.0%的mAP。次要的一点是,SPPnet在帕斯卡语中没有标记为“困难”的例子。删除这些示例将Fast R-CNN映射提高到68.1%。所有其他实验都使用“困难”的例子。

在VOC 2010 and 2012数据集中,实验将Fast R-CNN(简称FRCN)与公开排行榜comp4(外部数据)上的顶级方法进行比较(表2,表3)。对于NUS NIN c2000和BabyLearning方法,目前没有相关论文,实验无法找到所用ConvNet体系结构的确切信息;它们是网络设计中网络的变体。所有其他方法都是从相同的预训练VGG16网络初始化的。
Fast R-CNN以65.7%的mAP在VOC12上取得了最佳结果(额外数据为68.4%)。它也比其他方法快两个数量级,这些方法都基于“慢速”R-CNN管道。在VOC10上,SegDeepM获得了比Fast R-CNN更高的mAP(67.2%对66.1%)。SegDeepM在VOC12 trainval和分段注释上进行训练;通过使用马尔可夫随机场推理O2P语义分割方法中的R-CNN检测和分割,旨在提高R-CNN的准确性。快速R-CNN可以替换为SEGDEPM代替R-CNN,这可能会产生更好的结果。当使用扩大的07++12训练集(见表2标题)时,Fast R-CNN的mAP增加到68.8%,超过SegDeepM。

与R-CNN框架图对比,有两处不同:
(1)最后一个卷积层后加了一个RoI(Regions of Interest) pooling layer;
(2)损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中进行训练。
Fast R-CNN改进:
(1)RoI pooling layer:SPP-NET对每个proposal使用了不同大小的金字塔映射,将RoI pooling layer只需要下采样到一个7*7的特征图;
(2)使用softmax代替SVM分类,将多任务损失函数边框回归加入到网络中:除了region proposal提取阶段以外,其他的训练过程是端到端的;
(3)微调部分卷积层。
存在问题:要先提取region proposal,没有实现真正意义上的端到端训练。
3)Faster R-CNN(ICCV 2015)
经过R-CNN和Fast R-CNN的积淀,Ross B. Girshick在2016年的论文《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》提出了新的Faster RCNN。
Faster R-CNN算法原理:

整个网络可以分为四个部分:
(1)Conv layers。首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续的RPN层和全连接层。
(2)Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression来修正anchors来获得精确proposals。
(3)RoI Pooling。该层收集输入的feature maps和proposals,送入后续全连接层判定目标类别。
(4)Classifier。利用proposal feature maps计算proposals的类别,同时再次利用bounding box regression获得检测框最终的精确位置。
FASTER-RCNN算法步骤:
(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN生成建议窗口(proposals),每张图片生成300个建议窗口;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
实验结果:
实验在PASCAL VOC 2007检测基准上综合评估了FASTER-RCNN的方法【11】。该数据集包括约5k个TranVal图像和超过20个对象类别的5k个测试图像。FASTER-RCNN还提供了一些模型的PASCAL VOC 2012基准测试结果。对于ImageNet预训练网络,FASTER-RCNN使用“快速”版本的ZF net[32],它有5个卷积层和3个完全连接层,以及公共VGG-16 model7[3],它有13个卷积层和3个完全连接层。FASTER-RCNN主要评估检测平均精度(mAP),因为这是对象检测的实际度量(而不是关注对象建议代理度量)。
表2(顶部)显示了使用各种区域候选方法进行训练和测试时的Fast R-CNN结果。这些结果使用ZF网络。对于选Selective Search(SS),实验通过“快速”模式生成了大约2000个候选。对于EdgeBoxes(EB),实验通过调整为0.7 IoU的默认EB设置生成提案。在快速R-CNN框架下,SS的mAP为58.7%,EB的mAP为58.6%。使用Fast R-CNN的RPN取得了有竞争力的结果,在使用多达300个提议8的情况下,其mAP为59.9%。由于共享卷积计算,使用RPN比使用SS或EB产生更快的检测系统;更少的提案也降低了区域级完全连接层的成本(表5)。
为了研究RPN的行为作为一种建议方法,实验进行了几项消融研究。首先,实验展示了RPN和Fast R-CNN检测网络之间共享卷积层的效果。为此,实验在四步训练过程的第二步之后停止。使用单独的网络将结果略微降低到58.7%(RPN+ZF,非共享,表2)。观察到这是因为在第三步中,当使用detectortuned特征微调RPN时,建议质量得到了提高。
接下来,实验分析了RPN对训练Fast R-CNN检测网络的影响。为此,实验使用2000 SS提案和ZF网络来训练Fast R-CNN模型。Fast R-CNN修复此检测器,并通过更改测试时使用的建议区域来评估检测图。在这些烧蚀实验中,RPN与探测器不具有相同的特征
在测试时用300个RPN提案替换SS,mAP为56.8%。mAP中的损失是由于培训/测试提案之间的不一致。此结果作为以下比较的基线。有些令人惊讶的是,当在测试时使用排名前100的提案时,RPN仍然会导致竞争结果(55.1%),这表明排名前100的RPN提案是准确的。另一方面,使用排名靠前的6000个RPN方案(无NMS)有一个可比的地图(55.2%),表明NMS不会损害检测地图,并可能减少误报。
接下来,Fast R-CNN通过在测试时关闭其中一个来分别研究RPN的cls和reg输出的作用。当在测试时删除cls层(因此不使用NMS/排名)时,Fast R-CNN从未评分区域随机抽取N个提案。当N=1000时,mAP几乎没有变化(55.8%),但当N=100时,mAP显著下降至44.6%。这表明cls分数说明了排名最高的提案的准确性。
另一方面,当reg层在测试时被移除(因此提案成为锚定框)时,mAP下降到52.1%。这表明,高质量的提案主要是由于回归框界限。锚箱虽然具有多个刻度和纵横比,但不足以进行精确检测。实验还评估了更强大的网络对RPN提案质量的影响。实验使用VGG-16来训练RPN,并且仍然使用上述SS+ZF检测器。mAP从56.8%(使用RPN+ZF)提高到59.2%(使用RPN+VGG)。这是一个有希望的结果,因为它表明RPN+VGG的提案质量优于RPN+ZF。由于RPN+ZF的提案与SS具有竞争性(当持续用于培训和测试时,两者均为58.7%),可以预期RPN+VGG优于SS。以下实验证实了这一假设。
VGG-16的性能。表3显示了VGG-16的建议和检测结果。使用RPN+VGG,非共享特性的结果为68.5%,略高于SS基线。如上所示,这是因为RPN+VGG生成的提案比SS更准确。与预定义的SS不同,RPN经过积极培训,并受益于更好的网络。对于功能共享变体,结果是69.9%,比强大的SS基线要好,但几乎没有成本。实验进一步在PASCAL VOC 2007 trainval和2012 trainval的联合集上训练RPN和检测网络。mAP为73.2%。图5显示了PASCAL VOC 2007测试集的一些结果。在PASCAL VOC 2012测试集(表4)上,faster-RCNN的方法在VOC 2007 trainval+测试和VOC 2012 trainval的联合集上训练了70.4%的映射。表6和表7显示了详细的数据。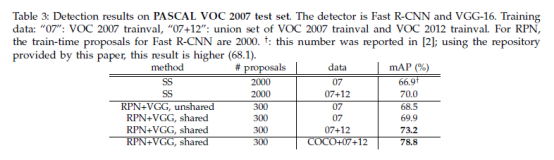




在表5中,实验总结了整个目标检测系统的运行时间。SS需要1-2秒,具体取决于内容(平均约1.5秒),而带有VGG-16的Fast R-CNN在2000个SS提案上需要320ms(如果在完全连接的层上使用SVD,则需要223ms[2])。实验使用VGG-16的系统在建议和检测方面总共需要198ms。共享卷积特性后,仅RPN就只需10ms即可计算额外的层。由于提案较少(每张图片300个),区域计算也较低。Faster RCNN系统在ZF网络上的帧速率为17 fps。
相比FAST R-CNN,主要两处不同:
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生候选窗口;
(2)产生候选窗口的CNN和目标检测的CNN共享
主要贡献:提出了区域推荐网络(RPN,Region Proposal Networks),实现了真正意义上的端到端训练。
RPN网络:在提取特征的最后的卷积层上滑动一遍,利用anchor机制和边框回归,得到多尺度多长宽比的region proposals。
Anchor机制:
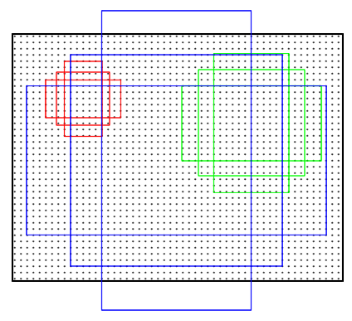
对于提取特征的最后的卷积层的每一个位置,考虑9个可能的候选窗口:
三种面积(128*128,256*256,512*512) * 三种比例(1:1,1:2,2:1)。这些候选窗口称为anchors。