目录
了解强化学习“T步累积奖励”和“γ折扣累积奖励”的计算方法。
熟悉仅探索(exploration-only)和仅利用(exploitation-only)的主要目的。
熟悉仅探索(exploration-only)和仅利用(exploitation-only)的存在的问题。
熟悉监督学习、无监督学习和强化学习之间的区别和联系。
- 监督学习:训练数据有标注信息
分类、回归
- 无监督学习:训练数据无标注信息(本质上是一种统计手段)
聚类、降维
- 强化学习:
了解强化学习的学习方式。
- 通过智能体(Agent)以试错的方式与环境交互,从而获得最高奖励。
- 强化学习任务通常用马尔可夫决策过程来描述
机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
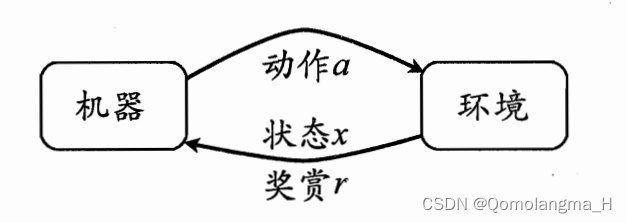
策略的优劣取决于长期执行这一策略后得到的累积奖赏,在强化学习任务中,学习的目的就是要找到能使长期累积奖赏最大化的策略。长期累积奖赏有多种计算方式,常用的有“T步累积奖赏”和“γ折扣累积奖赏”。
了解强化学习“T步累积奖励”和“γ折扣累积奖励”的计算方法。
状态值函数:

状态-动作值函数:
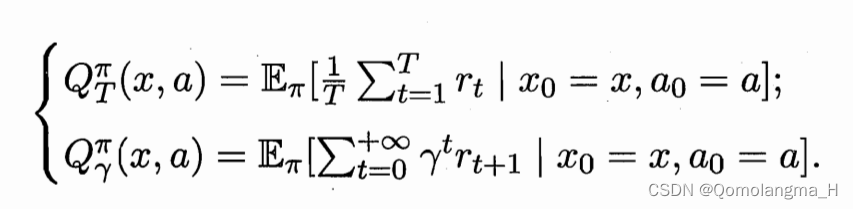
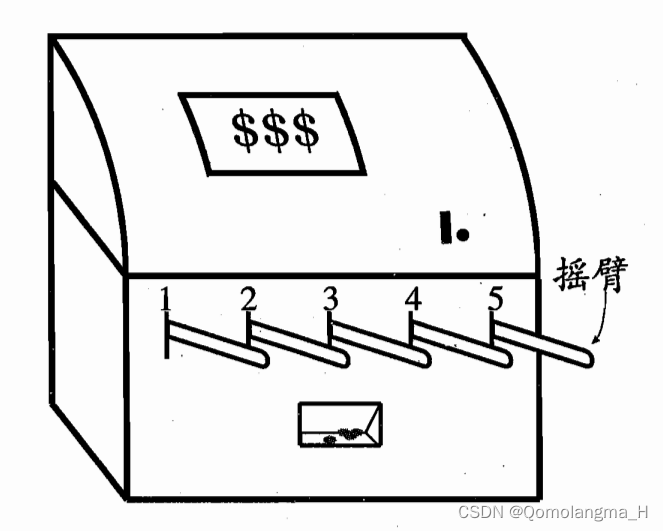
了解K-摇臂赌博机的游戏规则
K-摇臂赌博机有K个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒并不知道.赌徒的目标是通过一定的策略最大化自己的奖赏,即获得最多的硬币。
熟悉仅探索(exploration-only)和仅利用(exploitation-only)的主要目的。
- 仅探索以获得奖赏期望为目的:将所有的尝试机会平均分配给每个摇臂,即:轮流按下每个摇臂,最后以每个摇臂各自的平均吐币概率作为其奖赏期望的近似估计。
- 仅利用以获得最大奖赏为目的:按下目前最优的摇臂,即:到目前为止平均奖赏最大的,若有多个摇臂同为最优,则从中随机选取一个。
熟悉仅探索(exploration-only)和仅利用(exploitation-only)的存在的问题。
- 仅探索:能估计每个摇臂的奖赏,却会失去很多选择最优摇臂的机会
- 仅利用:没有很好地估计摇臂期望奖赏,很可能选不到最优摇臂
- 结论:
- 探索,即:估计摇臂的优劣;
- 利用,即:选择当前最优的摇臂
两种方法都难以使最终的累积奖赏最大化,即:探索-利用窘境
了解ε-贪心算法所解决的主要问题是什么。
解决探索-利用窘境
贪心法基于一个概率来对探索和利用进行折中:每次尝试时,以ε的概率进行探索,即以均匀概率随机选取一个摇臂;以1-ε的概率进行利用,即选择当前平均奖赏最高的摇臂(若有多个,则随机选取一个)。
通常 令ε取一个较小的常数,如0.1或0.01。然而,若尝试次数非常大,那么在一段时间后,摇臂的奖赏都能很好地近似出来,不再需要探索,这种情形下可让ε随着尝试次数的增加而逐渐减小。
熟悉K-摇臂赌博机游戏过程和马尔科夫过程的区别和联系。
马尔可夫决策过程(MDP):
马尔可夫性:当前状态包含了对未来预测所需要的有用信息,过去信息对未来预测不重要,就满足了马尔科夫性。严格来说,就是某一状态信息包含了所有相关的历史,只要当前状态可知,所有的历史信息都不再需要,当前状态就可以决定未来,则认为该状态具有马尔科夫性。