本文说明如何在MATLAB中使用长短期记忆(LSTM)网络对序列数据进行分类。要训练深度神经网络以对序列数据进行分类,可以使用LSTM网络。LSTM网络允许您将序列数据输入网络,并根据序列数据的各个时间步进行预测。此示例使用日语元音数据集。此示例训练一个LSTM网络,旨在根据表示连续说出的两个日语元音的时间序列数据来识别说话者。训练数据包含九个说话者的时间序列数据。每个序列有12个特征,且长度不同。该数据集包含270个训练观测值和370个测试观测值。
加载日语元音训练数据。XTrain是包含270个不同长度的12维序列的元胞数组。Y是对应于九个说话者的标签"1"、"2"、...、"9"的分类向量。XTrain中的条目是具有12行(每个特征一行)和不同列数(每个时间步一列)的矩阵。
[XTrain,YTrain] = japaneseVowelsTrainData;
XTrain(1:5)
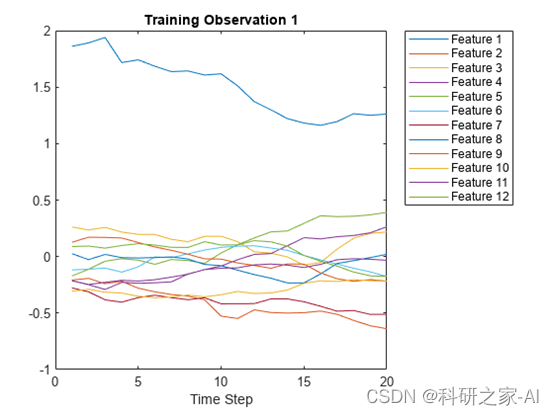
在绘图中可视化第一个时间序列。每行对应一个特征。
figure
plot(XTrain{1}')
xlabel("Time Step")
title("Training Observation 1")
numFeatures = size(XTrain{1},1);
legend("Feature " + string(1:numFeatures),Location="northeastoutside")
准备要填充的数据
在训练过程中,默认情况下,软件将训练数据拆分成小批量并填充序列,使它们具有相同的长度。过多填充会对网络性能产生负面影响。
为了防止训练过程添加过多填充,您可以按序列长度对训练数据进行排序,并选择合适的小批量大小,以使同一小批量中的序列长度相近。下图显示了对数据进行排序之前和之后填充序列的效果。

%%获取每个观测值的序列长度。
numObservations = numel(XTrain);
for i=1:numObservations
sequence = XTrain{i};
sequenceLengths(i) = size(sequence,2);
end
%%按序列长度对数据进行排序。
[sequenceLengths,idx] = sort(sequenceLengths);
XTrain = XTrain(idx);
YTrain = YTrain(idx);
%%在条形图中查看排序的序列长度。
figure
bar(sequenceLengths)
ylim([0 30])
xlabel("Sequence")
ylabel("Length")
title("Sorted Data")
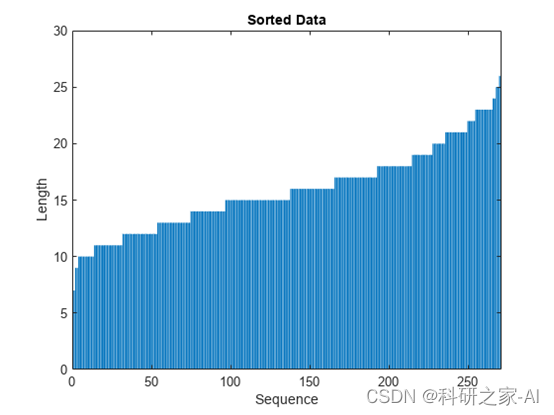
选择小批量大小27以均匀划分训练数据,并减少小批量中的填充量。下图说明了添加到序列中的填充。
miniBatchSize = 27;
定义LSTM网络架构
定义LSTM网络架构。将输入大小指定为序列大小12(输入数据的维度)。指定具有100个隐含单元的双向LSTM层,并输出序列的最后一个元素。最后,通过包含大小为9的全连接层,后跟softmax层和分类层,来指定九个类。
如果您可以在预测时访问完整序列,则可以在网络中使用双向LSTM层。双向LSTM层在每个时间步从完整序列学习。
inputSize = 12;
numHiddenUnits = 100;
numClasses = 9;
layers = [ ...
sequenceInputLayer(inputSize)
bilstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer]
现在,指定训练选项。指定求解器为 "adam",梯度阈值为 1,最大轮数为 50。要填充数据以使长度与最长序列相同,请将序列长度指定为"longest"。要确保数据保持按序列长度排序的状态,请指定从不打乱数据。
由于小批量数据存储较小且序列较短,因此更适合在 CPU 上训练。将 ExecutionEnvironment 选项设置为"cpu"。要在GPU(如果可用)上进行训练,请将 ExecutionEnvironment 选项设置为"auto"(这是默认值)。
options = trainingOptions("adam", ...
ExecutionEnvironment="cpu", ...
GradientThreshold=1, ...
MaxEpochs=50, ...
MiniBatchSize=miniBatchSize, ...
SequenceLength="longest", ...
Shuffle="never", ...
Verbose=0, ...
Plots="training-progress");
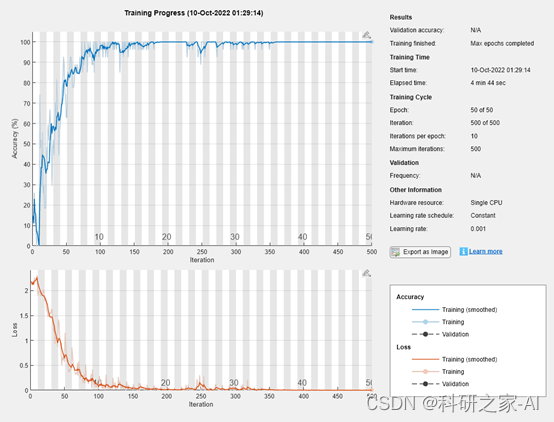
训练 LSTM 网络
使用 trainNetwork 以指定的训练选项训练 LSTM 网络。
net = trainNetwork(XTrain,YTrain,layers,options);
测试 LSTM 网络
[XTest,YTest] = japaneseVowelsTestData;
XTest(1:3)
numObservationsTest = numel(XTest);
for i=1:numObservationsTest
sequence = XTest{i};
sequenceLengthsTest(i) = size(sequence,2);
end
[sequenceLengthsTest,idx] = sort(sequenceLengthsTest);
XTest = XTest(idx);
YTest = YTest(idx);
对测试数据进行分类。要减少分类过程中引入的填充量,请指定使用相同的小批量大小进行训练。要应用与训练数据相同的填充,请将序列长度指定为 "longest"。
最后预测+计算准确率。订阅号”棒棒科研“输入”LSTM序列分类“获取完整代码。