
paper:https://arxiv.org/abs/2107.02126.pdf
一、论文概要
本论文主要是讨论了事件抽取的常用方法、数据集以及对应的评价指标。本综述还提供了不同技术之间的综合比较。最后,总结了今后的研究方向。
二、事件抽取简介
事件抽取(EE)是信息抽取研究中的一个重要而富有挑战性的课题。事件作为一种特殊的信息形式,是指在特定时间、特定地点发生的涉及一个或多个参与者的特定事件,通常可以描述为状态的变化。
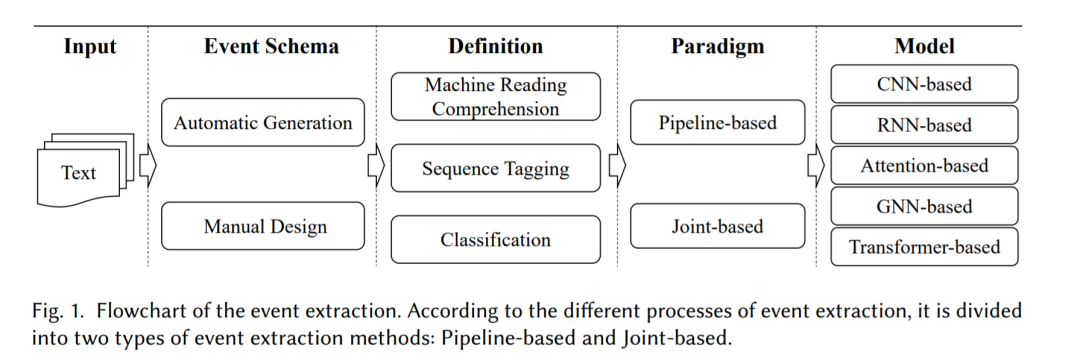
我们给出了事件抽取流程图,如图Fig1所示。
大多数基于深度学习的事件提取方法通常采用监督学习,这意味着需要高质量的大数据集。ACE 2005是少数可用的标记事件数据之一,手动标记新闻,博客,采访和其他数据。ACE数据规模小是影响事件提取任务发展的主要因素。依赖人工标注语料库数据耗时耗力,导致现有事件语料库数据规模小、类型少、分布不均匀。事件提取任务可能非常复杂。一个句子中可能有多个事件类型,不同的事件类型将共享一个事件参数。同样的论点在不同事件中的作用也是不同的。根据抽取范式,基于模式的抽取方法可分为基于管道的抽取方法和基于联合的抽取方法。对基于管道的模型学习事件检测模型,然后学习参数抽取模型。联合事件提取方法避免了触发器识别错误对参数提取的影响,但不能充分利用事件触发器的信息。到目前为止,最好的事件提取方法是基于联合的事件提取范例。
对于传统的事件提取方法,需要进行特征设计,而对于深度学习事件提取方法,可以通过深度学习模型进行端到端的特征提取。综合分析了现有的基于深度学习的事件提取方法,并对未来的研究工作进行了展望。本文的主要贡献如下:
-
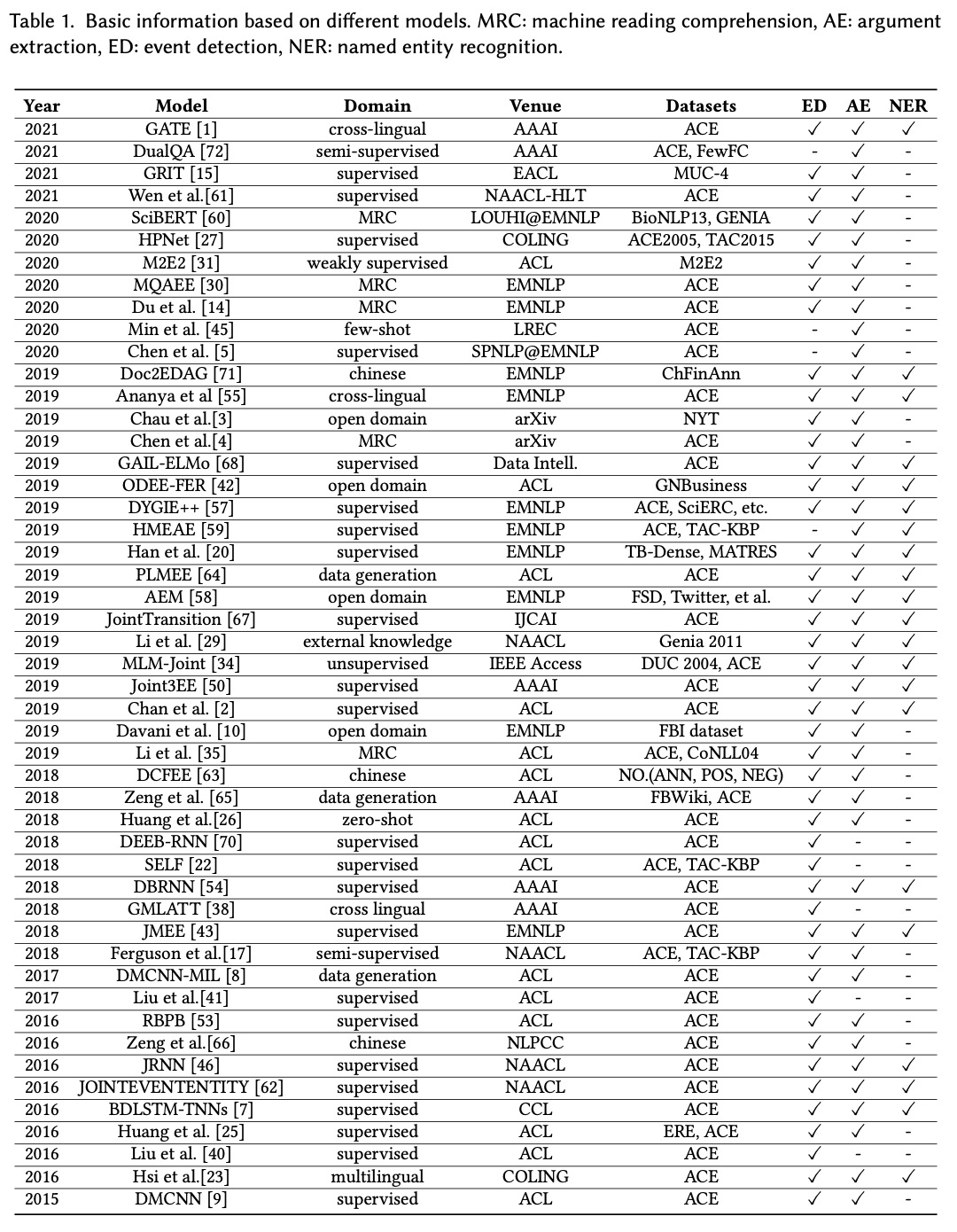
介绍了事件提取技术,回顾了事件提取方法的发展历史,指出基于深度学习的事件提取方法已成为主流。我们根据表1中发表年份总结了深度学习模型的必要信息,包括模型、领域、场所、数据集和子任务。
-
我们详细分析了各种基于深度学习的提取范式和模型,包括它们的优缺点。我们介绍了现有的数据集,并给出了主要评价指标的制定。我们在表3中总结了主要数据集的必要信息,如类别的数量,语言和数据地址。
-
我们在表5中总结了ACE 2005数据集上的事件提取准确度得分,并讨论了事件提取面临的未来研究趋势,从而总结了综述。
三、事件抽取介绍
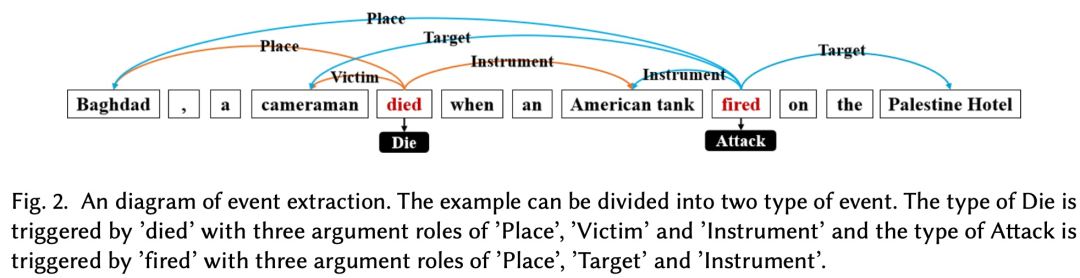
事件抽取是针对改定的文档,从中预测事件描述、事件触发词、事件对应的要素以及对应要素的角色。图Fig2中包括两个事件:“Die”和“Attack”,他们的事件触发词分别是“died”和“fired”。对于事件Die,事件要素是“Baghdad”,“cameraman”,“American tank”,他们对应的要素角色是“Place”,“Victim”,“Instrument”;对于时间Attack,事件要素是“Baghdad”,“American tank”,他们对应的要素角色是“Place”,“Instrument”。
通过Fig2的例子,说明一下事件抽取的相关概念
| 序号 | 概念名称 | 概念描述 |
| 1 | 实体(Entity) | 语义对象。比如人名、机构、组织都是实体 |
| 2 | 事件描述(Event mentions) | 描述事件信息的短语或者句子,图Fig2中的文本片段就是一个事件描述 |
| 3 | 事件类型(Event type) | 是事件的标签,通常是事件触发词的类型 |
| 4 | 事件触发词(Event trigger) | 标志着事件的开始,一般是动词或者动名词 |
| 5 | 事件要素(Event argument) | 用来描述一个事件的时间、地点、人物 |
| 6 | 要素角色(Argument role) | 事件要素在事件进行过程中的作用 |
基于schema的事件抽取主要包括以下四个任务:事件分类event classification, 事件触发词识别trigger identification, 事件要素识别argument identification和要素角色分类argument role classification。
(1)事件分类:
对文档中每个句子进行判断是否是事件,有几个事件,因此可以看成是一个多标签分类任务;
(2)事件触发词识别:
触发词是事件发生的核心
(3)事件要素识别:
识别事件的所有要素,通常依赖事件类型和触发词识别;
(4)要素角色分类:
就是对要素进行分类,也是一个多标签分类任务。
其实事件抽取任务可以转换成分类任务、序列标注任务或者机器阅读任务。
(1)分类任务:
分类任务是监督任务,需要预定义好事件的类型以及每类事件对应的要素角色,对于多个事件描述,模型需要输出每个事件描述对应每个事件类型的概率值
(2)序列标注任务:
基于word级别,类似NER,需要识别出事件类型对应的文本片段以及事件要素。
(3)机器阅读理解任务:
机器阅读理解就是首先需要理解自然语言文本的含义,然后基于文本回答相关问题。首先针对不同的事件类型设计不同的要素角色作为问题question,然后根据事件类型抽取对应的要素角色,最后模型需要根据每个要素角色输出对应的要素值。
四、事件抽取范式
事件抽取一般有两种范式:pipeline-based和joint-based。其中pipeline-based步骤是先识别事件触发词,然后根据触发词判断事件类型,再根据事件类型和触发词抽取事件要素以及要素对应的角色,这种方法容易造成错误传递。
4.1、pipeline-based

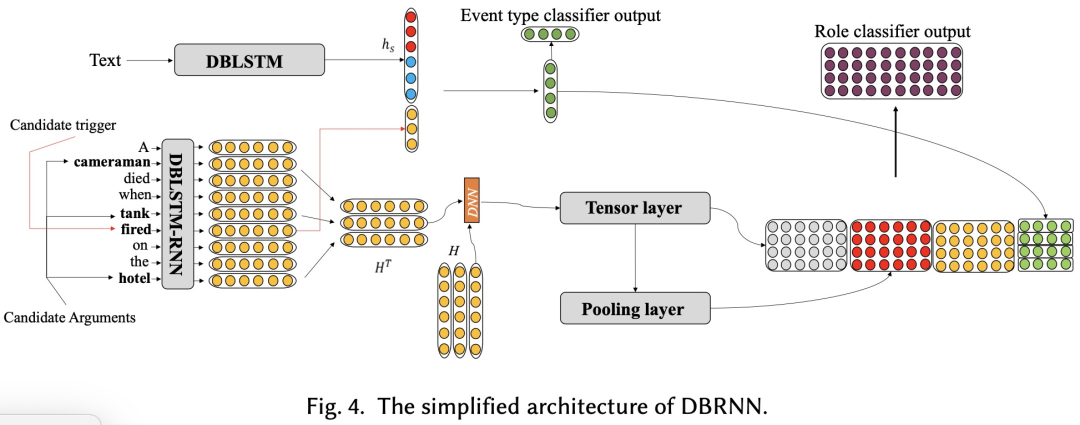
4.2、joint-based
五、事件抽取深度学习模型
5.1、CNN-based
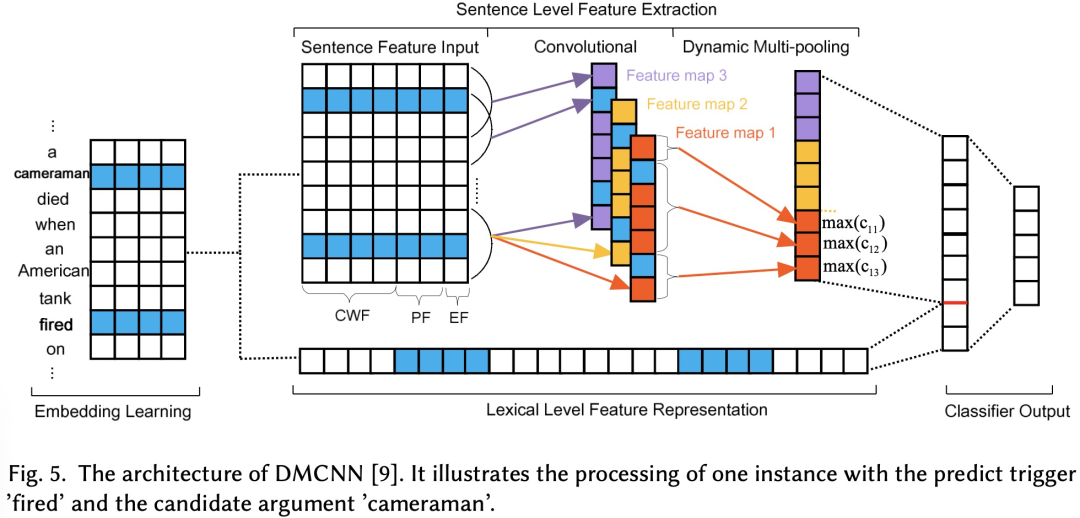
5.2、RNN-based

5.3、Attention-based
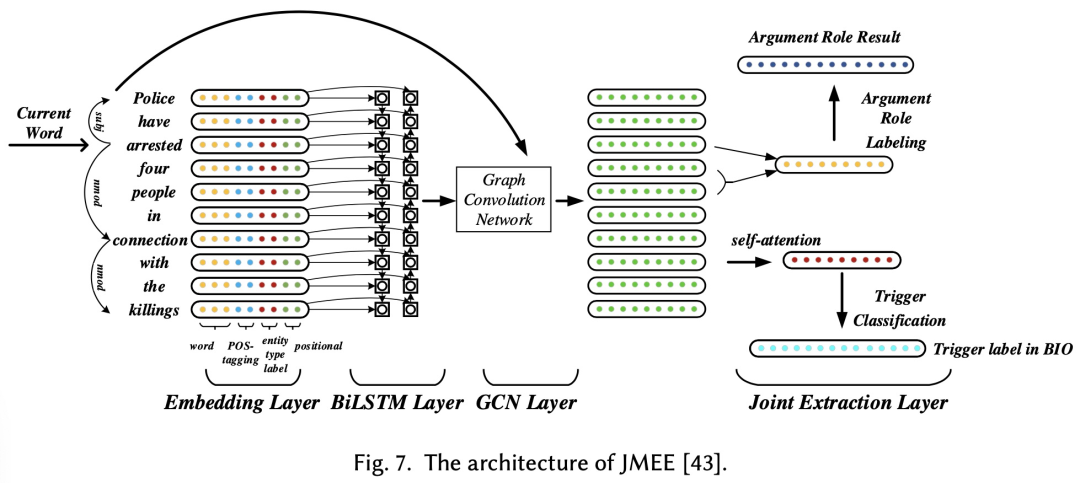
5.4、GCN-based
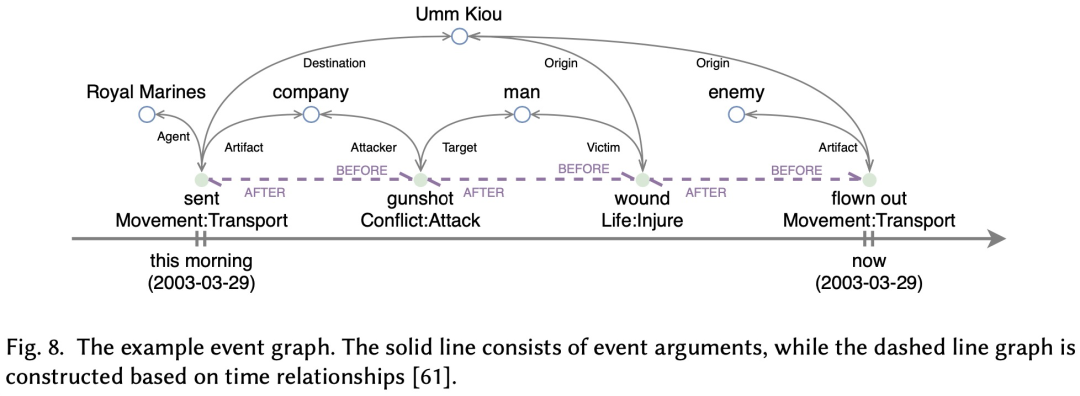
5.5、Transformer-based

六、事件抽取公开数据集
6.1、Document-level
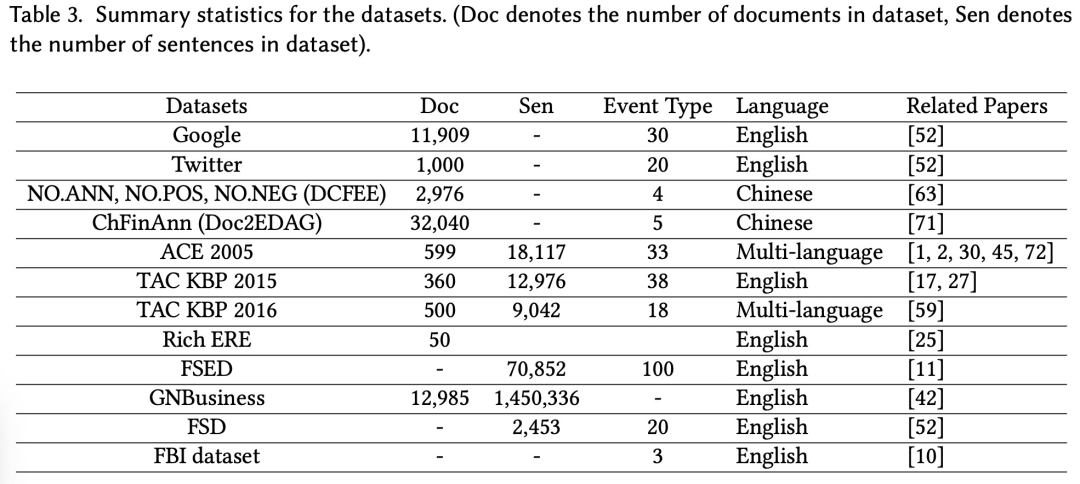
6.2、Sentence-level
常用的有:Automatic Content Extraction(ACE)、Text Analysis Conference Knowledge base Filling(TAC KBP)、Rich ERE、FSED、GNBusiness、FSD、FBI dataset