事件抽取
事件是促使事情状态和关系改变的条件。目前已存在的知识资源(如维基百科等) 所描述实体及实体间的关系大多是静态的,而事件能描述粒度更大的、动态的、 结构化的知识,是现有知识资源的重要补充。
与关系抽取相比,事件抽取同样需要从文本中抽取 谓语(predicate) 和对应的 arguments(事件元素),但不同的是,关系抽取的问题是 二元(binary) 的,且两个 arguments 通常都会在同一个句子中出现,而事件抽取的难点在于,有多个 arguments 和 修饰符(modifiers),可能会分布在多个句子中,且有些 arguments 不是必须的(在任何给定的事件实例中都将省略其中的一些),这使得 bootstrapping/distant learning/coreference 都变得非常困难。
事件抽取的任务可以分两大类:
事件识别和抽取
从描述事件信息的文本中识别并抽取出事件信息并以结构化的形式呈现出来,包括发生的时间、地点、参与角色以及与之相关的动作或者状态的改变。
事件检测和追踪
事件检测与追踪旨在将文本新闻流按照其报道的事件进行组织,为传统媒体多种来源的新闻监控提供核心技术,以便让用户了解新闻及其发展。具体而言,事件发现与跟踪包括三个主要任务:分割,发现和跟踪,将新闻文本分解为事件, 发现新的(不可预见的)事件,并跟踪以前报道事件的发展。
事件发现任务又可细分为历史事件发现和在线事件发现两种形式,前者目标是从按时间排序的新闻文档中发现以前没有识别的事件,后者则是从实时新闻流中实时发现新的事件。
本文的重点在于事件识别与抽取。首先看一下相关的核心概念:
-
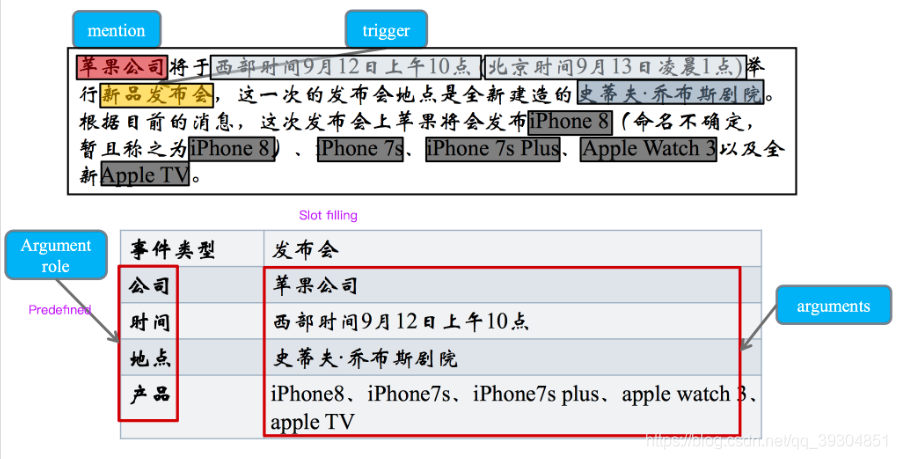
事件描述(Event Mention) :
描述事件的词组/句子/句群,包含一个 trigger(触发) 以及任意数量的 arguments -
事件触发(Event Trigger):
事件描述中最能代表事件发生的词汇,决定事件类别的重要特征,一般是动词或者名词 -
事件元素(Event Argument)
事件的重要信息,或者说是实体描述(entity mention),主要由实体、属性值等表达完整语义的细粒度单位组成 -
元素角色(Argument Role)
事件元素在事件中扮演的角色,事件元素与事件的语义关系,可以理解为 slot -
事件类型(Event Type)
事件识别和抽取理解
直观上来看,可以把事件抽取的任务理解成从文本中找到特定类别的事件,然后进行填表的过程。
事件抽取系统定义
Given a text document, an event extraction system should predict event triggers with specific sub-types and their arguments for each sentence.
给定一个文本文档,一个事件抽取系统必须为每个句子产生预测事件触发词 ,每个 事件触发词 含有具体的子类型 和它的具体事件元素。
也就是说,事件抽取任务最基础的部分包括:
- 识别事件触发词及事件类型
- 抽取事件元素(Event Argument)同时判断其角色(Argument Role)
- 抽出描述事件的词组或句子
当然还有一些其他的子任务包括事件属性标注、事件共指消解等。
事件抽取大多是分阶段进行,通常由 trigger classifier(触发分类器)开始,如果有 trigger,把 trigger 以及它的上下文作为特征进行分类判断事件类型,再进行下一步的 argument classifier(事件元素费雷其),对句子中的每个 entity mention(涉及实体) 进行分类,判断是否是 argument(事件元素),如果是,判定它的角色slot。
基于模式匹配的方法
MUCs 最开始,事件抽取的系统都是基于人工编写的规则,基于语法树或者正则表达式,如 CIRCUS (Lehnert 1991), RAPIER (Califf & Mooney 1997), SRV (Freitag 1998), AutoSlog (Riloff 1993), LIEP (Huffman 1995), PALKA (Kim & Moldovan 1995), CRYSTAL (Soderland et al. 1995), HASTEN (Krupka 1995) 等等,后来,慢慢的有了监督学习的模型,在 ACE 的阶段,大多数系统都是基于监督学习了,但由于标注一致性的问题,系统的效果普遍较差,ACE 事件抽取只举行了一次,在 2005 年。
下面先来看一下基于模板的抽取方法,基本都是通过 句法(syntactic) 和 语义约束(semantic constraints) 来进行识别。
基于人工标注语料
在早期,模板创建过程通常从一个大的标注集开始,模板的产生完全基于人工标注语料,学习效果高度依赖于人工标注质量。
AutoSlog(Riloff)
基本假设:
a. 事件元素首次提及之处即可确定该元素与事件间的关系
b. 事件元素周围的语句中包含了事件元素在事件中的角色描述
通过监督学习和人工审查来建立抽取规则。通过训练数据中已经填充好的槽(filled slot),AutoSlog 解析 slot 附近的句法结构,来自动形成抽取规则,由于这个过程产生的模板 too-general,所以需要人工来审核。本质上形成的是一个字典。
举个例子
Ricardo Castellar, the mayor, was kidnapped yesterday by the FMLN.
市长里卡多·卡斯特拉尔(Ricardo Castellar)昨天被马解阵线绑架。
假设 Ricardo Castellar 被标注成了 victim(受害者已被标注),AutoSlog 根据句法分析判断出 Ricardo Castellar 是主语,然后触发了主语的相关规则 (subj) passive-verb,将句子中相关的单词填充进去就得到了规则 (victim) was kidnapped,所以在之后的文本中,只要 kidnapped 在一个被动结构中出现,它对应的主语就会被标记为 victim。
PALKA
基本假设:特定领域中高频出现的语言表达方式是可数的
用语义框架和短语模式结构来表示特定领域中的抽取模式,通过融入 WordNet 的语义信息,PALKA 在特定领域可取得接近纯人工抽取的效果。
基于弱监督
人工标注耗时耗力,且存在一致性问题,而弱监督方法不需要对语料进行完全标注,只需人工对语料进行一定的预分类或者制定种子模板,由机器根据预分类语料或种子模板自动进行模式学习。
-
AutoSlog-TS
Riloff and Shoen, 1995
AutoSlog-TS 不需要进行文本的标注,只需要一个预先分类好的训练语料,类别是与该领域相关还是不相关。过程是先过一遍语料库,对每一个名词短语(根据句法分析识别)都产生对应的抽取规则,然后再整体过一遍语料库,产生每个规则的一些相关统计数据,基本的 idea 是与不相关文本相比,在相关文本中更常出现的抽取规则更有可能是好的抽取规则。假设训练语料中相关与不相关的文本比例是 1:1,对产生的每条抽取规则计算相关比率 relevance rate,相关文档中出现规则的实例数/整个语料库中出现规则的实例数,那么 relevance rate < 50% 的抽取规则就被丢弃了,剩下的规则会按照 relevance_rate * log(frequency) 的形式从高到低进行排序,然后由人工进行审核。 -
TIMES
Chai and Biermann, 1998
引入了领域无关的概念知识库 WordNet,提升模式学习的泛化能力,并通过人工或规则进行词义消歧,使最终的模式更加准确 -
NEXUS
Piskorski et.al., 2001; Tanev et.al., 2008
用聚类对语料进行预处理 -
GenPAM
Jiang, 2005
在由特例生成泛化模式的学习过程中,有效利用模式间的相似性实现词义消歧,最大限度地减少了人工的工作量和对系统的干预
小结
基于模式匹配的方法在特定领域中性能较好,知识表示简洁,便于理解和后续应用,但对于语言、领域和文档形式都有不同程度的依赖,覆盖度和可移植性较差。
模式匹配的方法中,模板准确性是影响整个方法性能的重要因素。在实际应用中,模式匹配方法应用非常广泛,主要特点是高准确率低召回率,要提高召回率,一是要建立更完整的模板库,二是可以用半监督的方法来建 trigger 字典。
基于统计 - 传统机器学习
建立在统计模型基础上,事件抽取方法可以分为 pipeline 和 joint model 两大类。
Pipeline
将事件抽取任务转化为多阶段的分类问题(管道抽取),需要顺序执行下面的分类器:
- 事件触发词分类器(Trigger Classifier)
判断词汇是否是事件触发词,以及事件类别 - 元素分类器(Argument Classifier)
词组是否是事件元素 - 元素角色分类器(Role Classifier)
判定元素的角色类别 - 属性分类器(Attribute Classifier)
判定事件属性 - 可报告性分类器(Reportable-Event Classifier)
判定是否存在值得报告的事件实例
