DMCNN是一种基于动态池化(dynamic pooling)的卷积神经网络模型的事件抽取方法,来自中国科学院自动化研究所的论文《Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks》。这是一种pipeline方式的事件抽取方案,即对触发词的检测和识别、对元素的检测和识别两个任务是分开进行的,后者依赖于前者的预测结果。两个子任务都被转换成了多分类问题,模型都采用DMCNN,只是稍有不同。
DMCNN算法原理:
本方法中,通过具有自动学习特征的DMCNN,将事件提取表述为两阶段、多类分类的任务。第一个阶段称为触发分类,在该阶段中,使用DMCNN对句子中的每个单词进行分类,以识别触发词。如果一个句子有触发器,则进行第二阶段,该阶段应用类似的DMCNN将元素分配给触发器,并对齐元素的角色。本方法称之为元素分类。
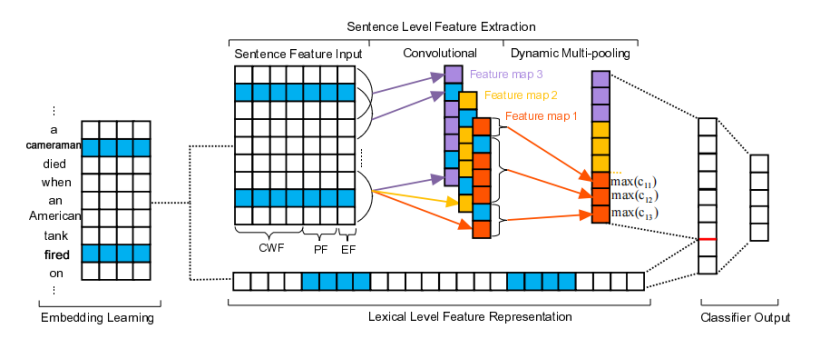
上图元素分类的结构,基本上涉及以下部分:(1)词嵌入学习,无监督方式;(2)词典级别特征表示,直接用词向量来发现词汇线索;(3)句子级特征抽取,提出DMCNN来学习句子中组成语义特征;(4)元素分类输出,为每一个元素候选角色计算置信度值。
词嵌入学习和词汇级特征表示
词汇级别特征是事件抽取中的重要线索。传统的词典级别特征基本上包括候选词的lemma,同义和词性标签。这种特征的质量依赖于现有的NLP工具和人工精巧。这篇论文选择无监督预训练词向量作为基本数据源特征,我们选择候选词的词向量(候选触发词,候选元素)和上下文token(候选词左右token)。然后,所有词向量串起来词汇级别特征向量L来表示元素分类里的词汇级别特征。
在这项工作中,使用skip-gram模型来预训练词向量。skip-gram使用扩大平均值log可能性来训练词语w1,w2……wm。
使用DMCNN进行句子级别特征学习
CNN使用最大池是一个很好的选择来获得句子中长距离词之间的语义关系。但是, 传统的CNN不能解决事件抽取的问题。因为一个句子中可能包含不仅仅一个事件,仅仅使用最重要的信息来表示这个句子,因为在传统的CNN中,会失去很多有价值的线索。为了解决这个问题,论文提出了DMCNN的方法来抽取句子级别的特征。DMCNN使用动态多池卷积神经网络来实现一个句子中每个部分的最大值获取,这个句子被事件触发词和事件元素分割。
输入
预测的触发词与候选元素之间的语义关系对于元素分类是至关重要的。因此,论文提出了三种类型输入来使DMCNN可以获得重要的线索:
词汇上下文特征(CWF): CWF是通过查找单词嵌入转换的每个单词标记的向量。
位置特征(PF):很有必要指定哪些词是元素分类中的预测触发器或候选元素。因此,论文提出PF定义为当前词语和候选元素或者触发词之间的距离,。为了编码位置特征,每一个距离值用向量表示。类似于词嵌入,距离值随机初始化和最优化使用后项传播方法。
事件类型特征(EF):当前触发词的事件类型对于元素分类是有价值的,所以论文在触发词分类阶段就对事件类型预测进行编码,然后作为DMCNN的重要线索。假定词向量大小为dw=4,位置嵌入大小为dp=1,事件类型嵌入为de=1,xi属于Rd,其中i表示第d维度在句子中第i个词汇,其中d=dw+dp*2+de。一个长度为n的句子如下:
x1:n = x1 ⊕ x2 ⊕ … ⊕ xn
⊕为串联操作符号。因此,结合词嵌入、位置嵌入和事件类型嵌入把一个实例转换成一个矩阵X ∈ Rn×d,然后X将输入卷积网络中。
卷积
卷积层目的在于抓取整个句子的组成语义,然后压缩那些有价值的语义到特征映射中。xi:i+j表示词向量从i到i+j的串联,卷积操作升级一个w ∈ Rh×d,应用h个单词为窗口来生成新的特征。比如说,特征Ci由xi:i+h-1的窗口单词生成。
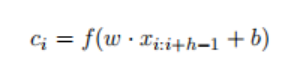
其中b∈ R是一个偏置项,f是一个非线性函数,如双曲正切。该滤波器应用于句子x1:h,x2:h+1,... ,xn−h+1:n生成特征映射ci,其中索引i的范围为1到n− h+1。
我们把这一过程描述为从以过滤抽取为特征映射。为了抓取不同的特征,通常在卷积中使用多个滤波器。假定使用滤波器W=w1,w2……wm,卷积操作表达如下:

其中j范围为1到m。卷积结果为矩阵C ∈ Rm×(n-h+1).
动态多池
为了提取每个特征图中最重要的特征(最大值),传统的cnn将一个特征图作为池,每个特征图只得到一个最大值。然而,单个最大池化对于事件提取是不够的。因为在论文的任务中,一个句子可能包含两个或更多的事件,而一个候选元素可能用不同的触发器发挥不同的作用。为了做出准确的预测,需要获取关于候选词变化的最有价值的信息。因此,根据元素分类阶段根据候选元素和预测触发器将每个特征映射分为三个部分。DMCNN不是使用整个特征映射的一个最大值来表示句子,而是保留每个分割部分的最大值,并称之为动态多池。与传统的最大池化相比,动态多池化可以在不遗漏最大池化值的情况下保留更多有价值的信息。
特征映射输出Cj被切分为三部分Cj1,Cj2,Cj3,动态多池可以表示如形式下,其中1<=j<=m,1<=i<=3 .pji = max(cji)、
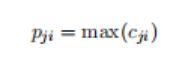
经过动态多卷积层,获得每个特征映射pij。串联所有pij成为向量P ∈ R3m
输出
自动学习词汇和句子级特征全部串联成一个向量F=[L,P].为了计算每一个元素角色的置信度,特征向量F ∈ R3m+dl,其中m是特征映射的个数,dl是词汇级别特征的维数。
触发分类任务
上述方法也适用于触发分类,但该任务只需要在句子中找到触发器,这比元素分类简单。因此,可以使用DMCNN的简化版本。在触发器分类中,DMCNN只在词汇级特征表示中使用候选触发器及其左右标记。在句子级别的特征表示中,使用与元素分类中相同的CWF,但只使用候选触发器的位置来嵌入位置特征。此外,句子不是把句子分成三个部分,而是被一个候选触发器分成两部分。除了上述特征和模型的变化外,将触发器分类为元素的分类。这两个阶段共同构成了事件提取的框架。
实验结果:
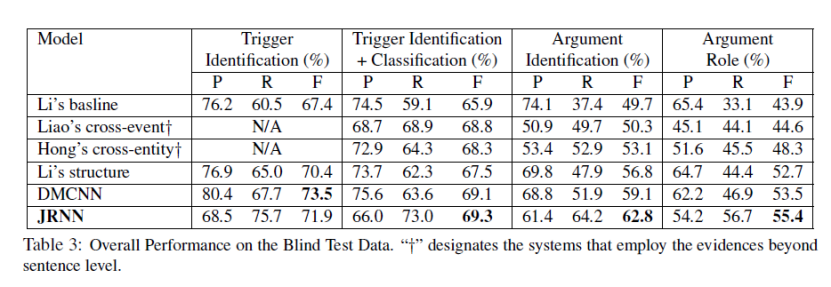
DMCNN的研究者选用ACE 2005 corpus作为实验的数据集,得到了如下表所示的实验结果。表1显示了盲测试数据集的总体性能。从结果可以看出,具有自动学习特征的DMCNN模型在所有比较方法中取得了最好的性能。DMCNN可以将最先进的F1触发器分类提高1.6%,元素角色分类提高0.8%。这证明了该方法的有效性。此外,将Liao’s cross-event(《Using document level cross-event inference to improve event extraction》)与Li’s baseline(《Joint event extraction via structured prediction with global features》)进行比较,说明Liao’s cross-event取得了更好的成绩。我们也可以在比较Hong‘s cross-entity和Liao’s cross-event以及比较Li’s structure(《Joint event extraction via structured prediction with global features》)和Hong‘s cross-entity(《Using cross-entity inference to improve event extraction》)时进行同样的观察。事实证明,当使用传统的人工设计的特征时,更丰富的特征集可以带来更好的性能。然而,DMCNN的方法在只使用从原始单词中自动学习的特征的情况下,可以获得更好的结果。具体而言,与Hong‘s cross entity相比,它在触发器分类F1上提高了0.8%,在元素分类F1上提高了5.2%。研究员认为,原因是DMCNN自动学习的特征可以捕捉到单词更有意义的语义规律。值得注意的是,与Li’s structure相比,尽管没有使用复杂的NLP工具,但DMCNN的句子和词汇特征方法取得了相当的性能。

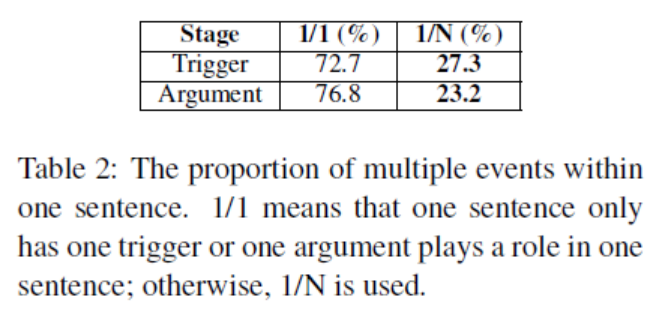
在一个句子中含有多个事件的抽取实验中得到了如下表所示的实验结果。表2显示了数据集中包含多个事件或单个事件的句子的比例,以及在一个句子中包含一个事件或多个事件的元素的比例。
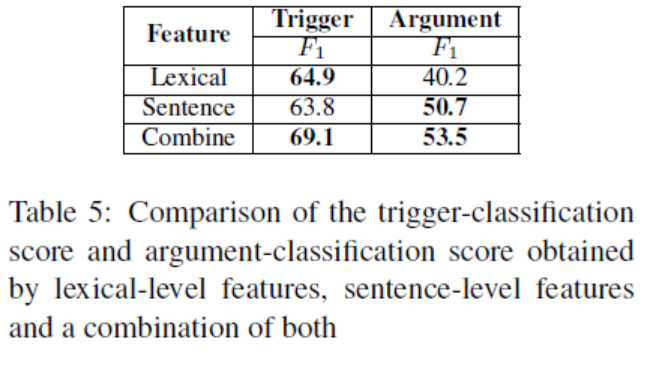
下表是DMCNN和CNN还有embedding+T的对比。表3说明了基于卷积神经网络(CNN和DMCNN)的方法优于embedding+T。这证明了卷积神经网络在句子级特征提取方面可能比传统的人类设计策略更有效。在表3中,对于所有句子,DMCNN的方法比CNN分别提高了约2.8%和4.6%。结果证明了动态多池层的有效性。有趣的是,DMCNN对有多个事件的句子的触发分类提高了7.8%。这种改进比有单一事件的句子要大。可以对元素分类结果进行类似的观察。这表明,拟议的DMCNN可以有效捕获比最大池CNN更多的有价值线索,尤其是当一句话包含多个事件时。
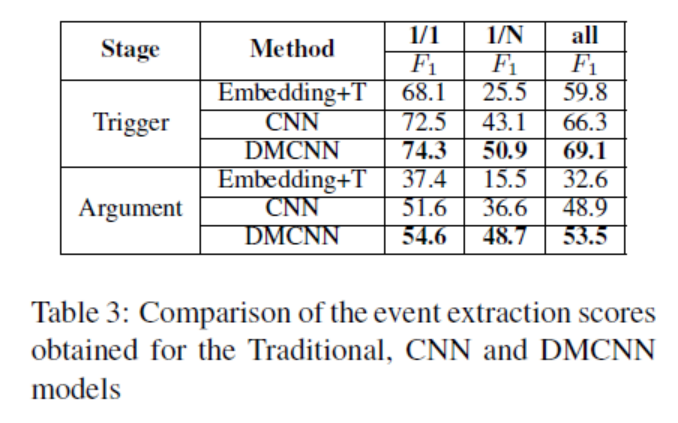
表四是DMCNN通过词汇特征进行事件抽取和传统方法通过词汇特征进行事件抽取的实验结果对比。表4表明,对于所有情况,与传统的词汇特征相比,DMCNN的方法在触发器和元素的分类方面都有显著的改进。对于情况B,从单词嵌入中提取的词汇级特征对触发器分类和元素分类分别提高了18.8%和8.5%。这是因为基线仅使用离散特征,因此它们存在数据稀疏性,无法充分处理触发器或元素未出现在训练数据中的情况。
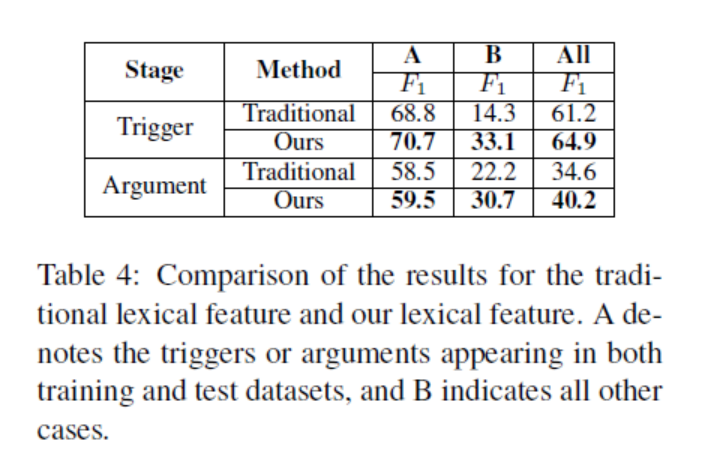
表五是不同层次特征进行抽取的有效性的实验对比。使用DMCNN获得的结果如表5所示。有趣的是,在触发分类阶段,词汇特征起着有效的作用,而句子特征在论点分类阶段起着更重要的作用。当实验将词汇级和句子级特征结合起来时,效果最好。这一观察结果表明,这两个级别的特征对于事件提取都很重要。
结论:
DMCNN提出了一种新的事件提取方法,可以自动从纯文本中提取词汇级和句子级特征无需复杂的NLP预处理。引入词表示模型来捕捉词汇语义线索,设计了动态多池卷积神经网络(DMCNN)对句子语义线索进行编码。实验结果证明了该方法的有效性。
JRNN来自纽约大学2016年的论文《Joint Event Extraction via Recurrent Neural Networks》,提出了一个基于循环神经网络的事件抽取联合模型,既避免了管道模型中的误差传播问题,同时也考虑到了事件触发词和事件元素之间的关系。
事件抽取的方法主要有两种:
(1)管道模型:首先识别事件触发器,之后再进行事件元素的识别。
(2)联合模型:同时预测句子的事件触发器和事件元素。
联合模型缓解了管道模型存在的误差传播问题,并考虑了事件触发器和事件元素之间的依赖关系。
JRNN的算法原理:
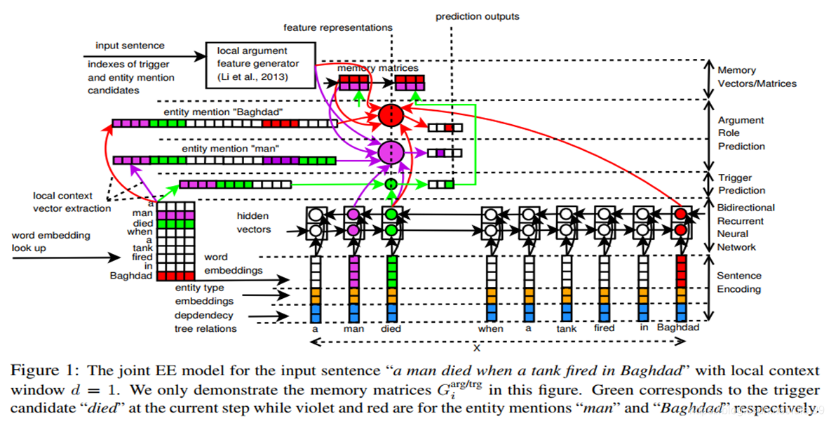 JRNN将事件抽取任务形式化如下。W=w1,w2,…,wn是一个句子,其中n是句子长度,wi是第i个标记。另外,让E=e1,e2,…,ek是这句句子中提到的实体(k是实体提到的数量,可以为零)。每个提到的实体都带有头部的偏移量和实体类型。进一步假设i1,i2,……,ik分别是e1,e2,……,ek的最后一个词的索引。在EE中,对于句子中的每个标记wi,需要预测它的事件子类型(如果有的话)。如果wi是某些感兴趣的事件的触发词,那么需要预测每个实体提到的ej在该事件中扮演的角色(如果有的话)
JRNN将事件抽取任务形式化如下。W=w1,w2,…,wn是一个句子,其中n是句子长度,wi是第i个标记。另外,让E=e1,e2,…,ek是这句句子中提到的实体(k是实体提到的数量,可以为零)。每个提到的实体都带有头部的偏移量和实体类型。进一步假设i1,i2,……,ik分别是e1,e2,……,ek的最后一个词的索引。在EE中,对于句子中的每个标记wi,需要预测它的事件子类型(如果有的话)。如果wi是某些感兴趣的事件的触发词,那么需要预测每个实体提到的ej在该事件中扮演的角色(如果有的话)
整个模型分为两个阶段:编码阶段和预测阶段
(1)编码阶段应用循环神经网络诱导句子更抽象的向量
(2)预测阶段使用新的向量执行事件触发和元素角色识别
编码阶段:
在编码阶段,首先使用以下三个向量的连接,将每个标记wi转换为一个实值向量xi:
1.wi的单词嵌入向量:通过查找一个预先训练好的单词嵌入表得到的
2.wi的实体类型的实值嵌入向量:该向量基于之前的工作(Nguyen和Grishman,《Event detection and domain adaptation with convolutional neural networks.》),通过查找wi的实体类型的实体类型嵌入表(随机初始化)生成。请注意,还使用BIO注释模式来为句子中的每个标记分配实体类型标签。
3.二元向量,其维数对应于依存树中词之间的可能关系。仅当W的依存树中存在与wi相连的对应关系的一条边时,该向量的每个维度的值才设置为1。该向量表示在先前的研究中(《Joint event extraction via structured prediction with global features.》)显示有帮助的依存特征
请注意,JRNN没有使用相对位置特征,原因是JRNN共同预测了整个句子的触发器和元素角色,因此在句子中没有固定的锚定位置。从标记wi到向量xi的转换本质上是将输入句子W转换为实值向量X=(x1,x2,……,xn),供循环神经网络用来学习更有效的表示。
预测阶段:
为了共同预测W的触发器和元素角色,JRNN为触发器创建一个二进制内存向量 ,为元素维护一个二进制内存矩阵和(每次i)。这些向量/矩阵最初被设置为零(i=0),并在W的预测过程中进行更新。
,为元素维护一个二进制内存矩阵和(每次i)。这些向量/矩阵最初被设置为零(i=0),并在W的预测过程中进行更新。
给定双向表示h1,h2,……,在编码阶段的hn和初始化的内存向量/矩阵,联合预测过程循环到句子中的n个令牌(从1到n)。在每个时间步i中,我们按照顺序执行以下三个阶段:
(1)对wi的触发器进行预测。
(2)所有实体提到的e1、e2的元素角色预测…,ek关于当前的令牌wi。
(3)使用之前的记忆向量/矩阵、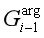 和
和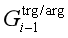 ,以及早期阶段的预测输出,计算当前步骤的
,以及早期阶段的预测输出,计算当前步骤的 、
、 和
和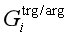 。
。
这个过程的输出将是wi的预测触发子类型ti,预测的元素角色ai1,ai2,…,aik和内存向量/矩阵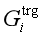 、
、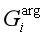 和
和 。请注意,如果wi是某些感兴趣的事件的触发词,或者在其他情况下是“Other”,则ti应该是事件子类型。相比之下,如果wi是一个触发词,而ej是对应事件的元素,则aij应该是关于wi的实体的元素角色,否则aij被设置为“Other”(j=1到k)。
。请注意,如果wi是某些感兴趣的事件的触发词,或者在其他情况下是“Other”,则ti应该是事件子类型。相比之下,如果wi是一个触发词,而ej是对应事件的元素,则aij应该是关于wi的实体的元素角色,否则aij被设置为“Other”(j=1到k)。
触发器预测:
在当前标记wi的触发预测阶段,我们首先使用以下三个向量的连接来计算wi的特征表示向量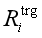
hi: 封装输入句子的全局上下文的隐藏向量。
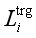 :wi的局部上下文向量。是通过将单词的上下文窗口中的向量连接起来生成的:=[D[wi−d],…,D[wi],…,D[wi+d]]。
:wi的局部上下文向量。是通过将单词的上下文窗口中的向量连接起来生成的:=[D[wi−d],…,D[wi],…,D[wi+d]]。
 :前一步中的记忆向量。
:前一步中的记忆向量。
然后将表示向量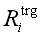 =[hi,,]输入前馈神经网络和softmax层,最终计算可能触发子类型的概率分布。最后计算wi的预测类型ti。
=[hi,,]输入前馈神经网络和softmax层,最终计算可能触发子类型的概率分布。最后计算wi的预测类型ti。
元素预测阶段:
在元素角色预测阶段,我们首先检查前一阶段预测的触发子型ti是否为“Other”。如果是,可以简单地将aij设置为所有j=1到k的“Other”,然后立即进入下一个阶段。否则,循环实体e1,e2,…,ek。
实验结果:
JRNN采用ACE 2005 corpus作为实验的数据集,得到了如下表所示的实验结果:
从表中,我们可以看到,在所有比较模型中,JRNN获得了最好的F1分数(对于触发器和元素标记)。这对于元素角色标记性能来说是非常重要的(比Chen等人(2015年)报道的最佳模型DMCNN提高了1.9%),并证明了在这项工作中,具有RNN和记忆特征的联合模型的好处。此外,由于JRNN显著优于Li等人(2013)提出的具有离散特征的联合模型(触发器和元素角色标记分别提高了1.8%和2.7%),我们可以确认JRNN在学习EE有效特征表示方面的有效性。
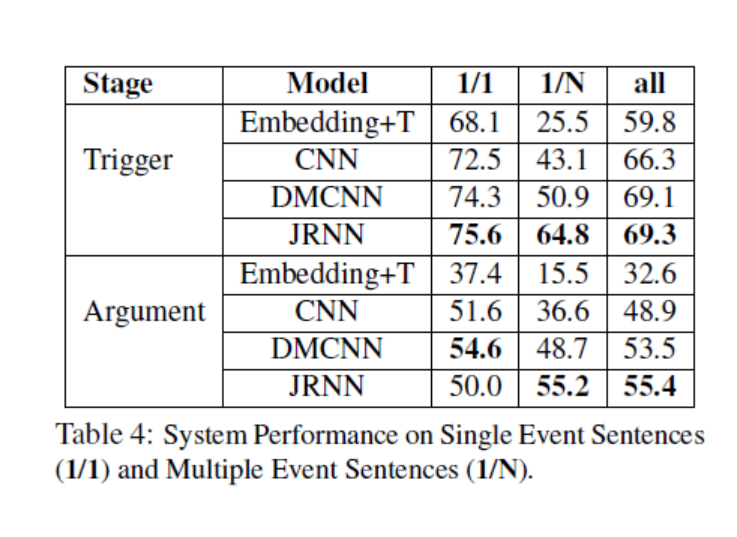
在一个句子中含有多个事件的抽取实验中得到了如下表所示的实验结果。表中最重要的观察结果是,当输入句子包含多个事件(即表中标记为1/N的行)时,JRNN显著优于所有其他具有较大裕度的方法。特别是,JRNN在触发器标记方面比DMCNN好13.9%,而元素角色标记方面的相应改进为6.5%,从而进一步表明了JRNN与内存特性的优势。就单事件句子的性能而言,JRNN在触发器标记上仍然是最好的系统,尽管在元素角色标记上不如DMCNN。这可以部分解释为,DMCNN包含元素的位置嵌入特性,而JRNN中的内存矩阵Garg/trg在这种单事件情况下不起作用
结论:
JRNN提出了一种基于双向RNN的执行事件抽取的联合模型,以克服以往模型的局限性。引入了记忆矩阵,可以有效地捕捉元素角色和触发器子类型之间的依赖关系。我们证明了CBOW单词嵌入对关节模型非常有用。在ACE 2005数据集上,所提出的联合模型在具有多个事件的句子上是有效的,并且产生了最先进的性能。
传统的事件抽取(EE)方法通常依赖于人为标注的数据,耗时耗力,而且标注的数据量不会很大。不充足的数据阻碍了模型的学习。
本文首先提出了一个EE模型——PLMEE,通过将元素(argument)预测按照角色进行分离来克服角色重叠问题。
为了解决训练数据不足的问题,提出了一种通过edit prototypes的方法来自动生成标注数据,并按照数据的质量进行排序,对生成的样本进行筛选。
PLMEE的算法原理:
EE任务的目的是识别出事件触发器和元素。如图所示。

提出的基于预训练语言模型的方法包括2个模块:(1)事件抽取模型;(2)有标签的事件生成方法。
(1)事件抽取模型
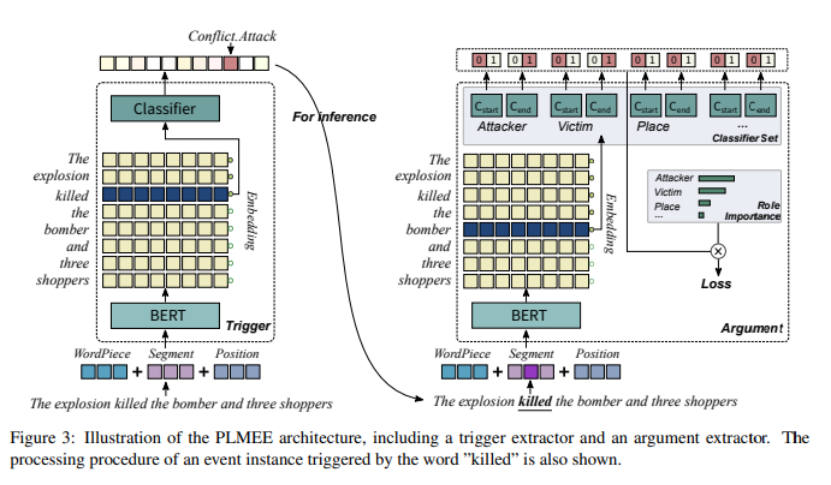
将事件提取作为一个两阶段的任务,包括触发器提取和元素提取,并提出了一个基于预训练语言模型的事件提取器(PLMEE)。图3说明了PLMEE的体系结构。它由一个触发器提取器和一个元素提取器组成,这两者都依赖于BERT的特征表示。
(2)预训练语言模型
预训练语言模型(PLM)用于生成标注数据,有两个关键步骤:1)argument replacement ;2)adjunct token rewriting。
并对生成的样本进行评分,选择出高质量的数据。将这些数据和现有的数据合并,可以增强事件抽取器的性能。
事件抽取模型
将EE看成两个子任务:1)触发器抽取;2)元素抽取,并提出PLMEE模型,模型架构如图3所示。模型由触发器抽取器和元素抽取器两部分组成,两者均依赖于BERT学习到的特征表示。
触发器的抽取
触发器抽取器的目的是预测出触发了事件的token,形式化为token级别的多类别分类任务,分类标签是事件类型。在BERT上添加一个多类分类器就构成了触发器抽取器。
触发器提取器的输入遵循BERT,即三种嵌入类型的总和,包括WordPiece嵌入、位置嵌入和片段嵌入。由于输入只包含一个句子,所以它的所有段id都被设置为零。此外,token[CLS]和[SEP]被放置在句子的开头和结尾。在许多情况下,触发器是一个短语。因此,将共享相同预测标签的连续令牌作为一个整体触发器。一般情况下,采用交叉熵作为损失函数进行微调。
元素的抽取
给定触发器,元素提取器旨在提取相关的元素和它们所扮演的所有角色。与触发器提取相比,元素提取更为复杂,因为有三个问题:元素对触发器的依赖性,大多数元素是长名词短语,以及角色重叠的问题。我们正好采取了一系列的行动来应对这些障碍。与触发器提取器一样,元素提取器也需要三种嵌入。然而,它需要知道哪些令牌构成了触发器。因此,将触发标记的段ids设为1来输入元素提取器。
为了克服元素提取中的后两个问题,论文在BERT上添加了多组二进制分类符。每一组分类器都分离了一个角色,以确定所有播放它的元素的跨度(每个跨度包括一个开始和一个结束)。这种方法类似于SQuAD上的问题回答任务,其中只有一个答案,而扮演相同角色的多个元素可以在一个事件中同时出现。由于预测是用角色分开的,因此一个元素可以扮演多个角色,而一个标记可以属于不同的元素。因此,也可以解决角色重叠问题。
训练数据的生成
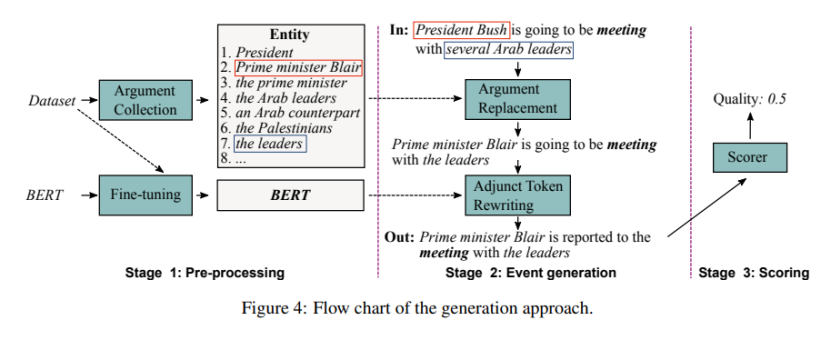
除了PLMEE之外,论文还提出了一种基于预训练的语言模型的事件生成方法,如图4所示。通过编辑原型,该方法可以生成可控数量的标记样本作为额外的训练语料库。它包括三个阶段:预处理、事件生成和评分。为了便于生成方法,论文将辅助标记定义为句子中除触发器和元素外的标记,不仅包括单词和数字,还包括标点符号。以图1中的句子为例,“is”和“going”是附加令牌。很明显,辅助标记可以调节表达的平滑性和多样性。因此,我们试图重写它们,以扩展生成结果的多样性,同时保持触发器和元素不变。
预处理
首先在ACE2005数据集中收集元素以及它们所扮演的角色。然而,这些与其他论点重叠的论点被排除在外。因为这样的元素通常是长的复合短语,包含太多意想不到的信息,将它们合并在元素替换中可能会带来更多不必要的错误。
在接下来的阶段,论文还采用BERT作为目标模型来重写辅助标记,并使用掩码语言模型任务对ACE2005数据集进行微调,以使其预测偏向于数据集分布。与BERT的预训练程序一样,每次抽取一批句子,并掩盖15%的令牌。它的目标仍然是在没有监督的情况下预测正确的标记
事件生成
为了生成事件,论文在一个原型上执行了两个步骤。首先将原型中的参元素替换为那些发挥了相同作用的类似元素。接下来,用精细的BERT重写附加令牌。通过这两个步骤,就可以获得一个带有注释的新句子
(1)元素替换
第一步是在事件中替换元素。要被替换的元素和新的元素都应该发挥同样的作用。虽然角色是在替换后继承的,所以仍然可以为生成的样本使用原点标签。为了不彻底改变意义,使用相似性作为选择新元素的标准。它基于以下两个考虑:一个是发挥相同作用的两个元素在语义上可能存在显著差异;另一个原因是,一个元素所扮演的角色在很大程度上取决于它的上下文。因此,应该选择在语义上相似且与上下文一致的元素
使用嵌入之间的余弦相似度来衡量两个元素的相似性。由于ELMO具有处理OOV问题的能力,论文使用它来嵌入元素:

其中a是元素,E是ELMO嵌入。我们选择最相似的top 10元素作为候选,并对它们的相似性使用softmax操作来分配概率。一个元素被替换为概率80%,同时保持概率20%的概率不变,以使事件表示偏向于实际事件。需要注意的是,触发器保持不变,以避免依赖关系的不良偏差
(2)重写adjunct tokens
元素替换的结果已经可以看作是生成的数据,但固定的上下文可能会增加过拟合的风险。因此,为了平滑数据并扩展其多样性,论文使用微调后的BERT进行adjunct tokens的重写。
重写是为了将原型中的一些辅助标记替换为与当前上下文更匹配的新标记。论文将它作为一个完形填空,其中一些adjunct tokens被随机屏蔽,第一阶段的BERT微调用于基于上下文预测合适令牌的词汇id。论文使用一个元素m来表示需要重写的adjunct tokens的比例。
附加令牌重写是一个一步一步的过程。每次屏蔽15%的adjunct tokens(使用令牌[MASK])。然后将句子输入BERT,产生新的adjunct tokens。尚未被重写的adjunct tokens将暂时保留在句子中。
对事件打分
理论上,用论文的生成方法可以产生无限数量的事件。然而,并不是所有的方法对提取器都有价值,有些甚至可能降低其性能。因此,论文增加了一个额外的阶段来量化每个生成的样本的质量,以挑选出那些有价值的样本。评估质量的关键在于,它与两个元素紧密相关,即困惑度和到原始数据集的距离。前者反映了生成的合理性,后者反映了数据之间的差异。
困惑度(Perplexity, PPL)

A表示在句子S ′中已被重写的adjunct tokens
距离(Distance, DIS)
使用余弦相似性: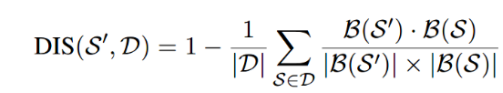
与ELMO的嵌入参数不同,论文利用BERT来嵌入句子,并将嵌入的第一个标记[CLS]作为句子的嵌入。PPL和DIS在[0,1]中都是有限的。论文认为生成的高质量样品应该同时具有低PPL和DIS。因此,将质量函数定义为:![]()
其中λ∈[0,1]为平衡参数。该函数用于选择实验中生成的高质量样本。
实验结果:
PLMEE实验选用的数据集为ACE2005,
实验结果的评估标准:触发器预测正确:span和type和真实值一致;元素预测正确:span和所有角色标签都预测正确。采用精度(P)、召回率(R)和F度量(F1)作为评估指标。得到了如下图所示的实验结果:
表2在测试集上将上述模型的结果与PLMEE进行了比较。如图所示,在触发器提取任务和元素提取任务中,PLMEE(-)在所有比较的方法中都取得了最好的结果。触发器提取的改进非常显著,F1分数大幅增加近10%。虽然元素提取方面的改进不太明显,达到了2%左右。这可能是由于我们采用了更严格的评估标准,以及元素提取任务的难度。此外,与基于特征的方法相比,基于神经网络的方法可以获得更好的性能。在比较基于外部资源的方法和基于神经的方法时,也出现了同样的观察结果。它表明,外部资源对于改进事件提取非常有用。此外,与PLMEE(-)模型相比,PLMEE模型在元素提取任务上可以取得更好的结果,识别F1得分提高0.6%,分类得分提高0.5%,这意味着重新加权损失可以有效提高性能
 表3显示了一个原型及其生成事件,元素m范围为0.2至1.0。可以观察到,替换后的变元与原型中的语境匹配较好,这表明它们在语义上与原型相似。另一方面,重写附加标记可以平滑生成的数据并扩展其多样性。但是,由于没有明确的指导,此步骤还可能引入不可预测的噪声,使生成过程不如预期流畅。
表3显示了一个原型及其生成事件,元素m范围为0.2至1.0。可以观察到,替换后的变元与原型中的语境匹配较好,这表明它们在语义上与原型相似。另一方面,重写附加标记可以平滑生成的数据并扩展其多样性。但是,由于没有明确的指导,此步骤还可能引入不可预测的噪声,使生成过程不如预期流畅。

总结:
论文解决的是EE问题,提出PLMEE模型,模型由事件抽取模型和生成模型两部分组成,这两个模块都使用到了预训练语言模型来引入更丰富的知识。针对角色重叠问题,论文的抽取方法根据角色分离了元素预测,针对每个元素使用一组二分类器,预测元素的角色标签。并根据不同角色对该类型事件的重要性,对损失函数的权重进行了重分配。
针对训练数据有限、人工标注耗时耗力的问题,本文提出了一个事件生成方法,通过元素替换和重写adjunct tokens生成新的事件样本,并使用一个打分函数对样本进行评分,选取高质量的样本作为训练数据的补充。
实验证明了该事件生成模型的有效性,将事件生成模型和事件抽取模型相结合可以增强事件抽取模型的性能。
PLMEE模型的局限性:
(1)同一类型的事件通常具有相似性,并且共现的角色通常有很强的关联,但是PLMEE模型忽略了这些特征。
(2)尽管生成模型中使用了评分函数对生成的样本进行筛选,但仍面临着和远程监督方法一样的角色偏离问题。(因为adjunct tokens重写之后语义可能会发生很大的变化)
未来工作:
将事件间的关联和元素间的关联纳入考虑,并合并到预训练语言模型中;使用更有效的度量方法,克服生成模型的角色偏离问题。