https://dblab.xmu.edu.cn/blog/2738
https://dblab.xmu.edu.cn/blog/2636/
spark 安装
安装 Spark2.4.0
sudo tar -zxf ~/下载/spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark
sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
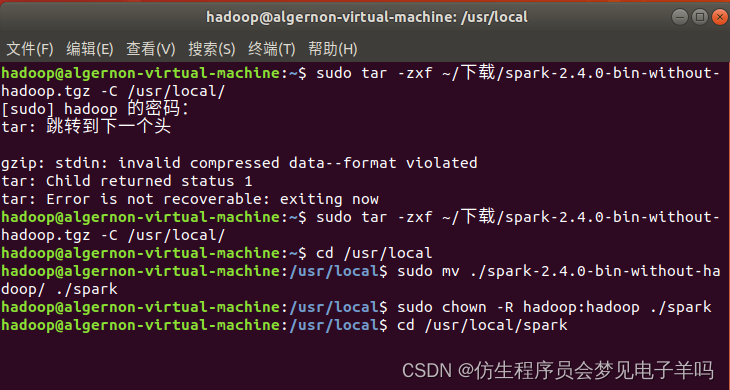
安装后,还需要修改Spark的配置文件spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
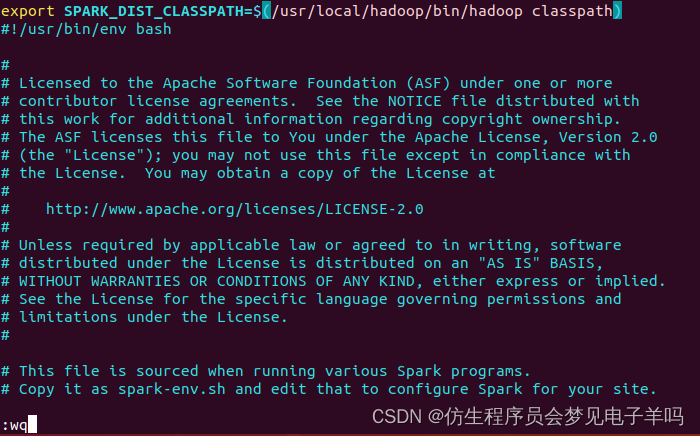
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
通过运行Spark自带的示例,验证Spark是否安装成功。
cd /usr/local/spark
bin/run-example SparkPi

执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
hadoop@algernon-virtual-machine:/usr/local/spark$ bin/run-example SparkPi
2023-03-26 23:34:21 WARN Utils:66 - Your hostname, algernon-virtual-machine resolves to a loopback address: 127.0.1.1; using 192.168.46.140 instead (on interface ens33)
2023-03-26 23:34:21 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address
2023-03-26 23:34:23 WARN NativeCodeLoader:60 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-03-26 23:34:26 INFO SparkContext:54 - Running Spark version 2.4.0
2023-03-26 23:34:26 INFO SparkContext:54 - Submitted application: Spark Pi
2023-03-26 23:34:26 INFO SecurityManager:54 - Changing view acls to: hadoop
2023-03-26 23:34:26 INFO SecurityManager:54 - Changing modify acls to: hadoop
2023-03-26 23:34:26 INFO SecurityManager:54 - Changing view acls groups to:
2023-03-26 23:34:26 INFO SecurityManager:54 - Changing modify acls groups to:
2023-03-26 23:34:26 INFO SecurityManager:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
2023-03-26 23:34:26 INFO Utils:54 - Successfully started service 'sparkDriver' on port 33901.
2023-03-26 23:34:26 INFO SparkEnv:54 - Registering MapOutputTracker
2023-03-26 23:34:26 INFO SparkEnv:54 - Registering BlockManagerMaster
2023-03-26 23:34:26 INFO BlockManagerMasterEndpoint:54 - Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2023-03-26 23:34:26 INFO BlockManagerMasterEndpoint:54 - BlockManagerMasterEndpoint up
2023-03-26 23:34:26 INFO DiskBlockManager:54 - Created local directory at /tmp/blockmgr-0ad19652-f78b-4bfc-9b4a-c3597666be10
2023-03-26 23:34:26 INFO MemoryStore:54 - MemoryStore started with capacity 366.3 MB
2023-03-26 23:34:26 INFO SparkEnv:54 - Registering OutputCommitCoordinator
2023-03-26 23:34:26 INFO log:192 - Logging initialized @27558ms
2023-03-26 23:34:26 INFO Server:351 - jetty-9.3.z-SNAPSHOT, build timestamp: 2018-06-06T01:11:56+08:00, git hash: 84205aa28f11a4f31f2a3b86d1bba2cc8ab69827
2023-03-26 23:34:27 INFO Server:419 - Started @27702ms
2023-03-26 23:34:27 INFO AbstractConnector:278 - Started ServerConnector@7ba63fe5{
HTTP/1.1,[http/1.1]}{
0.0.0.0:4040}
2023-03-26 23:34:27 INFO Utils:54 - Successfully started service 'SparkUI' on port 4040.
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2a3a299{
/jobs,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@64d43929{
/jobs/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1d269ed7{
/jobs/job,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@41c89d2f{
/jobs/job/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@410e94e{
/stages,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2d691f3d{
/stages/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1bdbf9be{
/stages/stage,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@78d39a69{
/stages/stage/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@3c818ac4{
/stages/pool,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@5b69d40d{
/stages/pool/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@71154f21{
/storage,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@15f193b8{
/storage/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2516fc68{
/storage/rdd,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@304a9d7b{
/storage/rdd/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@6bfdb014{
/environment,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@72889280{
/environment/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@606fc505{
/executors,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@4aa3d36{
/executors/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2d140a7{
/executors/threadDump,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@347bdeef{
/executors/threadDump/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2aa27288{
/static,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@2c30b71f{
/,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1d81e101{
/api,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@30cdae70{
/jobs/job/kill,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1654a892{
/stages/stage/kill,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO SparkUI:54 - Bound SparkUI to 0.0.0.0, and started at http://192.168.46.140:4040
2023-03-26 23:34:27 INFO SparkContext:54 - Added JAR file:///usr/local/spark/examples/jars/scopt_2.11-3.7.0.jar at spark://192.168.46.140:33901/jars/scopt_2.11-3.7.0.jar with timestamp 1679844867099
2023-03-26 23:34:27 INFO SparkContext:54 - Added JAR file:///usr/local/spark/examples/jars/spark-examples_2.11-2.4.0.jar at spark://192.168.46.140:33901/jars/spark-examples_2.11-2.4.0.jar with timestamp 1679844867099
2023-03-26 23:34:27 INFO Executor:54 - Starting executor ID driver on host localhost
2023-03-26 23:34:27 INFO Utils:54 - Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 40833.
2023-03-26 23:34:27 INFO NettyBlockTransferService:54 - Server created on 192.168.46.140:40833
2023-03-26 23:34:27 INFO BlockManager:54 - Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
2023-03-26 23:34:27 INFO BlockManagerMaster:54 - Registering BlockManager BlockManagerId(driver, 192.168.46.140, 40833, None)
2023-03-26 23:34:27 INFO BlockManagerMasterEndpoint:54 - Registering block manager 192.168.46.140:40833 with 366.3 MB RAM, BlockManagerId(driver, 192.168.46.140, 40833, None)
2023-03-26 23:34:27 INFO BlockManagerMaster:54 - Registered BlockManager BlockManagerId(driver, 192.168.46.140, 40833, None)
2023-03-26 23:34:27 INFO BlockManager:54 - Initialized BlockManager: BlockManagerId(driver, 192.168.46.140, 40833, None)
2023-03-26 23:34:27 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@34dc85a{
/metrics/json,null,AVAILABLE,@Spark}
2023-03-26 23:34:27 INFO SparkContext:54 - Starting job: reduce at SparkPi.scala:38
2023-03-26 23:34:27 INFO DAGScheduler:54 - Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
2023-03-26 23:34:27 INFO DAGScheduler:54 - Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
2023-03-26 23:34:27 INFO DAGScheduler:54 - Parents of final stage: List()
2023-03-26 23:34:27 INFO DAGScheduler:54 - Missing parents: List()
2023-03-26 23:34:27 INFO DAGScheduler:54 - Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
2023-03-26 23:34:28 INFO MemoryStore:54 - Block broadcast_0 stored as values in memory (estimated size 1936.0 B, free 366.3 MB)
2023-03-26 23:34:28 INFO MemoryStore:54 - Block broadcast_0_piece0 stored as bytes in memory (estimated size 1256.0 B, free 366.3 MB)
2023-03-26 23:34:28 INFO BlockManagerInfo:54 - Added broadcast_0_piece0 in memory on 192.168.46.140:40833 (size: 1256.0 B, free: 366.3 MB)
2023-03-26 23:34:28 INFO SparkContext:54 - Created broadcast 0 from broadcast at DAGScheduler.scala:1161
2023-03-26 23:34:28 INFO DAGScheduler:54 - Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
2023-03-26 23:34:28 INFO TaskSchedulerImpl:54 - Adding task set 0.0 with 2 tasks
2023-03-26 23:34:28 INFO TaskSetManager:54 - Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7866 bytes)
2023-03-26 23:34:28 INFO TaskSetManager:54 - Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 7866 bytes)
2023-03-26 23:34:28 INFO Executor:54 - Running task 0.0 in stage 0.0 (TID 0)
2023-03-26 23:34:28 INFO Executor:54 - Running task 1.0 in stage 0.0 (TID 1)
2023-03-26 23:34:28 INFO Executor:54 - Fetching spark://192.168.46.140:33901/jars/scopt_2.11-3.7.0.jar with timestamp 1679844867099
2023-03-26 23:34:28 INFO TransportClientFactory:267 - Successfully created connection to /192.168.46.140:33901 after 28 ms (0 ms spent in bootstraps)
2023-03-26 23:34:28 INFO Utils:54 - Fetching spark://192.168.46.140:33901/jars/scopt_2.11-3.7.0.jar to /tmp/spark-b78a374f-111d-4ff3-81ec-6e806aa62da3/userFiles-d3452412-f3fd-4537-b848-a839e587e22d/fetchFileTemp8254869077053879079.tmp
2023-03-26 23:34:28 INFO Executor:54 - Adding file:/tmp/spark-b78a374f-111d-4ff3-81ec-6e806aa62da3/userFiles-d3452412-f3fd-4537-b848-a839e587e22d/scopt_2.11-3.7.0.jar to class loader
2023-03-26 23:34:28 INFO Executor:54 - Fetching spark://192.168.46.140:33901/jars/spark-examples_2.11-2.4.0.jar with timestamp 1679844867099
2023-03-26 23:34:28 INFO Utils:54 - Fetching spark://192.168.46.140:33901/jars/spark-examples_2.11-2.4.0.jar to /tmp/spark-b78a374f-111d-4ff3-81ec-6e806aa62da3/userFiles-d3452412-f3fd-4537-b848-a839e587e22d/fetchFileTemp8998672681604896365.tmp
2023-03-26 23:34:28 INFO Executor:54 - Adding file:/tmp/spark-b78a374f-111d-4ff3-81ec-6e806aa62da3/userFiles-d3452412-f3fd-4537-b848-a839e587e22d/spark-examples_2.11-2.4.0.jar to class loader
2023-03-26 23:34:28 INFO Executor:54 - Finished task 1.0 in stage 0.0 (TID 1). 867 bytes result sent to driver
2023-03-26 23:34:28 INFO Executor:54 - Finished task 0.0 in stage 0.0 (TID 0). 867 bytes result sent to driver
2023-03-26 23:34:28 INFO TaskSetManager:54 - Finished task 0.0 in stage 0.0 (TID 0) in 404 ms on localhost (executor driver) (1/2)
2023-03-26 23:34:28 INFO TaskSetManager:54 - Finished task 1.0 in stage 0.0 (TID 1) in 389 ms on localhost (executor driver) (2/2)
2023-03-26 23:34:28 INFO TaskSchedulerImpl:54 - Removed TaskSet 0.0, whose tasks have all completed, from pool
2023-03-26 23:34:28 INFO DAGScheduler:54 - ResultStage 0 (reduce at SparkPi.scala:38) finished in 0.666 s
2023-03-26 23:34:28 INFO DAGScheduler:54 - Job 0 finished: reduce at SparkPi.scala:38, took 0.747248 s
Pi is roughly 3.1462957314786575
2023-03-26 23:34:28 INFO AbstractConnector:318 - Stopped Spark@7ba63fe5{
HTTP/1.1,[http/1.1]}{
0.0.0.0:4040}
2023-03-26 23:34:28 INFO SparkUI:54 - Stopped Spark web UI at http://192.168.46.140:4040
2023-03-26 23:34:28 INFO MapOutputTrackerMasterEndpoint:54 - MapOutputTrackerMasterEndpoint stopped!
2023-03-26 23:34:28 INFO MemoryStore:54 - MemoryStore cleared
2023-03-26 23:34:28 INFO BlockManager:54 - BlockManager stopped
2023-03-26 23:34:28 INFO BlockManagerMaster:54 - BlockManagerMaster stopped
2023-03-26 23:34:28 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:54 - OutputCommitCoordinator stopped!
2023-03-26 23:34:28 INFO SparkContext:54 - Successfully stopped SparkContext
2023-03-26 23:34:28 INFO ShutdownHookManager:54 - Shutdown hook called
2023-03-26 23:34:28 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-7dd0b4a9-d5ee-4945-9fe9-3c330363584d
2023-03-26 23:34:28 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-b78a374f-111d-4ff3-81ec-6e806aa62da3
hadoop@algernon-virtual-machine:/usr/local/spark$
cd /usr/local/spark
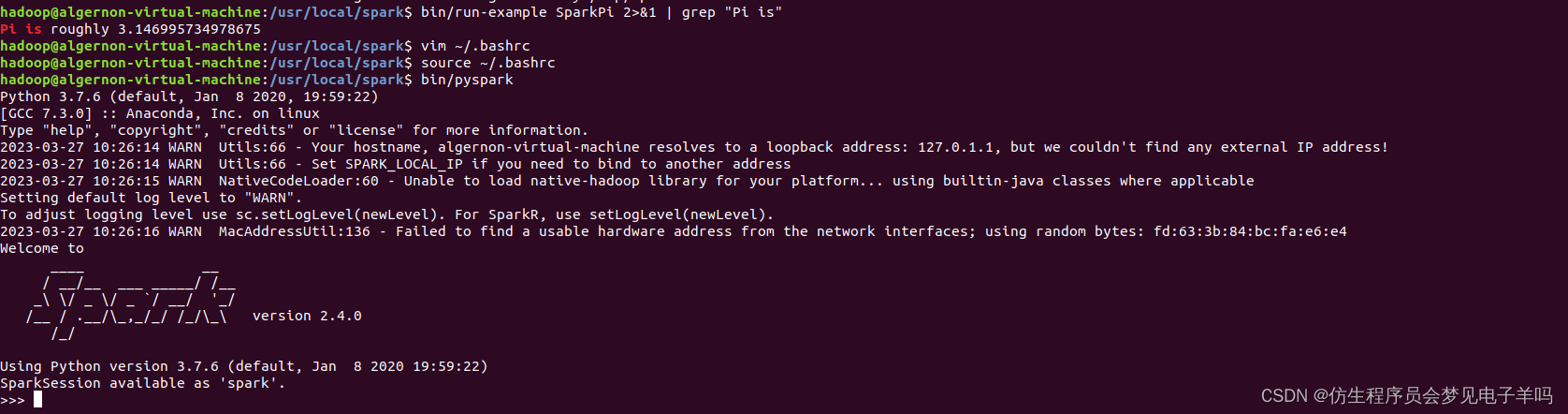
bin/run-example SparkPi 2>&1 | grep "Pi is"
过滤后的运行结果如下图示,可以得到π 的 5 位小数近似值:

启动Spark Shell
cd /usr/local/spark
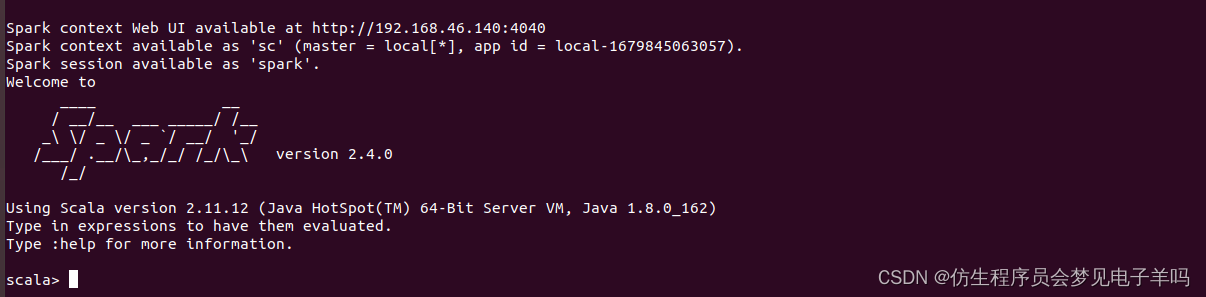
bin/spark-shell
启动spark-shell后,会自动创建名为sc的SparkContext对象和名为spark的SparkSession对象,如图:
加载text文件
spark创建sc,可以加载本地文件和HDFS文件创建RDD。这里用Spark自带的本地文件README.md文件测试。
val textFile = sc.textFile("file:///usr/local/spark/README.md")

加载HDFS文件和本地文件都是使用textFile,区别是添加前缀(hdfs://和file:///)进行标识。
简单RDD操作
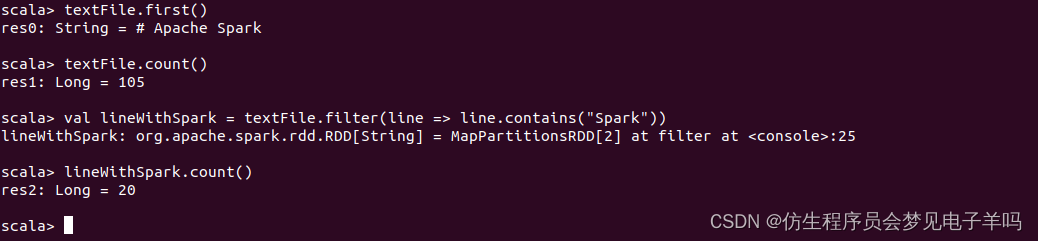
//获取RDD文件textFile的第一行内容
textFile.first()
//获取RDD文件textFile所有项的计数
textFile.count()
//抽取含有“Spark”的行,返回一个新的RDD
val lineWithSpark = textFile.filter(line => line.contains("Spark"))
//统计新的RDD的行数
lineWithSpark.count()
可以通过组合RDD操作进行组合,可以实现简易MapReduce操作
//找出文本中每行的最多单词数
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)

退出Spark Shell
输入exit,即可退出spark shell
:quit

独立应用程序编程
安装sbt
sudo mkdir /usr/local/sbt # 创建安装目录
cd ~/Downloads
sudo tar -zxvf ./sbt-1.3.8.tgz -C /usr/local
cd /usr/local/sbt
sudo chown -R hadoop /usr/local/sbt # 此处的hadoop为系统当前用户名
cp ./bin/sbt-launch.jar ./ #把bin目录下的sbt-launch.jar复制到sbt安装目录下
接着在安装目录中使用下面命令创建一个Shell脚本文件,用于启动sbt:
vim /usr/local/sbt/sbt
该脚本文件中的代码如下:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"

保存后,还需要为该Shell脚本文件增加可执行权限:
chmod u+x /usr/local/sbt/sbt
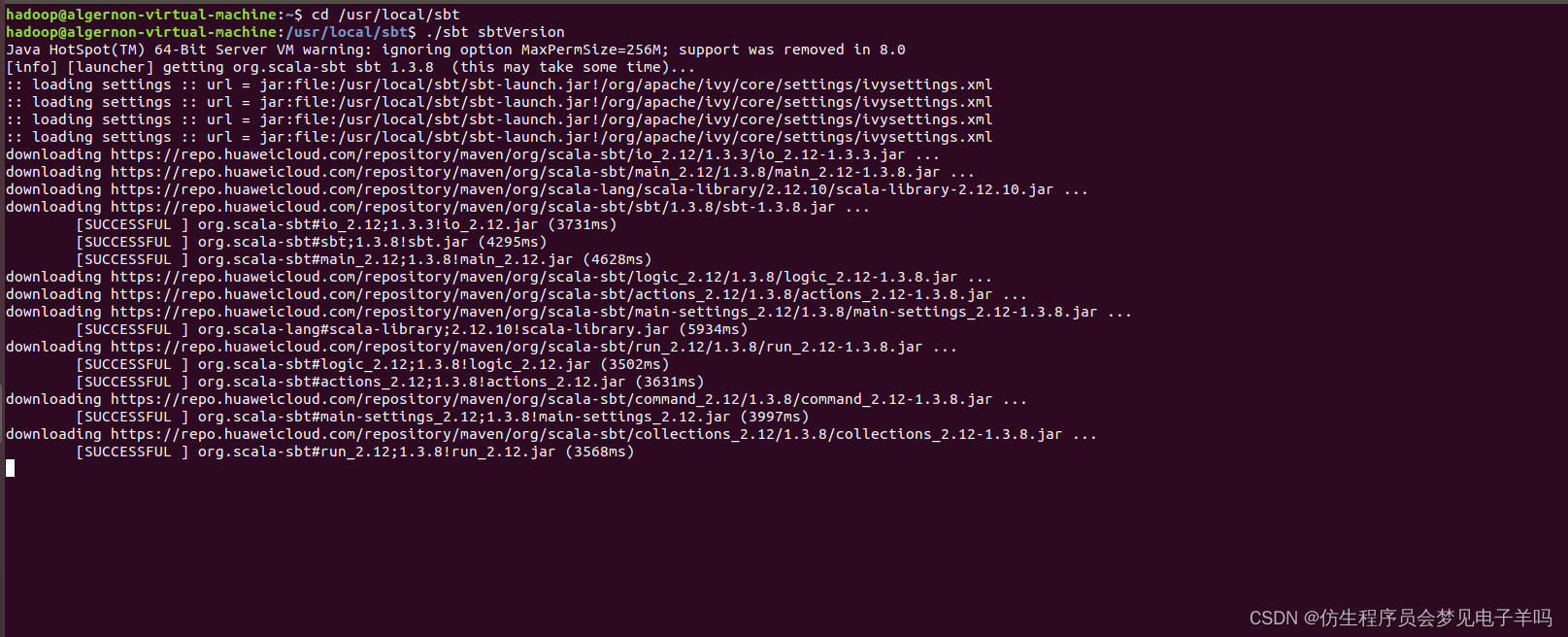
然后,可以使用如下命令查看sbt版本信息:
cd /usr/local/sbt
./sbt sbtVersion
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[warn] No sbt.version set in project/build.properties, base directory: /usr/local/sbt
[info] Set current project to sbt (in build file:/usr/local/sbt/)
[info] 1.3.8
Scala应用程序代码
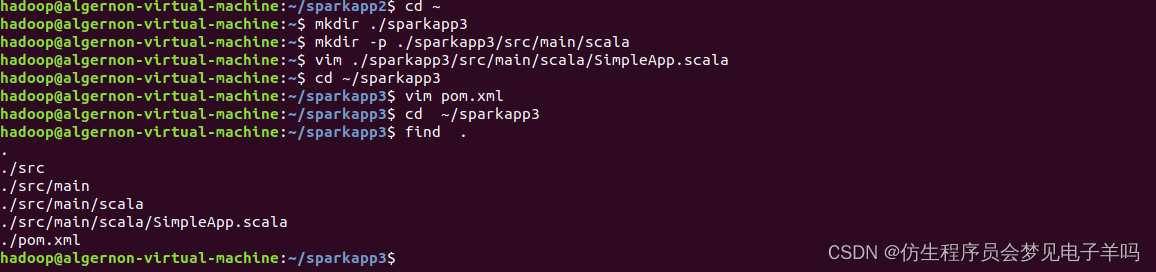
在终端中执行如下命令创建一个文件夹 sparkapp 作为应用程序根目录:
cd ~ # 进入用户主文件夹
mkdir ./sparkapp # 创建应用程序根目录
mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构

在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(vim ./sparkapp/src/main/scala/SimpleApp.scala),添加代码如下:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。代码第8行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。不同于 Spark shell,独立应用程序需要通过 val sc = new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。
该程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包。 在~/sparkapp这个目录中新建文件simple.sbt,命令如下:
cd ~/sparkapp
vim simple.sbt
在simple.sbt中添加如下内容,声明该独立应用程序的信息以及与 Spark 的依赖关系:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"

使用 sbt 打包 Scala 程序
为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:
cd ~/sparkapp
find .

接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ):
/usr/local/sbt/sbt package

通过 spark-submit 运行程序
最后,我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下:
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
# 上面命令执行后会输出太多信息,可以不使用上面命令,而使用下面命令查看想要的结果
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar 2>&1 | grep "Lines with a:"
最终结果如下:

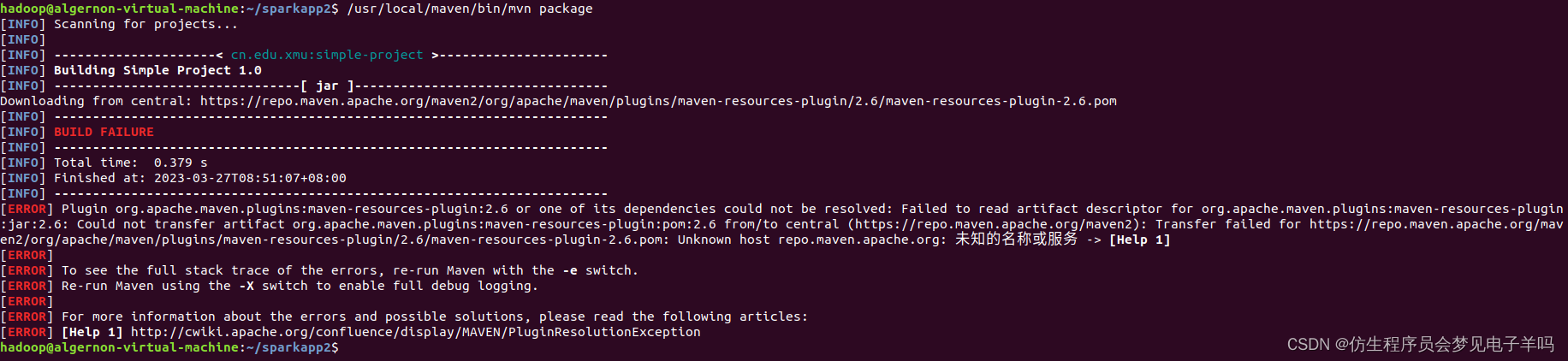
使用Maven对Java独立应用程序进行编译打包
sudo unzip ~/下载/apache-maven-3.6.3-bin.zip -d /usr/local
cd /usr/local
sudo mv apache-maven-3.6.3/ ./maven
sudo chown -R hadoop ./maven
cd ~ #进入用户主文件夹
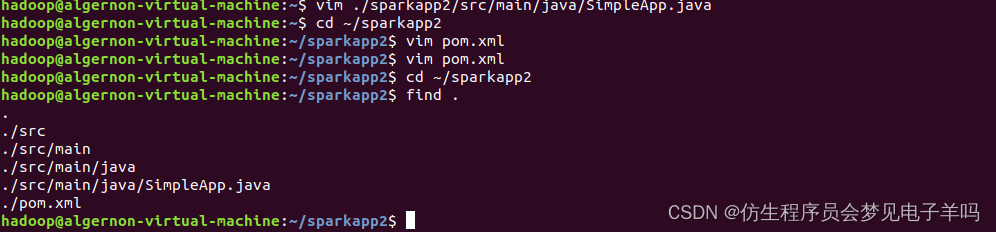
mkdir -p ./sparkapp2/src/main/java
在 ./sparkapp2/src/main/java 下建立一个名为 SimpleApp.java 的文件(vim ./sparkapp2/src/main/java/SimpleApp.java),添加代码如下:
/*** SimpleApp.java ***/
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.SparkConf;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "file:///usr/local/spark/README.md"; // Should be some file on your system
SparkConf conf=new SparkConf().setMaster("local").setAppName("SimpleApp");
JavaSparkContext sc=new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache();
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) {
return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) {
return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
}
}
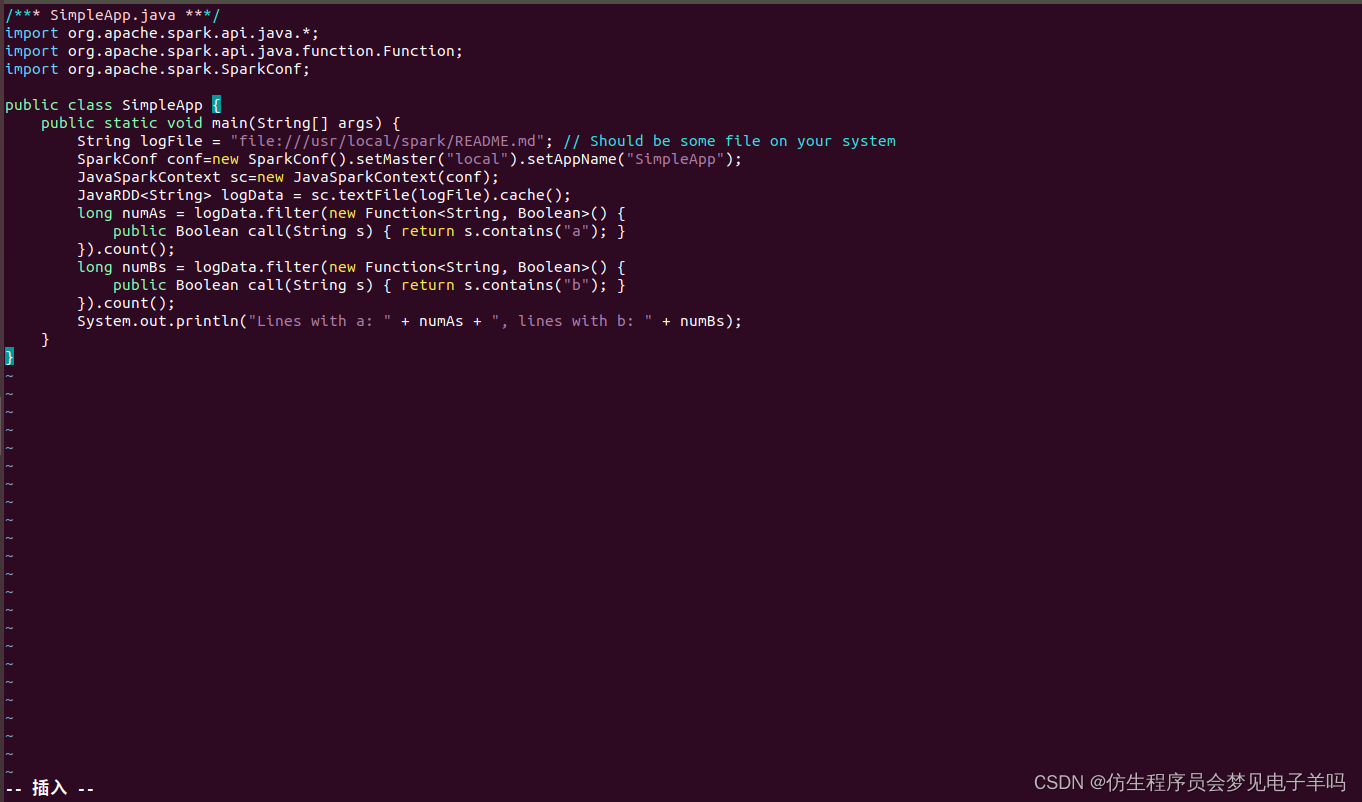
该程序依赖Spark Java API,因此我们需要通过Maven进行编译打包。在./sparkapp2目录中新建文件pom.xml,命令如下:
cd ~/sparkapp2
vim pom.xml
在pom.xml文件中添加内容如下,声明该独立应用程序的信息以及与Spark的依赖关系:
<project>
<groupId>cn.edu.xmu</groupId>
<artifactId>simple-project</artifactId>
<modelVersion>4.0.0</modelVersion>
<name>Simple Project</name>
<packaging>jar</packaging>
<version>1.0</version>
<repositories>
<repository>
<id>jboss</id>
<name>JBoss Repository</name>
<url>http://repository.jboss.com/maven2/</url>
</repository>
</repositories>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
</dependencies>
</project>

jupyter notebook 安装及使用
安装anaconda
cd /home/hadoop
bash Anaconda3-2020.02-Linux-x86_64.sh
安装成功以后,可以看到如下信息。
安装结束后,要关闭当前终端。然后重新打开一个终端,输入命令:conda -V,可以查看版本信息,如下图所示。
可以查看Anaconda的版本信息,命令如下:
anaconda -V

这时,你会发现,在命令提示符的开头多了一个(base),看着很难受,可以在终端中运行如下命令,消除这个(base):
conda config --set auto_activate_base false

然后,关闭终端,再次新建一个终端,可以看到,已经没有(base)了。但是,这时,输入“anaconda -V”命令就会失败,提示找不到命令。
这时,需要到~/.bashrc文件中修改配置,执行如下命令打开文件:
vim ~/.bashrc
打开文件以后,按键盘上的i键,进入编辑状态,然后,在PATH环境配置中,把“/home/hadoop/anaconda3/bin”增加到PATH的末尾,也就是用英文冒号和PATH的其他部分连接起来,
然后保存退出文件(先按Esc键退出文件编辑状态,再输入:wq(注意是英文冒号),再回车,就可以保存退出文件)。再执行如下命令使得配置立即生效:
source ~/.bashrc
执行完source命令以后,就可以成功执行“anaconda -V”命令了。
配置Jupyter Notebook
下面开始配置Jupyter Notebook,在终端中执行如下命令:
jupyter notebook --generate-config
然后,在终端中执行如下命令:
cd /home/hadoop/anaconda3/bin
./python
然后,在Python命令提示符(不是Linux Shell命令提示符)后面输入如下命令:
>>>from notebook.auth import passwd
>>>passwd()
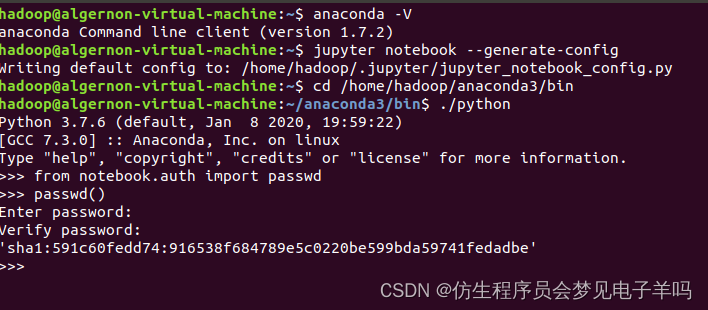
此时系统会让输入密码,并让你确认密码(如:123456),这个密码是后面进入到Jupyter网页页面的密码。然后系统会生成一个密码字符串,比如sha1:7c7990750e83:965c1466a4fab0849051ca5f3c5661110813795,把这个sha1字符串复制粘贴到一个文件中保存起来,后面用于配置密码。具体如下图所示:
'sha1:591c60fedd74:916538f684789e5c0220be599bda59741fedadbe'
'sha1:8f6545b8d0cf:41ec531eaf0df13e77f2846221a97516020a16f5'
然后,在Python命令提示符后面输入“exit()”,退出Python。
下面开始配置文件。
在终端输入如下命令:
vim ~/.jupyter/jupyter_notebook_config.py
进入到配置文件页面,在文件的开头增加以下内容:
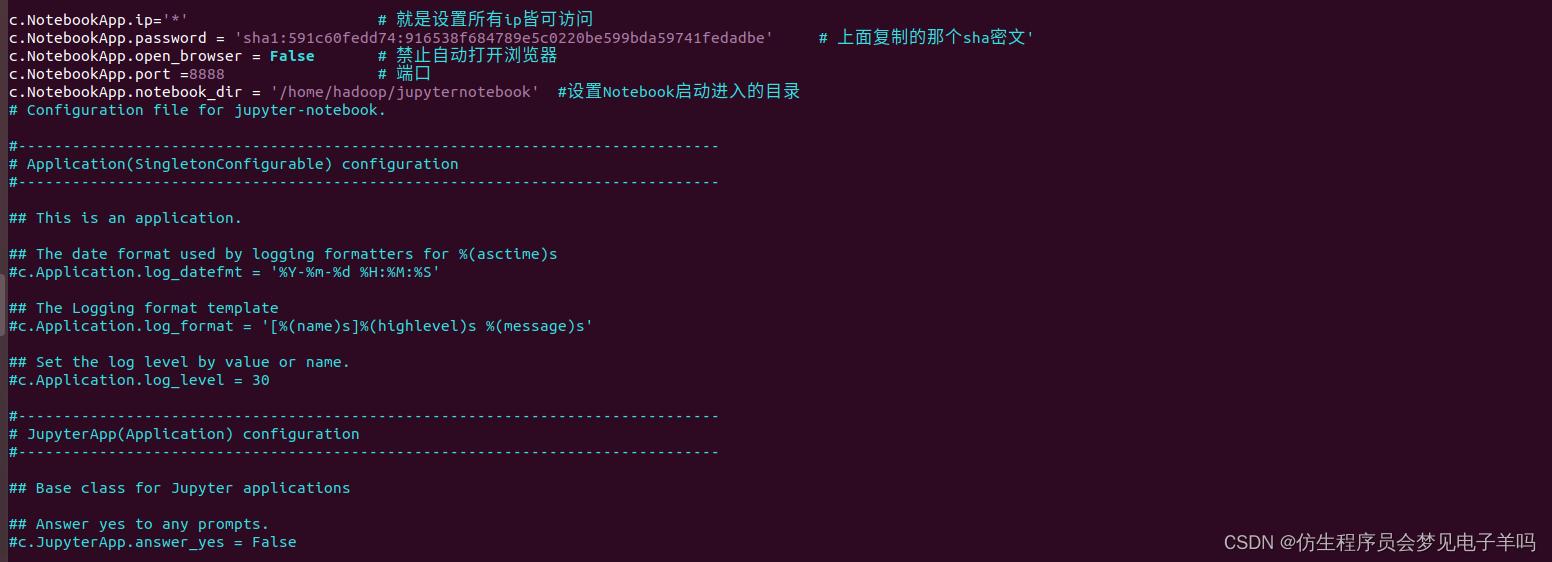
c.NotebookApp.ip='*' # 就是设置所有ip皆可访问
c.NotebookApp.password = 'sha1:7c7990750e83:965c1466a4fab0849051ca5f3c5661110813795b' # 上面复制的那个sha密文'
c.NotebookApp.open_browser = False # 禁止自动打开浏览器
c.NotebookApp.port =8888 # 端口
c.NotebookApp.notebook_dir = '/home/hadoop/jupyternotebook' #设置Notebook启动进入的目录
配置文件如下图所示:

然后保存并退出vim文件(Esc键,输入:wq)
需要注意的是,在配置文件中,c.NotebookApp.password的值,就是刚才前面生成以后保存到文件中的sha1密文。另外,c.NotebookApp.notebook_dir = ‘/home/hadoop/jupyternotebook’ 这行用于设置Notebook启动进入的目录,由于该目录还不存在,所以需要在终端中执行如下命令创建:
cd /home/hadoop
mkdir jupyternotebook
运行Jupyter Notebook
下面开始运行Jupyter Notebook。
在终端输入如下命令:
jupyter notebook
打开浏览器,输入http://localhost:8888
会弹出对话框,输入Python密码123456,点击“Log in”,如下图所示。
配置Jupyter Notebook实现和PySpark交互
在终端中输入如下命令:
vim ~/.bashrc
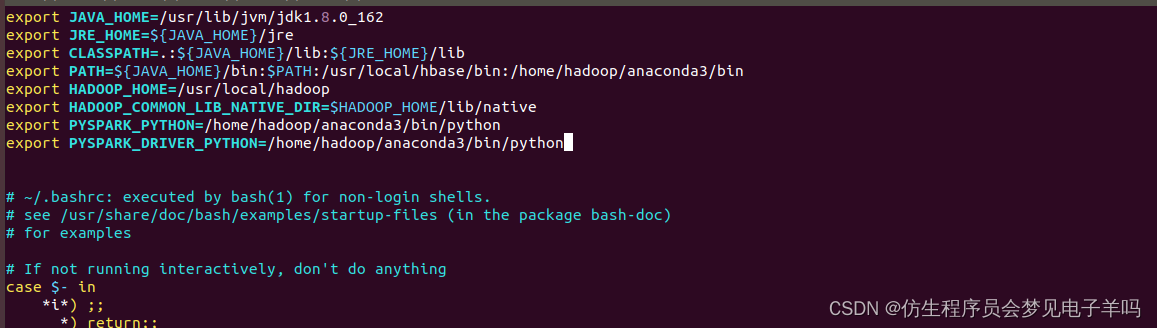
然后,在.bashrc文件中把原来已经存在的一行“export PYSPARK_PYTHON=python3”删除,然后,在该文件中增加如下两行:
export PYSPARK_PYTHON=/home/hadoop/anaconda3/bin/python
export PYSPARK_DRIVER_PYTHON=/home/hadoop/anaconda3/bin/python
然后,保存退出该文件。然后执行如下命令让配置生效:
source ~/.bashrc
然后,在Jupyter Notebook首页中,点击“New”,再点击“Python3”,另外新建一个代码文件,把文件保存名称为CountLine,在文件中输入如下内容:
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
logFile = "file:///usr/local/spark/README.md"
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))
然后,点击界面上的“Run”按钮运行该代码,会出现统计结果“Lines with a: 62, Lines with b: 31”,执行效果如下:

数据分析
格式转换
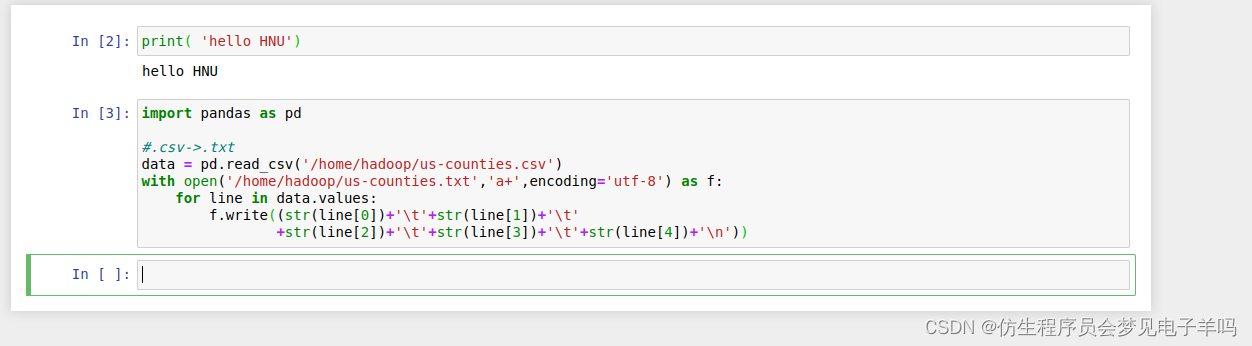
原始数据集是以.csv文件组织的,为了方便spark读取生成RDD或者DataFrame,首先将us-counties.csv转换为.txt格式文件us-counties.txt。转换操作使用python实现,代码组织在toTxt.py中,具体代码如下:
import pandas as pd
#.csv->.txt
data = pd.read_csv('/home/hadoop/us-counties.csv')
with open('/home/hadoop/us-counties.txt','a+',encoding='utf-8') as f:
for line in data.values:
f.write((str(line[0])+'\t'+str(line[1])+'\t'
+str(line[2])+'\t'+str(line[3])+'\t'+str(line[4])+'\n'))
将文件上传至HDFS文件系统中
然后使用如下命令把本地文件系统的“/home/hadoop/us-counties.txt”上传到HDFS文件系统中,具体路径是“/user/hadoop/us-counties.txt”。具体命令如下:
./bin/hdfs dfs -put /home/hadoop/us-counties.txt /user/hadoop
使用Spark对数据进行分析
记得先启动hadoop
from pyspark import SparkConf,SparkContext
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from datetime import datetime
import pyspark.sql.functions as func
def toDate(inputStr):
newStr = ""
if len(inputStr) == 8:
s1 = inputStr[0:4]
s2 = inputStr[5:6]
s3 = inputStr[7]
newStr = s1+"-"+"0"+s2+"-"+"0"+s3
else:
s1 = inputStr[0:4]
s2 = inputStr[5:6]
s3 = inputStr[7:]
newStr = s1+"-"+"0"+s2+"-"+s3
date = datetime.strptime(newStr, "%Y-%m-%d")
return date
#主程序:
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
fields = [StructField("date", DateType(),False),StructField("county", StringType(),False),StructField("state", StringType(),False),
StructField("cases", IntegerType(),False),StructField("deaths", IntegerType(),False),]
schema = StructType(fields)
rdd0 = spark.sparkContext.textFile("/user/hadoop/us-counties.txt")
rdd1 = rdd0.map(lambda x:x.split("\t")).map(lambda p: Row(toDate(p[0]),p[1],p[2],int(p[3]),int(p[4])))
shemaUsInfo = spark.createDataFrame(rdd1,schema)
shemaUsInfo.createOrReplaceTempView("usInfo")
#1.计算每日的累计确诊病例数和死亡数
df = shemaUsInfo.groupBy("date").agg(func.sum("cases"),func.sum("deaths")).sort(shemaUsInfo["date"].asc())
#列重命名
df1 = df.withColumnRenamed("sum(cases)","cases").withColumnRenamed("sum(deaths)","deaths")
df1.repartition(1).write.json("result1.json") #写入hdfs
#注册为临时表供下一步使用
df1.createOrReplaceTempView("ustotal")
#2.计算每日较昨日的新增确诊病例数和死亡病例数
df2 = spark.sql("select t1.date,t1.cases-t2.cases as caseIncrease,t1.deaths-t2.deaths as deathIncrease from ustotal t1,ustotal t2 where t1.date = date_add(t2.date,1)")
df2.sort(df2["date"].asc()).repartition(1).write.json("result2.json") #写入hdfs
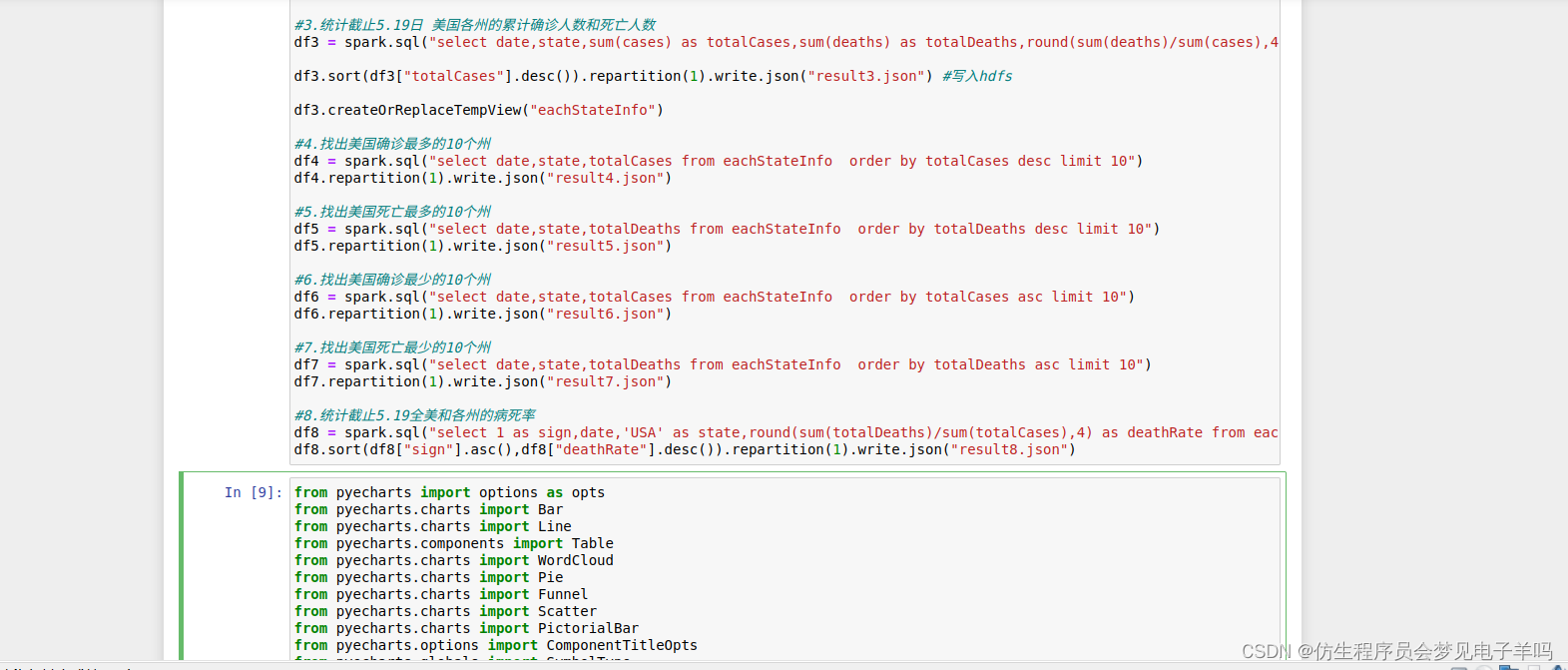
#3.统计截止5.19日 美国各州的累计确诊人数和死亡人数
df3 = spark.sql("select date,state,sum(cases) as totalCases,sum(deaths) as totalDeaths,round(sum(deaths)/sum(cases),4) as deathRate from usInfo where date = to_date('2020-05-19','yyyy-MM-dd') group by date,state")
df3.sort(df3["totalCases"].desc()).repartition(1).write.json("result3.json") #写入hdfs
df3.createOrReplaceTempView("eachStateInfo")
#4.找出美国确诊最多的10个州
df4 = spark.sql("select date,state,totalCases from eachStateInfo order by totalCases desc limit 10")
df4.repartition(1).write.json("result4.json")
#5.找出美国死亡最多的10个州
df5 = spark.sql("select date,state,totalDeaths from eachStateInfo order by totalDeaths desc limit 10")
df5.repartition(1).write.json("result5.json")
#6.找出美国确诊最少的10个州
df6 = spark.sql("select date,state,totalCases from eachStateInfo order by totalCases asc limit 10")
df6.repartition(1).write.json("result6.json")
#7.找出美国死亡最少的10个州
df7 = spark.sql("select date,state,totalDeaths from eachStateInfo order by totalDeaths asc limit 10")
df7.repartition(1).write.json("result7.json")
#8.统计截止5.19全美和各州的病死率
df8 = spark.sql("select 1 as sign,date,'USA' as state,round(sum(totalDeaths)/sum(totalCases),4) as deathRate from eachStateInfo group by date union select 2 as sign,date,state,deathRate from eachStateInfo").cache()
df8.sort(df8["sign"].asc(),df8["deathRate"].desc()).repartition(1).write.json("result8.json")

输出结果:
读取文件生成DataFrame
上面已经给出了完整代码。下面我们再对代码做一些简要介绍。首先看看读取文件生成DataFrame。
由于本实验中使用的数据为结构化数据,因此可以使用spark读取源文件生成DataFrame以方便进行后续分析实现。
本部分代码组织在analyst.py中,读取us-counties.txt生成DataFrame的代码如下:
from pyspark import SparkConf,SparkContext
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from datetime import datetime
import pyspark.sql.functions as func
def toDate(inputStr):
newStr = ""
if len(inputStr) == 8:
s1 = inputStr[0:4]
s2 = inputStr[5:6]
s3 = inputStr[7]
newStr = s1+"-"+"0"+s2+"-"+"0"+s3
else:
s1 = inputStr[0:4]
s2 = inputStr[5:6]
s3 = inputStr[7:]
newStr = s1+"-"+"0"+s2+"-"+s3
date = datetime.strptime(newStr, "%Y-%m-%d")
return date
#主程序:
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
fields = [StructField("date", DateType(),False),StructField("county", StringType(),False),StructField("state", StringType(),False),
StructField("cases", IntegerType(),False),StructField("deaths", IntegerType(),False),]
schema = StructType(fields)
rdd0 = spark.sparkContext.textFile("/user/hadoop/us-counties.txt")
rdd1 = rdd0.map(lambda x:x.split("\t")).map(lambda p: Row(toDate(p[0]),p[1],p[2],int(p[3]),int(p[4])))
shemaUsInfo = spark.createDataFrame(rdd1,schema)
shemaUsInfo.createOrReplaceTempView("usInfo")
进行数据分析
本实验主要统计以下8个指标,分别是:
- 统计美国截止每日的累计确诊人数和累计死亡人数。做法是以date作为分组字段,对cases和deaths字段进行汇总统计。
- 统计美国每日的新增确诊人数和新增死亡人数。因为新增数=今日数-昨日数,所以考虑使用自连接,连接条件是t1.date = t2.date + 1,然后使用t1.totalCases – t2.totalCases计算该日新增。
- 统计截止5.19日,美国各州的累计确诊人数和死亡人数。首先筛选出5.19日的数据,然后以state作为分组字段,对cases和deaths字段进行汇总统计。
- 统计截止5.19日,美国确诊人数最多的十个州。对3)的结果DataFrame注册临时表,然后按确诊人数降序排列,并取前10个州。
- 统计截止5.19日,美国死亡人数最多的十个州。对3)的结果DataFrame注册临时表,然后按死亡人数降序排列,并取前10个州。
- 统计截止5.19日,美国确诊人数最少的十个州。对3)的结果DataFrame注册临时表,然后按确诊人数升序排列,并取前10个州。
- 统计截止5.19日,美国死亡人数最少的十个州。对3)的结果DataFrame注册临时表,然后按死亡人数升序排列,并取前10个州
- 统计截止5.19日,全美和各州的病死率。病死率 = 死亡数/确诊数,对3)的结果DataFrame注册临时表,然后按公式计算。
在计算以上几个指标过程中,根据实现的简易程度,既采用了DataFrame自带的操作函数,又采用了spark sql进行操作。
数据可视化
选择使用python第三方库pyecharts作为可视化工具。
在使用前,需要安装pyecharts,安装代码如下:
pip install pyecharts
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.charts import Line
from pyecharts.components import Table
from pyecharts.charts import WordCloud
from pyecharts.charts import Pie
from pyecharts.charts import Funnel
from pyecharts.charts import Scatter
from pyecharts.charts import PictorialBar
from pyecharts.options import ComponentTitleOpts
from pyecharts.globals import SymbolType
import json
#1.画出每日的累计确诊病例数和死亡数——>双柱状图
def drawChart_1(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
date = []
cases = []
deaths = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
date.append(str(js['date']))
cases.append(int(js['cases']))
deaths.append(int(js['deaths']))
d = (
Bar()
.add_xaxis(date)
.add_yaxis("累计确诊人数", cases, stack="stack1")
.add_yaxis("累计死亡人数", deaths, stack="stack1")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="美国每日累计确诊和死亡人数"))
.render("/home/hadoop/result/result1/result1.html")
)
#2.画出每日的新增确诊病例数和死亡数——>折线图
def drawChart_2(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
date = []
cases = []
deaths = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
date.append(str(js['date']))
cases.append(int(js['caseIncrease']))
deaths.append(int(js['deathIncrease']))
(
Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(xaxis_data=date)
.add_yaxis(
series_name="新增确诊",
y_axis=cases,
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值")
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_="average", name="平均值")]
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="美国每日新增确诊折线图", subtitle=""),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("/home/hadoop/result/result2/result1.html")
)
(
Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(xaxis_data=date)
.add_yaxis(
series_name="新增死亡",
y_axis=deaths,
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(type_="max", name="最大值")]
),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="average", name="平均值"),
opts.MarkLineItem(symbol="none", x="90%", y="max"),
opts.MarkLineItem(symbol="circle", type_="max", name="最高点"),
]
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="美国每日新增死亡折线图", subtitle=""),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("/home/hadoop/result/result2/result2.html")
)
#3.画出截止5.19,美国各州累计确诊、死亡人数和病死率--->表格
def drawChart_3(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
allState = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
row = []
row.append(str(js['state']))
row.append(int(js['totalCases']))
row.append(int(js['totalDeaths']))
row.append(float(js['deathRate']))
allState.append(row)
table = Table()
headers = ["State name", "Total cases", "Total deaths", "Death rate"]
rows = allState
table.add(headers, rows)
table.set_global_opts(
title_opts=ComponentTitleOpts(title="美国各州疫情一览", subtitle="")
)
table.render("/home/hadoop/result/result3/result1.html")
#4.画出美国确诊最多的10个州——>词云图
def drawChart_4(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
data = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
row=(str(js['state']),int(js['totalCases']))
data.append(row)
c = (
WordCloud()
.add("", data, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="美国各州确诊Top10"))
.render("/home/hadoop/result/result4/result1.html")
)
#5.画出美国死亡最多的10个州——>象柱状图
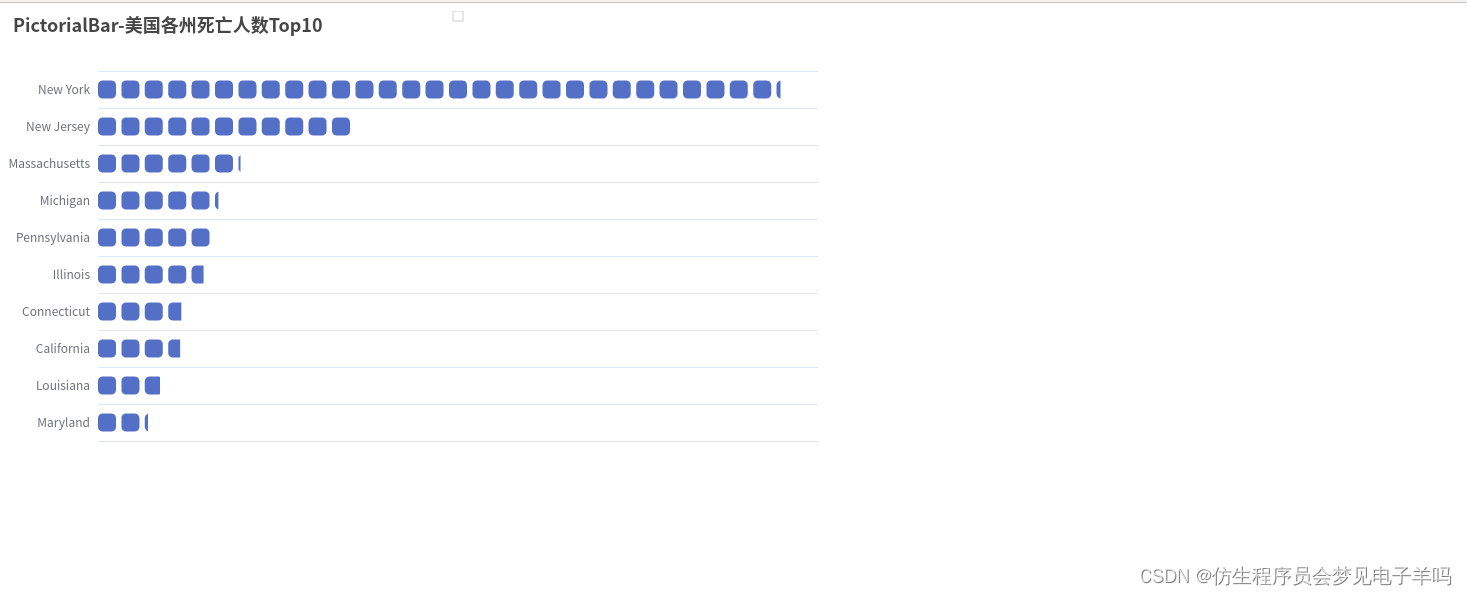
def drawChart_5(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
state = []
totalDeath = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
state.insert(0,str(js['state']))
totalDeath.insert(0,int(js['totalDeaths']))
c = (
PictorialBar()
.add_xaxis(state)
.add_yaxis(
"",
totalDeath,
label_opts=opts.LabelOpts(is_show=False),
symbol_size=18,
symbol_repeat="fixed",
symbol_offset=[0, 0],
is_symbol_clip=True,
symbol=SymbolType.ROUND_RECT,
)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts(title="PictorialBar-美国各州死亡人数Top10"),
xaxis_opts=opts.AxisOpts(is_show=False),
yaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(opacity=0)
),
),
)
.render("/home/hadoop/result/result5/result1.html")
)
#6.找出美国确诊最少的10个州——>词云图
def drawChart_6(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
data = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
row=(str(js['state']),int(js['totalCases']))
data.append(row)
c = (
WordCloud()
.add("", data, word_size_range=[100, 20], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="美国各州确诊最少的10个州"))
.render("/home/hadoop/result/result6/result1.html")
)
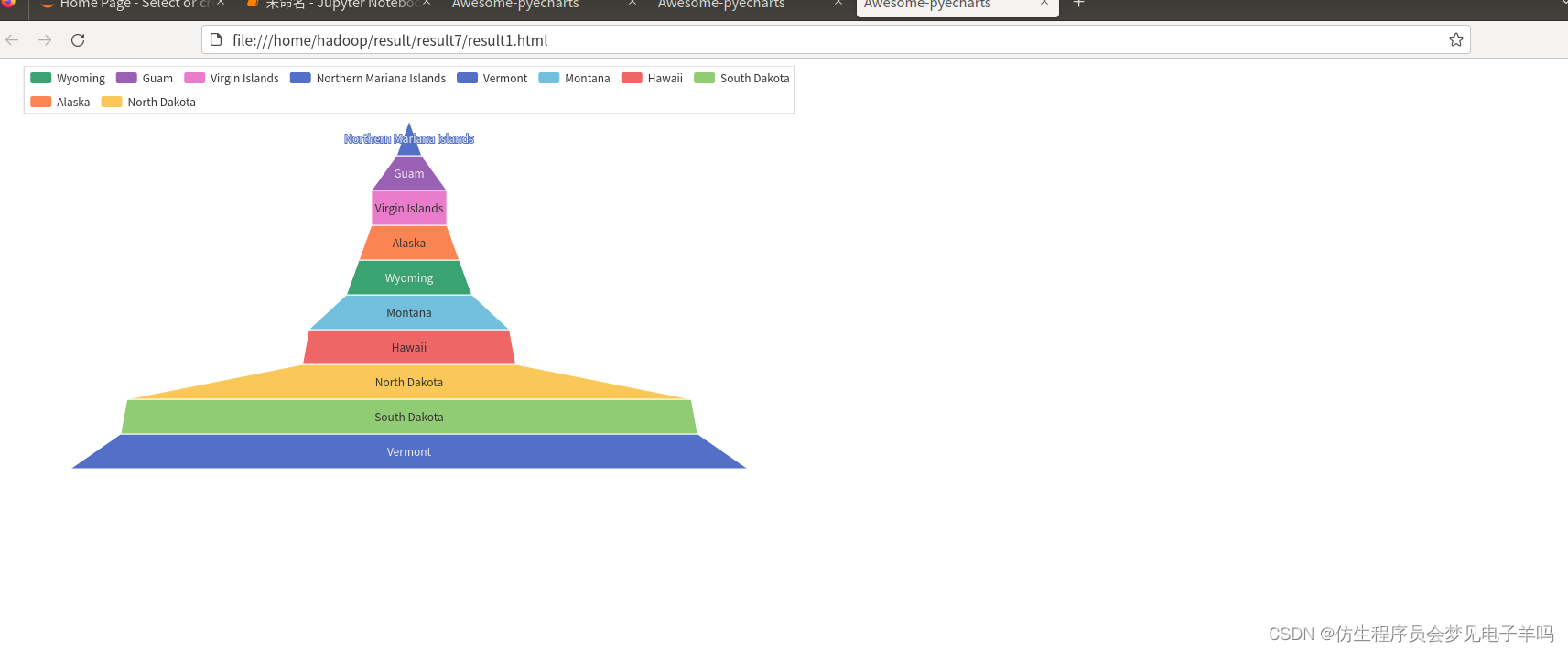
#7.找出美国死亡最少的10个州——>漏斗图
def drawChart_7(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
data = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
data.insert(0,[str(js['state']),int(js['totalDeaths'])])
c = (
Funnel()
.add(
"State",
data,
sort_="ascending",
label_opts=opts.LabelOpts(position="inside"),
)
.set_global_opts(title_opts=opts.TitleOpts(title=""))
.render("/home/hadoop/result/result7/result1.html")
)
#8.美国的病死率--->饼状图
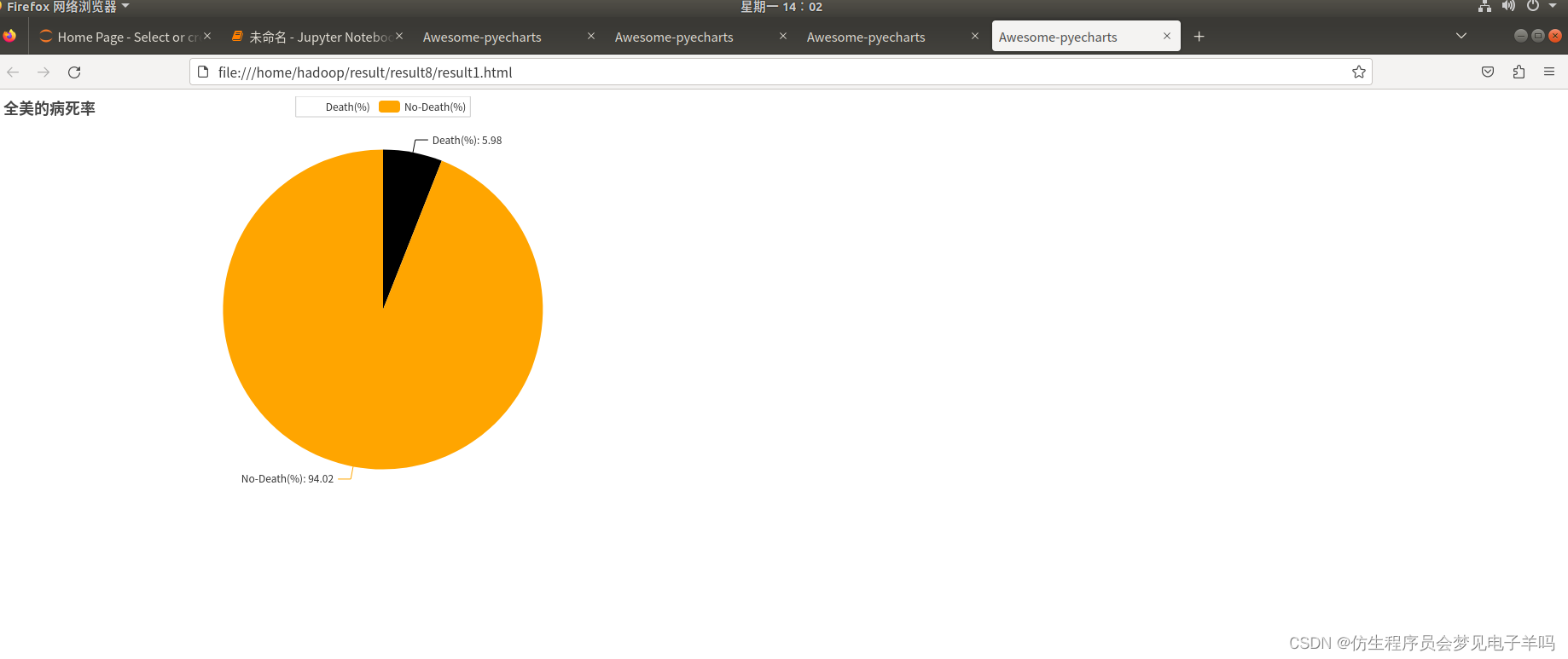
def drawChart_8(index):
root = "/home/hadoop/result/result" + str(index) +"/part-00000.json"
values = []
with open(root, 'r') as f:
while True:
line = f.readline()
if not line: # 到 EOF,返回空字符串,则终止循环
break
js = json.loads(line)
if str(js['state'])=="USA":
values.append(["Death(%)",round(float(js['deathRate'])*100,2)])
values.append(["No-Death(%)",100-round(float(js['deathRate'])*100,2)])
c = (
Pie()
.add("", values)
.set_colors(["blcak","orange"])
.set_global_opts(title_opts=opts.TitleOpts(title="全美的病死率"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
.render("/home/hadoop/result/result8/result1.html")
)
#可视化主程序:
index = 1
while index<9:
funcStr = "drawChart_" + str(index)
eval(funcStr)(index)
index+=1
结果展示
(1)美国每日的累计确诊病例数和死亡数——>双柱状图
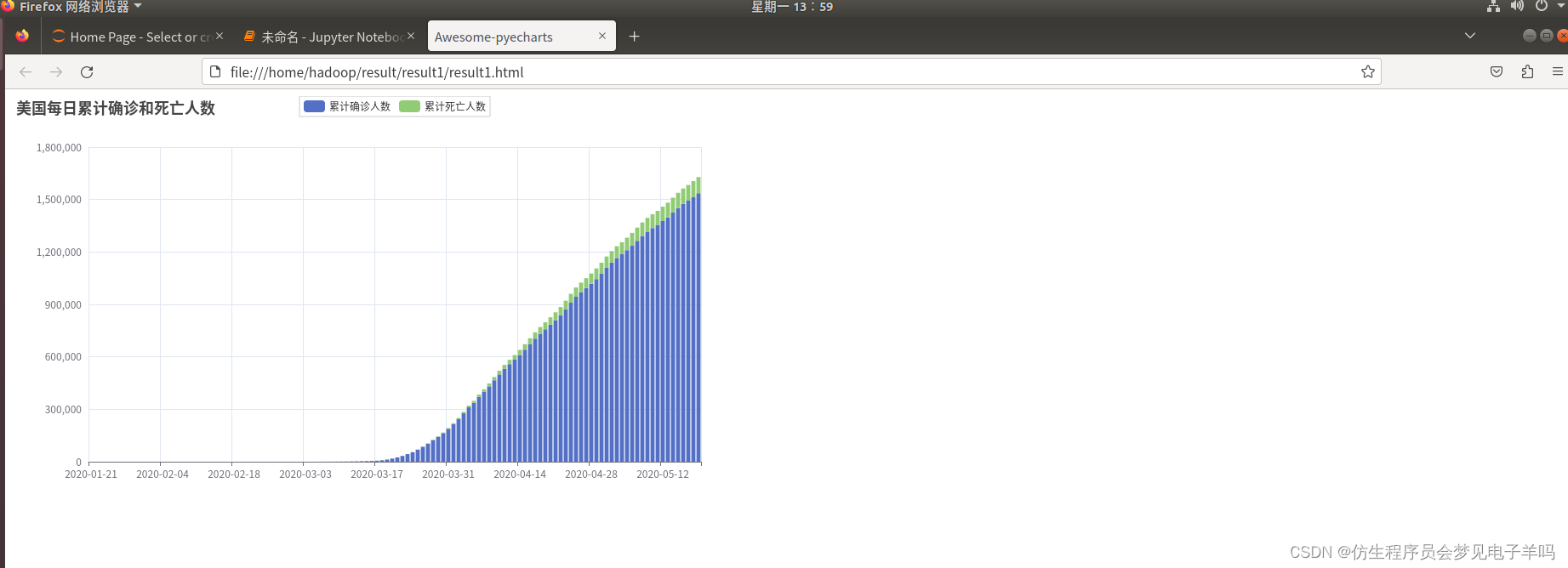
(2)美国每日的新增确诊病例数——>折线图
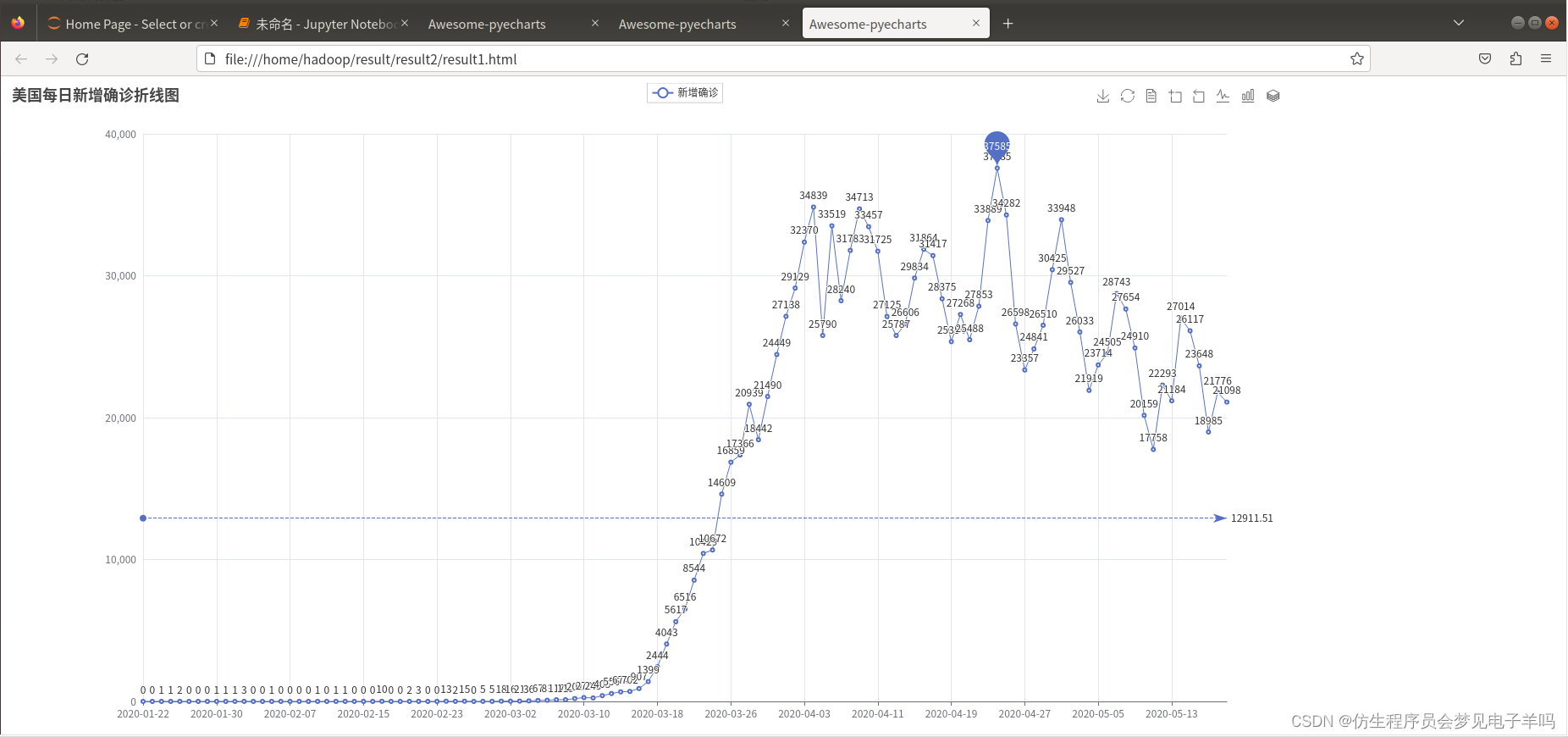
(3)美国每日的新增死亡病例数——>折线图
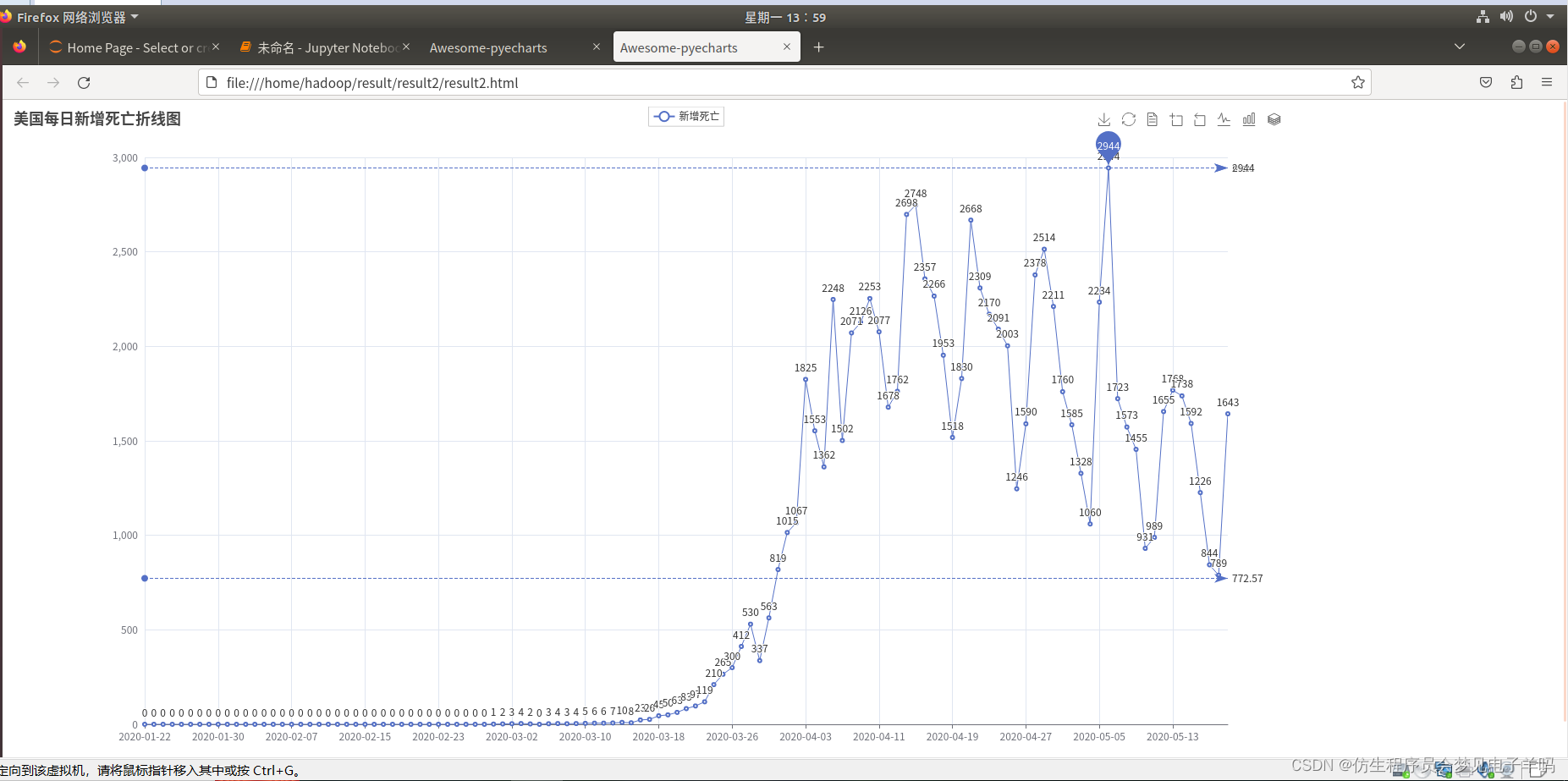
(4)截止5.19,美国各州累计确诊、死亡人数和病死率—>表格
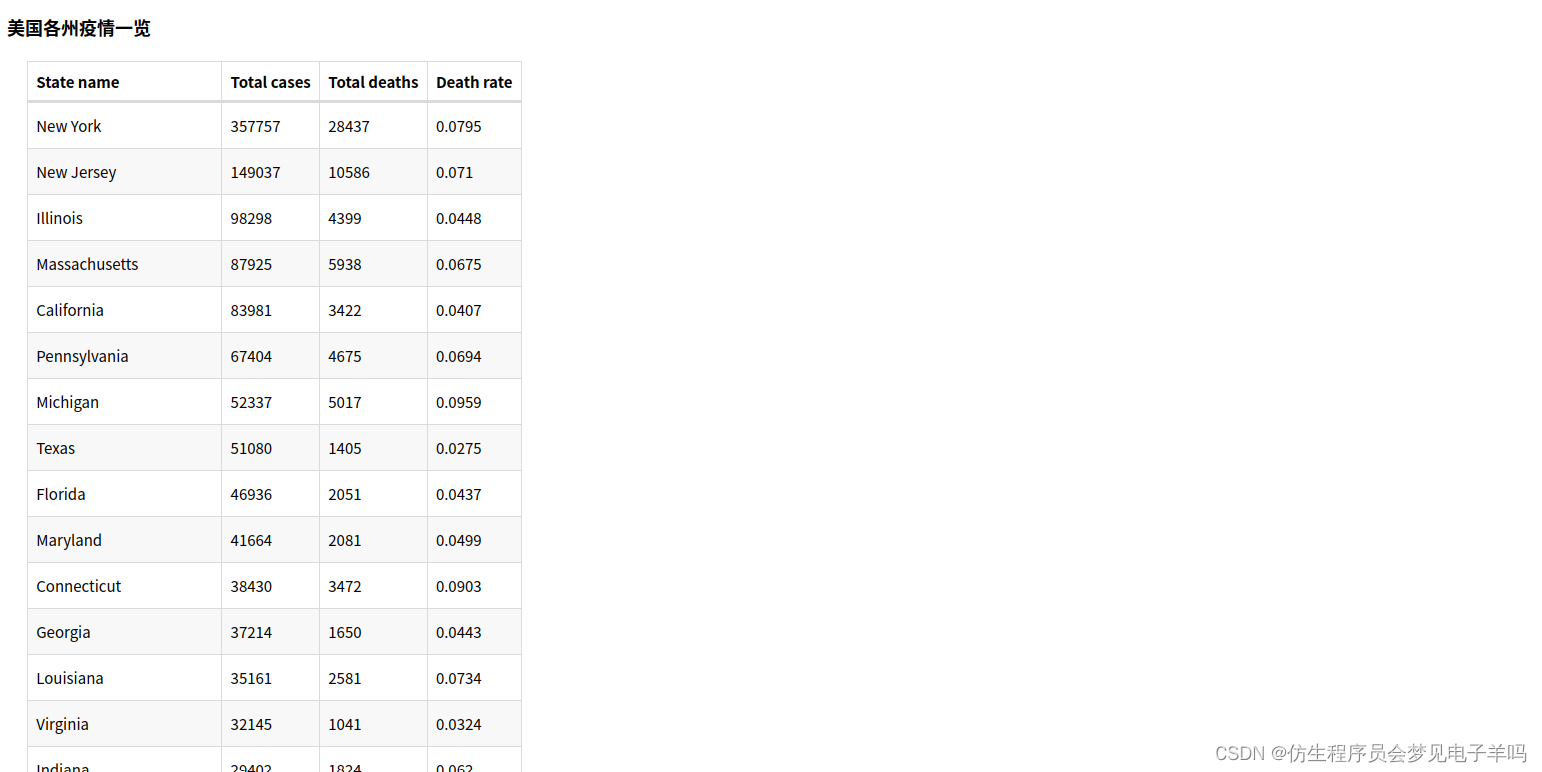
(5)截止5.19,美国累计确诊人数前10的州—>词云图
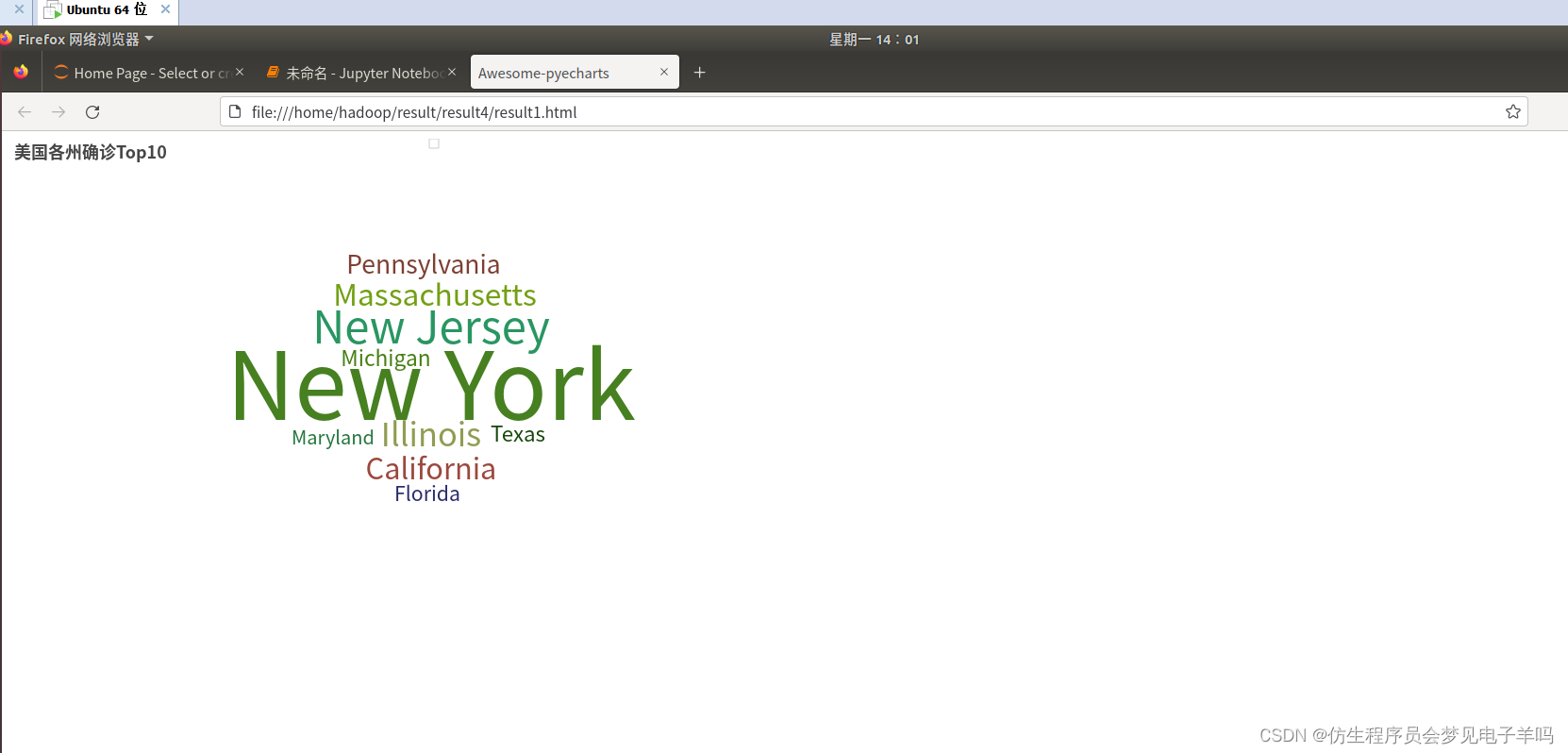
(6)截止5.19,美国累计死亡人数前10的州—>象柱状图
(7)截止5.19,美国累计确诊人数最少的10个州—>词云图

(8)截止5.19,美国累计死亡人数最少的10个州—>漏斗图
(9)截止5.19,美国的病死率—>饼状图
问题
1 无法上传到hdfs中
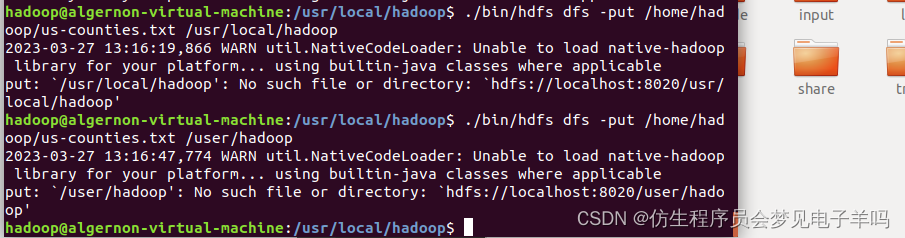
解决方法:需要先开启hadoop
2 路径出现错误
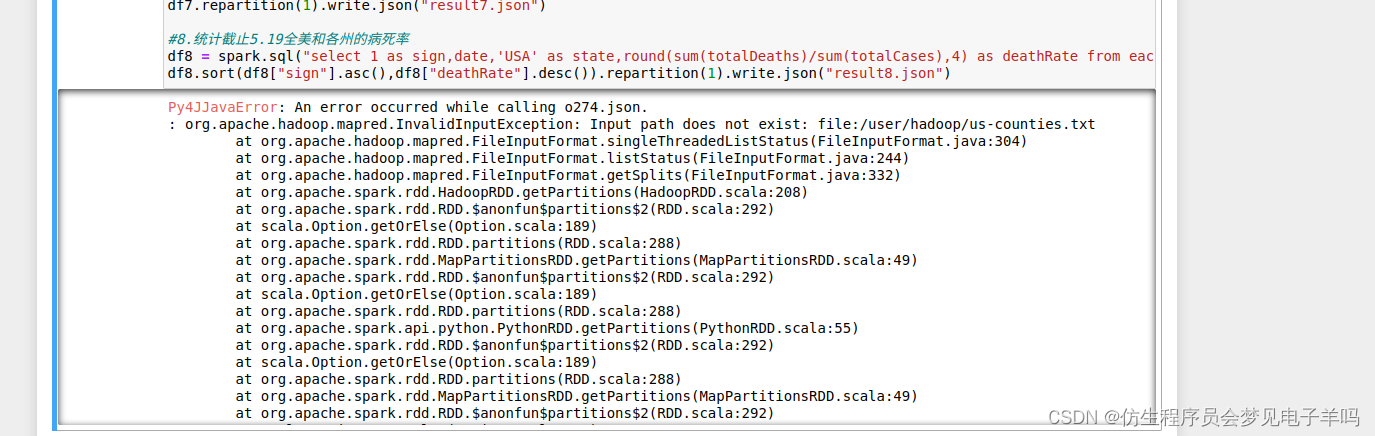
Caused by: java.io.IOException: Input path does not exist: file:/user/hadoop/us-counties.txt
at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:278)
... 101 more
解决方法:修改路径
3 pip下载pyecharts网络出错
解决方法:换源,且换成手机热点下载