Python新冠肺炎疫情数据获取与分析
不知道大家是否跟我一样,刚开始以为这次的新冠病毒并没那么严重,但随着疫情的不断蔓延,才意识到这次的疫情已经严重影响了每个人的生活和工作;其现状和发展趋势成了大家时刻关注的焦点;与此同时,真假消息混为一谈,各持所辞。
本篇文章将以Python为工具,从腾讯新闻网处获取疫情最新数据,并围绕以下几个问题展开分析,最终将结果可视化,力争让数据说话。
- 国内各省的疫情确诊案例分布情况?
- 各国疫情确诊案例分布情况?
- 湖北省疫情确诊案例分布情况?
- 疫情发展趋势?
关键词:抓取数据;数据处理,数据分析可视化;
核心方法:requests; Json; Pandas; Matplotlib; Pyecharts;
具体过程如下:
第一步:提取疫情数据接口
进入腾讯新闻网https://new.qq.com/,选择“抗肺炎”标题,该页面右上角位置有新型冠状病毒肺炎疫情实时追踪信息,点击该模块,即可到达疫情信息页面(https://news.qq.com//zt2020/page/feiyan.htm)
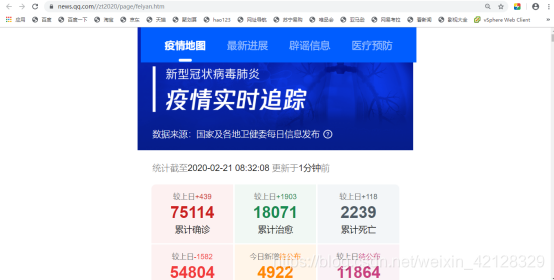
打开Chrome浏览器(其它浏览器也可),右击并选择“检查”项,即可打开浏览器的开发者工具,点击”Network”选项,并刷新页面,可以看到,在Network页面下方出现诸多条目,其中,一个条目就代表一次发送请求和接收响应的过程,如下图所示:
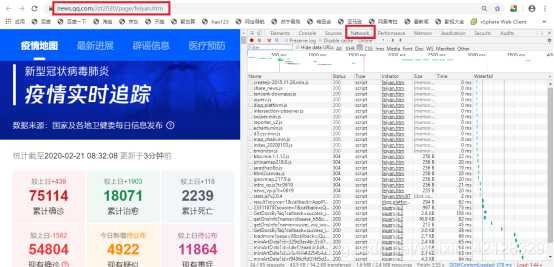
点击条目,在右侧的Response中核查疫情数据,最终发现,对应条目如下:
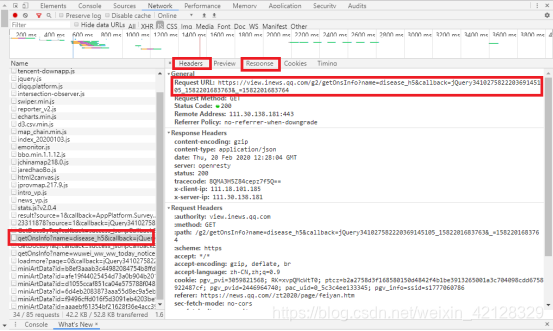
在右侧的Headers(头信息)中可观察请求和响应信息,可观察到,请求的URL为:https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery341027582220369145105_1582201683763&=1582201683764。打开该网址,如下界面:
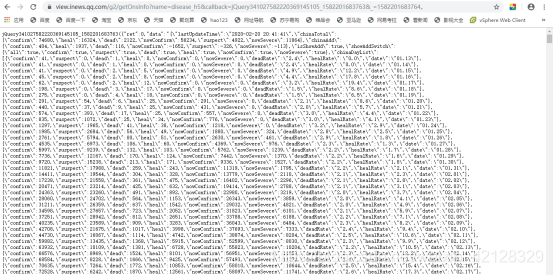
由于后期只需()中的相关数据,网址中的callback=jQuery341027582220369145105_1582201683763&=1582201683764部分可去掉,即最终得到的数据接口的URL为:https://view.inews.qq.com/g2/getOnsInfo?
name=disease_h5。
第二步:获取源代码、提取目标数据、保存
已知数据接口,利用requests第三方库可获取相应数据;具体代码如下:
import requests
import json
area = requests.get('https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5').text
#print(type(area))
#此处获取的area是Json字符串,使用loads()方法将其转化为Python对象
data_dict = json.loads(area)
#print(type(data_dict))
print(data_dict)代码的部分结果如下所示:
{'ret': 0, 'data': '{"lastUpdateTime":"2020-02-21 08:45:51","chinaTotal":{"confirm":75114,"heal":18104,"dead":2239,"nowConfirm":54771,"suspect":4922,"nowSevere":11864},"chinaAdd":{"confirm":439,"heal":1936,"dead":118,"nowConfirm":-1615,"suspect":0,"nowSevere":0},"isShowAdd":true,"showAddSwitch":{"all":true,"confirm":true,"suspect":false,"dead":true,"heal":true,"nowConfirm":true,"nowSevere":false},"chinaDayList":[{"confirm":41,"suspect":0,"dead":1,"heal":0,"nowConfirm":0,"nowSevere":0,"deadRate":"2.4","healRate":"0.0","date":"01.13"},{"confirm":41,"suspect":0,"dead":1,"heal":0,"nowConfirm":0,"nowSevere":0,"deadRate":"2.4","healRate":"0.0","date":"01.14"},{"confirm":41,"suspect":0,"dead":2,"heal":5,从上述结果可观察到,疫情数据存储在字典和列表中,而疫情数据主要包含在字典data_dict的data元素中,结果查看如下:
#查看疫情主要数据
data_values = json.loads(data_dict['data'])
#查看主要数据的所有键
print([i for i in data_values.keys()])代码的执行结果如下所示:
['lastUpdateTime', 'chinaTotal', 'chinaAdd', 'isShowAdd', 'showAddSwitch', 'chinaDayList', 'chinaDayAddList', 'dailyHistory', 'wuhanDayList', 'dailyNewAddHistory', 'dailyDeadRateHistory', 'dailyHealRateHistory', 'areaTree', 'articleList']后期分析主要用到’lastUpdateTime’(上次更新时间);‘chinaDayList’(国内每天的疫情数据列表);‘areaTree’(区域树);
(1) 根据日期提取疫情数据
此处以天为单位提取疫情数据时,用到数据’chinaDayList’(国内每天的疫情数据列表);提取该数据的代码如下所示:
data_context = data_values['chinaDayList']
print(data_context)代码执行的部分结果如下:
[{'confirm': 41, 'suspect': 0, 'dead': 1, 'heal': 0, 'nowConfirm': 0, 'nowSevere': 0, 'deadRate': '2.4', 'healRate': '0.0', 'date': '01.13'}, {'confirm': 41, 'suspect': 0, 'dead': 1, 'heal': 0, 'nowConfirm': 0, 'nowSevere': 0, 'deadRate': '2.4', 'healRate': '0.0', 'date': '01.14'}获取最后更新的时间代码如下:
lastUpdateTime = data_values['lastUpdateTime'].split()[0]执行结果如下:
2020-02-21提取上述数据和保存的代码如下:
#创建列表,每个元素表示每天的疫情数据
all_list = []
for date_data in data_context:
#每天的疫情数据以字典为单位存储
every_day_data = {}
every_day_data['date'] = date_data['date']
every_day_data['confirm'] = date_data['confirm']
every_day_data['suspect'] = date_data['suspect']
every_day_data['dead'] = date_data['dead']
every_day_data['heal'] = date_data['heal']
every_day_data['lastUpdateTime'] = lastUpdateTime
all_list.append(every_day_data)
df = pd.DataFrame(all_list)
#以csv文件保存
df.to_csv('data_date.csv', index=False)根据日期提取疫情数据展示如下:
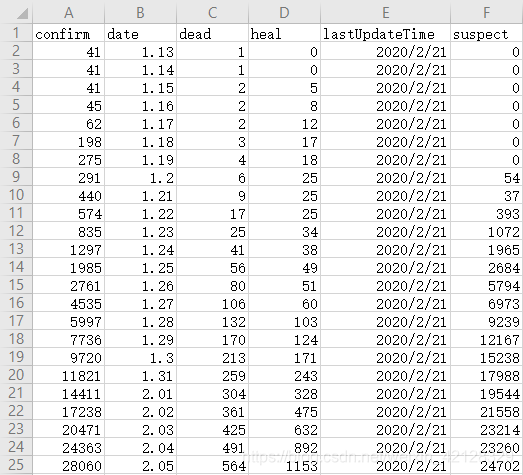
(2) 以省份为单位提取目标数据
此处以省份为单位提取疫情数据时,用到数据’areaTree’(区域树);提取该数据的代码如下所示:
data_context = data_values['areaTree']提取数据和保存的代码如下:
all_list = []
for country_data in data_context:
if country_data['name'] != '中国':
continue
else:
all_provinces = country_data['children']
#province_data表示一个省的所有信息
for province_data in all_provinces:
each_province_data = {}
each_province_data['province_name'] = province_data['name']
each_province_data['tod_confirm'] = province_data['today']['confirm']
each_province_data['tod_isUpdated'] = province_data['today']['isUpdated']
each_province_data['confirm'] = province_data['total']['confirm']
each_province_data['suspect'] = province_data['total']['suspect']
each_province_data['dead'] = province_data['total']['dead']
each_province_data['deadRate'] = province_data['total']['deadRate']
each_province_data['showRate'] = province_data['total']['showRate']
each_province_data['heal'] = province_data['total']['heal']
each_province_data['healRate'] = province_data['total']['healRate']
each_province_data['showHeal'] = province_data['total']['showHeal']
all_list.append(each_province_data)
df = pd.DataFrame(all_list)
df.to_csv('data_province.csv', index=False, encoding="utf_8_sig")以省份为单位提取的目标数据结果如下:
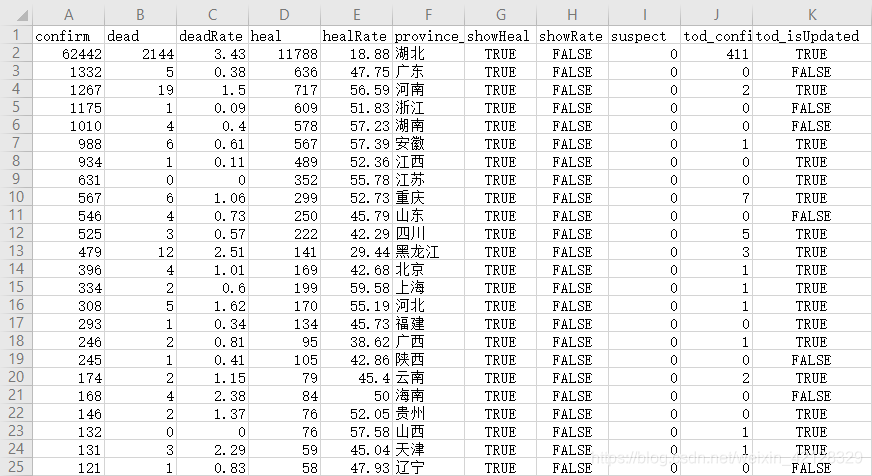
(3) 以国家为单位提取目标数据
此处以国家为单位提取疫情数据时,也用到数据’areaTree’(区域树);提取该数据的代码如下所示:
data_context = data_values['areaTree']
print(data_context)
all_list = []
for country in data_context:
each_country_data = {}
each_country_data['name'] = country['name']
each_country_data['tod_confirm'] =country['today']['confirm']
each_country_data['tod_isUpdated'] = country['today']['isUpdated']
each_country_data['tot_confirm'] = country['total']['confirm']
each_country_data['tot_suspect'] = country['total']['suspect']
each_country_data['tot_dead'] = country['total']['dead']
each_country_data['tot_deadRate'] = country['total']['deadRate']
each_country_data['tot_showRate'] = country['total']['showRate']
each_country_data['tot_heal'] = country['total']['heal']
each_country_data['tot_healRate'] = country['total']['healRate']
each_country_data['tot_showHeal'] = country['total']['showHeal']
all_list.append(each_country_data)
df = pd.DataFrame(all_list)
df.to_csv('data_countries.csv', index=False,encoding="utf_8_sig")以国家为单位提取的目标数据结果如下:
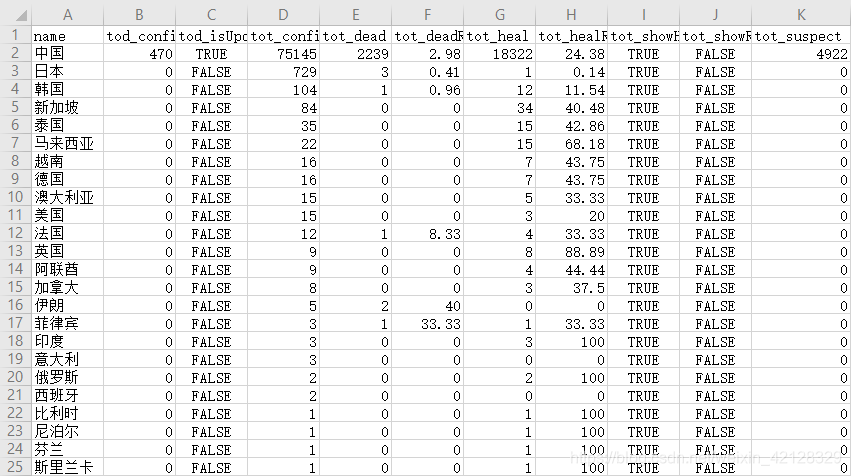
(4) 在省份的基础上提取市区的疫情确诊案例分布情况
提取的代码和上述提取代码方法一致,此处不做展示,现以湖北省为例,获取的部分数据展示如下:
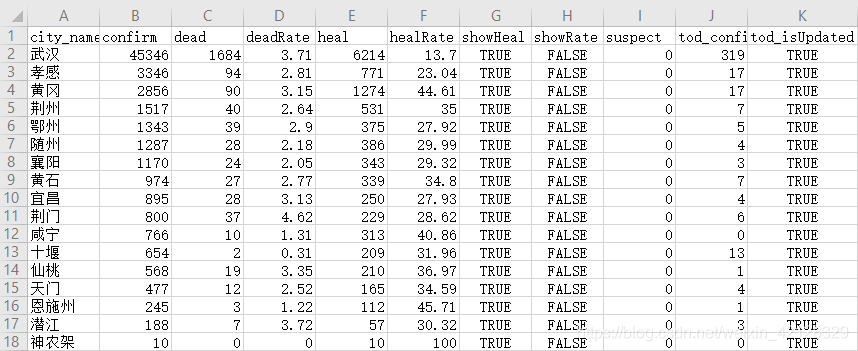
第三步: 数据分析可视化
基于以上获取的数据,现开始可视化分析
1. 国内各省的疫情确诊案例分布情况
以省份为单位的可视化代码如下所示:
co_data = pd.read_csv(r".\data_province.csv")
map = Map().add("人数", [list(z) for z in zip(co_data['province_name'], co_data['confirm'])], "china").set_global_opts(title_opts=opts.TitleOpts(title="国内确诊案例分布详情"),visualmap_opts=opts.VisualMapOpts(
## 传入指定分段的范围,且每个分段显示的标签及填充的颜色
pieces=[
{"value":0,"label":"0","color":"#FFFFFF"},
{"min":1,"max":9,"label":"1-9人","color":"#fcebcf"},
{"min":10,"max":99,"label":"10-99人","color":"#f59e83"},
{"min":100,"max":499,"label":"100-499人","color":"#e45a4f"},
{"min":500,"max":999,"label":"500-999人","color":"#cb2b2f"},
{"min":1000,"max":9999,"label":"1000-9999人","color":"#811c24"},
{"min":10000,"label":"10000人以上","color":"#4f060d"}
],
## 设置分段显示
is_piecewise=True),
## 设置提示框内容
tooltip_opts=opts.TooltipOpts(
formatter='省份:{b} 累计确诊:{c}',
)
)
map.render('map_province.html')可视化结果如下:
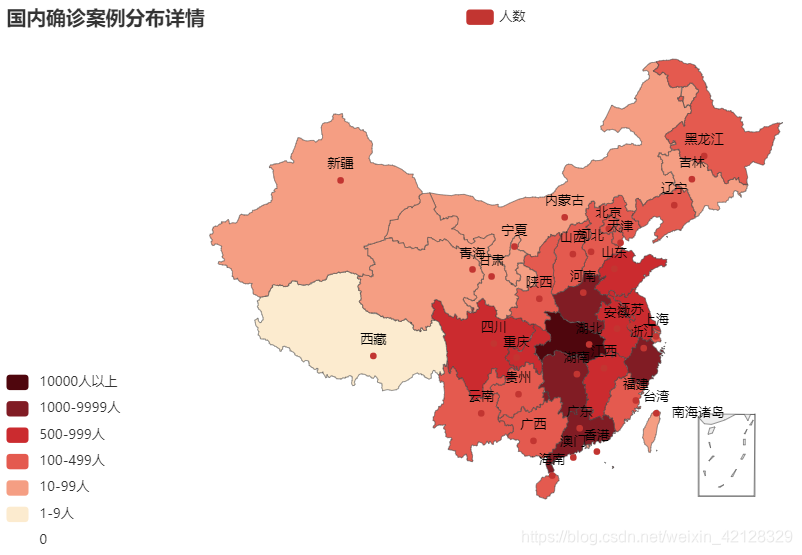
2. 各国疫情确诊案例分布情况
以国家为单位的可视化代码如下所示:
co_data = pd.read_csv(r".\data_countries.csv")
#print(co_data)
#去除中国所在行数据
co_data = co_data.drop(0)
co_data = co_data.head(10)
print(co_data)
x_data = co_data.name
y_data1 = co_data.tot_confirm
print(x_data)
print(y_data1)
plt.pie(y_data1,labels=x_data,startangle=90, shadow=True,autopct='%1.1f%%')
plt.title("各国疫情确诊人数前8(除中国)")
# 为两条坐标轴设置名称
plt.show()
可视化结果如下:
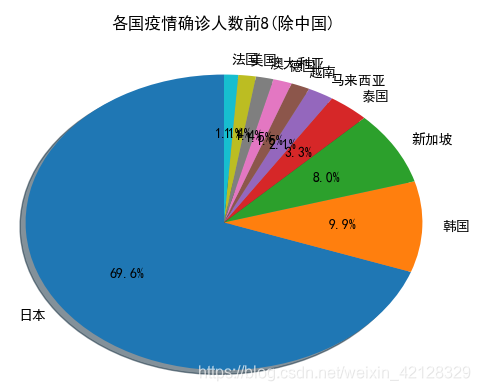
3. 湖北省疫情确诊案例分布情况
由于湖北省疫情确诊人数较多,现对湖北省的情况进行可视化分析
data = pd.read_csv("data_hubei.csv")
print(data)
pie= Pie().add("湖北省确诊案例分布详情",[list(z) for z in zip(data.province_name, data.confirm)],radius=[30,65],label_opts = opts.LabelOpts(formatter='{b} {c} ({d}%))')).set_global_opts(title_opts=opts.TitleOpts(title="湖北省确诊案例分布详情"),legend_opts=opts.LegendOpts(pos_top='bottom'))
pie.render('hubei'+'.html')可视化结果如下:
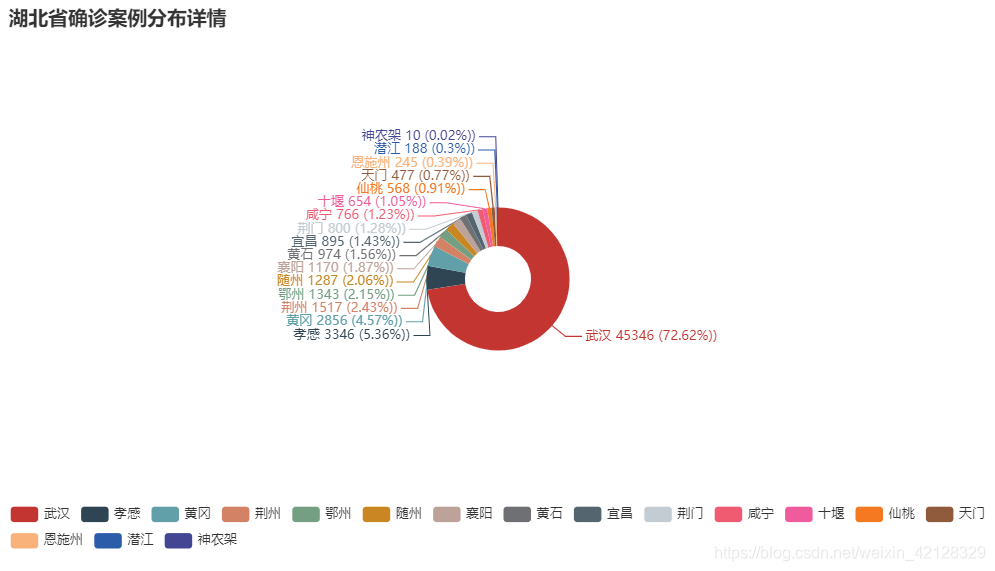
4. 疫情发展趋势
以天数为单位对当前疫情发展趋势分析的代码如下:
date_data = pd.read_csv("data_date.csv",dtype={'date':'str'})
date_list = []
odd_day = list(date_data.date)
for i in range(0,len(odd_day)):
#注意:一定要先strip,否则切完后的保留一个空格,转换失败
month, day = odd_day[i].strip().split('.')[0],odd_day[i].strip().split('.')[1]
print(month,day)
date_list.append(datetime.strptime('2020-%s-%s' % (month, day), '%Y-%m-%d'))
date_data['date'] = date_list
print(date_data)
#开始绘制图形
x = date_data['date']
y1 = date_data['confirm']
y2 = date_data['suspect']
y3 = date_data['dead']
y4 = date_data['heal']
print(y1)
plt.plot(x,y1,label = u'确诊人数',color='b', linewidth=2)
plt.plot(x,y2,label = u'疑似人数',color='r', linewidth=2)
plt.plot(x,y3,label = u'死亡人数',color='m',linewidth=2)
plt.plot(x,y4,label = u'治愈人数',color='g', linewidth=2)
plt.xlabel('日期(最后更新时间:'+date_data.lastUpdateTime[0]+")")
plt.ylabel('人数')
plt.gcf().autofmt_xdate()
plt.title('疫情发展趋势图')
plt.grid()
plt.legend()
plt.show()可视化结果如下:
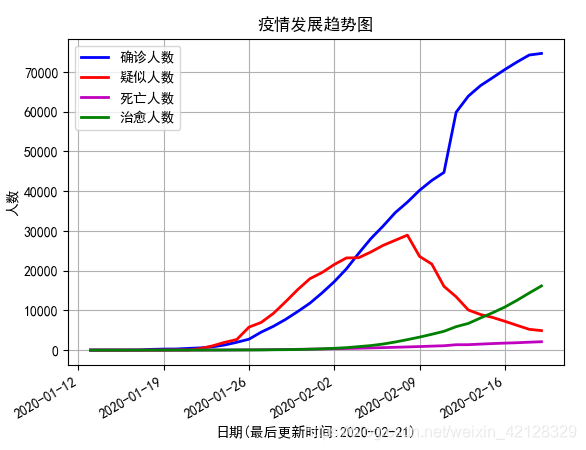
补充:对其它省份的疫情信息进行分析
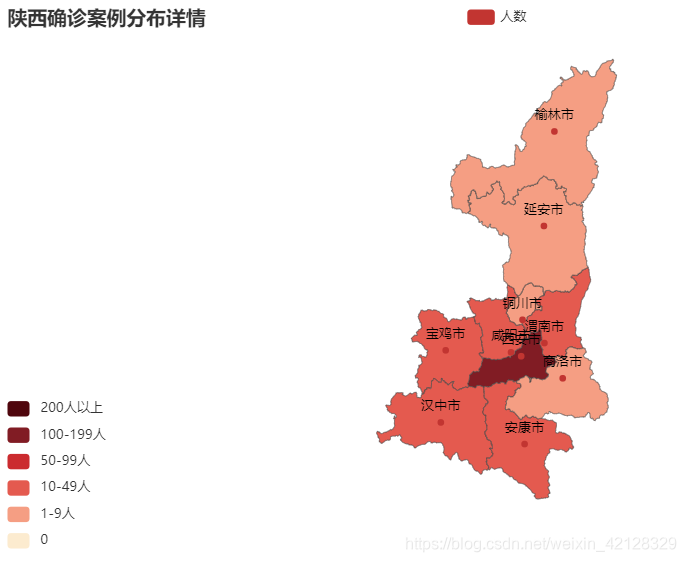
以陕西省为例,分析的代码如下:
data = pd.read_csv("data_shaanxi.csv")
data = data.head(10)
print(data.province_name)
data['province_name'] =[ i+'市' for i in data['province_name']]
print(data.province_name)
map = Map().add("人数", [list(z) for z in zip(data['province_name'], data['confirm'])], "陕西").set_global_opts(title_opts=opts.TitleOpts(title="陕西确诊案例分布详情"),visualmap_opts=opts.VisualMapOpts(
## 传入指定分段的范围,且每个分段显示的标签及填充的颜色
pieces=[
{"value":0,"label":"0","color":"#fcebcf"},
{"min":1,"max":9,"label":"1-9人","color":"#f59e83"},
{"min":10,"max":49,"label":"10-49人","color":"#e45a4f"},
{"min":50,"max":99,"label":"50-99人","color":"#cb2b2f"},
{"min":100,"max":199,"label":"100-199人","color":"#811c24"},
{"min":200,"label":"200人以上","color":"#4f060d"}
],
## 设置分段显示
is_piecewise=True),
## 设置提示框内容
tooltip_opts=opts.TooltipOpts(
formatter='市区:{b} 累计确诊:{c}',
)
)
map.render('map_shaanxi.html')可视化结果如下:
以上即为本次疫情数据的获取及可视化过程,如有不足之处,还请批评指点;同时,在疫情的转折点期间切勿放松警惕,防控疫情,人人有责。
,
