新冠病毒疫情的数据爬取和简单分析
近期有闲暇时间,有幸可以爬取一波新冠疫情的数据,并对全球的疫情形势做简单的分析。
在此过程中对全球的疫情严重程度和抗疫情况有了个更深入的了解。
一、数据来源和网站分析
网上新冠疫情数据平台其实就那几个,这里选择“丁香医生”,链接:丁香医生疫情数据网址
这个网站几乎没有反爬的机制,就正常分析就可以很快拿到想要的数据了。这个网站数据的获取过程不一,你可以根据自己的情况来选择。说一说两种爬取途径吧:
1、审查元素,抓包获取数据
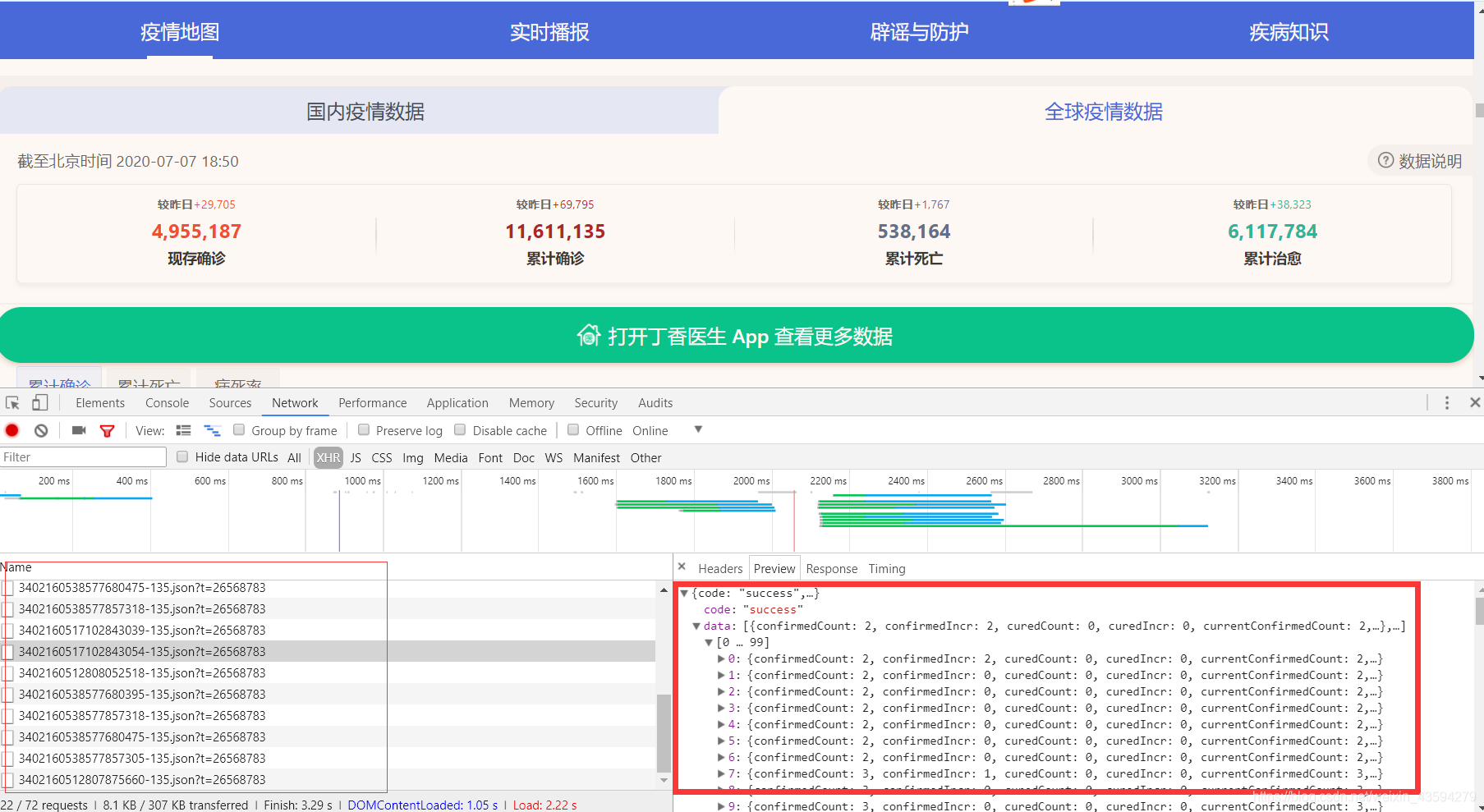
按F12,刷新可看到一堆json数据包,这些数据就是被渲染到网页上的疫情数据了,然而我分析的时候因为时间关系没有用这种方法,因为json包中并没有指明这些数据是哪个国家的。
2、分析网页源代码
其实这应该放到第一步,一般分析网站的第一个步骤就是看网页源码,如果想要的数据在其中就不需要大费周章地抓包了。右键点击网页源代码。
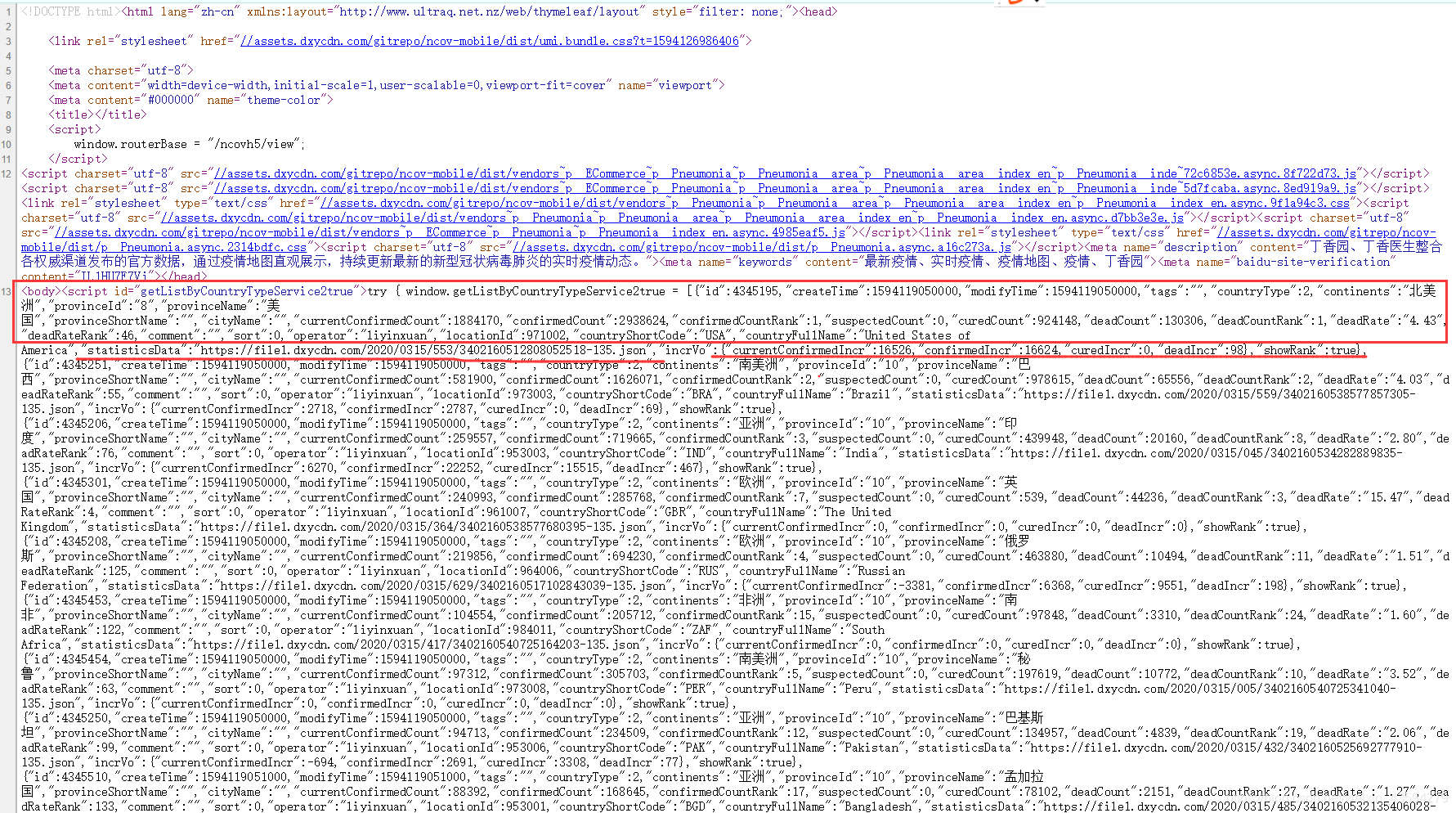
可以看到,每个国家的数据都一目了然,应有尽有。图上方框中的数据是这个国家当天的一些疫情统计情况,值得注意的是划线的"statisticsData",它后面竟然跟随着一个json的链接,大胆地猜测这个链接是这个国家的历史数据。
至此我们的分析就结束了,接下来就是写代码的事情了。
二、代码的编写
其中的被注释的代码可以选择性的去除,当然去留都根据自己的情况决定。
import requests
import json
import os
#requests的请求头
headers = {
'User-Agent':#自行填写
}
'''静态网页里有主要国家的json,而其中仅为当天数据,不过其中的statisticsData里
有对应国家的历史疫情数据,数据量有215个国家之多'''
"""这里的start_data.txt特别说明一下,这里偷了个懒,这个txt文件中的数据其实就是网页源代码含各个国家疫情数据的字典的源码,因为我经过试验发现直接从网站提取实在费力,re和xpath都有匹配不到的现象。不想花时间写匹配模式我索性直接复制。"""
#导入本地网页的json数据
with open('start_data.txt','r',encoding='utf-8')as f:
json_data = json.loads(f.read())
continents=[] #国家所在大洲
provinceName=[] #国家名称
statisticsData=[] #数据链接
for item in json_data:
continents.append(item['continents'])
provinceName.append(item['provinceName'])
statisticsData.append(item['statisticsData'])
#备份链接数据
##index_data = [['大洲','国家','数据网址']]
##
##for i,j,k in zip(continents,provinceName,statisticsData):
## index_data.append([i,j,k])
##
##print('数据链接生成完毕')
##
##with open('index_data.csv','w',encoding='utf-8')as fn:
## for index in index_data:
## fn.write(','.join(index)+'\n')
##
##print('数据链接保存完毕')
#按大洲分别建立对应文件夹
##continents_name = set(continents)
##print(continents_name)
##
##for name in continents_name:
## print(name,'文件夹建立成功')
## os.makedirs(name,exist_ok=True)
#遍历每一个链接
for path_name,file_name,url in zip(continents,provinceName,statisticsData):
res = requests.get(url,headers=headers)
## json数据备份,这个步骤其实可以不用,保存一个样例用于后面数据的结构分析就好了
## with open('{}/{}.json'.format(path_name,file_name),'w',encoding='utf-8')as fa:
## fa.write(str(res.content))
## print(path_name,file_name,'json下载成功')
res.encoding='utf-8'
every_country_data = json.loads(res.content)
dateId=[] #对应one_data的每一项
confirmedCount=[]
confirmedIncr=[]
curedCount=[]
curedIncr=[]
deadCount=[]
deadIncr=[]
one_data=[['日期','确诊病例','新增确诊','累计治愈','新增治愈','死亡病例','新增死亡']]
every_country_data=every_country_data['data']
#这里的操作是为了方便形成csv文件
for every in every_country_data:
dateId.append(str(every['dateId']))
confirmedCount.append(str(every['confirmedCount']))
confirmedIncr.append(str(every['confirmedIncr']))
curedCount.append(str(every['curedCount']))
curedIncr.append(str(every['curedIncr']))
deadCount.append(str(every['deadCount']))
deadIncr.append(str(every['deadIncr']))
#在对应文件夹生成相应的csv文件
for a,b,c,d,e,f,g in zip(dateId,confirmedCount,confirmedIncr,curedCount,curedIncr,deadCount,deadIncr):
one_data.append([a,b,c,d,e,f,g])
with open('{}/{}.csv'.format(path_name,file_name),'w',encoding='utf-8')as fb:
for one in one_data:
fb.write(','.join(one)+'\n')
print(path_name,file_name,'csv数据下载成功')
三、通过K-means聚类实现疫情国家分类
数据我们已经下载完成了,就要对这些数据进行运用,得出一些规律和有用信息。
基于这些历史疫情数据是时间序列型的数据,通过特征值作为聚类的处理数据可能难度太高而且效果不佳、时间成本也高。
既然是时间序列,那就很自然想到拟合曲线方程,我将方程的系数作为关键因子,也可以说是伪特征值,然后将这些特征值丢到K-means聚类器中就行了。
统一选择2月27日到7月1日的数据,让数据的基准一致。
1、代码实现
import csv
import numpy as np
import os
#from pprint import pprint
path = "../选中国家/" #这里填充需要分类的国家所在的文件夹
files = os.listdir(path) #得到文件夹内文件的名称
title=[] #国家名
feature_X = [] #存拟合函数的斜率
feature_Y = [] #存拟合函数的截距
#读取csv文件数据
for file_name in files:
title.append(file_name.split('.')[0])
with open(path+file_name,'r',encoding='utf-8')as f:
data=list(csv.reader(f))
## confirmedIncr = [] #获取新增确诊数据对应列
## for i in range(1,len(data)):
## confirmedIncr.append(eval(data[i][2]))
## X = [i for i in range(len(confirmedIncr))]
## Y = np.array(confirmedIncr)
column=1 #第一列
confirmedCount = [] #获取确诊数据对应列
for i in range(1,len(data)):
confirmedCount.append(eval(data[i][column])) #1表示确诊病例,3为累计治愈,5为累计死亡
X = [i for i in range(len(confirmedCount))]
Y = np.array(confirmedCount)
f1=np.polyfit(X,Y,1) #一维多项式拟合即线性回归
f1=list(f1)
feature_X.append(f1[0])
feature_Y.append(f1[1])
feature=[]
for i,j,k in zip(title,feature_X,feature_Y):
feature.append([i,j,k])
pprint(feature)
'''聚类分析'''
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
k_temp = []
for i,j in zip(feature_X,feature_Y):
k_temp.append([i,j])
k_data = np.array(k_temp)
##print(k_data)
clf = KMeans(n_clusters = 4)#聚类簇为4
clf = clf.fit(k_data)
##print(clf.cluster_centers_) #聚类中心
##print(clf.labels_) #数据被标记的标签
#聚类簇为4
data_1_x=[]
data_2_x=[]
data_3_x=[]
data_4_x=[]
data_1_y=[]
data_2_y=[]
data_3_y=[]
data_4_y=[]
data_1_title=[]
data_2_title=[]
data_3_title=[]
data_4_title=[]
for i,j in enumerate(clf.labels_):
if j==0:
data_1_x.append(feature_X[i])
data_1_y.append(feature_Y[i])
data_1_title.append(title[i])
elif j==1:
data_2_x.append(feature_X[i])
data_2_y.append(feature_Y[i])
data_2_title.append(title[i])
elif j==2:
data_3_x.append(feature_X[i])
data_3_y.append(feature_Y[i])
data_3_title.append(title[i])
elif j==3:
data_4_x.append(feature_X[i])
data_4_y.append(feature_Y[i])
data_4_title.append(title[i])
##print(data_1_x,data_1_y)
##print(data_2_x,data_2_y)
##print(data_3_x,data_3_y)
print('第1类',data_1_title)
print('第2类',data_2_title)
print('第3类',data_3_title)
print('第4类',data_4_title)
plt.scatter(data_1_x,data_1_y,50,color='#0000FE',marker='+',linewidth=2,alpha=0.8) #结果图上的点为蓝色
plt.scatter(data_2_x,data_2_y,50,color='#000000',marker='+',linewidth=2,alpha=0.8) #结果图上的点为黑色
plt.scatter(data_3_x,data_3_y,50,color='#FE0000',marker='+',linewidth=2,alpha=0.8) #结果图上的点为红色
plt.scatter(data_4_x,data_4_y,50,color='#99CC01',marker='+',linewidth=2,alpha=0.8) #结果图上的点为绿色
plt.xlabel('X-parameter')
plt.ylabel('Y-distance')
plt.grid(color='#95a5a6')
plt.show()
2、最终的图像
按确诊病例分类图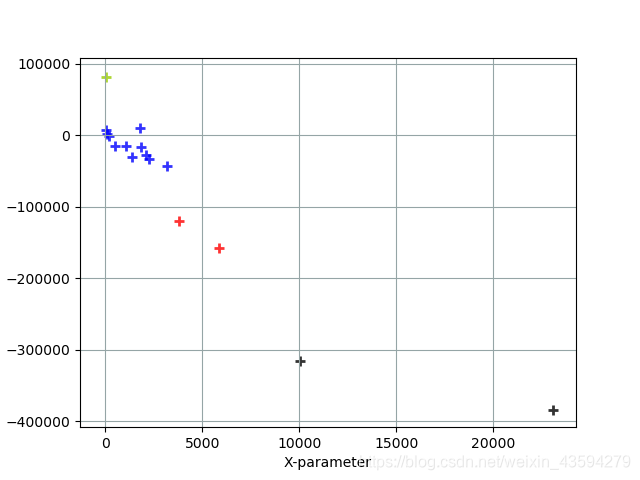
蓝色标记:伊朗, 加拿大, 埃及, 德国, 日本, 法国, 澳大利亚, 英国, 西班牙, 韩国, 意大利
黑色标记:巴西, 美国
红色标记:俄罗斯, 印度
绿色标记:中国
分析:横轴上数值越大证明疫情确诊病例增长趋势曲线越陡,新增病例越多;纵轴上的数据可以理解为已经确诊的人数,当然还是要配合实际情况而定,纵轴的数据所占权重较小。从图中就可以看出,美国和巴西的疫情还是很严重的,未来还会有更多的病例出现,而中国毋庸置疑是疫情防控做的最好的,近期几乎没有新的病例产生。俄罗斯和印度的情形也是相对严重的,还需要加把劲才能控制住疫情。
这里还附上这些国家的时间序列数据的共同绘制图:
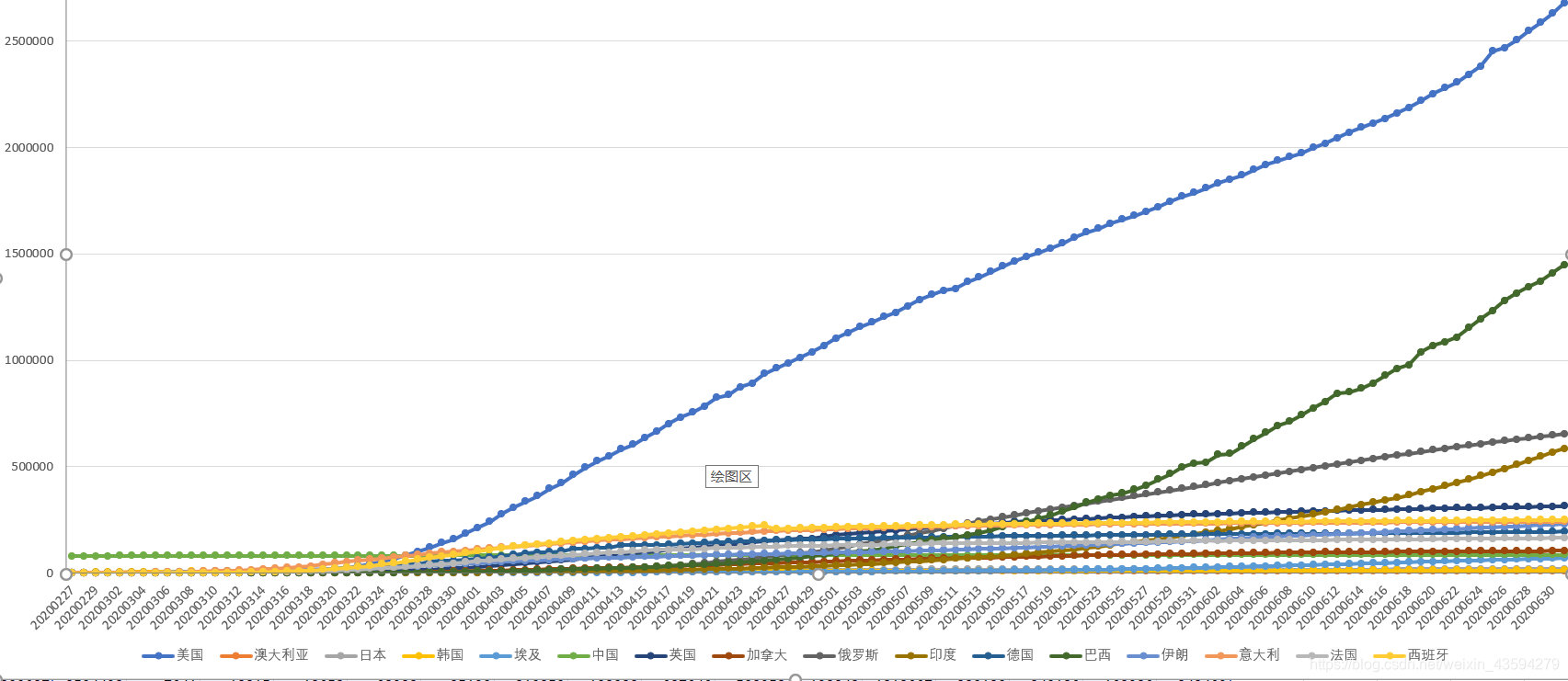
通过各个国家的走势和排序,再一次验证这个分类方法是有效的。
面对当今疫情形势,我们还不能停止脚步休息,还要时刻警惕疫情再次扩散,近期有权威机构通告新冠病毒可能会长期存在,这就宣告了人类和肺炎病毒间的长时间拉锯战,这是一场不得不打的仗。衷心希望世界各国团结一心,摈弃前嫌,共同对抗疫情。