pdf版本在我的资源里,免费下载!
Linux命令
常用Linux命令的基本使用
- ls:list,查看当前文件夹下的内容
- pwd:print work directory,查看当前所在文件夹
- cd[目录名]:change directory,切换文件夹
- touch[目录名]:touch,如果文件不存在,新建文件
- mkdir[目录名]:make directory,创建目录
- rm[文件名]:remove,删除指定的文件
- tree[目录名]:tree,以树状图列出文件目录结构
- cp 源文件 目标文件:copy,复制文件或者目录
- mv 源文件 目标文件:move,移动文件或者目录 / 文件或者目录重命名
- clear:清屏
路径
- 相对路径:在输入路径时,最前面不是 / 或者 ~ ,表示相对当前目录所在的目录位置
- 绝对路径:在输入路径时,最前面是 / 或者 ~ ,表示从根目录/家目录开始的具体目录位置
查看文件内容
- cat 文件名:concatenate,查看文件内容、创建文件、文件合并、追加文件内容等功能
- more 文件名:more,分屏显示文件内容
- grep 搜索文本 文件名:grep,搜索文本文件内容。grep允许对文本文件进行模式查找,所谓模式查找,又被称为正则表达式
①^a:行首,搜寻以a开头的行;
②ke$:行尾,搜寻以ke结束的行
其他
-
echo 文字内容:会在终端中显示参数指定的文字,通常会和重定向联合使用
-
重定向>和>>
①Linux允许将命令执行结果重定向到一个文件
②将本应该显示在终端上的内容输出 / 追加到指定文件中
③>:表示输出,会覆盖文件原有的内容
④>>:表示追加,会将内容追加到已有文件的末尾
-
管道 |
①Linux允许将一个命令的输出可以通过管道作为另一个命令的输入
②常用的管道命令有:more、grep
远程管理命令
-
shutdown 选项 时间:关机 / 重新启动
①选项有:-r,重新启动
②不指定选项和参数,默认表示1分钟之后关闭电脑
③想立即关闭 / 重启系统,时间可以填 now
④shutdown -c:取消之前指定的关机计划
⑤shutdown +10:再过10分钟自动关机
-
查看或配置网卡信息
①ifconfig:查看 / 配置计算机当前的网卡配置信息
②ping ip地址:检测到目标ip地址的连接是否正常
-
远程登录和复制文件
①ssh 用户名@ip:关机 / 重新启动
②scp 用户名@ip:文件名或路径 用户名@ip:文件名或路径:远程复制文件
③ssh基础
- 在Linux中SSH是非常常用的工具,通过SSH客户端,我们可以连接到运行了SSH服务器的远程机器上
- SSH客户端是一种使用Secure Shell(SSH)协议连接到远程计算机的软件程序。SSH是目前较可靠,专为远程登录会话和其它网络服务提供安全性的协议
- 利用SSH协议,可以有效防止远程管理过程中的信息泄露;通过SSH协议,可以对所有传输的数据进行加密,也能够防止DNS欺骗和IP欺骗
- SSH的另一项优点是传输的数据可以是经过压缩的,所以可以加快传输的速度
④scp基础
- scp就是secure copy,是一个在Linux下用来进行远程拷贝文件的命令
- 它的地址格式与ssh基本相同,需要注意的是,在指定端口时用的是大写的-P而不是小写的
- 加上-r选项可以传送文件夹
SSH高级
-
免密码登录
①配置公钥
- 执行 ssh-keygen 即可生成SSH钥匙,一路回车即可
②上传公钥到服务器
- 执行 ssh-copy-id -p port user@ip,可以永远让远程服务器记住我们的公钥
-
配置别名
①每次都输入 ssh -p port user@ip ,时间久了就会觉得很麻烦,特别是当user,ip和port都得输入,而且还不好记忆
②而配置别名可以让我们进一步偷懒,譬如用:ssh mac来替代上面这么一长串,那么就在 ~/.ssh/config 里面追加以下内容:
Host mac HostName ip地址 User 用户名 Port 端口号③保存之后,即可用 ssh mac 实现远程登录了,scp同样可以适用
用户权限
-
基本概念
①用户是Linux系统工作中重要的一环,用户管理包括用户与组管理
②在Linux系统中,不论是由本机或是远程登录系统,每个系统都必须拥有一个账号,并且对于不同的系统资源拥有不同的使用权限
③在Linux中,可以指定每一个用户针对不同的文件或者目录的不同权限
④对文件 / 目录的权限包括:
序号 权限 英文 缩写 数字代号 01 读 read r 4 02 写 write w 2 03 执行 excute x 1 ⑤在实际应用中,可以预先针对组设置好权限,然后将不同的用户添加到对应的组中,从而不用依次为每一个用户设置权限
-
chmod简单使用
①chmod可以修改用户 / 组对文件 / 目录的权限
②格式:chmod +/-rwx 文件名 | 目录名
③以上方式会一次性修改拥有者 / 组权限
-
超级用户
①Linux系统中的root账号通常用于系统的维护和管理,对操作系统的所有资源具有所有访问权限。在大多数版本的Linux中,都不推荐直接使用root账号登录系统
②在Linux安装的过程中,系统会自动创建一个用户账号,而这个默认的用户就称为“标准用户”
③sudo命令
- su是substitute user的缩写,表示使用另一个用户的身份
- sudo命令是用来以其它身份来执行命令,预设身份为root
- 用户使用sudo时,必须先输入密码,之后有5分钟的有效期限,超过期限必须重新输入密码
-
组管理终端命令
①创建组 / 删除组的终端命令都需要通过sudo执行
序号 命令 作用 01 groupadd 组名 添加组 02 groupdel 组名 删除组 03 cat /etc/group 确认组信息 04 chgrp 组名 文件 / 目录名 修改文件 / 目录的所属组 ②组信息保存在**/etc/group**文件中
③**/etc**目录是专门用来保存系统配置信息的目录
用户管理
-
用户管理
命令 作用 说明 useradd -m -g 组 新建用户名 添加新用户 -m 自动建立用户家目录;
-g 指定用户所在的组,否则会建立一个和用户同名的组passwd 用户名 设置用户密码 如果是普通用户,直接用passwd可以修改自己的账户密码 userdel -r 用户名 删除用户 -r 选项会自动删除用户家目录 cat /etc/passwd | grep 用户名 确认用户信息 新建用户后,用户信息会保存在 /etc/passwd 文件中 -
查看用户信息
命令 作用 id [用户名] 查看用户UID(用户标识)和GID(组表示)信息 who 查看当前所有登录的用户列表 whoami 查看当前登录用户的账户名 -
usermod
- usermod可以用来设置用户的主组 / 附加组和登录Shell
- 主组:通常在新建用户时指定,在etc/passwd的第四列GID对应的组
- 附加组:在etc/group中最后一列表示该组的用户列表,用于指定用户的附加权限
- 修改用户主组:usermod -g 组 用户名
- 修改用户附加组:usermod -G 组 用户名
- 修改用户登录Shell:usermod -s /bin/bash
-
which
- /etc/passwd:是用于保存用户信息的文件
- /usr/bin/passwd:是用于修改用户密码额程序
- which命令可以查看执行命令所在位置
-
切换用户
命令 作用 说明 su - 用户名 切换用户,并且切换目录 -可以切换到用户家目录,否则保持位置不变 exit 退出当前登录账户 -
修改文件权限
命令 作用 chown 用户名 文件名 | 目录名 修改拥有者 chgrp 修改组 chmod 修改权限 - chmod在设置权限时,可以简单的使用三个数字分别对应拥有者 / 组 / 其他用户的权限,如:chmod -R 755 文件名 | 目录名
拥 有 者 组 其 他 r w x r w x r w x 4 2 1 4 2 1 4 2 1
系统信息
-
时间和日期
命令 作用 date 查看系统时间 cal calendar查看日历,-y选项可以查看一年的日历 -
磁盘信息
命令 作用 df -h disk free 显示磁盘剩余空间 du -h[目录名] disk usage 显示目录下的文件大小 - -h选项:以人性化的方式显示文件大小
-
进程信息
-
所谓进程,就是当前正在执行的一个程序
命令 作用 ps aux process status 查看进程的详细状况 top 动态显示运行中的进程并且排序 kill [-9] 进程代号 终止指定代号的进程,-9表示强制终止 -
ps 默认只会显示当前用户通过终端启动的应用程序
-
ps选项说明
选项 含义 a 显示终端上的所有进程,包括其他用户的进程 u 显示进程的详细状态 x 显示没有控制终端的进程 -
要退出top,可以直接输入q
-
其他命令
-
查找文件
- find命令通常用来在特定的目录下搜索符合条件的文件
- find [路径] -name “*.py”:查找特定路径下扩展名是.py的文件,包括子目录
- 如果省略路径,表示在当前文件夹下查找
-
软链接
命令 作用 ln -s 被链接的源文件 链接文件 建立文件的软链接,用通俗的方式将类似于Windows下的快捷方式 - 没有 -s 选项建立的是一个硬链接文件
- 源文件要使用绝对路径,不能使用相对路径,这样可以方便移动链接文件后,仍然能够正常使用
-
打包解包
-
在不同操作系统中,常用的打包压缩方式是不同的,Windows常用rar,Mac常用zip,Linux常用tar.gz
-
打包文件:tar -cvf 打包文件.tar 被打包的文件 / 路径
-
解包文件:tar -xvf 打包文件.tar
-
tar选项说明
选项 含义 c 生成档案文件,创建打包文件 x 解开档案文件 v 列出归档接档的详细过程,显示进度 f 指定档案的文件名称,f后面一定是.tar文件,所以必须放选项最后
-
-
压缩和解压缩
- tar只负责打包文件,但不压缩。tar与gzip命令结合可以实现文件打包和压缩。用gzip压缩tar打包后的文件,其扩展名一般用xxx.tar.gz
- 在tar命令中有一个选项-z可以调用gzip,从而可以方便的实现压缩和解压缩的功能
- 压缩文件:tar -zcvf 打包文件.tar,gz 被压缩的文件 / 路径
- 解压缩文件:tar -zxvf 打包文件.tar.gz
- 解压缩到指定路径:tar -zxvf 打包文件.tar.gz -C 目标路径
- tar与bzip2命令结合可以实现文件的打包和压缩,用bzip2压缩tar打包后的文件,其扩展名一般用xxx.tar.bz2.在tar命令中有一个选项-j可以调用bzip2
-
通过apt安装 / 卸载软件
- apt是Advanced Packaging Tool,是Linux下的一款安装包管理工具,可以在终端中方便的安装 / 卸载 / 更新软件包
- 安装软件:sudo apt install 软件包
- 卸载软件:sudo apt remove 软件名
- 更新已安装的包:sudo apt upgrade
Python基础
Python简介
- 计算机不能直接理解任何除机器语言以外的语言,所以必须要把程序员写的程序语言翻译成机器语言,计算机才能执行程序。将其他语言翻译成机器语言的工具,被称为编译器
- 编译器翻译的方式有两种:一个是编译,另一个是解释。两种方式之间的区别在于翻译时间点的不用。当编译器以解释的方式运行的时候,也称之为解释器
- Python特点
- Python是完全面向对象的语言
- Python拥有一个强大的标准库
- Python社区提供了大量的第三方模块
第一个Python程序
-
Python源程序就是一个特殊格式的文本文件,可以使用任意文本编辑软件做Python的开发。Python程序的文件扩展名通常都是 .py
-
第一个程序
print("Hello python") print("Hello world") -
print是python中我们学习的第一个函数,print函数的作用,可以把""内部的内容,输出到屏幕上
-
执行Python程序的三种方式
- 解释器python(python 2.x) / python3(python 3.x)
- CPython:官方版本的C语言实现
- Jython:可以运行在Java平台
- IronPython:可以运行在.NET和Mono平台
- PyPy:Python实现的,支持JIT即时编译
- 交互式运行Python程序
- 在Python的Shell中直接输入Python的代码,会立即看到程序执行结果
- Python的IDE——PyCharm
- 集成开发环境(IDE,Integrated Development Environment),集成了开发软件需要的所有工具,一般包括:图形界面、代码编辑器、编译器/解释器等
- PyCharm是Python的一款非常优秀的集成开发环境,除了具有一般IDE所必备的功能外,还可以在Windows、Linux、macOS下使用,适合开发大型项目
- 解释器python(python 2.x) / python3(python 3.x)
-
Python命名规则
- 命名文件时建议只使用小写字母、数字和下划线
- 文件名不能以数字开头
程序的注释
- 注释的作用:使用自己熟悉的语言,在程序中对某些代码进行标准说明,增强程序的可读性
- 单行注释(行注释)
- 以 # 开头,# 右边的所有东西都被当成说明文字,而不是真正要执行的程序,只起到辅助说明作用
- 为了保证代码的可读性,# 后面建议先添加一个空格,然后再编写相应的说明文字
- 在程序开发时,同样可以使用 # 在代码的后面(旁边)增加说明性的文字
- 多行注释(块注释)
- 如果希望编写的注释信息很多,一行无法显示,就可以使用多行注释
- 要在Python程序中使用多行注释,可以使用一对连续的三个引号(单引号和双引号都可以)
算术运算符
-
算术运算符是运算符的一种,是完成基本的算术运算使用的符号,用来处理四则运算
运算符 描述 实例 + 加 10 + 20 = 30 - 减 20 - 10 = 10 * 乘 10 * 20 = 200 / 除 10 / 20 = 0.5 // 取整除 返回除法的整数部分(商) % 取余数 返回除法的余数 9%2=1 ** 幂 又称次方,乘方 -
在Python中 * 运算符还可以用于字符串,计算结果就是字符串重复指定次数的结果
-
算术运算符的优先级
- 先乘除后加减
- 同级运算符是从左至右计算
- 可以使用 () 调整计算的优先级
-
优先级排序
运算符 描述 ** 幂(最高优先级) * / % // 乘、除、取余数、取整数 + - 加、减
变量
-
定义:程序就是用来处理数据的,而变量就是用来存储数据的。在Python中,每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建
-
等号(=)用来给变量赋值,左边是变量名,右边是存储在变量中的值。变量名 = 值。变量定义之后,后续就可以直接使用了
-
在Python中,定义变量时是不需要指定变量的类型的,在运行的时候,Python的解释器,会根据赋值语句等号右侧的数据,自动推导出变量中保存数据的准确类型
-
数据类型可以分为数字型和非数字型
- 数字型
- 整型(int)
- 浮点型(float)
- 布尔型(bool)
- 真 True 非0数 ——非零即真
- 假 False 0
- 复数型(complex)
- 主要用于科学计算
- 非数字型
- 字符串
- 列表
- 元组
- 字典
- 数字型
-
使用 type() 函数可以查看一个变量的类型
-
不同类型变量之间的计算
- 数字型变量之间可以直接计算
- 在Python中,两个数字型变量是可以直接进行算术运算的,如果变量是bool型,在计算时,True对应的数字是1,False对应的数字是0
- 字符串变量之间使用 + 拼接字符串
- 在Python中,字符串之间可以使用 + 拼接生成新的字符串
- 字符串变量可以和整数使用 * 重复拼接相同的字符串
- 数字型变量和字符串之间不能进行其他计算
- 数字型变量之间可以直接计算
-
变量的输入
-
所谓输入,就是用代码获取用户通过键盘输入的信息。在Python中,如果要获取用户在键盘上的输入信息,需要使用到 input 函数
-
函数就是一个提前准备好的功能(别人或者自己的代码),可以直接使用,而不用关心内部的细节。已经学习过的函数有:
函数 说明 print(x) 将x输出到控制台 type(x) 查看x的变量属性 -
在Python中可以使用 input 函数从键盘等待用户的输入,用户输入的任何内容Python都认为是一个字符串
- 语法:字符串变量 = input(“提示信息:”)
-
类型转换函数
函数 说明 int(x) 将 x 转换为一个整数 float(x) 将 x 转换为一个浮点数
-
-
变量的格式化输出
-
在Python中如果希望输出文字信息的同时,一起输出数据,就需要用到格式化操作符。%被称为格式化操作符,专门用于处理字符串中的格式,包含 % 的字符串,被称为格式化字符串。% 和不同的字符连用,不同类型的数据需要使用不同的格式化字符串
格式化字符串 含义 %s 字符串 %d 有符号十进制整数,%06d表示输出的整数显示位数,不足的地方使用0补全 %f 浮点数,%.02f表示小数点后只显示两位 %% 输出% -
语法格式:
- print(“格式化字符串” % (变量1,变量2…))
-
-
变量的命名
-
标识符就是程序员定义的变量名、函数名
-
标识符可以由字母、数字和下划线组成,不能以数字开头,不能与关键字重名
-
关键字就是在Python内部已经使用的标识符,关键字具有特殊的功能和含义,开发者不允许定义和关键字相同名字的标识符
-
通过以下命令可以查看Python中的关键字
import keyword print(keyword.kwlist) -
import关键字可以导入一个“工具包”,在Python中不同的工具包,提供有不同的工具
-
-
变量的命名规则
- 命名规则可以被视为一种惯例,并无绝对与强制,目的是为了增加代码的识别和可读性
- 在Python中的标识符是区分大小写的
- 在定义变量时,为了保证代码格式,= 的左右应该各保留一个空格
- 在Python中,如果变量名需要由二个或多个单词组成时,可以按照以下方式命名
- 每个单词都使用小写字母
- 单词与单词之间使用 _下划线 连接
- 当变量名是由二个或多个单词组成时,还可以利用驼峰命名法来命名
- 小驼峰式命名法
- 第一个单词以小写字母开始,后续单词的首字母大写
- 大驼峰式命名法
- 每一个单词的首字母都采用大写字母
判断语句
-
if语句
-
在Python中,if 语句 就是用来进行判断的,整个 if 语句可以看成一个完整的代码块,格式如下:
if 要判断的条件 : 条件成立时,要做的事情 ... -
代码的缩进为一个 tab 键,或者4个空格,建议使用空格。在Python开发中,Tab和空格不能混用
-
-
else处理条件不满足的情况
-
在使用 if 判断时,只能做到满足条件时要做的事情,那如果需要在不满足条件的时候,做某些事情,就需要使用else语句
if 要判断的条件 : 条件成立时,要做的事情 ... else : 条件不成立时,要做的事情 ... -
if 和 else 语句以及各自的缩进部分共同是一个完整的代码块
-
-
elif语句
-
在开发中,使用 if 可以判断条件,使用 else 可以处理条件不成立的情况,但是,如果希望在增加一些条件,条件不同,需要执行的代码也不同时,就可以使用 elif
-
语法格式
if 条件1 : 条件1满足时,执行的代码 ... elif 条件2 : 条件2满足时,执行的代码 ... else : 以上条件都不满足时,执行的代码 ... -
elif 和 else 都必须和 if 联合使用,而不能单独使用
-
-
if 嵌套
- 在开发中,使用 if 进行条件判断,如果希望在条件成立的执行语句中,再增加条件判断,就可以使用if 的嵌套
- if 的嵌套的应用场景:在之前条件满足的前提下,在增加额外的判断
- if 的嵌套的语法格式,除了缩进之外和之前的没有区别
运算符
-
比较(关系)运算符
运算符 描述 == 检查两个操作数的值是否相等,如果是,则条件成立,返回True != 检查两个操作数的值是否不相等,如果是,则条件成立,返回True > 检查左操作数的值是否大于右操作数的值,如果是,则条件成立,返回True < 检查左操作数的值是否小于右操作数的值,如果是,则条件成立,返回True >= 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立,返回True <= 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立,返回True -
逻辑运算
-
在程序开发中,通常在判断条件时,会需要同时判断多个条件,只有多个条件都满足,才能够执行后续代码,这个时候就需要使用到逻辑运算符。逻辑运算符可以把多个条件按照逻辑进行连接,变成更复杂的条件
-
Python中的逻辑运算符包括:与and / 或or / 非not 三种
-
and
-
条件1 and 条件2
-
两个条件同时满足,返回True;只要有一个不满足,就返回False
条件1 条件2 结果 成立 成立 成立 成立 不成立 不成立 不成立 成立 不成立 不成立 不成立 不成立
-
-
or
-
条件1 or 条件2
-
两个条件只要有一个满足,返回True;两个条件都不满足,返回False
条件1 条件2 结果 成立 成立 成立 成立 不成立 成立 不成立 成立 成立 不成立 不成立 不成立
-
-
not
-
not 条件
条件 结果 成立 不成立 不成立 成立
-
-
-
赋值运算符
-
在Python中,使用 = 可以给变量赋值,在算术运算时,为了简化代码的编写,Python还提供了一系列的与算术运算符对应的赋值运算符。使用赋值运算符时,中间不能使用空格
运算符 描述 实例 = 简单的赋值运算符 c = a + b 将 a + b的运算结果赋值给c += 加法赋值运算符 c += a 等效于 c = c + a -= 减法赋值运算符 c -= a 等效于 c = c - a *= 乘法赋值运算符 c *= a 等效于 c = c * a /= 除法赋值运算符 c /= a 等效于 c = c / a //= 取整除赋值运算符 c //= a 等效于 c = c // a %= 取模(余数)赋值运算符 c %= a 等效于 c = c % a **= 幂赋值运算符 c **= a 等效于 c = c ** a
-
随机数
-
在Python中,要使用随机数,首先需要导入随机数的模块——“工具包”
import random -
导入模块后,可以直接在模块名称后面敲一个 . 然后按 Tab 键,会提示该模块中包含的所有函数
random.randint(a, b) # 返回[a, b]之间的整数,包含 a 和 b -
在导入工具包的时候,应该将导入的语句,放在文件的顶部,这样可以方便下方的代码,在任何需要的时候,使用工具包中的工具
循环
-
程序的三大流程
- 顺序:从上向下,顺序执行代码
- 分支:根据条件判断,决定执行代码的分支
- 循环:让特定代码重复执行
-
while 循环基本使用
-
循环的作用就是让指定的代码重复的执行,while 循环最常见的应用场景就是让执行的代码按照指定的次数重复执行
-
基本语法
# 初始条件设置——通常是重复执行的计数器 while 条件(判断计数器是否达到目标次数) : 条件满足时,做的事情 ... 处理条件(计数器 + 1)
-
-
死循环
- 由于程序员的原因,忘记在循环内部修改循环的判断条件,导致循环持续执行,程序无法终止
-
Python中的计数方法
- 自然计数法(从1开始)
- 程序计数法(从0开始):几乎所有的程序语言都选择从 0 开始计数
- 在编写程序时,除非需求的特殊要求,否则循环的计数都从 0 开始
-
循环计算
-
计算 0 ~ 100 之间所有数字的累计求和结果
sum = 0 i = 0 while i <= 100 : sum += i i += 1 print(sum) -
计算 0 ~ 100 之间所有偶数的累计求和结果
sum = 0 i = 0 while i <= 100 : if i % 2 == 0: sum += i i += 1 print(sum)
-
-
break 和 continue
- break 和 continue 是专门在循环中使用的关键字
- break 某一条件满足时,退出循环,不再执行后续重复的代码
- continue 某一条件满足时,不执行当前循环的后续代码,转到下一次循环
- break 和 continue 只针对当前所在循环有效
- 注意:在循环中,如果使用continue这个关键字,在使用之前,需要确认循环的计数是否修改,否则可能会导致死循环
-
循环嵌套
- while 嵌套就是:while里面还有while
-
print 函数增强
- 在默认情况下,print 函数输出内容之后,会自动在内容末尾增加换行。如果不希望末尾增加换行,可以在print函数输出内容的后面增加 end=“”
- 其中 “” 中间可以指定print函数输出内容之后,继续希望显示的内容
-
循环嵌套练习
-
连续输出五行 * ,每一行星号的数量依次递增
i = 1 while i <= 5 : j = 1 while j <= i : print("*", end = "") j += 1 print() i += 1 -
九九乘法表
i = 1 while i <= 9 : j = 1 while j <= i : print(j, "*", i, "=", j * i, end = "\t") j += 1 print("") i += 1
-
转义字符
-
\t:在控制台输出一个 制表符,协助在输出文本时,垂直方向保持对齐
- 制表符的功能是在不使用表格的情况下在垂直方向按列对齐文本
-
\n:在控制台输出一个 换行符
转义字符 描述 \\ 反斜杠符号 \’ 单引号 \" 双引号 \n 换行 \t 横向制表符 \r 回车
函数
-
函数的概念
- 所谓函数,就是把具有独立功能的代码块组织为一个小模块,在需要的时候调用
- 函数的使用包含两个步骤:
- 定义函数:封装独立的功能
- 调用函数:享受封装的成果
- 函数的作用,在开发程序时,使用函数可以提高编写的效率以及代码的重用
-
函数的定义
def 函数名() : 函数封装的代码 ...- def 是英文 define 的缩写,函数名称应该能够表达函数封装代码的功能,方便后续的调用
- 函数名称的命名应该符合标识符的命名规则
- 定义好函数之后,只表示这个函数封装了一段代码而已,如果不主动调用函数,函数是不会主动执行的
-
函数调用
- 调用函数很简单,通过 函数名() 即可完成对函数的调用
- 函数调用必须在函数定义之后,不能先调用,后定义
-
函数的文档注释
- 在开发中,如果希望给函数添加注释,应该在定义函数的下方,使用连续的三对引号,在连续的三对引号之间编写对函数的说明文字
- 在函数调用位置,使用快捷键 Ctrl+Q 可以查看函数的说明信息
- 因为函数体相对比较独立,函数定义的上方,应该和其他代码(包括注释)保留两个空行
-
函数的参数
- 在函数名后面的小括号内部填写 参数,多个参数之间使用 , 分隔
- 函数,把具有独立功能的代码块组织为一个小模块,在需要的时候调用
- 函数的参数,增加函数的通用性,针对相同的数据处理逻辑,能够适应更多的数据
- 在函数内部,把参数当做变量使用,进行需要的数据处理
- 函数调用时,按照函数定义的参数顺序,把希望在函数内部处理的数据,通过参数传递
- 形参:定义函数时,小括号中的参数,是用来接收参数用的,在函数内部作为变量使用
- 实参:调用函数时,小括号中的参数,是用来把数据传递到函数内部用的
-
函数的返回值
- 在程序开发中,有时候,会希望一个函数执行结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理
- 返回值是函数完成工作后,最后给调用者的一个结果。在函数中使用 return 关键字可以返回结果
- 调用函数的一方,可以使用变量来接收函数的返回结果
- return 表示返回,后续的代码都不会被执行
-
函数的嵌套调用
- 一个函数里面又调用了另外一个函数,这就是函数嵌套调用
- 如果函数test2中,调用了test1,那么执行到调用test1函数时,会先把函数test1中的任务都执行完,才会回到test2中调用函数test1的位置,继续执行后续的代码
模块
- 模块是Python程序架构的一个核心概念
- 模块就好比是工具包,要想使用这个工具包中的工具,就需要导入import这个模块
- 每一个以扩展名 py 结尾的Python源代码文件都是一个模块,在模块中定义的全局变量、函数都是模块能够提供给外界直接使用的工具
- 可以在一个Python文件中定义变量或者函数,然后在另外一个文件中使用 import 导入这个模块,导入之后,就可以使用 模块名.变量 / 模块名.函数 的方式,使用这个模块中定义的变量或者函数
- 模块名也是一个标识符
列表
-
在Python中,所有非数字型变量都支持以下特点:
- 都是一个序列(sequence),也可以理解为容器
- 取值 []
- 遍历 for in
- 计算长度、最大 / 最小值、比较、删除
- 链接 + 和重复 *
- 切片
-
列表的定义
-
List(列表)是Python中使用最频繁的数据类型,在其他语言中通常叫做数组。专门用于存储一串信息
-
列表用 [] 定义,数据之间使用 , 分隔,列表的索引从 0 开始
-
索引就是数据在列表中的位置编号,索引又可以被称为下标,从列表中取值时,如果超出索引范围,程序会报错
name_list = ["zhangsan", "lisi", "wangwu"]
-
-
列表常用操作
序号 分类 关键字 / 函数 / 方法 说明 1 增加 列表.insert(索引, 数据) 在指定位置插入数据 列表.append(数据) 在末尾追加数据 列表.extend(列表2) 将列表2的数据追加到列表 2 修改 列表[索引] = 数据 修改指定索引的数据 3 删除 del 列表[索引] 删除指定索引的数据 列表.remove[数据] 删除第一个出现的指定数据 列表.pop 删除末尾数据 列表.pop(索引) 删除指定索引数据 列表.clear 清空列表 4 统计 len(列表) 列表长度 列表.count(数据) 数据在列表中出现的次数 5 排序 列表.sort() 升序排序 列表.sort(reverse=True) 降序排序 列表.reverse() 逆序、反转 6 取值 列表名[索引] 取出指定索引的值 列表.index(数据) 确定数据在列表中的索引 - 使用 index 方法需要注意,如果传递的数据不在列表中,程序会报错
- del 关键字本质上是用来将一个变量从内存中删除的
-
关键字、函数和方法
- 关键字是Python内置的、具有特殊意义的标识符,关键字后面不需要使用括号
- 函数封装了独立功能,可以直接调用
- 方法和函数类似,同样是封装了独立的功能,方法需要通过对象来调用,表示针对这个对象要做的操作
-
列表的循环遍历
-
遍历就是从头到尾依次从列表中获取数据,在循环体内部针对每一个元素,执行相同的操作
-
在Python中为了提高列表的遍历效率,专门提供的迭代iteration遍历,使用 for 就能够实现迭代遍历
# for循环内部使用的变量 in 列表 for name in name_list : 循环内部针对列表元素进行操作 print(name)
-
元组
-
元组的定义
-
Tuple(元组)与列表类似,不同之处在于元组的元素不能修改,元组表示多个元素组成的序列,在Python中,元组有特定的应用场景,元组用于存储一串信息,数据之间用 , 分隔
-
元组用 () 定义,索引从 0 开始
info_tuple = ("zhangsan", 18, 1.75) # 创建一个空元组 info_tuple = () -
元组中只包含一个元素时,需要在元素后面添加逗号
-
-
元组的常用操作
- 元组名.count:获取某个数据在元组中出现的次数
- 元组名.index:获取某个数据在元组中对应的索引下标
-
元组的遍历
- 在Python中,可以使用 for 循环遍历所有非数字型的变量:列表、元组、字典、以及字符串
- 在实际开发中,除非能够确认元组中的数据类型,否则针对元组的循环遍历需求并不是很多。因为元组中通常保存的数据类型是不用的
-
元组的应用场景
- 函数的参数和返回值,一个函数可以接收任意多个参数,或者一次返回多个数据
- 格式化字符串,格式化字符串后面的 () 本质上就是一个元组
- 让列表不可以被修改,以保护数据安全
-
元组和列表之间的转换
- 使用 list 函数可以把元组转换成列表
- 使用 tuple 函数可以把列表转换成元组
字典
-
字典的定义
-
dictionary(字典)是除列表外Python中最灵活的数据类型。字典同样可以用来存储多个数据,通常用于存储描述一个物体的相关信息
-
和列表的区别
- 列表是有序的对象集合
- 字典是无序的对象集合
-
字典用 {} 定义,使用键值对存储数据,键值对之间使用 , 分隔
- 键 key 是索引
- 值 value 是数据
- 键和值之间使用 : 分隔
- 键必须是唯一的
- 值可以是任何数据类型,但键只能使用字符串、数字或元组
person = { "name" : "小明", "age" : 18, "gender" : True, "height" : 1.75 }
-
-
字典的常用操作
- 字典名[key]:取值
- 字典名[key] = 值:新增或修改
- 字典名.pop[key]:删除
- len(字典名):统计键值对数量
- 字典名.update(字典名2):合并字典
- 如果被合并的字典中包含已经存在的键值对,会覆盖原有的键值对
- 字典名.clear():清空字典
-
字典的遍历
- 字典的遍历和之前一样,使用for循环,循环时的变量,是获取到的键值对的key
-
应用场景
- 使用多个键值对,存储描述一个物体的相关信息
- 将多个字典放在一个列表中,再进行遍历,在循环体内部针对每一个字典进行相同的处理
字符串
-
字符串的定义
- 字符串就是一串字符,是编程语言中表示文本的数据类型
- 在Python中可以使用 一对双引号"" 或者 一对单引号’’ 定义一个字符串
- 虽然可以使用 \" 或者 \’ 做字符串的转义,但是在实际开发中:
- 如果字符串内部需要使用 " ,可以使用 ’ 定义字符串
- 如果字符串内部需要使用 ’ ,可以使用 " 定义字符串
- 可以使用索引获取一个字符串中指定位置的字符,索引计数从0开始,也可以使用for循环遍历字符串中每一个字符
-
字符串的常用操作
- len(字符串):获取字符串的长度
- 字符串.count(字符串):小字符串在大字符串中出现的次数
- 字符串[索引]:从字符串中取出单个字符
- 字符串.index(字符串):获取小字符串第一次出现的索引
-
字符串的切片
-
切片方法适用于字符串、列表、元组。切片使用索引值来限定范围,从一个大的字符串中切出小的字符串
-
列表和元组都是有序集合,都能够通过索引值获取到对应的数据。字典是一个无序集合,是使用键值对保存数据
字符串[开始索引 : 结束索引 : 步长] -
指定的区间属于 左闭右开型,从起始位开始,到结束位的前一位结束,不包括结束位本身
-
从头开始,开始索引数字可以省略,冒号不能省略。到末尾结束,结束索引数字可以省略,冒号不能省略。步长默认为1,如果连续切片,数字和冒号都可以省略
-
公共方法
-
Python内置函数
函数 描述 备注 len(item) 计算容器中元素个数 del(item) 删除变量 del有两种方式 max(item) 返回容器中元素最大值 如果是字典,只针对key比较 min(item) 返回容器中元素最小值 如果是字典,只针对key比较 cmp(item1, item2) 比较两个值,-1小于 / 0相等 / 1大于 Python 3.x取消了cmp函数 -
切片
描述 Python表达式 结果 支持的数据类型 切片 “0123456”[::-2] “6420” 字符串、列表、元组 - 切片使用索引值来限定范围,从一个大的字符串中切出小的字符串
- 列表和元组都是有序的集合,都能够通过索引值获取到对应的数据
- 字典是一个无序的集合,是使用键值对保存数据
-
运算符
运算符 Python表达式 结果 描述 支持的数据类型 + [1, 2] + [3, 4] [1, 2, 3, 4] 合并 字符串、列表、元组 * [“a”] * 4 [“a”, “a”, “a”, “a”] 重复 字符串、列表、元组 in 3 in (1, 2, 3) True 元素是否存在 字符串、列表、元组、字典 not in 4 not in (1, 2, 3) True 元素是否不存在 字符串、列表、元组、字典 > >= == < <= (1, 2, 3) < (2, 2, 3) True 元素比较 字符串、列表、元组 - in 在对字典操作时,判断的是字典的键
- in 和 not in 被称为成员运算符
-
完整的 for 循环语法
for 变量 in 集合 : 循环体代码 else : 没有通过 break 退出循环,循环结束后,会执行的代码
综合应用——名片管理系统
-
系统需求
- 程序启动,显示名片管理系统欢迎界面,并显示功能菜单
- 用户用数字选择不同的功能
- 根据功能选择,执行不同的功能
- 用户名片需要记录用户的姓名、电话、QQ、邮件
- 如果查询到指定的名片,用户可以选择修改或者删除名片
-
pass关键字
- 如果在开发程序时,不希望立刻编写分支内部的代码,可以使用pass关键字,表示一个占位符,能够保证程序的代码结构正确
-
代码
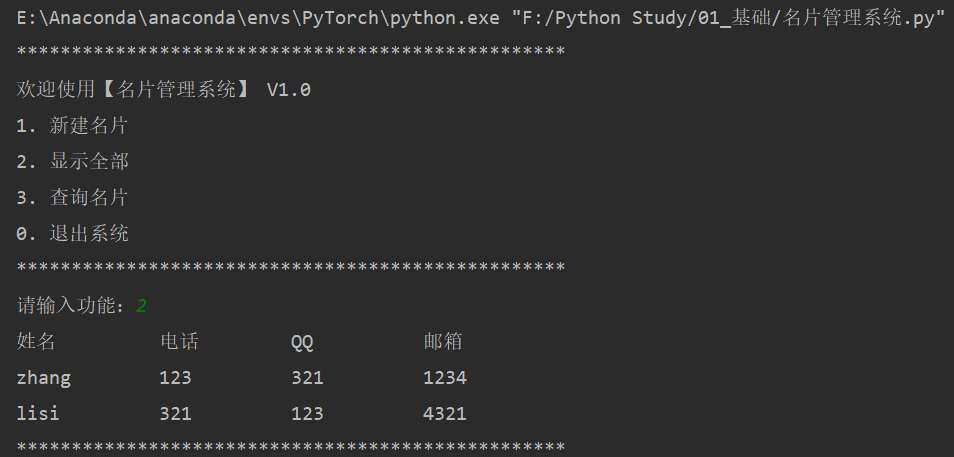
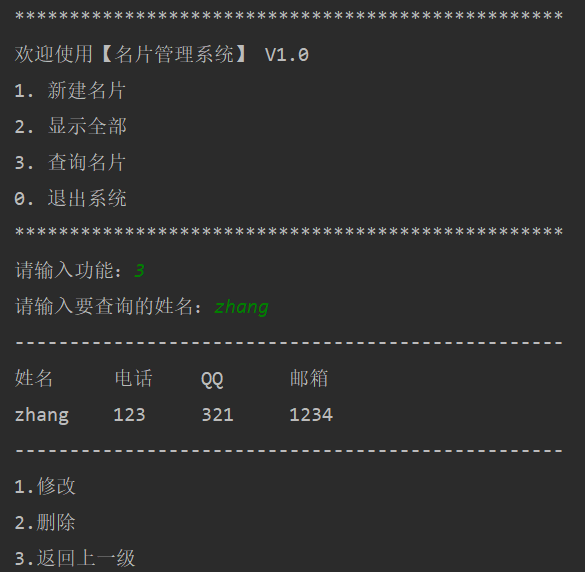
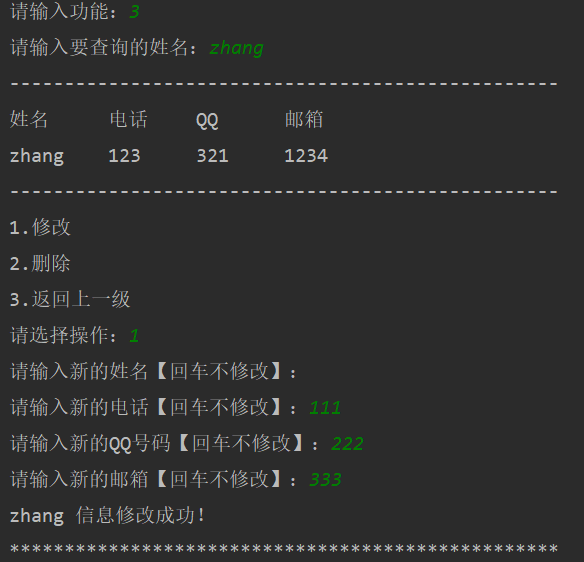
""" 系统需求: - 程序启动,显示名片管理系统欢迎界面,并显示功能菜单 - 用户用数字选择不同的功能 - 根据功能选择,执行不同的功能 - 用户名片需要记录用户的姓名、电话、QQ、邮件 - 如果查询到指定的名片,用户可以选择修改或者删除名片 """ # 创建一个用户名片列表,列表内部使用字典 users = [] while True : # 欢迎界面 print("*" * 50) print("欢迎使用【名片管理系统】 V1.0") print("1. 新建名片") print("2. 显示全部") print("3. 查询名片") print("0. 退出系统") print("*" * 50) user_choose = input("请输入功能:") if user_choose == "1" : user_name = input("请输入姓名:") user_phone = input("请输入电话:") user_QQ = input("请输入QQ号码:") user_email = input("请输入邮箱:") temp = { "name" : user_name, "phone" : user_phone, "QQ" : user_QQ, "email" : user_email} users.append(temp) print("用户添加成功!") elif user_choose == "2" : if len(users) == 0 : print("当前系统内没有任何数据!") else : print("姓名 \t\t 电话 \t\t QQ \t\t 邮箱") for user in users : print("%s \t\t %s \t\t %s \t\t %s" % (user["name"], user["phone"], user["QQ"], user["email"])) elif user_choose == "3" : user_find = input("请输入要查询的姓名:") for user in users : if user["name"] == user_find : print("-" * 50) print("姓名 \t 电话 \t QQ \t 邮箱") print("%s \t %s \t %s \t %s" % (user["name"], user["phone"], user["QQ"], user["email"])) print("-" * 50) print("1.修改") print("2.删除") print("3.返回上一级") user_find_option = input("请选择操作:") if user_find_option == "1" : update_name = input("请输入新的姓名【回车不修改】:") if update_name != "" : user["name"] = update_name update_phone = input("请输入新的电话【回车不修改】:") if update_phone != "" : user["phone"] = update_phone update_QQ = input("请输入新的QQ号码【回车不修改】:") if update_QQ != "" : user["QQ"] = update_QQ update_email = input("请输入新的邮箱【回车不修改】:") if update_email != "" : user["email"] = update_email print("%s 信息修改成功!" % user["name"]) break elif user_find_option == "2" : users.remove(user) print("%s 删除成功!" % user["name"]) break elif user_find_option == "3" : break else : # 都查询一遍,如果没有,则提示用户查无此人 print("查无此人!") elif user_choose == "0" : print("欢迎再次使用【名片管理系统】!") break; else : print("请输入正确的功能序号!") -
系统截图
变量进阶
- 引用的概念
- 在Python中,变量和数据是分开存储的,数据保存在内存中的一个位置,变量中保存着数据在内存中的地址,变量中记录数据的地址,就叫做引用
- 使用 id() 函数可以查看变量中保存数据所在的内存地址
- 如果变量已经被定义,当给一个变量赋值的时候,本质上是修改了数据的引用
- 在Python中,函数的 实参 / 返回值 都是靠引用来传递的
- 可变和不可变类型
- 不可变类型:内存中的数据不允许被修改:
- 数字类型:int, bool, float, complex, long(2.x)
- 字符串:str
- 元组:tuple
- 可变类型:内存中的数据可以被修改:
- 列表:list
- 字典:dict
- 字典的key只能使用不可变类型的数据
- 可变类型的数据变化,是通过方法来实现的。如果给一个可变类型的变量,赋值了一个新的数据,引用会修改
- 不可变类型:内存中的数据不允许被修改:
- 哈希(hash)
- Python中内置有一个名字叫做 hash(o) 的函数,可以接收一个不可变类型的数据作为参数,返回结果是一个整数
- 哈希是一种算法,其作用就是提取数据的特征码(指纹),相同的内容得到相同的结果,不同的内容得到不同的结果
- 在Python中,设置字典的键值对时,会首先对key进行hash已决定如何在内存中保存字典的数据,以方便后续对字典的操作:增、删、改、查
- 键值对的key必须是不可变类型数据,键值对的value可以是任意类型的数据
- 局部变量
- 局部变量是在函数内部定义的变量,只能在函数内部使用
- 函数执行结束后,函数内部的局部变量,会被系统回收。不同的函数,可以定义相同名字的局部变量,但是不会相互影响
- 局部变量在函数内部使用,临时保存函数内部需要使用的数据
- 局部变量的生命周期
- 所谓生命周期就是变量从被创建到被系统回收的过程
- 局部变量在函数执行时才会被创建,函数执行结束后被系统回收
- 局部变量在生命周期内,可以用来存储函数内部临时使用到的数据
- 全局变量
- 全局变量是在函数外部定义的变量(没有定义在某一个函数内),所有函数内部都可以使用这个变量
- 函数执行时,需要处理变量时,会:
- 首先查找函数内部是否存在指定名称的局部变量,如果有,直接使用
- 如果没有,查找函数外部是否存在指定名称的全局变量,如果有,直接使用
- 如果还没有,程序报错
- 在函数内部,可以通过全局变量的引用获取对应的数据,但是,不允许直接修改全局变量的引用——使用赋值语句修改全局变量的值,这样只会在函数内部定义一个新的局部变量
- 如果在函数中需要修改全局变量,需要使用 global 关键字进行声明。global关键字会告诉解释器后面的变量是一个全局变量,再使用赋值语句时,就不会创建局部变量
- 为了保证所有的函数都能够正确使用到全局变量,应该将全局变量定义在其他函数的上方
函数参数和返回值
-
函数返回值
-
元组可以包含多个数据,因此可以使用元组让函数一次返回多个值。如果函数返回的是元组,小括号可以省略
-
如果函数返回的类型是元组,同时希望单独的处理元组中的元素,可以使用多个变量,一次接收函数的返回结果。使用多个变量接收结果时,变量的个数应该和元组中元素的个数保持一致
num1, num2 = method() -
交换两个变量的值:a, b = b, a
-
-
函数的参数
- 无论传递的参数是可变还是不可变。只要针对参数使用赋值语句,会在函数内部修改局部变量的引用,不会影响到外部变量的引用
- 如果传递的参数是可变类型,在函数内部,使用方法修改了数据的内容,同样会影响到外部的数据
- 在Python中,列表变量调用 += 本质上是在执行列表变量的extend方法,不会修改变量的引用
-
缺省参数
-
定义函数时,可以给某个参数指定一个默认值,具有默认值的参数就叫做缺省参数
-
调用函数时,如果没有传入缺省参数的值,则在函数内部使用定义函数时指定的参数默认值
-
函数的缺省参数,将常见的值设置为参数的缺省值,从而简化函数的调用
-
指定函数的缺省参数
- 在参数后使用赋值语句,可以指定参数的缺省值
-
缺省参数,需要使用最常见的值作为默认值,如果一个参数的值不确定,则不应该设置默认值,具体的数值在调用函数时,由外界传递
def print_info(name, gender = True) : gender_text = "男生" if not gender : gender_text = "女生" print("%s 是 %s" % (name, gender_text)) print_info("老王") print_info("小明", False) -
缺省参数的注意事项
- 带有默认值的缺省参数必须在参数列表末尾
- 在调用函数时,如果有多个缺省参数,需要指定参数名,这样解释器才能够知道参数的对应关系
-
-
多值参数
- 有时可能需要一个函数能够处理的参数个数是不确定的,这个时候,就可以使用多值参数
- Python中有两种多值参数:
- 参数名前增加一个 * 可以接收元组
- 参数名前增加两个 * 可以接收字典
- 一般在给多值参数命名是,习惯使用一下两个名字
- *args —— 存放元组数组,前面有一个*
- **kwargs —— 存放字典参数,前面有两个*
- 在调用带有多值参数的函数时,如果希望将一个元组变量,直接传递给args,将一个字典变量直接传递给kwargs,就可以使用拆包,简化参数的传递,拆包的方式是:
- 在元组变量前,增加一个*
- 在字典变量前,增加两个*
递归
-
特点
- 一个函数内部调用自己
- 函数内部的代码是相同的,只是针对参数不同,处理的结果不同。当参数满足一个条件时,函数不再执行。这个非常重要,通常被称为递归的出口,否则会出现死循环
-
递归实现数字累加
def num_sum(num) : if num == 0: return 0 return num + num_sum(num - 1) sum = num_sum(4) print(sum)
面向对象
-
面向对象编程——Object Oriented Programming 简写OOP。之前学习的编程方式就是面向过程的,面向过程和面向对象,是两种不同的编程方式
- 过程是早期的一个编程概念,过程类似于函数,只能执行,但是没有返回值,函数不仅能执行,还可以返回结果
-
面向过程——怎么做?
- 把完成某一个需求的所有步骤从头到尾逐步实现
- 根据开发需求,将某些功能独立的代码封装成一个又一个函数
- 最后完成的代码,就是顺序地调用不同的函数
-
面向过程特点
- 注重步骤与过程,不注重职责分工
- 如果需求复杂,代码会变得很复杂
- 开发复杂项目,没有固定的套路,开发难度很大
-
面向对象——谁来做?
- 相比较函数,面向对象是更大的封装,根据职责在一个对象中封装多个方法
- 在完成某一个需求前,首先确定职责——要做的事情(方法)
- 根据职责确定不同的对象,在对象内部封装不同的方法(多个)
- 最后完成的代码,就是顺序地让不同的对象调用不同的方法
-
面向对象特点
- 注重对象和职责,不同的对象承担不同的职责
- 更加适合应对复杂的需求变化,是专门应对复杂项目开发,提供的固定套路
- 需要在面向过程基础上,再学习一些面向对象的语法
-
类
- 类是对一群具有相同特征或行为的事物的一个统称,是抽象的,不能直接使用。特征被称为属性,行为被称为方法
-
对象
- 对象是由类创建出来的一个具体存在,可以直接使用
- 由哪一个类创建出来的对象,就拥有在哪一个类中定义的属性和方法
- 在程序开发中,应该先有类、再有对象
- 类是模板,对象是根据类这个模板创建出来的,类只有一个,而对象可以有很多个,不同的对象之间属性可能会各不相同
- 类中定义了什么属性和方法,对象中就有什么属性和方法,不可能多,也不可能少
-
类的设计
- 类名:这类事物的名字,满足大驼峰命名法
- 属性:这类事物具有什么样的特征
- 对对象的特征描述
- 方法:这类事物具有什么样的行为
- 对象具有的行为(动词)
-
dir内置函数
-
使用内置函数 dir 传入标识符 / 数据,可以查看对象内的所有属性及方法
-
提示 __方法名__ 格式的方法是Python提供的内置方法 / 属性
方法名 类型 作用 __new__ 方法 创建对象时,会被自动调用 __init__ 方法 对象被初始化时,会被自动调用 __del__ 方法 对象被从内存中销毁前,会被自动调用 __str__ 方法 返回对象的描述信息,print函数输出使用
-
定义类
-
语法
class 类名 : def 方法1(self, 参数列表) : pass def 方法2(self, 参数列表) : pass- 方法的定义格式和之前学习过的函数几乎一样,区别在于第一个参数必须是 self
-
创建对象
-
当一个类定义完成之后,要使用这个类来创建对象,语法是
对象变量 = 类名()
-
-
引用
- 在面向对象开发中,引用的概念是同样适用的
- 在Python中使用类创建对象之后,对象变量中仍然记录的是对象在内存中的地址,也就是对象变量引用了新建的对象
- 使用print输出对象变量,默认情况下,能够输出这个变量引用的对象是由哪一个类创建的对象,以及在内存中的地址(十六进制表示)
- %d 可以以十进制输出数字
- %x 可以以十六进制输出数字
-
self
- 哪一个对象调用的方法,self 就是哪一个对象的引用
- 在类封装的方法内部,self 就表示当前调用方法的对象自己
- 调用方法时,不需要传递 self 参数,在方法内部,可以通过 self. 访问对象的属性或者调用其他的对象方法
初始化方法
-
在日常开发中,不推荐在类的外部给对象增加属性,对象应该包含哪些属性,应该封装在类的内部
-
初始化方法
- 当使用 类名() 创建对象时,会自动执行以下操作:
- 为对象在内存中分配空间——创建对象
- 为对象的属性设置初始值——初始化方法(init)
- 这个初始化方法就是 __init__ 方法,__init__ 是对象的内置方法,专门用来定义一个类具有哪些属性的方法
- 当使用 类名() 创建对象时,会自动执行以下操作:
-
在初始化方法内部定义属性
- 在 __init__ 方法内部使用 self.属性名 = 属性的初始值 就可以定义属性
- 定义属性之后,在使用类创建的对象,就会拥有该属性
-
初始化的同时设置初始值
-
在开发中,如果希望在创建对象的同时,就设置对象的属性,可以对 __init__ 方法进行改造
-
把希望设置的属性值,定义成 __init__ 方法的参数
-
在方法内部使用 self.属性 = 形参 接收外部传递的参数
-
在创建对象时,使用 类名(属性1, 属性2…) 调用
class Cat : def __init__(self, name) : self.name = name tom = Cat("Tom") lazy_cat = Cat("大懒猫")
-
封装
-
定义
- 封装是面向对象编程的一大特点
- 面向对象编程的第一步——将属性和方法封装到一个抽象的类中
- 外界使用类创建对象,然后让对象调用方法
- 对象方法的细节都被封装在类的内部
-
小明爱跑步
-
需求
- 小明体重75公斤
- 每次跑步会减肥0.5公斤
- 每次吃东西会增加1公斤
-
代码
class Person : def __init__(self, name, weight) : self.name = name self.weight = weight print("大家好,我叫 %s ,我的体重是:%.2f 公斤" % (name, weight)) def run(self) : self.weight -= 0.5 print("跑步好累!") def eat(self) : self.weight += 1 print("吃东西好快乐!") def __str__(self) : return "我的体重是: %.2f 公斤" % self.weight xiaoming = Person("小明", 75) xiaoming.run() print(xiaoming) xiaoming.eat() print(xiaoming) xiaomei = Person("小美", 45) xiaomei.run() print(xiaomei) xiaomei.eat() print(xiaomei) -
在对象的方法内部,可以直接访问对象的属性
-
同一个类创建的多个对象之间,属性互不干扰
-
-
摆放家具
-
需求
- 房子有户型、总面积和家具名称列表,新房子没有任何家具
- 家具有名字和占地面积,其中席梦思占地4平米、衣柜占地2平米、餐桌占地1.5平米
- 将以上三件家具添加到房子中
- 打印房子时,要求输出户型、总面积、剩余面积、家具名称列表
- 在创建房子对象时,定义一个剩余面积的属性,初始值和总面积相等
- 当调用add_item方法,向房间添加家具时,让剩余面积 -= 家具面积
-
代码
class HouseItem : def __init__(self, name, area): self.name = name self.area = area def __str__(self): return "[%s] 占地 %.2f 平米" % (self.name, self.area) class House : def __init__(self, house_type, area): self.house_type = house_type self.area = area self.free_area = area self.item_list = [] def __str__(self): return "该房子的户型是 %s,总面积是:%.2f 平米,目前剩余面积是:%.2f 平米,家具有:%s" \ % (self.house_type, self.area, self.free_area, self.item_list) def add_item(self, item): # 判断家具面积 if item.area > self.free_area : print("%s 的面积太大,无法添加!" % item.name) return self.item_list.append(item.name) self.free_area -= item.area # 创建家具 bed = HouseItem("席梦思", 30) chest = HouseItem("衣柜", 20) table = HouseItem("餐桌", 15) TV = HouseItem("电视", 100) # 创建房子对象 my_home = House("三室一厅", 120) # 添加家具 my_home.add_item(bed) my_home.add_item(chest) my_home.add_item(table) my_home.add_item(TV) print(my_home)
-
-
士兵突击
-
需求
- 士兵许三多有一把AK47
- 士兵可以开火
- 枪能够发射子弹
- 枪装填子弹——增加子弹数量
-
在定义属性时,如果不知道设置什么初始值,可以设置为 None,None关键字表示什么都没有,表示一个空对象,没有方法和属性,是一个特殊的常量,可以将None赋值给任何一个变量
-
代码
class Gun : def __init__(self, model): self.model = model self.bullet_count = 0 def __str__(self): return "%s,共有 %d 颗子弹" % (self.model, self.bullet_count) def add_bullet(self, bullet_count): self.bullet_count += bullet_count print("装填了 %d 颗子弹" % bullet_count) def shoot(self): if self.bullet_count <= 0: print("子弹不足,请装弹") return self.bullet_count -= 3 print("突突突......目前还剩 %d 颗子弹" % self.bullet_count) class Soldier: def __init__(self,name): self.name = name # 每个新兵都没有枪 self.gun = None def __str__(self): return "我是士兵 %s,我的武器是 %s" % (self.name, self.gun) def fire(self): if self.gun is None : print("%s 还没有枪...." % self.name) return self.gun.add_bullet(100) self.gun.shoot() # 创建枪对象 ak47 = Gun("AK47") # 创建士兵 xsd = Soldier("许三多") xsd.gun = ak47 xsd.fire()
-
-
身份运算符
-
身份运算符用于比较两个对象的内存地址是否一致——是否是对同一个对象的引用
-
在Python中针对None比较时,建议使用 is 判断
运算符 描述 实例 is is是判断两个标识符是不是引用同一个对象 x is y,类似于id(x) == id(y) is not is not是判断两个标识符是不是引用不同对象 x is not y,类似于id(x) != id(y) -
is 与 == 区别
- is 用于判断两个变量引用对象是否为同一个
- == 用于判断引用变量的值是否相等
-
私有属性和私有方法
- 应用场景
- 在实际开发中,对象的某些属性或方法可能只希望在对象的内部被使用,而不希望在外部被访问到
- 私有属性就是对象不希望公开的属性
- 私有方法就是对象不希望公开的方法
- 定义方法
- 在定义属性或方法时,在属性名或者方法名前增加两个下划线,定义的就是私有属性或方法
- Python中,并没有真正意义的私有
- 在给属性、方法命名时,实际上对名称做了一些特殊处理,使得外界无法访问到
- 处理方式:在名称前面加上 _类名,即 _类名__名称
- 在日常开发中,不要使用这种方式,访问对象的私有属性或私有方法
继承
-
面向对象三大特性
- 封装:根据职责将属性和方法封装到一个抽象的类中
- 继承:实现代码的重用,相同的代码不需要重复的编写
- 多态:不同的对象调用相同的方法,产生不同的执行结果,增加代码的灵活度
-
单继承
-
继承的概念:子类拥有父类的所有方法和属性
-
继承的语法
class 类名(父类名): pass -
子类继承自父类,可以直接享受父类中已经封装好的方法,不需要再次开发。子类中应该根据职责,封装子类特有的属性和方法
-
代码
class Animal: def eat(self): print("吃东西") def drink(self): print("喝东西") class Dog(Animal): def bark(self): print("汪汪叫") dog = Dog() dog.eat() dog.drink() dog.bark() -
Dog类是Animal类的派生类(子类),Animal类是Dog类的基类(父类),Dog类从Animal类派生(继承)
-
-
继承的传递性
- 子类拥有父类以及父类的父类中封装的所有属性和方法
-
方法的重写
-
当父类的方法实现不能满足子类需求时,可以对方法进行重写(override)
-
重写父类方法有两种情况
- 覆盖父类的方法:在子类中定义一个和父类同名的方法并且实现
- 对父类方法进行扩展:在需要的位置使用 super().父类方法 来调用父类方法的执行,代码其他的位置针对子类的需求,编写子类特有的代码实现
-
super
-
在Python中 super 是一个特殊的类,super()就是使用super类创建出来的对象
-
最常使用的场景就是在重写父类方法时,调用在父类中封装的方法实现
class Animal: def eat(self): print("吃东西") def drink(self): print("喝东西") class Dog(Animal): def bark(self): print("汪汪叫") class XiaoTianQuan(Dog): def bark(self): print("神犬") super().bark() xtq = XiaoTianQuan() xtq.bark()
-
-
-
父类的私有属性和私有方法
- 子类对象不能在自己的方法内部,直接访问父类的私有属性或私有方法
- 子类对象可以通过父类的公有方法间接访问到私有属性或私有方法
-
多继承
-
子类可以拥有多个父类,并且具有所有父类的属性和方法
-
语法
class 子类名(父类名1, 父类名2...): pass -
如果父类之间存在同名的属性或者方法,应该尽量避免使用多继承
-
MRO——方法搜索顺序
- Python中针对类提供了一个内置属性 __mro__ 可以查看方法搜索顺序。MRO是method resolution order,主要用于在多继承时判断方法、属性的调用路径
- print(C.__mro__)
- 在搜索方法时,是按照 __mro__ 的输出结果从左至右的顺序查找的。如果在当前类中找到方法,就直接执行,不再搜索;如果没有找到,就查找下一个类中是否有对应的方法,最终都没有找到,程序报错
-
新式类与经典类
- object是Python为所有对象提供的基类,提供有一些内置的属性和方法,可以使用dir函数查看
- 新式类:以object为基类的类,推荐使用
- 经典类:不以object为基类的类,不推荐使用
- 在Python 3.x中定义类时,如果没有指定父类,会默认使用object作为该类的基类——新式类
-
多态
- 多态:不同的子类对象调用相同的父类方法,产生不同的执行结果
- 多态可以增加代码的灵活度
- 以继承和重写父类方法为前提
- 是调用方法的技巧,不会影响到类的内部设计
类的结构
-
实例
- 对象创建后,内存中就有了一个对象的实实在在的存在——实例
- 通常,创建出来的对象叫做类的实例,创建对象的动作叫做实例化,对象的属性叫做实例属性,对象调用的方法叫做实例方法
-
类是一个特殊的对象
- class AAA: 定义的类属于类对象,obj1 = AAA() 属于实例对象
- 类是一个特殊的对象——类对象。除了封装实例的属性和方法外,类对象还可以拥有自己的属性(类属性)和方法(类方法)。通过 类名. 的方式可以访问类的属性或者调用类的方法
- 在程序运行时,类同样会被加载到内存,类对象在内存中只有一份,使用一个类可以创建出很多个对象实例
-
类属性
-
类属性就是给类对象中定义的属性,通常用来记录与这个类相关的特征,类属性不会用于记录具体对象的特征
-
代码
class Tool: # 类属性 count = 0 def __init__(self, name): self.name = name Tool.count += 1 t1 = Tool("斧头") t2 = Tool("扳手") t3 = Tool("剪刀") print(Tool.count) -
属性获取机制
- 在Python中属性的获取存在一个向上查找机制
-
访问类属性的方式
- 类名.类属性
- 对象.类属性(不推荐):如果使用 对象.类属性 = 值 赋值语句,只会给对象添加一个属性,而不会影响到类属性的值
-
-
类方法
-
类方法就是针对类对象定义的方法,在类方法内部可以直接访问类属性或者调用其他的类方法
-
语法
@classmethod def 类方法名(cls): pass -
类方法需要用 修饰器**@classmethod** 来标识,告诉解释器这是一个类方法,类方法的第一个参数应该是 cls。由哪一个类调用的方法,方法内的cls就是哪一个类的引用,这个参数和实例方法的第一个参数self类似
-
通过 类名. 调用类方法,调用方法时,不需要传递cls参数
-
在方法内部,可以通过 cls. 访问类的属性,也可以通过 cls. 调用其他的类方法
-
-
静态方法
-
在开发时,如果需要在类中封装一个方法,这个方法既不需要访问实例属性或者调用实例方法,也不需要访问类属性或者调用类方法,这个时候,就可以把这个方法封装成一个静态方法
-
语法
@staticmethod def 静态方法名(): pass -
静态方法需要用 修饰器@staticmethod 来标识,告诉解释器这是一个静态方法,通过 类名. 调用静态方法
-
-
综合案例
-
设计一个 Game 类
-
属性
- 定义一个类属性 top_score 记录游戏的历史最高分
- 定义一个实例属性 player_name 记录当前游戏的玩家姓名
-
方法
- 静态方法 show_help 显示游戏帮助信息
- 类方法 show_top_score 显示历史最高分
- 实例方法 start_game 开始当前玩家的游戏
-
主程序步骤
- 查看帮助信息
- 查看历史最高分
- 创建游戏对象,开始游戏
-
代码
class Game: top_score = 0 def __init__(self, name): self.player_name = name @staticmethod def show_help(): print("这是帮助信息") @classmethod def show_top_score(cls): print("当前最高分是:%.2f" % cls.top_score) def start_game(self): print("%s 开始游戏了" % self.player_name) # 查看帮助信息 Game.show_help() # 查看历史最高分 Game.show_top_score() # 创建游戏对象 game = Game("小明") game.start_game()
-
单例
- 单例设计模式
- 设计模式是前人工作的总结和提炼,通常,被人们广泛流传的设计模式都是针对某一特定问题的成熟的解决方案,使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性
- 单例设计模式的目的:让类创建的对象,在系统中只有唯一的一个实例,每一次执行 类名() 返回的对象,内存地址是相同的
- __new__ 方法
- 使用 类名() 创建对象时,Python的解释器首先会调用 __new__ 方法为对象分配空间。__new__ 是一个有object基类提供的内置的静态方法,主要作用有两个:
- 在内存中为对象分配空间
- 返回对象的引用
- 重写 __new__ 方法一定要 return super().__new__(cls) ,否则Python的解释器得不到分配了空间的对象引用,就不会调用对象的初始化方法
- __new__ 是一个静态方法,在调用时需要主动传递cls参数
- 使用 类名() 创建对象时,Python的解释器首先会调用 __new__ 方法为对象分配空间。__new__ 是一个有object基类提供的内置的静态方法,主要作用有两个:
- Python中的单例
- 定义一个类属性,初始值是None,用于记录单例对象的引用
- 重写 __new__ 方法
- 如果类属性 is None,调用父类方法分配空间,并在类属性中记录结果
- 返回类属性中记录的对象引用
异常
-
概念
- 程序在运行时,如果Python解释器遇到一个错误,会停止程序的执行,并且提示一些错误信息,这个就是异常
- 程序停止执行并且提示错误信息这个动作,我们通常称之为:抛出(raise)异常
- 程序开发时,很难将所有的特殊情况都处理的面面俱到,通过异常捕获可以针对突发事件做集中的处理,从而保证程序的稳定性和健壮性
-
捕获异常
-
在程序开发中,如果对某些代码的执行不能确定是否正确,可以增加 try 来捕获异常
-
语法格式
try: 尝试执行的代码 except: 出现错误的处理 -
try 尝试,下方编写要尝试代码,不确定是否能够正常执行的代码
-
except 如果不是,下方编写尝试失败的代码
-
-
错误类型捕获
-
在程序执行时,可能会遇到不同类型的异常,并且需要针对不同类型的异常,做出不同的响应,这个时候,就需要捕获错误类型了
-
语法
try: pass except 错误类型1: pass except (错误类型2, 错误类型3): pass except Exception as result: print("未知错误%s" % result) -
当Python解释器抛出异常时,最后一行错误信息的第一个单词,就是错误类型
-
捕获未知错误
except Exception as result: print("未知错误%s" % result) -
异常捕获完整语法
try: pass except 错误类型1: pass except (错误类型2, 错误类型3): pass except Exception as result: print("未知错误%s" % result) else: pass finally: print("无论是否有异常,都会执行的代码") -
else 只有在没有异常时才会执行的代码
-
finally 无论是否有异常,都会执行的代码
-
-
异常的传递
- 当函数 / 方法执行出现异常,会将异常传递给函数 / 方法的调用一方,如果传递到主程序,仍然没有异常处理,程序才会被终止
- 在开发中,可以在主函数中增加异常捕获,而在主函数中调用其他的函数,只要出现异常,都会传递到主函数的异常捕获中,这样就不需要在代码中,增加大量的异常捕获,能够保证代码的整洁
-
抛出异常
-
Python中提供了一个 Exception 异常类,在开发时,如果满足特定业务需求时,希望抛出异常,可以:
- 创建一个Exception的对象
- 使用 raise 关键字抛出异常对象
ex = Exception("异常信息") raise ex
-
模块
-
模块的概念
- 模块是Python程序架构的一个核心概念,每一个以扩展名 py 结尾的Python源代码文件都是一个模块,模块名同样也是一个标识符,需要符合标识符的命名规则
- 在模块中定义的全局变量、函数、类都是提供给外界直接使用的工具,模块就好比是工具包,要想使用这个工具包中的工具,就需要先导入这个模块
-
模块的两种导入方式
-
import 导入
import 模块名1 import 模块名2-
在导入模块时,每个导入应该独占一行
-
导入之后,通过 模块名. 使用模块提供的工具——全局变量、函数、类
-
如果模块的名字太长,可以使用 as 指定模块的名称,以方便在代码中的使用,模块别名应该符合大驼峰命名法
import 模块名1 as 模块别名
-
-
from…import导入
-
如果希望从某一个模块中,导入部分工具,就可以使用from…import的方式,import 模块名是一次性把模块中所有工具全部导入,并且通过模块名 / 别名访问
from 模块名1 import 工具名 -
导入之后,不需要通过 模块名. ,可以直接使用模块提供的工具,如果两个模块,存在同名的函数,那么后导入模块的函数,会覆盖掉先导入的函数
-
-
from…import *
- 从模块导入所有工具
- 这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查
-
-
模块的搜索顺序
- Python的解释器在导入模块时,会搜索当前目录指定模块名的文件,如果有就直接导入,如果没有,在搜索系统目录
- 在开发时,给文件起名,不要和系统的模块文件重名
- Python中每一个模块都有一个内置属性 __file__ 可以查看模块
-
开发原则
-
在导入文件时,文件中所有没有任何缩进的代码,都会被执行一遍
-
__name__ 属性可以实现测试模块的代码只在测试情况下被运行,而在被导入时不会被执行
-
__name__ 是Python的一个内置属性,记录着一个字符串,如果是被其他文件导入的,__name__ 就是模块名;如果是当前执行的程序,__name__ 是 __main__
if __name__ == "__main__" : 测试代码
-
-
包(Package)
-
包是一个包含多个模块的特殊目录,目录下有一个特殊的文件 __init__.py,包名的命名方式和变量名一致,小写字母+_
-
使用import 包名可以一次性导入包中所有的模块
-
__init__.py
-
要在外界使用包中的模块,需要在 __init__.py 中指定对外界提供的模块列表
from . import send_message from . import receive_message
-
-
-
pip 安装第三方模块
-
pip 是一个现代的、通用的Python包管理工具,提供了对Python包的查找、下载、安装、卸载等功能
-
安装和卸载命令
# 安装到Python 2.x环境 sudo pip install 模块名 sudo pip uninstall 模块名 # 安装到Python 3.x环境 sudo pip3 install 模块名 sudo pip3 uninstall 模块名
-
文件
-
基础知识
- 计算机的文件,就是存储在某种长期储存设备上的一段数据
- 长期储存设备包括:硬盘、U盘、移动硬盘、光盘
- 文件的作用就是将数据长期保存下来,在需要的时候使用
- 在计算机中,文件是以二进制的方式保存在磁盘上的
-
操作文件的函数 / 方法
-
在Python中要操作文件需要记住1个函数3个方法
函数 / 方法 说明 open 打开文件,并且返回文件操作对象 read 将文件内容读取到内存 write 将指定内容写入文件 close 关闭文件 -
open函数负责打开文件,并且返回文件对象
-
其他三个方法都需要通过文件对象来调用
-
-
read方法——读取文件
-
open函数的第一个参数是要打开的文件名(文件名区分大小写),如果文件存在,返回文件操作对象;如果文件不存在,会抛出异常
-
read方法可以一次性读入并返回文件的所有内容,close方法负责关闭文件。如果忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问
-
方法执行后,会把文件指针移动到文件的末尾
# 打开文件 file = open("文件名的位置") # 读取 text = file.read() print(text) # 关闭 file.close() -
在开发中,通常会先编写打开和关闭的代码,在编写中间针对文件的读 / 写操作
-
-
文件指针
- 文件指针标记从哪个位置开始读取数据,第一次打开文件时,通常文件指针会指向文件的开始位置,当执行了read方法后,文件指针会移动到读取内容的末尾
- 如果执行了一次read方法,读取了所有内容,那么再次调用read方法,就不能够获得到内容了
-
打开文件的方式
-
open函数默认以只读方式打开文件,并且返回文件对象
f = open("文件名", "访问方式")访问方式 说明 r 以只读方式打开文件,文件的指针将会放在文件开头,这是默认模式。如果文件不存在,抛出异常 w 以只写方式打开文件,如果文件存在会被覆盖,如果文件不存在,创建新文件 a 以追加方式打开文件,如果文件已存在,文件指针将会放在文件的结尾,如果文件不存在,创建新文件进行写入 r+ 以读写方式打开文件,文件的指针将会放在文件的开头,如果文件不存在,抛出异常 w+ 以读写方式打开文件,如果文件存在会被覆盖,如果文件不存在,创建新文件 a+ 以读写方式打开文件,如果文件存在,文件指针将会放在文件的结尾,如果文件不存在,创建新文件进行写入 -
频繁的移动文件指针,会影响文件的读写效率,开发中更多的时候会以只读、只写的方式来操作文件
-
read方法默认会把文件的所有内容一次性读取到内存,如果文件太大,对内存的占用会非常严重
-
readline方法可以一次读取一行内容,方法执行后,会把文件指针移动到下一行,准备再次读取
-
-
文件 / 目录的常用管理操作
-
在Python中,如果希望通过程序实现文件 / 目录管理操作,需要导入 os 模块
-
文件操作
方法名 说明 示例 rename 重命名文件 os.rename(源文件名, 目标文件名) remove 删除文件 os.remove(文件名) -
目录操作
方法名 说明 示例 listdir 目录列表 os.listdir(目录名) mkdir 创建目录 os.mkdir(目录名) rmdir 删除目录 os.rmdir(目录名) getcwd 获取当前目录 os.getcwd() chdir 修改工作目录 os.chdir(目标目录) path.isdir 判断是否是文件 os.path.isdir(文件路径) -
文件或者目录操作都支持相对路径和绝对路径
-
eval函数
-
eval函数十分强大——将字符串当成有效的表达式来求值并返回计算结果
# 基本的数学计算 eval("1 + 1") # 输出2 # 字符串重复 eval("'*' * 50") -
在开发时,千万不要使用 eval 直接转换input的结果