1引言
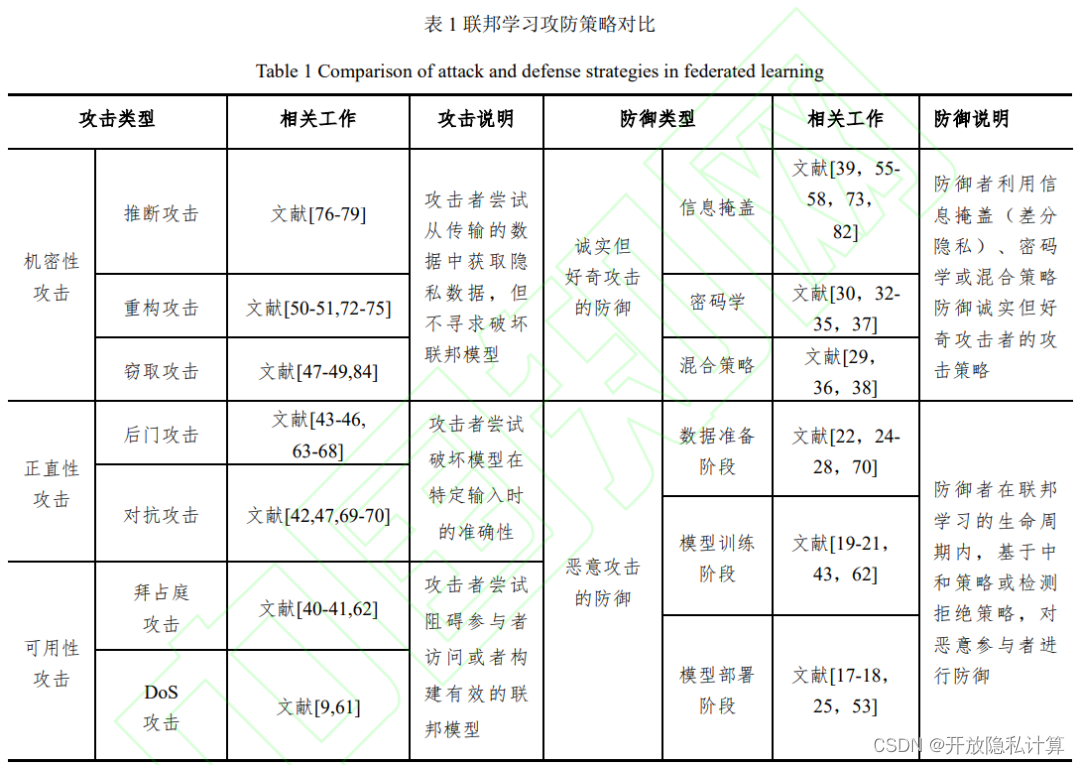
联邦学习旨在利用去中 心化的数据源训练一个中心化的联邦模型,并且 在训练的过程中保证原始数据的隐私安全。 联邦学习仍面临四个挑战:高昂的通信成本、系统异质性、数据异质性以及数据安全。联邦学习面临的主要攻击包括机密性攻击、正直性攻击和可用性攻击。诚实但好奇攻击者主要针对机密性攻击,而恶意攻击者则针对正直性攻击和可用性攻击 。本文从机密性、正直性和可用性 3 种攻击性质出发,重点介绍了联邦学习在建模过程中可能出现的攻击行为,同时从诚实但好奇和恶意两个角度归纳了不同防御策略的优点与缺点, 攻防策略的对比如表 1 所列。
2联邦学习攻防的基础知识
2.1 联邦学习
本文主要针对横向联邦学习。联邦学习 中,参与者的共同目标为,在保证原始数据不出 库的前提下,协同地训练一个联合模型。联合模型的参数用 w 表示,联邦学习的训练目标可以被定义为一个优化问题:
在训练的过程中,每个参与者基于本地数据 维护一个本地模型 ,而服务器则利用各种可能的聚合规则对本地模型进行聚合并得到全局模型。 联邦学习的整体流程图如下:
2.2 攻击模型
攻击面
联邦学习中,攻击者的攻击面如下:
(1) 攻击者可以操纵原始数据收据和预处理,完成正直性攻击。
(2) 攻击者可以操纵本地模型训练,完成 正直性攻击和可用性攻击。
(3) 攻击者可以分析传递的模型参数,完成 机密性攻击。
(4) 攻击者可以干预模型参数聚合,完成正 直性和可用性攻击。
(5) 攻击者可以通过 API 接口,窃取模型的 具体参数,破坏机密性。
攻击能力
本文根据攻击者的方向,将攻击类型划分为 3 类。
(1) 机密性攻击,攻击者尝试从传递的数据 中推断隐私信息。
(2) 正直性攻击,攻击者尝试破坏联邦模型 在特定输入上的功能,而保证其在遇到其他输入 时正常输出。
(3) 可用性攻击,攻击者尝试阻碍正常参与 者构建或者访问一个有效联邦模型。
2.3 防御技术
差分隐私
如图 2 所示,考虑两个只相差一个样本的相邻数据集 #1 和 #2 ,差分隐私通过 向模型的输出上加入噪声,来使攻击者无法根据 输出结果从统计学上严格地区分两个数据集。差分隐私并不保护整体数据集的隐私安全,而是通过噪声机制对数据集中的每个个体的隐私数据进行保护。
密码学策略
联邦学习中应用 的密码学策略主要包括混淆电路、不经意传 输、秘密分享以及同态加密,下面对这 4 种策略进行简单介绍。
(1) 混淆电路是一种加密协议。根据该协 议,两个参与方可以在不知道对方数据的前提下 实现某个函数的计算。在混淆电路中,目标函数被转换成布尔电路。
(2) 不经意传输中存在两个角色,即发送方 和接收方。发送方拥有一对消息 , 而 接 收 方 拥 有 一 个 位 数 据 。当执行完不经意传输后,接收方得 到 b 对应的消息 ,而发送方不知道 b 的 值。
(3) 秘密分享允许用户将秘密信息划分成 m 份,并将它们分发给一组参与者。只有当所有的 m 份信息被聚合在一起,原始的秘密信息才可以被推导出来。
(4) 同态加密允许使用者基于密文进行基础 运算,而不用对密文解密。
3联邦学习中的攻击策略
3.1 机密性攻击
推断攻击
Shokri 等最先提出成员推断攻击,其旨在推断某一样本是否属于训练目标模型的数据集。如图 3 所示,与原始训练集分布相似的影子训练集被用于训练影子模型 ,而对应的预测结果 被标记为“in”。而对于不在原始训练集分布中的 影子测试集,也会被影子模型分类,并且对应的预测结果被标记为“out”。 这些“in”数据和 “out”数据被收集,用于 训练一个二分类攻击模型,以判断某一样本是否存在于原始数据集中。
重构攻击
重构攻击旨在利用联邦学习建 模过程中传递的模型信息重构出原始数据。 Zhu 等[73]提出了一种新的重构攻击策 略,并将它命名为梯度的深度泄漏攻击(Deep Leakage from Gradients, DLG),其旨在从传输的 梯度信息中恢复出原始数据 。
虽然 DLG 重构攻击效果显著,但其也存在 一些缺陷,首先它只针对批次数量有限的梯度下 降(上限为 8);其次,它无法处理深层神经网络 模型,如 ResNet[11]。Geiping 等[72]则在 DLG 的 基础上提出了反转梯度攻击。其改进如下:1)利 用余弦相似度替换二范数,将其作为度量两个梯 度更新差异的标准;2)在损失函数上引入全变分 (Total Variation),用于平滑 x ' ;3)利用 Adam[86] 优化器对损失函数进行优化。
模型窃取攻击
Orekondy 等[84]提出了 Knockoff Net。该策略不假 设攻击者拥有目标模型的结构以及对应训练集分 布的先验知识,而攻击者仅利用目标模型 API 输 出的置信值来完成目标模型的窃取。 在 Knockoff 网络的训练过程中,Orekondy 等[84]研究了不同 复杂度的 Knockoff 网络 对窃取效果的影 响,并发现模型复杂度越高模型的窃取效果就越好。
3.2 正直性攻击
后门攻击
后门攻击最初在文献[66-67]中被提出,其旨 在向目标模型中注入后门,当模型遇到可以触发 后门的输入时,模型会输出攻击者设定的输出。本文根据攻击者的攻击能力将后门攻击划分成了 数据毒害攻击和模型毒害攻击。
对抗攻击
对抗攻击则是 利用模型本身的缺陷来构造对抗样本,以欺骗目标模型。Papernot 等[54]假定攻击者拥有对模型的白盒 访问,并将对抗样本的生成过程划分成两部分, 即敏感度方向估计和扰动选择。
3.3 可用性攻击
联邦学习中的可用性攻击表示攻击者尝试破 坏模型收敛性或者访问权限。在联邦学习系统中,联 合模型的有效依赖于参与者和服务器在建模过程 中的诚实行为。这里的诚实意味着参与者和服务 都会遵守规则并发送正常数据。
拜占庭攻击
拜占庭攻击指要求所有参与者达成共识的分 布式系统包含一些不可靠参与者的情况。 在 Blanchard 等[62]的工作中,他们假 设恶意参与者通过向服务器发送任意消息来发起 攻击。当服务器采用 FedAvg[81]等简单的线性聚 合策略时,目标模型很容易被攻击者劫持。恶意 参与者除了通过发送任意数据发起拜占庭攻击 外,还可以根据本地模型编造特定的传输数据来 破坏目标模型。
拒绝服务攻击
拒绝服务攻击(DoS 攻击)是一种破坏服务提供者正常功能并阻止其他用户访问的攻击。 分布式拒绝服务攻击(Distributed DoS, DDoS) 指来自多个来源的虚假流量使得在线服务不可 用。而在联邦系统中,参与者可以自由地加入和 退出,这使得攻击者可以轻松地控制多个参与者 发起 DDoS 攻击。
4联邦学习中的防御策略
4.1 针对诚实但好奇攻击者的防御
信息掩盖
联邦学习中的参与者需要通过服务器交互一 些重要模型信息(如梯度或者权重)来构建联合模 型。而机密性攻击已经被证明可以从这些模型信 息中恢复原始数据。为了防御这类攻击,直接的 想法是尽可能地对传递的信息进行掩盖。差分隐私被利用到这一类防御策略中。联邦学习中不同水平的差分隐私保护如图 12 所示 。其中表示第 k 位参与者在第 t 轮上 传的模型参数, 表示第 k 位参与者的第 i 个 样本。
密码学方法
对于基础的FedAvg[81]聚合算法而言,服务器只需要对上传的模型参数进行加权相加。这种简单的聚合规则使得同态加密算法可以被应用到联邦学习的隐私保护中。在基于同态加密的保护机制中,每个参与者加密并上传对应的密文,服务器收集并直接对密文进行运算。而在多方安全计算框架中,参与者 协同地通过一些密码学技术来完成特定函数的计算。
混合策略
Hao等[37]在基于同步随机梯度下降的优化算 法中,将加法同态加密和差分隐私相结合,构建了一个高效安全的联邦深度学习系统。Xu等[38]认为健壮且隐私安全的联邦系统需要满足 3 个要素:严格的隐私保证、针对参与者 掉队的应对机制以及高效的通信计算。为了满足这些条件,他们提出了一种名为 HybridAlpha 的 联邦计算框架,如图 13 所示。
4.2 针对恶意攻击者的防御
本节根据联邦学习的生命周 期,将针对恶意攻击者的防御策略划分成 3 部分:1)数据准备阶段的防御;2)模型训练阶段的 防御;3)模型部署阶段的防御。
数据准备阶段的防御
对抗训练最早在文献[28,70]中被提出,其 旨在向训练集中添加对抗样本,以增加目标模型 的鲁棒性。 另外一种 防御对抗攻击的策略是,对输入数据进行变换处 理。Dziugaite 等[27]利用 JPG 压缩技术消除输入 图片的对抗扰动。 而针对数据毒害的后门攻击,由于毒害样本 和正常样本的差异性,最直观的防御策略就是检 测并拒绝有毒的输入样本。Liu 等[25]利用异常检 测算法(支持向量机和决策树)对有毒样本进行检 测并拒绝识别。 除了对有毒样本进行检测拒绝的防御策略 外,还可以利用有毒样本和正常样本之间的分布 差异性,对样本进行重构或直接消除其中的有毒 部分。
模型训练阶段的防御
在联邦模型训练过程中,无论是拜占庭攻击 还是后门攻击,为了破坏联邦模型的正直性或可 用性,攻击者都会发送与正常参与者统计分布不 一致的数据,而这种不一致性就可以被用来设计 防御策略。Bhagoji 等[43]提出了联邦学习中检测异常 参与者的两个标准:1)模型在验证集上的预测性 能;2)传输数据的模型信息。对于第一个标准, 服务器利用验证集检测第 k 个参与者在第 t 轮的 本地模型 ,如果第 k 个参与者的本地模型在 验证集上的表现远差于其余模型聚合后的结果, 那么该参与者将被标注为恶意参与者。而对于第 二个标准,他们计算第 k 个本地模型与剩余模型 之间的距离,并认为这些距离的范围表明了该模 型与其他模型的差异。
模型部署阶段的防御
当联邦模型收敛后,无论是将其作为全局模 型分发给参与者,还是以 API 接口开放给外部使 用者,模型内部存在的缺陷都会对其可用性和正 直性造成威胁。Wang 等[53]提出了一种名为 Neural Cleanse 的新技术,用于检测和删除嵌入在神经网络中的 后门触发器。他们将防御策略划分为 3 部分:1) 检测后门的存在;2)构建后门的触发模式;3)移 除目标模型中的后门。除了对后门触发器进行检测清除外,另外一 种思路是对目标模型进行微调(fine-tuning)或重 构。Liu 等[18]利用正常样本对目标模型进行进一 步的训练 ,以迫使其“ 忘记 ”后门触发器。
5未来展望
(1)攻击能力的约束。在一个 攻击策略中,针对攻击者过多攻击能力的假设,会导致该攻击策略过于特殊而无法被应用到更多的场景。因此,在攻击策略的设计上,未来的发展方向会是在危害联邦系统 的前提下,尽可能地约束攻击者的攻击能力并隐 藏自身的攻击行为。
(2)相互适应的防御策略。 如何和谐地结合多种防御机制(如将异常检测纳入多方安全计算框架中)是一个重要的方向。
(3)隐私、通信和计算的平衡。 考虑到单一防御策略的局限性,越来越多的 工作[36-38]尝试将多种防御策略集成起来,但如何 平衡联邦系统中计算、通信、模型性能和隐私安 全依然是未来研究的重点。
(4)向善的技术应用。
译者简介:
庄智廉:重庆大学大数据与软件学院一年级研究生。主要研究兴趣包括隐私保护机器学习、联邦学习。语雀:阿柴,知平:acai
关注 开放隐私计算公众号就,了解更多内容。