摘要
- 基本介绍深度学习、强化学习;
- 介绍深度强化学习流行算法;
- 深度强化学习在机器人操作领域的应用现状;
- 未来的发展方向作出总结与展望;
关键词
- 深度学习;
- 强化学习;
- 机器人操作;
- 深度强化学习;
- 机器人学习;
1 引言
传统机器人难题:机器人不具备处理未知环境的能力;开发时间长;专业技能需求高;仅能完成固定工作且不能泛化到新任务。
深度强化学习(deep reinforcement learning,DRL)将深度学习的感知能力和强化学习的决策能力相结合,可以直接根据输入信息控制机器人的行为,赋予了机器人接近人类的思维方式,是机器人获得操作技能非常重要的方法。
机器人技能学习是使机器人通过交互数据,从行为轨迹中自主获取和优化技能,并应用于类似的任务。
RL 应用于机器人操作行为的研究存在数据特征提取困难和机器人缺乏感知能力等问题。
2 概念和术语
2.1 深度学习
深度学习侧重于对事物的感知和表达,其核心思想是通过多层网络结构和非线性变换,将低层次数据特征映射为易于处理的高层次表示,以发现数据之间的联系和特征表示。
深度学习的模型主要有深度信念网络(deep belief network)、卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network)等。
| 学者 | 工作 |
|---|---|
| Krizhevsky等 | 提出 AlexNet 深度卷积神经网络,该网络引入了全新的深层结构,并采取随机丢弃部分隐藏神经元的方法抑制过拟合现象 |
| Simonyan等 | 通过增加网络层数,提出了 VGG-Net 模型,图像识别准确率进一步提升 |
| Lin等 | 通过增加卷积模块,利用多层感知卷积层提取图像特征,大大降低了图像识别错误率 |
深度学习方法应用到机器人操作困难:状态估计中存在噪声干扰、奖励函数难以确定、连续行为空间难以处理等。
基于深度学习训练的机器人模型不具备行为决策能力和对未知环境的适应能力
2.2 强化学习
2.2.1 强化学习算法原理
行为策略函数是智能体的行为准则,其本质是映射,将环境状态集合 S S S 映射到行为集合 A A A 的概率分布函数或者概率密度函数,指导智能体选择最佳行为。
2.2.2 强化学习算法分类
1. 无模型(model-free)算法和基于模型(model-based)的算法
无模型强化学习算法是智能体通过与环境交互产生的样本数据,直接优化动作,而不是拟合模型。
- 无模型算法在样本数据收集方面非常昂贵;
- 无模型算法对超参数(比如学习率)非常敏感;
基于模型的强化学习算法是智能体根据其与环境交互产生的数据,训练并拟合模型,然后智能体基于模型优化行为准则。在基于模型的算法中,智能体可以推断未知的环境状态,提前计算状态转移概率和未来期望奖励,提高了样本效率。
对未知的、复杂的动态环境难以精确地建模。
基于深度强化学习,机器人操作行为研究多采用无模型强化学习方法。
2. 基于价值(value-based)的算法和基于策略(policy-based)的算法
基于价值的算法计算所有可能的动作值,但只选取价值最大的动作。但是,该算法计算量大,存在振荡不收敛现象,而且难以解决连续动作空间的问题。
基于策略的算法中,智能体直接输出下一时刻可能动作的概率,然后根据概率选择行为。该算法将策略参数化,将累积回报的期望值作为目标函数,并通过梯度策略法求解目标函数的最优解。目标函数定义如下。
J ( θ ) = E ( G t ∣ π θ ) J(\theta) = E(G_{t}|\pi_{\theta}) J(θ)=E(Gt∣πθ)
3 深度强化学习
3.1 深度强化学习概述及分类
深度学习通过学习深层的非线性网络结构和数据集的本质特征,实现函数的逼近。智能体在与环境交互的过程中,利用强化学习通过不断试错和最大化累积奖励来生成最优的行为策略。
| 学者 | 工作 | 论文 |
|---|---|---|
| DeepMind | 将深度强化学习算法应用到连续动作领域,比如机器人操作和运动 | Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[DB/OL]. (2017-08-16) [2021-04-02].https://arxiv.org/abs/1509.02971. |
| Heess | 基于分布式近端策略优化算法,使用前向传播的简单奖励函数,在多种具有挑战性的地形和障碍物上,成功训练了多个虚拟人物完成跑酷任务 | Heess N, TB D, Sriram S, et al. Emergence of locomotion behaviours in rich environments[DB/OL]. (2019-07-05) [2021-04-02]. https://arxiv.org/abs/1707.02286. |
| OpenAI | 提出了新型的近端策略优化算法,成功训练多腿机器人相互玩游戏,并指导机器人不断适应彼此策略中的增量变化 | (1)Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[DB/OL]. (2017-08-28) [2021-04-02]. https://arxiv.org/abs/1707.06347. (2)Al-Shedivat M, Bansal T, Burda Y, et al. Continuous adaptation via meta-learning in nonstationary and competitive environments[DB/OL]. (2018-02-23) [2021-04-02]. https://arxiv.org/abs/1710.03641. |
| 加州大学伯克利分校 | 提出策略搜索算法,该算法迭代拟合局部线性模型以优化连续的动作轨迹,并且训练机器人成功完成了拧瓶盖任务 | (1)Levine S, Abbeel P. Learning neural network policies with guided policy search under unknown dynamics[C]//Advances in Neural Information Processing Systems. La Jolla, USA: Neural Information Processing Systems Foundation, 2014: 1071-1079.(2)Levine S, Finn C, Darrell T, et al. End-to-end training of deep visuomotor policies[J]. The Journal of Machine Learning Research, 2016, 17(1): 1334-1373. |
3.2 典型深度强化学习算法
3.2.1 深度 Q 网络算法
有效地解决了 Q 学习算法计算效率低和数据内存受限的问题。
双网络结构打破了数据之间的相关性,使得 DQN 算法具有更好的泛化性。
经验回放部分储存了智能体历史行为信息,打破了经验池中数据相关性和非静态分布问题。
| 学者 | 模型 | 特点 |
|---|---|---|
| Mnih V, Kavukcuoglu K, Silver D, et al. | DQN | 过度估计,并且产生较大的偏差。 |
| Hasselt | Double DQN(DDQN) | 解决策略过度估计价值问题。解耦动作价值计算和动作选择。 |
| Wang | Dueling DQN | 优化了 DQN 算法结构。将网络分成价值函数和优势函数 2 部分。具有较强的表达能力。 |
| Bellemare | C51 | 直接对价值的分布进行建模,采用 KL 散度(Kullback-Leibler divergence)作为损失函数。对价值的分布进行建模,其优势是提高了学习稳定性,而且近似分布也降低了基于非平稳策略开展学习所造成的影响。 |
| Dabney | QR-DQN | 通过损失函数拟合价值的分位数,进行反向传播计算,其稳定性和精度均优于传统的 DQN 算法。 |
3.2.2 演员―评论家算法
| 模型 | 特点 | |
|---|---|---|
| AC | 演员部分通过探索环境生成动作集合,然后根据动作概率函数选择动作;评论家部分负责评估演员的动作;演员根据评论家的评分优化动作概率函数,最终指导智能体选择最优动作。 | |
| A3C | 训练框架异步化、网络结构优化以及评估点优化等。借鉴DQN 算法的经验回放并利用多线程的方法,使多个智能体同时与环境进行交互,并将智能体的学习数据汇集到公共空间,以使得每个智能体都能从公共空间采样并共享数据,指导自身的策略学习,解决了 AC 算法难以收敛的问题。 | |
| SAC | 当今最有效的无模型算法之一,通过最大熵方法保证算法的稳定性和有效性。演员同时最大化期望和策略分布的熵,并且在选取最优行为的同时保证行为策略的随机性。 |
3.2.3 深度确定性策略梯度算法
1. DDPG
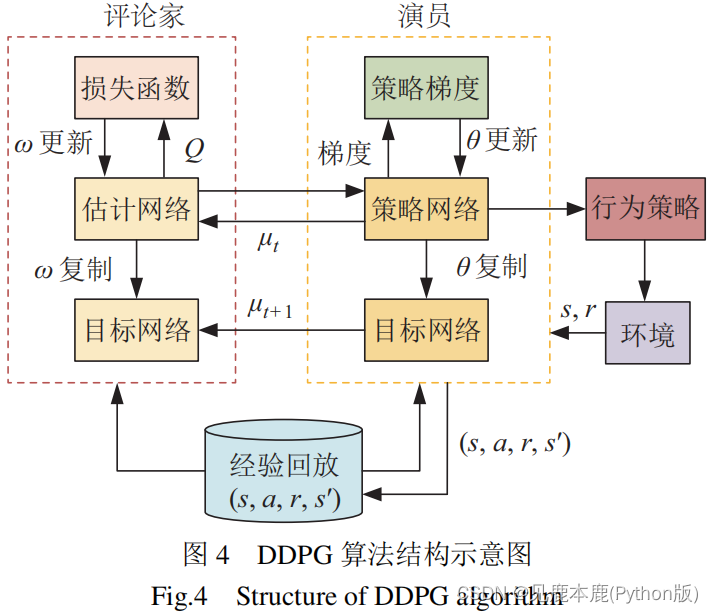
评论家模块采用时序差分误差(temporal difference error,TD-error)的方式更新网络参数 ω \omega ω,并且定期复制 ω \omega ω 到目标网络。演员模块采用 DPG 算法的方式更新网络参数 θ \theta θ,并且行为策略根据其策略网络的输出结果来选择动作作用于环境。
优点:DDPG 算法与 DQN 算法、AC算法相比具有良好的稳定性,而且能够处理连续动作空间任务。
缺点:对超参数的变化很敏感,需要经过长时间的参数微调才能实现较好的算法性能,而且评论家的 Q 函数存在高估 Q 值的问题,会导致行为策略学习不充分,收敛到非最优状态。
Silver D, Lever G, Heess N, et al. Deterministic policy gradient algorithms[J]. Proceedings of Machine Learning Research, 2014, 32(1): 387-395.
2. TD3
- 采用双 Q 网络的方式解决了评论家中 Q 函数高估 Q 值的问题;
- 通过延迟演员的策略更新使得演员的训练更加稳定;
- 利用目标策略平滑化的方法在演员的目标网络计算 Q 值的过程中加入噪声,使网络准确且鲁棒性强。
Fujimoto S, van Hoof H, Meger D. Addressing function approximation error in actor-critic methods[DB/OL]. (2018-10-22) [2021-04-02]. https://arxiv.org/abs/1802.09477.
3. MA-BDDPG
将 DDPG 算法中的经验池分为传统经验池和想像经验池;
想像经验池数据来自动力学模型生成的随机想像转换;
训练前,智能体计算当前状态行为序列 Q 值的不确定性,Q 值的不确定性越大,则智能体从想像经验池中采集数据的概率越大。
该方法通过扩充训练数据集显著加快了训练速度。
Kalweit G, Boedecker J. Uncertainty-driven imagination for continuous deep reinforcement learning[J]. Proceedings of Machine Learning Research, 2017, 78: 195-206.
3.2.4 信赖域策略优化算法
1. TRPO
策略梯度算法中,神经网络直接输出策略函数,根据状态选择动作,其回报函数定义如下。
η ( π ^ ) = E τ ∣ p i ^ [ ∑ t = 0 ∞ γ t ( r ( s t ) ) ] \eta(\hat{\pi})=E_{\tau|\hat{pi}}[\sum_{t=0}^{\infty}\gamma^{t}(r(s_{t}))] η(π^)=Eτ∣pi^[t=0∑∞γt(r(st))]
在 TRPO 算法中,回报函数定义为旧策略与新旧策略回报差之和。
{ η ( π ^ ) = η ( π ) + E τ ∣ p i ^ [ ∑ t = 0 ∞ γ t A π ( s t , a t ) ] A π ( s , a ) = Q π ( s , a ) − V π ( s ) \begin{cases} \eta(\hat{\pi})&=\eta(\pi)+E_{\tau|\hat{pi}}[\sum_{t=0}^{\infty}\gamma^{t}A_{\pi}(s_{t},a_{t})] \\ A_{\pi}(s,a) &= Q_{\pi}(s,a)-V_{\pi}(s) \end{cases} {
η(π^)Aπ(s,a)=η(π)+Eτ∣pi^[∑t=0∞γtAπ(st,at)]=Qπ(s,a)−Vπ(s)
最终优化式如下。
{ m a x θ E [ π θ ( a ∣ s n ) π θ o l d ( a ∣ s n ) A θ o l d ( s , a ) ] s . t . D K L m a x ( θ o l d , θ ) ≤ δ \begin{cases} \mathbf{max}_{\theta}E[\frac{\pi_{\theta}(a|s_{n})}{\pi_{\theta_{old}}}(a|s_{n})A_{\theta_{old}}(s,a)] \\ s.t. D^{max}_{KL}(\theta_{old},\theta) \le \delta \end{cases} {
maxθE[πθoldπθ(a∣sn)(a∣sn)Aθold(s,a)]s.t.DKLmax(θold,θ)≤δ
优点:保证了策略优化过程中性能渐进提高。
缺点:其计算量较大,并且策略与值函数之间参数不共享。
Schulman J, Levine S, Abbeel P, et al. Trust region policy optimization[J]. Proceedings of Machine Learning Research, 2015, 37: 1889-1897.
2. PPO
重要性采样机制重复利用样本数据,提高了样本效率,限制了采样网络和训练网络的分布相差程度。
PPO 算法在目标函数中增加剪切项,将策略更新限制在规定区间内。
Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[DB/OL]. (2017-08-28) [2021-04-02]. https://arxiv.org/abs/1707.06347.
3. ME-TRPO
集成神经网络解决环境中数据不稳定性的问题;
并交替进行模型学习和策略学习,增加适应性;
Kurutach T, Clavera I, Duan Y, et al. Model-ensemble trust-region policy optimization[DB/OL]. (2018-10-05) [2021-04-02]. https://arxiv.org/abs/1802.10592.
4. SLBO
使用 L2 范数损失函数训练动力学模型;
SLBO 算法在多项 MuJoCo 仿真器任务中的性能优于 SAC 算法、TRPO 算法等
Luo Y, Xu H, Li Y, et al. Algorithmic framework for model-based deep reinforcement learning with theoretical guarantees[DB/OL]. (2021-02-15) [2021-04-02]. https://arxiv.org/abs/1807.03858.
3.2.5 其他深度强化学习算法
| 项目 | 工作 |
|---|---|
| HER(hindsight experience replay) | 解决了稀疏奖励导致强化学习困难的问题。HER 算法通过附加目标奖励和价值函数,使得智能体到达的每个状态均有目标,且每个目标均对应一套稀疏奖励函数。智能体可以利用失败的探索经历进行动作限制,提高了样本利用率。除此之外,HER 算法将目标数据附加到经验池中,重塑了经验池数据结构。 |
| I2As(imagination-augmented agents) | 解决了基于模型的算法存在的模型不准确导致行为预测存在误差的问题。在环境模型想像过程中加入模型训练,并且模拟人类的思维方式,使智能体根据已掌握的知识进行信息预测,以选择当前的动作,增强了无模型智能体的性能。想像过程中加入模型训练增加了模型复杂度,导致参数增多,算法收敛较慢。 |
| MBMF(model-based RL with model-free fine-tuning) | 采用基于模型算法的控制器对无模型算法的学习器进行初始化,加快了学习速率。仅训练一次就能通过修改奖励函数,将模型应用到不同的任务,无需重新训练智能体模型。 |
| MBVE (model-based value expansion) | 先使环境模型与环境进行多次迭代,然后进行行为价值的预测。因此,目标 Q 值的预测融合了基于环境模型的短期估计和基于目标网络的长期预估,预测结果更加准确。 |
| STEVE (stochastic ensemble value expansion) | 在不同环境中直接展开特定的步数,然后通过计算每一步的不确定性,动态调整MBVE 算法的权重,以得到更优的 Q 值估计 |
| SimPLe(simulated policy learning) | 直接处理每一帧图片。在训练过程中,生成的视频预测器根据每帧像素预测下一帧图像的动作,以自我监督的方式将环境模型的观察像素作为学习策略的监督信号。 |
4 深度强化学习在机器人操作中的应用
传统机器人操作研究的局限性表现如下。
- 动态环境具有不可预测性;
- 机器人仅在固定位置完成任务且不具备自主学习的能力;
- 机器人技术开发时间长等;
基于视觉的机器人操作系统是从图像中提取视觉特征信息来控制机器人运动,直接根据输入信息,输出机器人的行为。
4.1 刚性目标和非刚性目标
机器人操作刚性物体时,物体不会发生形变或者形变可忽略不计。
机器人操作非刚性物体会导致结构发生变化,非刚性物体的精确建模异常困难。
4.1.1 刚性目标
基于视觉的抓取流程主要分为 3 个阶段:感知、规划和行动。
| 项目 | 工作 |
|---|---|
| Zeng等 | 利用深度相机采集工作空间信息,基于 DQN 算法训练机器人完成推动和抓取物体的协同操作任务 |
| Berscheid 等 | 基于 Zeng 的工作提出了动作最佳位姿算法,减轻了智能体对稀疏奖励的需求,加强了数据学习。能够将模型泛化到未知的形状不规则的生活物品,并且抓取效率达到 90% 以上 |
| Kalashnikov 等 | 提出了QT-Opt 框架,通过多个机器人收集抓取操作数据,经过训练后的机器人抓取未知、形状各异物体的成功率高达 96%,并且可以灵活地应对动态变化 |
针对模型对未知环境适应性差的问题,不同学者提出了如下模型。
| 项目 | 工作 |
|---|---|
| Mahler等 | 利用 Dex-Net4.0 行为策略,以 300 次/h 的平均抓取速度清理 25 个未知物品,可靠性达到 95%,证明了模型在未知环境中的高度适应能力。 |
| Jiang 等 | 设计了基于 DDPG 的机器人操作算法,构造了非对称的 AC 结构,并在演员网络结构中加入了辅助任务分支。机器人在操作实验中通过行为策略成功学习了操作技能,而且非对称 AC 结构和辅助任务分支可以有效提高学习效率和抓取策略性能。 |
| Popov 等 | 基于 DPG 算法,融合A3C 分布式思想,将训练16 台机器人所用的时间成功缩短到仅 10 h,大大提高了数据收集率。 |
针对机器人操作刚性物体的情形
开展研究。
| 项目 | 工作 |
|---|---|
| Jang 等 | 使用表示学习(representation learning)方法学习以物体为中心的数据表示并指导智能体完成复杂的任务 |
| Li 等 | 利用强化学习策略指导机械手进行抓取等操作,成功降低了视觉反馈的复杂性 |
| Fang 等 | 使用面向任务的抓取网络,成功操作工具完成任务且准确率达到 70 % ~ 80 % 70\%~80\% 70%~80%,使得机器人握持工具完成操作任务成为可能 |
| Nagabandi 等 | 基于模型的深度强化学习算法学习多指灵巧手的操作技能方法,仅花费 4 h 即可成功掌握操作技能,如写字 |
| Zakka 等 | 提出了通用化装配框架(Form2Fit),将装配任务表述为形状匹配问题,并学习了一种通用的匹配函数。该函数对初始条件具备较强的鲁棒性,可以处理新的套件组合并泛化到新的对象。 |
| Khansari 等 | 提出以动作图像表示抓取建议,并利用深度卷积网络提取抓取任务的局部特征,推断抓取质量。 |
| Murali 等 | 提出了 6 自由度抓取方法。行为策略根据目标物的位置进行路径规划并完成抓取任务。 |
4.1.2 非刚性目标
Lin 等提出的处理可变形对象的开源模拟基准 SoftGym 为非刚体的研究提供了便利。
Lin X, Wang Y, Olkin J, et al. SoftGym: Benchmarking deep reinforcement learning for deformable object manipulation[DB/OL]. (2021-03-08) [2021-04-02]. https://arxiv.org/abs/2011.07215.
现如今机器人模拟器中缺乏对非刚性物体的精确模型,导致非刚体的操作研究并不广泛,因此基于深度强化学习的非刚体操作任务的研究亟待解决。
4.2 模拟训练和真实训练
但由于领域差异,仅用模拟环境下的数据集训练的模型不能保证实体机器人正常工作。
4.2.1 模拟训练
| 学者 | 内容 |
|---|---|
| Lin 等 | 在迁移学习的框架下验证了视觉预训练能够有效地提高学习操作对象的泛化能力和样本利用率 |
| Rusu 等 | 通过 A3C 算法在模拟环境训练模型,并通过渐进网络弥补模型迁移的差距 |
| Gupta 等 | 以轨迹为中心的强化学习算法,利用时变线性高斯策略指导机器人完成目标定位和目标移动等任务,并通过领域自适应成功完成了模型转移 |
| Peng 等 | 通过组合递归确定性策略梯度(recurrent deterministic policy gradient,RDPG) 与 HER,指导 7 自由度机械手完成了物体布置任务,并通过领域随机化将模型成功部署到了真实机器人 |
| Haarnoja 等 | SQL(soft Q-learning)应用到 Sawyer 机器人的推动和堆叠等任务中,并且验证了其鲁棒性优于 NAF (normalized advantage function)和 DDPG 算法 |
- James 等提出随机化到规范化的适应网络,不使用现实世界数据克服视觉现实差异。
将该训练模型转移到真实世界中,实现了 70% 的未知物体抓取成功率。 - Hundt 等设计了 SPOT(schedule for positivetask)框架,直接在真实机器人上加载模拟训练的模型,而无需进行额外的实际微调。
- Pedersen等利用 CycleGAN 算法缩小模拟环境和真实环境的差距。
Pedersen O M, Misimi E, Chaumette F. Grasping unknown objects by coupling deep reinforcement learning, generative adversarial networks, and visual servoing[C]//IEEE International Conference on Robotics and Automation. Piscataway, USA: IEEE, 2020: 5655-5662.
4.2.2 真实训练
| 学者 | 工作 | 优缺点 |
|---|---|---|
| Kalashnikov 等 | QT-Opt 框架。该算法侧重于抓取任务的长期推理并分解抓取任务为多个动作序列。对 7 个 KUKA LBR IIWA 机械臂进行为期 4 个月的训练,做出 58 万次抓取尝试。 | 代价大但精度高 |
| Mahmood 等 | 采用 TRPO 算法直接训练 UR5机械臂,证明了减少延迟可以有效解决参数设置带来的敏感问题。 | None |
| Finn 等 | 提出了结合深度动作条件的视频预测模型和使用完全未标记训练数据的模型预测控制(model-predictive control,MPC)的方法。通过 10 个 7 自由度机械臂对数百个对象进行 5 万次的操作,并基于此制作数据集。 | None |
| Yahya 等 | 引导策略搜索(guided policy search,GPS)方法扩展为分布式和异步版本的引导策略搜索(distributed asynchronous GPS,DAGPS),并指导 4 个机器人执行开门任务的策略学习。 | 需要强大的设备支持和长时间训练 |
4.3 稀疏奖励和塑性奖励
| 稀疏奖励 | 塑性奖励 |
|---|---|
| 二元函数,机器人完成目标才能获得相应的奖励值; | 某些变量的函数,机器人行为的奖励值随着变量动态变化 |
| 训练初期负奖励样本数远远高于正奖励样本数,严重影响机器人学习 | 在复杂任务中函数定义复杂,难以实际应用 |
4.3.1 稀疏奖励
Zeng 等和Berscheid 等设计稀疏奖励函数。
奖励函数可以设计为机器人末端执行器和方块之间的距离函数,即塑性奖励函数。
仅通过视觉很难获得实验环境中方块的随机位置,因此在目标位置的动态变化情况下,采取稀疏奖励函数定义任务成功与否更为合适。
| 学者 | 工作 | 优缺点 |
|---|---|---|
| Riedmiller 等 | 提出了调度辅助控制(scheduled auxiliary control,SACX)方法,存在多个稀疏奖励信号的情况下,从头开始学习复杂行为,并且主动调度和辅助策略的执行,使智能体对环境进行充分探索 | 具有高度可靠性,其行为多样化且鲁棒性强。 |
| Andrychowicz 等 | 提出 HER 机制,该机制不需要复杂的奖励函数过程设计,将智能体每个回合到达的目标状态存入经验池中,大大扩展了经验池中完成任务的经验数量,将稀疏问题转化成了非稀疏问题 | 实验效果优于仅使用稀疏奖励机制的方法。 |
| Li 等 | 使用深度强化学习、关系图结构和课程学习的方法将多个方块堆叠成塔,并且通过逐步稀疏的奖励方式评价机器人的操作行为 | 在数据利用率方面提高了几个数量级,并且效果超过了利用演示数据的相关方法 |
4.3.2 塑性奖励
| 学者 | 奖励函数设置 | 场景 | 特点 |
|---|---|---|---|
| Liu 等 | 由对象目标配置和对象当前配置进行构造 | 采用 PPO 算法的改进型算法学习和优化技能策略,改进型 PPO 算法性能优于PPO 算法和 A3C 算法。 | 手工设计 |
| Zuo 等 | 目标点与机械臂末端抓取器之间的距离函数。 | 实现了 OWI-535 机械臂的目标点定位 | 手工设计 |
| Singh 等 | 没有设计奖励函数 | 提供机器人成功完成任务的演示。机器人执行动作后,请求查询并根据得到的标签判断任务是否成功完成。 | 非手工设计 |
| Zhu 等 | 没有设计奖励函数,训练了能够区分成功和失败的判别器,判别信号指导智能体学习。 | 设计了VICE(variational inverse control with events)框架 | 非手工设计 |
| Xu 等 | 奖励函数学习方法与正确-未标注(positive-unlabeled)学习方法相结合 | 解决了算法过拟合问题和奖励学习的欠拟合问题 | 非手工设计 |
| Wu 等 | 以自我监督的方式估算任务进程奖励。 | 从机器人高维观测数据 | 具有更好的操作性能和更快的收敛性 |
4.4 示范和次优示范
模仿学习(imitation learning,IL)和深度强化学习的融合方法利用示范数据提高了机器人的自学能力和学习速率。
要采取合适的措施优化可能存在的次优数据。
4.4.1 示范
| 学者 | 工作 | 优缺点 |
|---|---|---|
| Rajeswaran 等 | 基于示范强化策略梯度(demo augmented policy gradient,DAPG)算法,加入机械手成功开门示范数据,解决了从零开始训练的低效问题 | 相对于从零开始学习,速率提高了近 30 倍 |
| Zhu 等 | 同样基于 DAPG 算法,加入人类示范数据。机器人成功地完成了旋转阀门和翻转物体等操作 | 学习时间减少一半 |
| Gupta 等 | 通过手持机械手完成期望动作的示范,然后利用 GPS 算法训练智能体执行操作任务 | 效果优于未加入示范 |
| 的情况 | ||
| Chen 等 | BAIL(best-action imitation learning)方法学习策略函数,并选择高性能动作。模仿学习通过高性能动作训练策略网络。 | 收敛速度和性能均得到提高 |
4.4.2 次优示范
- Xiang 等提出将任务奖励和目标导向奖励相结合的方法,并利用少量不完美的专家演示进行训练指导
形成的 AC 算法相对于部分基准深度强化学习算法具有更高的采样效率,大大降低了样本复杂度。 - Mandlekar等提出了新型框架 IRIS(implicit reinforcement without interaction at scale),其中包括目标低层控制器和高层目标选择机制。
目标低层控制器模仿了简短的演示序列;
高层目标选择机制为目标低层控制器选择目标并有选择性地组合部分次优示范; - Gao 等提出了统一的强化学习规范算法,归一化演员―评论家(normalized actor-critic,NAC)。
NAC 算法有效地规范化了动作价值函数,降低了示范数据中不存在的动作价值,对次优数据具有很强的鲁棒性。 - Brown 等设计了一种从次优示范中学习奖励功能的 T-REX(trajectory-ranked reward extrapolation),并且效果优于专家示范。
4.5 元强化学习
元强化学习的本质是利用少量样本数据微调模型以使行为策略匹配新环境和新任务。
其原理是将基础强化学习方法中手动设定的超参数设定为元参数,然后学习和调整元参数以指导底层强化学习。
| 学者 | 工作 | 优缺点 |
|---|---|---|
| Goyal 等 | PixL2R(pixels and language to reward)模型,直接将像素映射到奖励,使机器人学习操作行为策略 | 提高了策略学习的样本利用率 |
| Wu 等 | 采样效率高的元强化学习算法,该算法只根据一个视频演示就可以执行新任务。 | 在机器人的抓取和放置等操作任务中,该算法性能远超行为克隆和强化学习算法。 |
| Yu 等 | 提出了包含 50 个不同的机器人操作任务的用于元强化学习和多任务学习的开源模拟基准,为机器人的训练提供了支撑 | 证明了元强化学习在机器人操作领域的重要作用 |
5 挑战和未来展望
几乎没有机器人操作问题可以被严格地定义为马尔可夫决策过程,而是表现为部分可观性和非平稳性,这是实验效果并不如预期的原因之一。
- 非刚性物体难以被精确建模。
针对此挑战,设计多指灵巧机械手和开发非刚性物体的开源模拟平台可能成为机器人操作柔性物体的有效解决方法。
具体而言,多指灵巧机械手的手指可以相互配合,类似于人类手指,并且每个手指可以单独动作。 - 模型难以从模拟环境迁移到真实环境。
根据实验需求,将二者的领域差异因素加入到模拟环境中,可使行为策略具备更强的鲁棒性。
从动力学角度加入真实场景中的摩擦力、光照、噪声等干扰因素。 - 不同环境不同任务间模型可移植性差。
元强化学习、多任务学习。 - 人为设计的奖励函数难以评价多步操作任务。
逆强化学习可以指导机器人根据已知的行为策略学习奖励函数,一定程度上可为操作算法提供思路。
求以自我监督的方式估算任务奖励或者人为辅助奖励。 - 机器人采样效率低、学习速率慢。
模仿学习与强化学习的结合可以提高机器人学习速率。
专家示范方法存在对示范者要求高和成本大的问题。
通过深度强化学习指导机器人自动生成行为示例,以此作为示范数据,丰富机器人的数据集。