为了以后的学习方便,把几篇计算机视觉的论文放上来,仅为自己的学习方便,本文仅将自己感兴趣部分简单翻译。排版对手机端不友好。因为MathType过期,没找到解决方法,所以文章中的大部分公式为图片形式。
这篇文章是实例分割方向的文献,属于自下而上的方法(bottom-up approach)
原文地址:PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric
论文简介
PersonLab运用了一个single shot模型(暂时理解为一张图片的意思),不需要物体框,基于自下而上(暂时理解为特征信息和位置信息)的思想来解决多人物图中人物姿态评估和实例分割,并使用part-based模型解决了语义级别的推理和物体部分的联合。该模型用一个卷积网络来学习检测每一个关键点并预测他们之间相关的关系,方便将关键点分到对应人物姿态实例中。除此之外,还使用了一个 part-induced geometric embedding descriptor将人物像素分配到对应的人物中,实现人物的实例分割。整个系统是基于全卷积网络结构,模型的运行时间和图片中的人物个数无关。在COCO数据集上测试,单尺度模型的平均预测准确率为0.665,多尺度的平均预测准确率为0.687,比当前任何自下而上的系统都要好。同时也是第一个使用自下而上的模型来单独做人物分割的,人物分割的平均准确率为0.417。
论文内容
1、论文结构
Section 1(Introduction):
说明了关键点检测和实例分割的主要任务,以及对于多人物检测、姿态检测和实例分割的两种主要方法进行了简单的阐述。
Section 2 (Related Work):
对当前主流的关键点检测和实例分割的方法进行了说明。
Section 3 (Methods):
对PersonLab的架构进行简单的介绍,并对文章中的创新点的思想来源和具体方法进行了简单说明,对可量化表示的数据进行解释。
Section 4 (Experimental Evaluation):
列举了实验中具体的细节,以及通过对比试验来说明论文提出方法的效果。
Section 5 (Conclusion):
论文总结。
2、Introduction
本文提出的PersonLab是一个可以解决多人物检测、2维姿势评估和实例分割的综合性模型。对于给定的图片,可以做到以下三点:
- 区分每个人;
- 找出面部和身体的关键点;
- 生成实例掩模;
针对多人物检测、2维姿势评估和实例分割这三个问题,根据解决方法的结构不同,主要分为“自上而下”( top-down )和“自下而上”( down-top )两种方法:
⑴ “自上而下”的方法首先通过物体框检测,对目标进行辨认并粗略的定位每个人。然后对物体框中的每一个人进行姿势的检测和二值掩模的生成。
⑵ “自上而下”的方法首先定位出每一个语义实例(包括关键点和语义标签)裁剪和调整大小的方法。
PersonLab在第二种方法的基础上,提出了一种无需物体框的的全卷积网络,这个方法的计算量与图片中的人物个数无关,只与CNN的特征提取骨干网络有关。
特别地是,PersonLab首先运用一个全卷积的方法(什么方法??)将图片中每个人的所有关键点找到。然后预测每一对关键点的相对位置关系,为了提高两个远距离的关键点预测的准确率,提出一种新的循环的方法(什么方法??),极大地提高了效果。最后使用贪婪解码方法,将所有的关键点对应分到各自的实例中。PersonLab采用了先从最有把握的关键点开始进行分割,而不是直接定义一个确定的基准,例如鼻子,使得在聚类的时候表现的很好。
除了预测稀疏的关键点(sparse keypoints),该方法同样对每个人预测了密集的实例分割掩模(dense instance segmentation mask)。为了得到掩模,该方法对语义级别的未知的人物进行预测。对于每一个语义级别是人物的像素,预测了和它有关的人物的关键点的偏置向量。相应的矢量场可以看作一个几何上的embedding representation,并为每个人物实例引入basins。这样便得到一个简单的算法:
对任意像素,预测该像素所属人物的
个关键点的位置,并计算该像素与这些关键点的平均距离。同时计算所有候选人物中最有可能的
的
个关键点
3、Related Work
根据文章的分类,因为实验主要是为了解决关键点检测和实例分割的问题,于是针对两个方面的相关工作的说明如下:
A、Pose estimation
早期成功的人体姿势估计模型以基于零件的图形模型[6][7]上的推理机制为中心,通过可配置的part集合表示一个人。在这之后,人们提出了许多方法来开发可处理的推理算法,以解决捕获身体各部分之间丰富依赖性的能量最小化问题。虽然这项工作的正向推理机制不同于这些早期基于DPM的模型,但PersonLab同样提出了一种自底向上的方法,将部分检测分组到个人实例。
最近,基于现代大规模卷积网络的模型在单人姿势估计和多人姿势估计上都取得了最先进的性能。从广义上讲,文献中姿势估计主要有两种方法:自上而下(人先)和自下而上(part先)。前者的例子包括G-RMI[1]、CFN、RMPE、Mask R-CNN[8]和CPN。
在自下而上的方法中,首先检测身体部位,然后将这些部位分组到人类实例中。有学者通过线性程序将多人姿态估计问题制定为part分组和标记问题。也有工作将修改的一元联合检测器与零件亲和力字段合并,并生成个人实例proposal。与此同时,还有人提出关联嵌入(associative embedding),以识别同一个人的关键点检测。
B、Instance segmentation
这一问题同样分为两种:自下而上(bottom-up)和自上而下(top-down)的方法。
自上而下的方法利用最先进的检测模型对掩模方案进行分类,或通过优化边界框方案来获得遮罩分割结果。
PersonLab的方法是自下而上的,在这种方法中,先得到每个像素的分类,然后经过回归将像素分组。
4、人物检测和姿态评估
A、关键点检测
假设为二维图像中的位置,其中
,这里N代表整个图中像素的个数。并
将定义为以y为中心,半径为R的扇区。同时定义
代表第j个人的第k个关键点,其中
,M代表图中人物的个数。
对于每一个关键点,对应产生一个二值掩模图。并假设
为热图,当像素
满足
时,则
,否则
。代表像素
属于第
个人的第
个关键点,并产生了掩模。所以对于
个人物,有
个二分类的任务,相当于对图像中每个人的所有关键点都预测了一个半径为
的像素区域。在论文中的实验中,预设
,与人物尺寸大小无关,这么做的原因是为了同等地计算每个人的分类损失函数。
除了预测热图,我们同样预测了短距离(short-range)的偏置向量,以便于提高关键点位置的准确率。在关键点扇区内的每一个位置,对于每一类关键点
,二维的短距离偏置向量
,表示从图像的
位置指向第j个人的第k个关键点,如图1所示:

图1 PersonLab的整体结构图
PersonLab产生了个向量区域,以便于分别解决图像中每个位置点和关键点的二维回归问题。在训练阶段,用
损失函数去计算短距离(short-range)的偏移量预测误差,仅对在关键点扇区内的位置
,进行取平均并进行后向传播计算误差值。文中将短距离偏置(以及文中所提到的其他回归任务)除以半径
,以便于得到一个归一化的结果并使得其动态范围与热图分类损失函数相称。
通过Hough Voting,将热图(heatmap)和短距离(short-range)偏置整合成二维的Hough分数图,对于不同类型的关键点,使用不同的Hough累加器。每一个图像的位置对每一种关键点通道产生一个vote,对应的权重为它的激活概率:
其中表示双线性插值核,具体的形式如图1所示。
B、将关键点分到对应的实例中
⑴ 中距离偏置
分数图的局部最大值被视作人物关键点的候选位置,但它们不携带有关实例的信息。当图像中存在多个人物时,我们需要一种“连接点”机制,使得属于每个人物的关键点分到对应人物中。为了解决上述问题,PersonLab在网络中增加了一个中距离的偏置
,用于连接成对的关键点。这样需要计算
(这里的
我理解为共有K个关键点,每个关键点需要与其他的所有关键点)个偏移量,其中偏移量是用有向边来表示的,每个有向边连接一对关键点
,这些关键点在人的树结构运动图中彼此相邻,详见图1和2。

图2 中距离偏置示意图
值得指出地是,第k个关键点到第l个关键点对应的偏移量可以由下式表示:
它的目的是为了让同属于实例j的第k个关键点移动到第l个关键点。在训练阶段,只有当训练样本中同时存在两个关键点时,才定义此目标回归向量。同时计算了回归预测误差在源关键点的区域上的平均
损失,并通过网络进行反向传播。
⑵ 偏置修正
尤其是对于大型人的情况,运动图的边缘连接着的一对关键点,如右肘和右肩,它们可能在图像中相距几百像素,很难生成精确的回归。为解决这一问题,通过使用更精确的短程补偿,反复地细化中距离(Mid-range),具体来说是:
其中,,具体细节如图2所示。在实验中,对此细化重复了两次。采用双线性插值方法对中间位置
处的短距离偏移场进行采样,并将误差沿中距离和短距离输入偏移分支反向传播。PersonLab在CNN输出激活的分辨率上执行偏移量细化,使处理非常快速。如图2所示,偏移细化过程显著减少了中间范围回归误差,这是该方法中的一个关键新颖之处。
⑶ 快速的贪婪解码(Fast greedy decoding)
PersonLab提出了一种非常快速的贪婪解码算法,能够将所有的关键点分到检测到的每个人的实例中。论文首先创建一个优先级队列,在所有K类关键点中共享。其中,在Hough score map中插入所有局部极大值的位置
和关键点类型k,其得分高于阈值,该阈值在所有报告的实验中设置为0.01,得到的这些点作为实例的候选点。然后,按降序从队列中弹出元素。在每次迭代中,如果类型k的候选检测种子的位置
在检测到的实例人
的对应的关键点的区域
内,则拒绝它。对应的有,
(像素)的非最大抑制半径。否则,我们启动一个新的检测实例j,并将第k个关键点在位置
作为种子。然后,我们沿着运动学人图的边缘跟随中距离位移矢量,贪婪地连接相邻关键点对
,并定义
。
值得注意的是,该解码算法不会优先处理任何关键点类型,而其他技术总是使用相同的关键点类型(如躯干或鼻子)作为种子来生成检测。虽然从经验上观察到,大多数正面人物的检测都是从更容易定位的面部关键点开始的,但是本文中的方法也可以处理大部分人被遮挡的情况。
C、Keypoint- and instance-level detection scoring
论文尝试了不同的方法为贪婪解码算法生成的检测分配一个关键点和实例级别的分数。第一个关键点级别评分方法遵循[1]并为每个关键点分配一个置信分。这种方法的一个缺点是,较方便定位关键点,例如面部,通常比不方便可定位的关键点(如臀部或膝盖)获得更高的分数。第二种方法则是尝试校准不同关键点类型的分数,由COCO关键点任务中使用的对象关键点相似性(OKS)评估指标驱动的,该指标使用不同的精度阈值
来惩罚不同类型的关键点的定位错误。
具体来说,考虑一个具有关键点坐标的被检测人实例j,并假设
是第j个人实例的所有被检测关键点的边界框区域的平方根。则第k个关键点的预期OKS分数定义为

其中,是在
内的标准化的Hough score。预期的OKS关键点水平分数是对关键点存在的置信度的产物,乘以OKS定位精度置信度,得到关键点的信息。
运用关键点分数的平均值作为实例级别的分数![]() ,是经过极大值抑制(NMS)得到的。对基于hard-OKS的NMS[1]和[2]中的关键点任务的soft-OKS的NMS方案进行了试验,将尚未由得分较高的实例声明的关键点得分之和作为最终实例的得分,并通过关键点总数进行归一化:
,是经过极大值抑制(NMS)得到的。对基于hard-OKS的NMS[1]和[2]中的关键点任务的soft-OKS的NMS方案进行了试验,将尚未由得分较高的实例声明的关键点得分之和作为最终实例的得分,并通过关键点总数进行归一化:
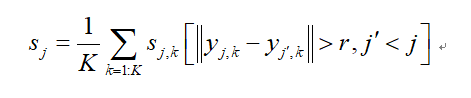
其中,为NMS的半径。本文的实验报告了具有最佳性能的预期OKS评分(Expected-OKS score)和软NMS(soft-NMS)的结果,并在补充材料中描述了对比试验。
5、人物实例分割
分割阶段的任务是识别属于人的像素,并将其与检测到的人实例相关联,即为分组各自对应的像素。接下来我们将描述各自的语义分割和映射模块,具体细节如图3所示。

图3 人物实例分割
A、人物语义分割
本文中使用全卷积得到人的语义分割[3]。用一个卷积层构成分割head,该卷积层执行dense逻辑回归,并对每个图像像素
上计算它属于实例人的概率
。在训练过程中,计算并反向传播了所有图像区域的logistic损失平均值,这些图像区域已被注释。
B、通过geometric embeddings将分割与实例关联
这模块的任务是实现实例分割,即将语义分割得到的像素与人物检测和姿态估计模块(person detection and pose estimation module)生成的关键点进行相互的关联。
与[4]类似,该任务也采用了基于embedding的方法。在这个框架中,在每个像素位置计算一个embedding vector ,然后进行聚类以获得最终的对象实例。在之前的工作中,通常通过计算不同图像位置的embedding vector来学习representation,并使用一个损失函数来吸引两个embedding vector(如果它们都来自同一对象实例),如果它们来自不同的人实例,则排斥。这通常会导致embedding representation难以解释,并且涉及到解决一个困难的学习问题,该问题需要仔细选择损失函数并调整多个超参数,例如the pair sampling protocol。
所以这里选择了一种简单的几何方法。在带注释的实例人j的分割掩模内的每个图像位置处,二维关键点位置
,并定义远距离(long-range)的偏移向量
,用以表示从图像位置
指向对应实例j的第k个关键点位置。此处需要说明的是,这与短距离预测任务相比除了动态范围不同之外,其他均相似。同样的,需要计算K个这样的二维向量场,每种关键点类型有一个。在训练过程中,仅当图像位置属于单个个体对象实例时,使用
损失函数、取平均和反向传播来惩罚长距离偏移回归误差。该方法忽略了背景区域、人群区域和由两个或多个人脸覆盖的像素。
远距离预测任务具有挑战性,尤其是对于可能覆盖整个图像的大型实例对象。于是通过双线性翘曲函数,细化了长距离偏移量:
![]()
第一次是定义式细化,第二次是通过短距离偏移量细化。

图4 长距离偏置的定义
如上图所示,说明了与鼻子相对应的远距离偏移量,这是由训练过的CNN计算出来的。可以看到,长距离矢量场有效地将图像平面分割成吸引每个人的basins。这促使我们将维向量
定义为实例关联任务的embedding representation,其中
。
PersonLab所提出的embedding representation有一个非常简单的几何解释:在每个图像位置,在语义上被识别为人,embedding
表示对
所属的人的每个关键点的绝对位置的局部估计,即它代表实例人的预测形状。特别地,为了判定人像素是否属于第j个,可以计算embedding distance metric:

其中,是第k个人的第j个关键点的位置,
表示该位置的存在概率。通过关键点存在概率来衡量误差,可以对由于缺少关键点而导致的两种形状的差异进行抵消。通过检测到的实例尺度
对误差进行归一化,可以得到尺度不变的标准(metric)。将
设置为严格包含第j个人的所有检测关键点的边界框区域的平方根。因为只需要计算
像素和第M个人实例之间的距离度量,所以该算法在实践中非常快速。该算法具有标准的embedding-based的分割技术的复杂性
,而不是
,至少在原则上需要计算所有像素对。
为了得到最终的分割结果,我们将进行以下两个操作:
- 找到语义分割图中所有的位置都被标记为人的像素,即语义分割概率
的像素。
- 将每个像素与每个检测到的实例人j相关联,其中嵌入距离标准(embedding distance metric)满足
。
对上述需要说明的是,在所有的实验中,设置相对距离阈值。需要注意的是,像素实例分配是非独有的:每个像素可能与多个被检测人实例相关联,或者它可能仍然是孤立的。在该情况下,使用前一个检测和姿势估计阶段产生的同一实例的分数来评估COCO数据集的分割任务,并获得平均精度性能。
6、输入缺少的关键点注释
标准COCO数据集在针对小人物实例的训练集中不包含关键点注释,并且在模型评估期间忽略关键点注释。但是,标准的COCO数据集包含分段注释,并能够评估这些小实例的掩码预测结果。由于我们的几何嵌入(geometric embeddings)训练需要关键点注释,已经在COCO训练集中运行了[1]的单人姿势估计量(仅针对COCO数据进行训练),该训练集中针对训练小人物实例的真正的框,注释周围的图像作物,以输入那些丢失的关键点注释。在个人实验室模型培训中,将这些输入的关键点作为常规的培训注释。当然,这个缺失的关键点插补步骤对于在小人物实例上的COCO实例分割性能特别重要。需要强调的是,与[5]不同,在此过程中,我们不使用COCO序列分割图像和注释之外的任何数据。如[5]所述,对附加图像进行数据预处理可能会产生进一步的改进。
7、实验效果
A、训练集上的关键点检测
通过上述的讲述,并结合不同的网络结构,在COCO关键点的训练集上得到的实验对比如图5所示:

图5 在COCO关键点的训练集的效果
B、测试集上的关键点检测
通过与FCIS和Mask R-CNN的方法进行对比关键点检测的效果如下:

图6 与Mask R-CNN和FCIS的对比效果
可以看到,Mask R-CNN的效果任然占优势。
C、实例分割的效果图

图7 实例分割的实现效果图
从上图可以看到,PersonLab同时做到了关键点的检测和实例分割的任务。同时最后一行显示了一些失败案例:漏掉关键点检测、假阳性关键点检测和漏掉分割。
未来的方向
为了提高实例分割的性能,可以对语义分割到实例分割的中间加一个低层信息的再利用网络。
论文的优点
⑴ 使用方向特征,并对不同方向上不同区域进行分区,进一步提高性能;
⑵ 结合了检测和分割的优点,获得更高的性能;
⑶ 掩模细化采用超列,结合了多层次的信息;
参考文献
- Papandreou G , Zhu T , Kanazawa N , et al. Towards Accurate Multi-person Pose Estimation in the Wild[J]. 2017.
- Bodla N , Singh B , Chellappa R , et al. Soft-NMS -- Improving Object Detection With One Line of Code[J]. 2017.
- Long J , Shelhamer E , Darrell T . Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4):640-651.
- De Brabandere B , Neven D , Van Gool L . Semantic Instance Segmentation with a Discriminative Loss Function[J]. 2017.
- Radosavovic I , Dollár, Piotr, Girshick R , et al. Data Distillation: Towards Omni-Supervised Learning[J]. 2017.
- Fischler M A , Elschlager R A . The Representation and Matching of Pictorial Structures[J]. IEEE Trans Computers C, 1973, 22(1):67-92.
- Felzenszwalb P F , Mcallester D A , Ramanan D . A Discriminatively Trained, Multiscale, Deformable Part Model[C]// 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008), 24-26 June 2008, Anchorage, Alaska, USA. IEEE, 2008.
- He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
附录
附录一:
术语对照表
| 英语表达 |
中文翻译 |
| OKS(object keypoint similarity) |
自上而下的调制(用于物体检测的方法) |
| Bilinear Warping Function |
双线性翘曲函数 |