目录
实验二 NFA 到 DFA
一、实验目的
- 掌握NFA和DFA的概念。
- 掌握é闭包的求法和子集的构造方法。
- 实现NFA到DFA的转换。
二、预备知识
- 完成从正则表达式到NFA的转换过程是完成本实验的先决条件。虽然DFA和NFA都是典型的有向图,但是基于NFA自身的特点,在之前使用了类似二叉树的数据结构来存储NFA,达到了简化的目的。但是,DFA的结构相对复杂,所以在这个实验中使用了图的邻接链表来表示DFA。
- 对DFA的含义有初步的理解,了解ε―闭包的求法和子集的构造方法。
三、实验内容
NFA向DFA的转换的思路
从单个字符的某个状态中去除ε-转换和多重转换。消除ε-转换涉及到ε-闭包的构造。消除在单个字符上的多重转换涉及跟踪可由匹配单个字符而达到的状态的集合,这个算法称作子集构造。
从NFA的矩阵表示中可以看出,表项通常是一状态的集合,而在DFA的矩阵表示中,表项是一个状态,NFA到相应的DFA的构造的基本思路是:DFA的每一个状态对应NFA的一组状态DFA使用它的状态记录在NFA读入一个输入符号后可能达到的所有状态。
状态集合的ε-闭包:将单个状态s的ε- 闭包定义为可由一系列的零个或多个ε- 转换能达到的状态集合,并将这个集合写作 。
子集构造:从一个给定的NFA------M来构造DFA的算法,并将其称作 。首先计算M初始状态的ε-闭包它就变成
的初始状态。对于这个集合以及随后的每个集合,计算a字符上的转换如下所示:假设有状态的S集和字母表中的字符a,计算集合
={t|对于S中的一些s,在a上有从s到t的转换}。接着计算
,它是
的闭包。这就定义了子集构造中的一个新状态和一个新的转换
,继续这个过程直到不再产生新的状态和转换。
NFA和DFA之间的联系
在非确定的有限自动机NFA中,由于某些状态的转移需从若干个可能的后续状态中进行选择,故一个NFA对符号串的识别就必然是一个试探的过程。这种不确定性给识别过程带来的反复,无疑会影响到FA的工作效率。而DFA则是确定的,将NFA转化为DFA将大大提高工作效率,因此将NFA转化为DFA是有其一定必要的。
NFAToDFA.h 文件
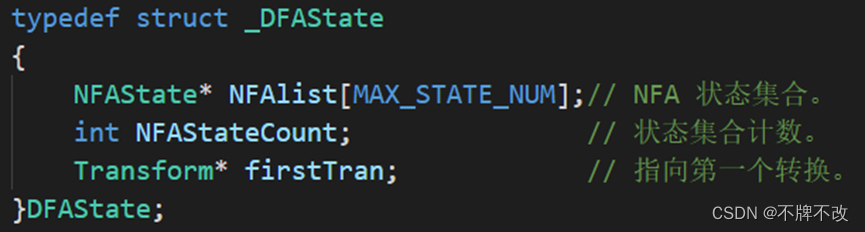
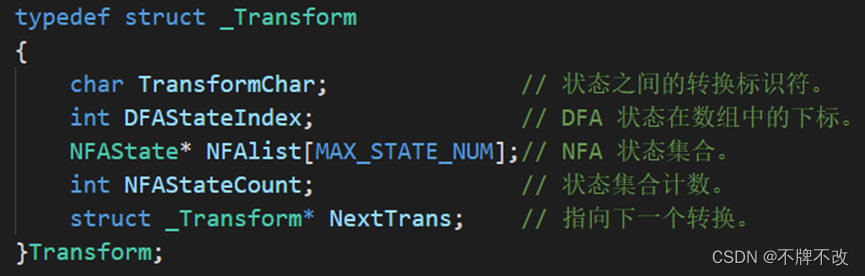
主要定义了与NFA和DFA相关的数据结构,其中有关NFA的数据结构在前一个实验中有详细说明,所以这里主要说明一下有关DFA的三个数据结构,这些数据结构定义了DFA的邻接链表,其中DFAState结构体用于定义有向图中的顶点(即DFA状态),Transform结构体用于定义有向图中的弧(即转换)。具体内容可参见下面的表格。

其中,DFA的成员DFAlist为指针数组,指针类型为DFAstate类型。
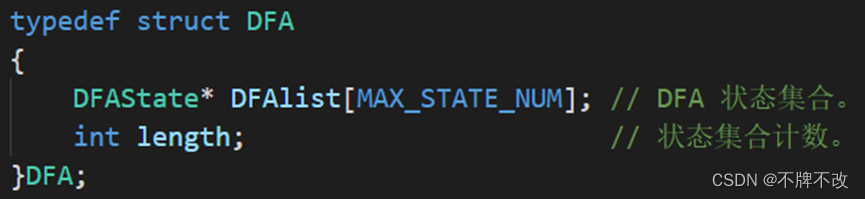

其中,DFAstate的成员NFAlist为指针数组,指针类型为NFAstate类型。NFAstate包含五个成员,字符型的Transform为状态间装换的标识,用'$'表示'ε-转换';两个NFAstate类型的Next指针,指向下一个状态;整数类型的状态名称Name;整数类型的AcceptFlag表示是否为接受状态的标志,1表示是接受状态0表示非接受状态。

main.c 文件
定义了main函数。在main函数中首先初始化了栈,然后调用了re2post函数,将正则表达式转换到解析树的后序序列,最后调用了post2dfa函数将解析树的后序序列转换到DFA。
在main函数的后面,定义了一系列函数,有关函数的具体内容参见下面的表格。关于这些函数的参数和返回值,可以参见其注释。

RegexpToPost.c 文件
定义了re2post函数,此函数主要功能是将正则表达式转换成为解析树的后序序列形式。
PostToNFA.c 文件
定义了post2nfa函数,此函数主要功能是将解析树的后序序列形式转换成为NFA。关于此函数的功能、参数和返回值,可以参见其注释。
NFAFragmentStack.c 文件
定义了与栈相关的操作函数。注意,这个栈是用来保存NFA片段的。NFAStateStack.c 文件
定义了与栈相关的操作函数。注意,这个栈是用来保存NFA状态的。RegexpToPost.h 文件
声明了相关的操作函数。为了使程序模块化,所以将re2post函数声明包含在一个头文件中再将此头文件包含到“main.c”中。
PostToNFA.h 文件
声明了相关的操作函数。为了使程序模块化,所以将post2nfa函数声明包含在一个头文件中再将此头文件包含到“main.c”中
NFAFragmentStack.h 文件
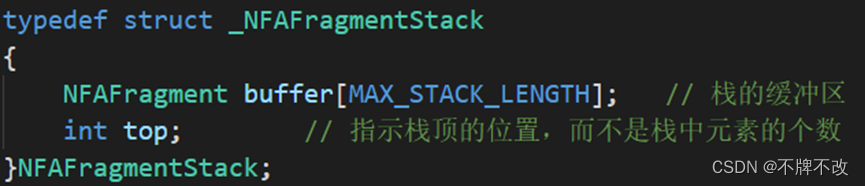
定义了与栈相关的数据结构并声明了相关的操作函数。定义的数据结构本质上是数组模拟的栈。
NFAStateStack.h 文件
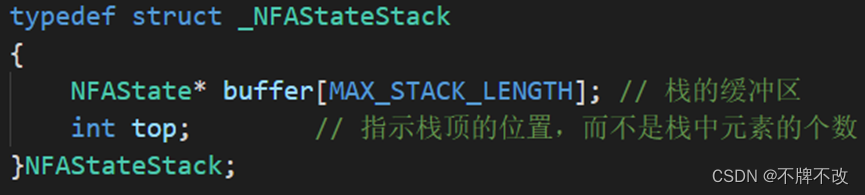
定义了与栈相关的数据结构并声明了相关的操作函数。定义的数据结构本质上是数组模拟的栈。
demo过程讲解
Step1:断点位于“Start = post2nfa(postfix);”处时(未执行),调用 post2nfa 函数将解析树的后序遍历序列转换为 NFA ,并返回开始状态。此时还未生成NFA状态图。可视化界面如下:
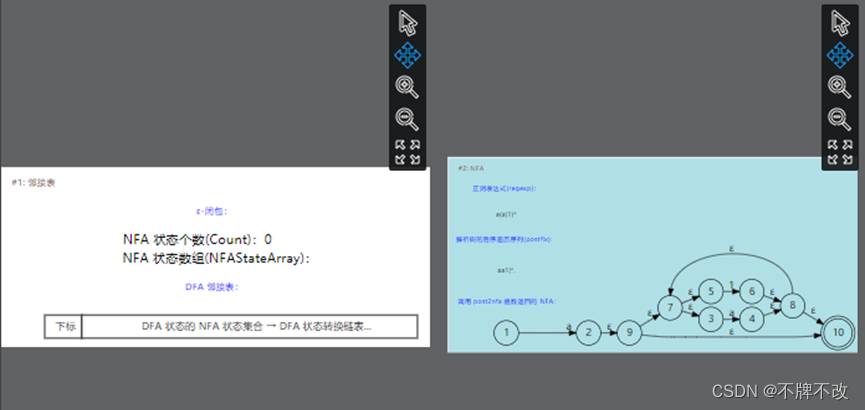
Step2:执行完创建NFA的语句后得到NFA状态图。可视化界面如下:
Step3:利用创建NFA返回的起始状态创建一个DFA状态,同时将DFA状态加入到DFA状态线性表中。
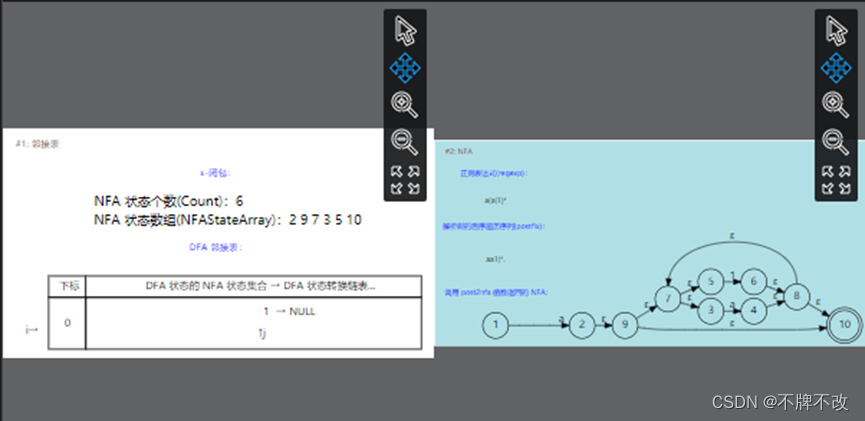
Step4:遍历线性表中所有DFA状态,对应每个DFA状态,遍历其所有的NFA状态(子集构造法会使得一个DFA状态包含多个NFA状态)。如果遍历到的NFA状态是接受状态或者转换是空转换,就跳过此NFA状态;否则,调用Closure函数构造 NFA 状态的ε-闭包。调用IsTransfromExist函数判断某个 DFA 状态的转换链表中是否已经存在一个字符的转换(即相当于保证状态转换表的列索引为不同的输入符号)。对于第一个DFA状态,仅包含起始状态{1},其闭包就是本身,因此遍历完第一个DFA状态后得到的ε-闭包为{1}。当前输入的字符为a,即NFA状态对应的Transform成员,如果Transform为NULL,说明当前状态遇到该字符的转换情况已经被记录过了(对应于转换表上,某个空被填上),此时调用CreateDFATransform函数创建一个转换,并将这个转换插入到转换链表的开始位置。NFA状态1遇到输入字符a后到达状态NFA状态2,Closure函数已经将NFA状态2的闭包状态作为一个NFAlist添加到NFAStateArray(二维指针)中了,此时NFAStateArray包含两个NFAlist,第一个为“{2,9,7,3,5,10}”,第二个为“1”,第三个为NULL。可视化界面如下:

Step5:遍历 DFA 状态的转换链表,根据每个转换创建对应的 DFA 状态。遍历的过程中,需要调用 NFAStateIsSubset 函数判断转换中的 NFA 状态集合是否为某一个 DFA 状态中 NFA 状态集合的子集。如果是子集,因为NFAlist中的一组NFA状态是等价的(空转换得到),所以子集经过空转换可以转换为父集,故父集存在相当于子集已经存在于DFA状态集合中了。在demo过程中,DFA线性表中不存在“{2,9,7,3,5,10}”的父集,因此调用 CreateDFAState 函数创建一个新的 DFA 状态并加入 DFA 线性表中,同时,将转换的 DFAStateIndex 赋值为新加入的 DFA 状态的下标。可视化界面如下:

Setp6:因为保存DFA状态的是线性表,插入新状态是在表的末尾插入,所以现在遍历到了线性表的下一个DFA状态,也即刚刚加入的DFA状态。可视化界面如下:
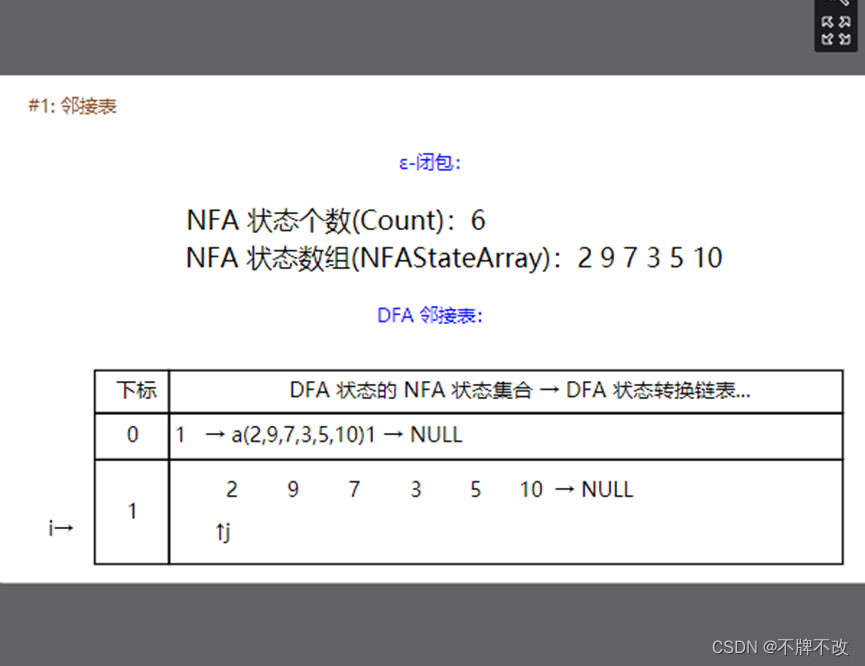
Setp7:接下来若干步,对于j指向的NFA状态2、9、7只有空转换,所以continue。
Step8:j指向了NFA状态3,调用Closure函数得到NFA状态3对于输入字符a的等价NFA状态,可以得到NFAStateArray为{4,8,7,3,5,10}。可视化界面如下:

Step9:j指向了NFA状态5,调用Closure函数得到NFA状态5对于输入字符1的等价NFA状态,可以得到NFAStateArray为{6,8,7,3,5,10}。可视化界面如下:

Step10:NFA状态10是可接受状态,continue。
Step11:将新DFA状态{6,8,7,3,5,10}加入到DFA线性表中,类似地,将新DFA状态{4,8,7,3,5,10}也加入到DFA线性表中:

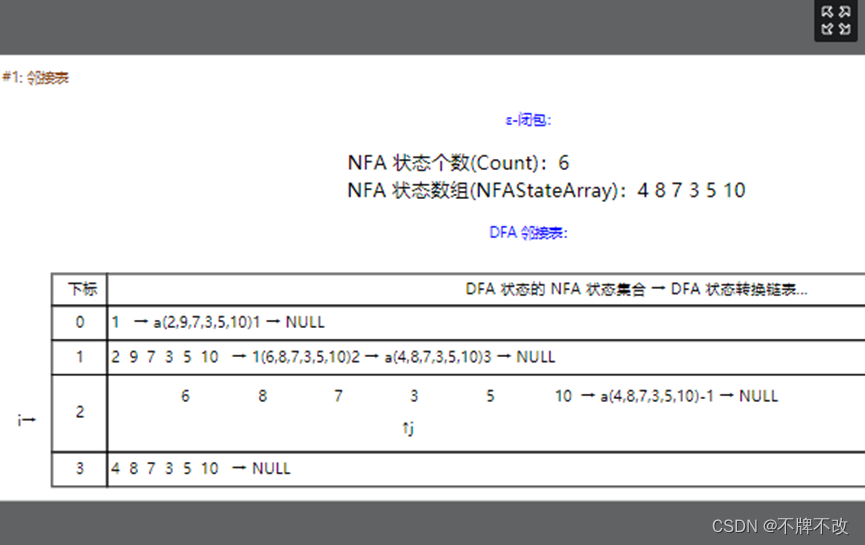
Step12:遍历下一个DFA状态,即{6,8,7,3,5,10}。对于NFA状态6、8、7,只存在空转换,因此直接continue。由于该状态下对于输入字符为a的情况没有出现过状态的转换,因此,需要将NFA状态3遇到输入字符a的输出状态作为{6,8,7,3,5,10}遇到输入字符a的输出状态;类似地,NFA状态5遇到输入字符1的时候进行同样的操作。可视化界面如下:
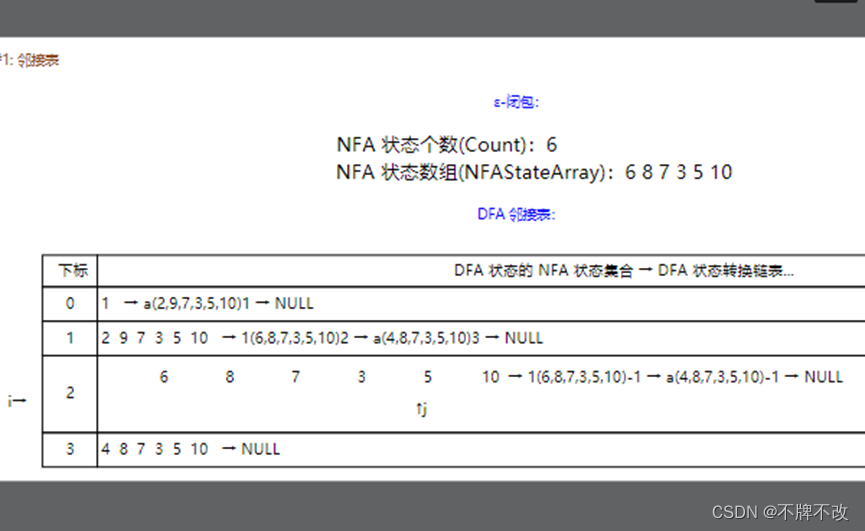
Step13:NFA状态10是可接受状态,直接continue。
Step14:通过上图可以看出DFA状态{6,8,7,3,5,10},遇到输入字符1时,转换为状态{6,8,7,3,5,10},由于该状态已经存在,所以无需重新创建DFA状态并加入DFA线性表中。类似地,DFA状态{4,8,7,3,5,10}也存在了。在DFA状态转换图中添加一条DFA状态{6,8,7,3,5,10}指向自己的箭头,和一条由{6,8,7,3,5,10}经过a指向{4,8,7,3,5,10}的箭头。可视化界面如下:
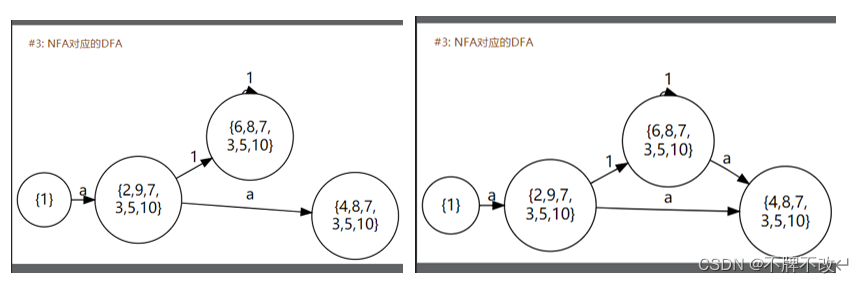
Step15:遍历状态{4,8,7,3,5,10},重复进行上述过程,最终得到的DFA状态转换图如下:

Step16:进入launch.json文件,找到Demo toend:
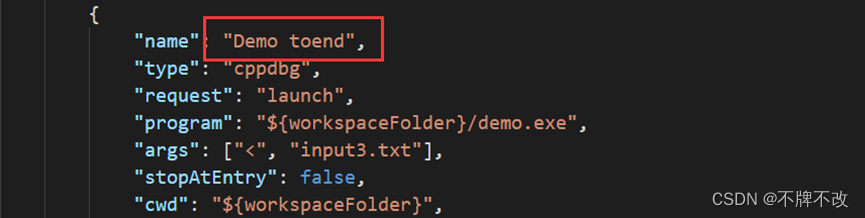
修改其args为不同的input文件直接显示不同输入下的最终结果:
input2.txt结果如下:
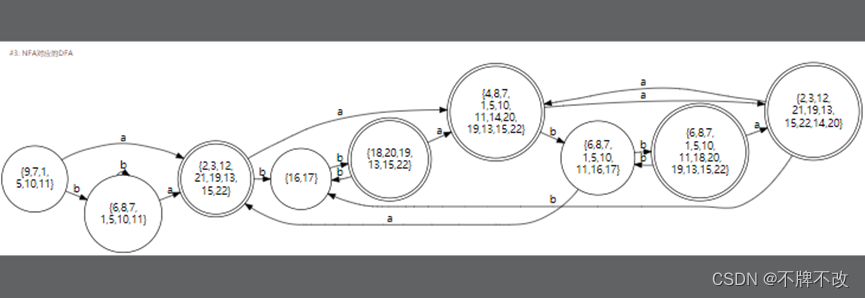
input3.txt结果如下:

补充代码
1. 补充PostToNFA.c代码,实验一中已经完成,这里不再赘述;
2. 补充main.c中NFAStateIsSubset函数的代码,思路如下:
遍历当前的 DFA 线性表中的所有 DFA 状态,记录pTransform 中能够在当前 DFA 状态的 NFA 集合中找到的 NFA 数量,遍历当前 DFA 状态的 NFA 集合,如果 pTransform 中的所有 NFA 均能被匹配,即记录的数量相等,则表明 pTransform 转换中的 NFA 状态集合为遍历到的 DFA 状态中 NFA 状态集合的子集。
功能:判断一个转换中的 NFA 状态集合是否为某一个 DFA 状态中 NFA 状态集合的子集。
参数与返回值:
pDFA -- DFA 指针。
pTransform -- DFA 状态转换指针。
如果存在返回 DFA 状态下标,不存在返回 -1。

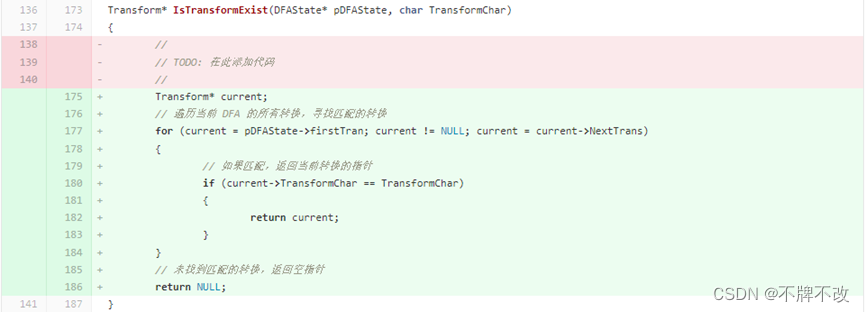
3. 补充main.c中IsTransformExist函数的代码,思路如下:
遍历当前 DFA 的所有转换,寻找匹配的转换。如果匹配,返回当前转换的指针;如果未找到匹配的转换,返回空指针。
功能:判断某个 DFA 状态的转换链表中是否已经存在一个字符的转换。
参数与返回值:
pDFAState -- DFAState 指针。
TransformChar -- 转换标识符。
返回Transform 结构体指针。
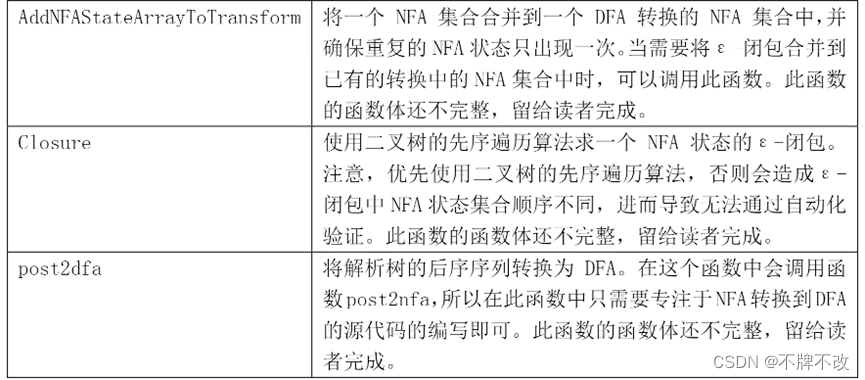
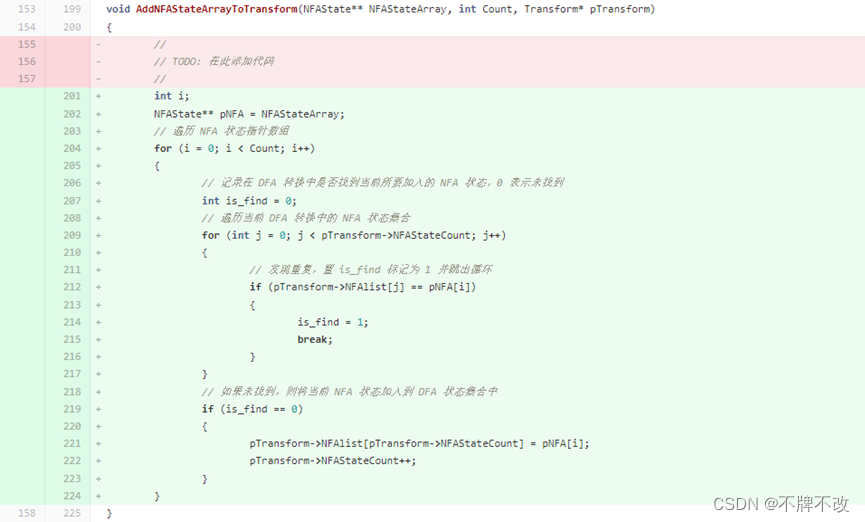
4. 补充main.c中AddNFAStateArrayToTransform函数的代码,思路如下:
遍历 NFA 状态指针数组,记录在 DFA 转换中是否找到当前所要加入的 NFA 状态,0 表示未找到,遍历当前 DFA 转换中的 NFA 状态集合;如果发现重复,置 is_find 标记为 1 并跳出循环,如果最终仍然未找到,则将当前 NFA 状态加入到 DFA 状态集合中。
功能:将一个 NFA 集合合并到一个 DFA 转换中的 NFA 集合中。注意,合并后的 NFA 集合中不应有重复的 NFA 状态。
参数与返回值:
NFAStateArray -- NFA 状态指针数组,即待加入的 NFA 集合。
Count -- 待加入的 NFA 集合中元素个数。
pTransform -- 转换指针。
5. 补充main.c中Closure函数的代码,思路如下:
补充Closure函数的核心是实现先序遍历二叉树,因此通过深度优先搜索的方式对二叉树进行遍历。将当前深搜到的状态存入 NFA 状态集合中,如果左子树存在且为 eplison 转换,则向左子树遍历,如果右子树存在且为 eplison 转换,则向右子树遍历。最后Closure函数调用DFS函数即可。
功能:使用二叉树的先序遍历算法求一个 NFA 状态的ε-闭包。
参数与返回值:
State -- NFA 状态指针。从此 NFA 状态开始求ε-闭包。
StateArray -- NFA 状态指针数组。用于返回ε-闭包。
Count -- 元素个数。 用于返回ε-闭包中 NFA 状态的个数。

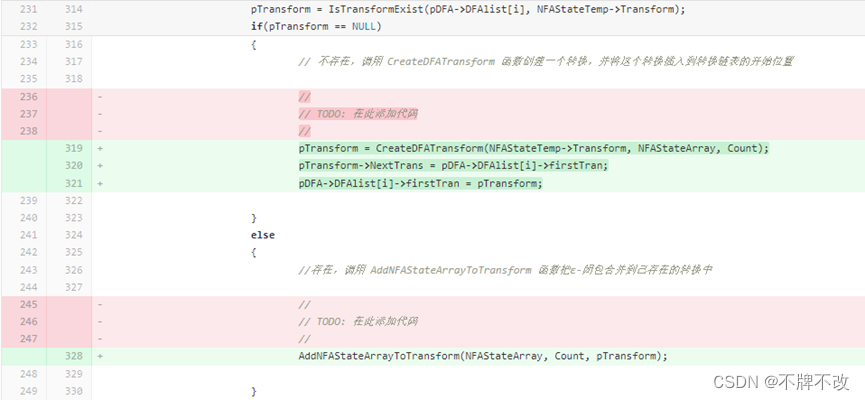
6. 补充main.c中对于不同pTransform的情况下执行的不同代码,思路如下:
调用 IsTransfromExist 函数判断当前 DFA 状态的转换链表中是否已经存在该 NFA 状态的转换,如果不存在,调用 CreateDFATransform 函数创建一个转换,并将这个转换插入到转换链表的开始位置;如果存在,调用 AddNFAStateArrayToTransform 函数把ε-闭包合并到已存在的转换中。其中不存在的情况下,采用链表的首插法将新状态加入到转移链表中。
思考与练习
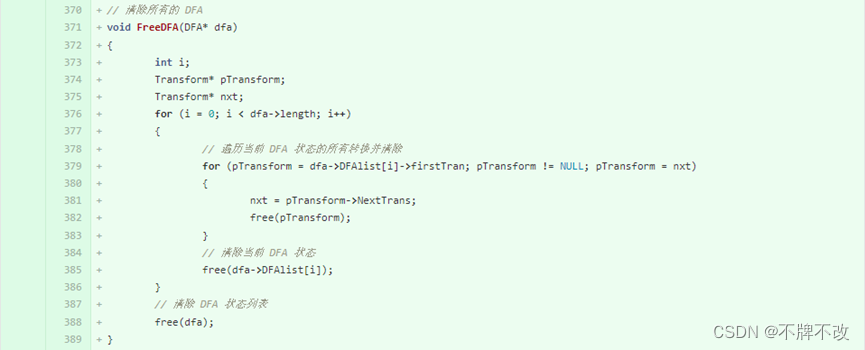
1. 编写一个FreeNFA函数和一个FreeDFA函数,当在main函数的最后调用这两个函数时,可以将整个NFA和DFA的内存分别释放掉,从而避免内存泄露。
释放NFA内存比较容易,只要顺序free NFASateList即可。

完全释放DFA内存需要先将每个状态对应的保存转换的内存释放掉,再将DFA状态内存释放掉。
2. 读者可以尝试使用白己编写的代码将input2.txt和 input3.txt中的正则表达式转换成DFA,并确保能够通过自动化验证。
input1.txt:
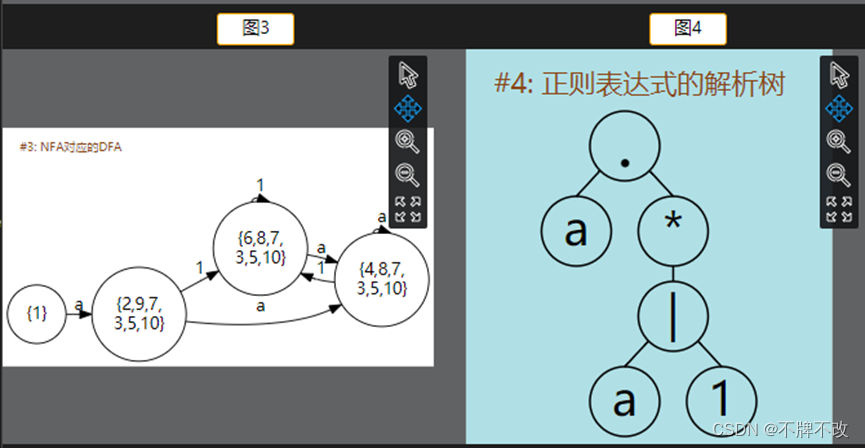
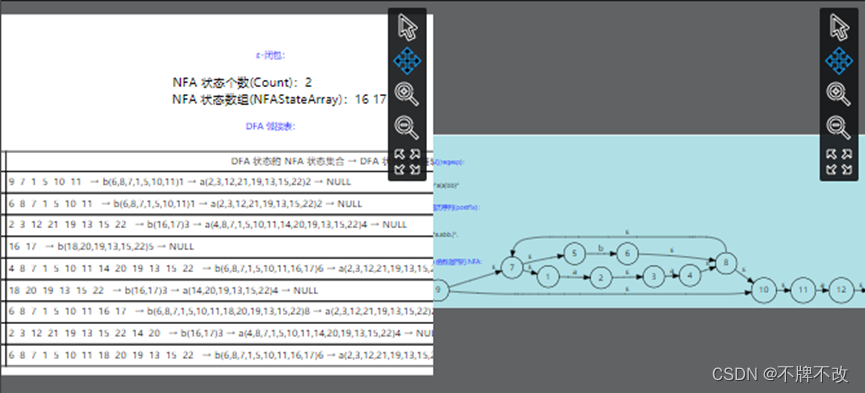

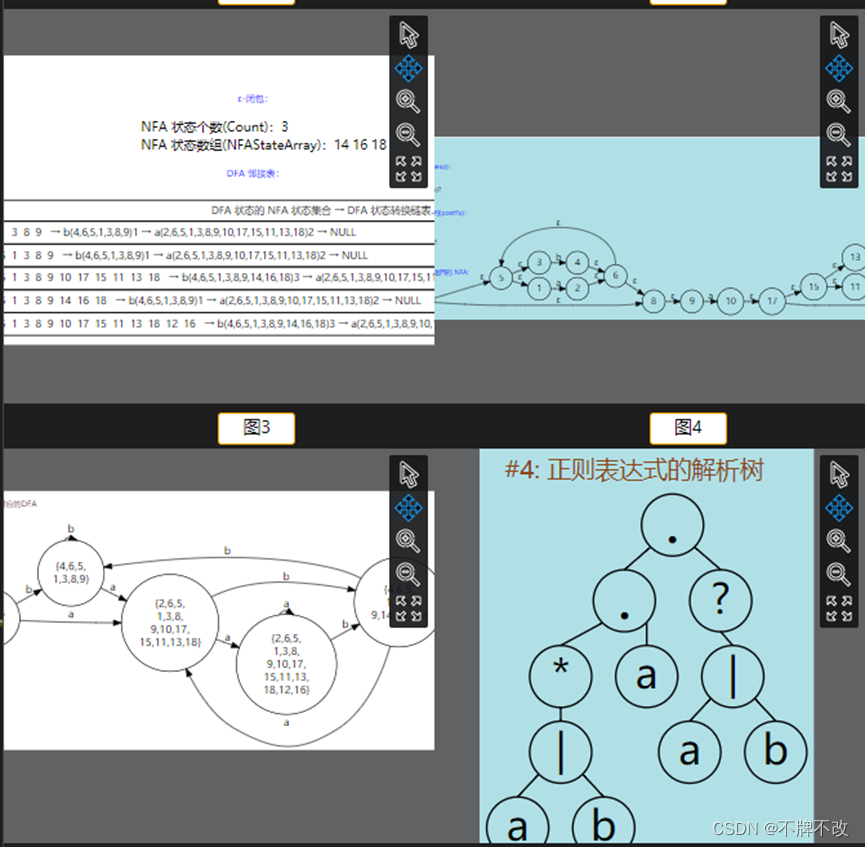

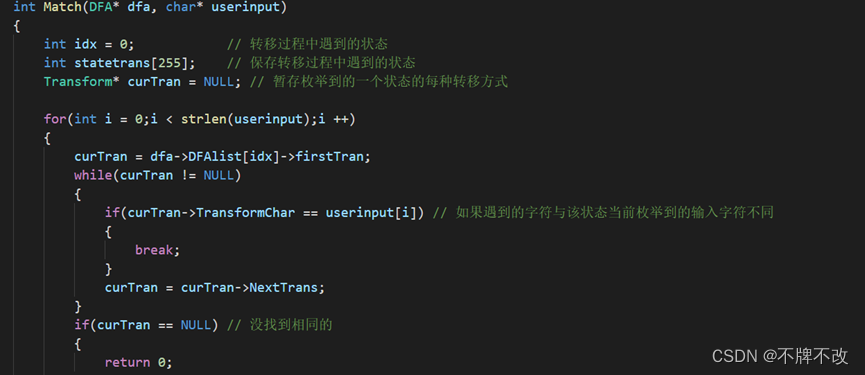
3. 编写一个 Match 函数,此函数可以将一个字符串与正则表达式转换的DFA进行匹配,如果匹配成功返回1,否则返回0。
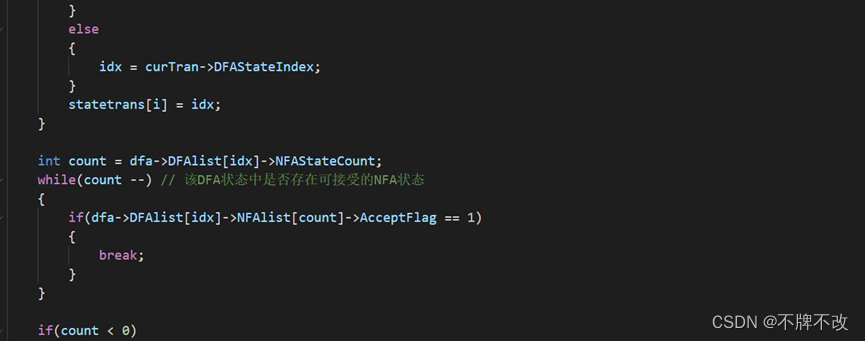
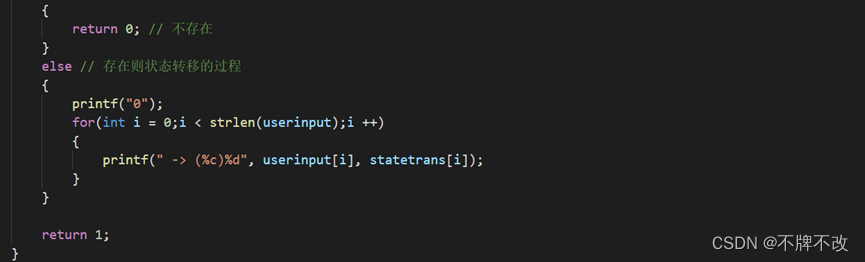
只展示input1.txt构造的状态转换图,对于输入为“a”的字符串进行判断:
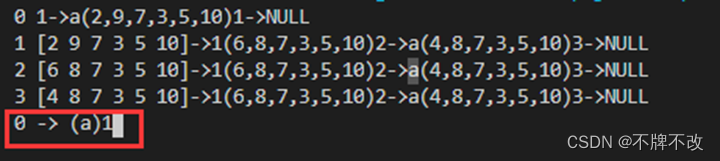
0表示初始DFA状态编号,遇到字符“a”后转换为状态1。
对于输入为“aaaaa”的字符串进行判断:

对于输入为“a1aa1a”的字符串进行判断:

当无法对输入字符串进行分析时,不会输出状态转换路径,比如对输入字符串“1”:

四、实验总结
本次实验主要是实现将NFA状态转换图变成DFA状态转换图,其中包含补全“判断一个转换中的 NFA 状态集合是否为某一个 DFA 状态中 NFA 状态集合的子集”的函数、“判断某个 DFA 状态的转换链表中是否已经存在一个字符的转换”的函数、“将一个 NFA 集合合并到一个 DFA 转换中的 NFA 集合中”的函数、“使用二叉树的先序遍历算法求一个 NFA 状态的ε-闭包”的函数。这四个函数都需要对原代码给出的NFA、DFA、DFAList等等数据结构非常熟悉才能完成。
在本次实验中,绝大部分时间用于优化代码,尤其是内存的释放问题,对于如何释放内存有了一定的认识,但是经过多次提交作业,仍然无法将代码中的minor问题处理掉,有些可惜。
值得高兴的是将Match函数完成了,整体思路是遍历匹配字符串,同时状态从初始状态开始,也即状态0,如果遍历到的字符与当前状态可以进行转换的某一个输入字符相同,则按照该路径进行状态转换,如果不存在对应的输入字符,则说明匹配出错。除此之外,如果最终遍历完字符串但是停留在的状态不是最终状态也说明匹配出错。重复该过程直至结束或出错。